
.NET Core 3.0 System.Text.Json 和 Newtonsoft.Json 行為不一致問題及解決辦法
行為不一致
.NET Core 3.0 新出了個內建的 JSON 庫, 全名叫做尼古拉斯 System.Text.Json - 效能更高佔用記憶體更少這都不是事...
對我來說, 很多或大或小的專案能少個第三方依賴項, 還能規避多個依賴項的依賴 Newtonsoft.Json 版本不一致的問題, 是件極美的事情.
但是, 結果總不是不如預期那麼簡單和美好, 簡單測試了下, 有一些跟 Newtonsoft.Json 行為不一致的地方, 程式碼如下:
using Microsoft.VisualStudio.TestTools.UnitTesting; namespace UnitTestProject3 { [TestClass] public class TestJsonDiff { [TestMethod] [Description(description: "測試數字序列化")] public void TestNumber() { object jsonObject = new { number = 123.456 }; string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject); string bJsonString = System.Text.Json.JsonSerializer.Serialize(value: jsonObject); Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試數字序列化失敗"); } [TestMethod] [Description(description: "測試英文序列化")] public void TestEnglish() { object jsonObject = new { english = "bla bla" }; string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject); string bJsonString = System.Text.Json.JsonSerializer.Serialize(value: jsonObject); Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試英文序列化失敗"); } [TestMethod] [Description(description: "測試中文序列化")] public void TestChinese() { object jsonObject = new { chinese = "灰長標準的布咚發" }; string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject); string bJsonString = System.Text.Json.JsonSerializer.Serialize(value: jsonObject); Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試中文序列化失敗"); } [TestMethod] [Description(description: "測試英文符號")] public void TestEnglishSymbol() { object jsonObject = new { symbol = @"~`!@#$%^&*()_-+={}[]:;'<>,.?/ " }; string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject); string bJsonString = System.Text.Json.JsonSerializer.Serialize(value: jsonObject); Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試英文符號失敗"); } [TestMethod] [Description(description: "測試中文符號")] public void TestChineseSymbol() { object jsonObject = new { chinese_symbol = @"~·@#¥%……&*()—-+={}【】;:“”‘’《》,。?、" }; string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject); string bJsonString = System.Text.Json.JsonSerializer.Serialize(value: jsonObject); Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試中文符號失敗"); } [TestMethod] [Description(description: "測試反序列化數值字串隱式轉換為數值型別")] public void TestDeserializeNumber() { string ajsonString = "{\"Number\":\"123\"}"; TestClass aJsonObject = Newtonsoft.Json.JsonConvert.DeserializeObject<TestClass>(ajsonString); // 報錯,The JSON value could not be converted to System.Int32. Path: $.number | LineNumber: 0 | BytePositionInLine: 15 TestClass bJsonObject = System.Text.Json.JsonSerializer.Deserialize<TestClass>(json: ajsonString); Assert.AreEqual(expected: aJsonObject.Number, actual: bJsonObject.Number, message: "測試反序列化數值字串隱式轉換為數值型別失敗"); } public class TestClass { public int Number { get; set; } } } }
先來看看總體的測試結果:
這是 VS 顯示的結果
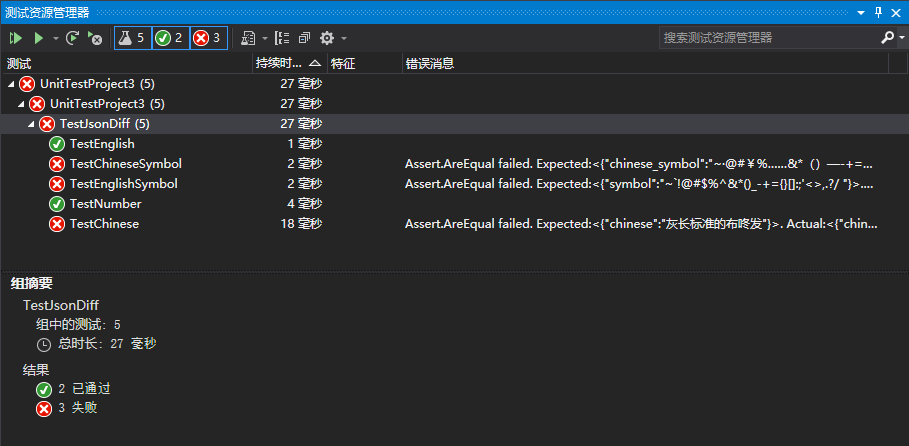
這是執行 dotnet test 命令列顯示的結果
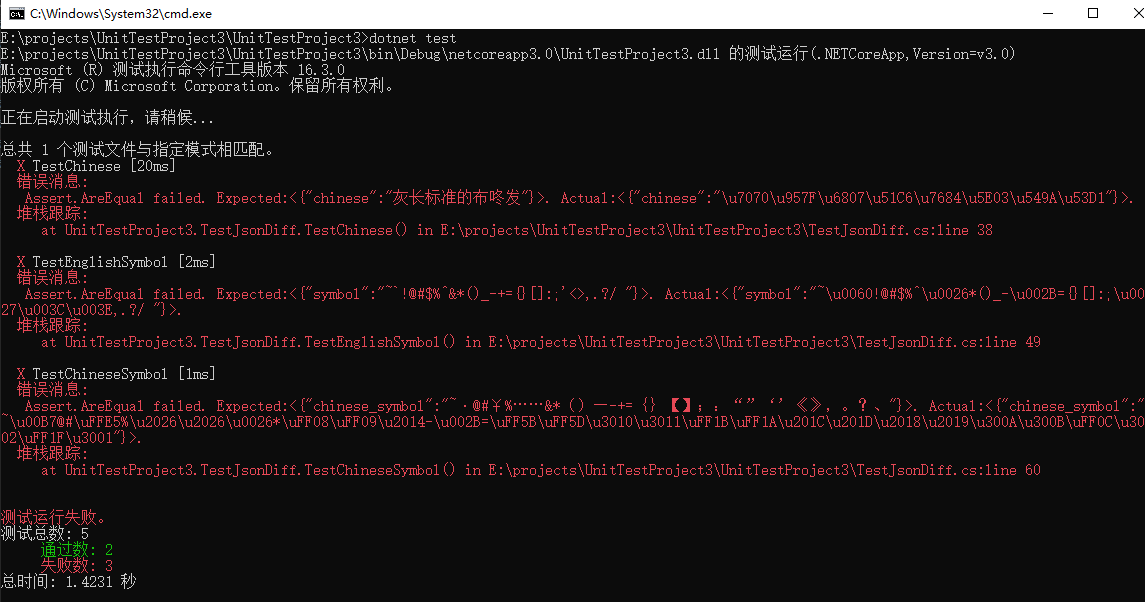
這個時候需要配個圖

那麼問題來了, 國慶去哪玩比較好呢, 我是誰? 這是哪? 發生了什麼?
可以羅列為以下行為不一致, 當然可能還有更多, 歡迎補充...讓更多小夥伴看到
中文被編碼
部分符號被轉義
數值字串不能隱式轉換為數值型別
這裡有個相關的 issue System.Text.Json: Deserialization support for quoted numbers #39473
隱式轉換會出現精度缺失, 但依舊會轉換成功最終導致資料計算或者資料落庫等安全隱患, 是個潛在的問題, 而 Newtonsoft.Json 等預設支援隱式轉換, 不一定是個合理的方式.
但是大家習慣用了, 先找找如何讓二者行為一致的辦法吧, 可以通過自定義型別轉換器來實現.
// 自定義型別轉換器 public class IntToStringConverter : JsonConverter<int> { public override int Read(ref Utf8JsonReader reader, Type type, JsonSerializerOptions options) { if (reader.TokenType == JsonTokenType.String) { ReadOnlySpan<byte> span = reader.HasValueSequence ? reader.ValueSequence.ToArray() : reader.ValueSpan; if (Utf8Parser.TryParse(span, out int number, out int bytesConsumed) && span.Length == bytesConsumed) { return number; } if (Int32.TryParse(reader.GetString(), out number)) { return number; } } return reader.GetInt32(); } public override void Write(Utf8JsonWriter writer, int value, JsonSerializerOptions options) { writer.WriteStringValue(value.ToString()); } }
使用的時候新增到配置即可, 依此類推可以自行新增更多其他型別轉換器
JsonSerializerOptions options = new System.Text.Json.JsonSerializerOptions();
options.Converters.Add(item: new IntToStringConverter());
//options.Converters.Add(item: new OthersConverter());
System.Text.Json.JsonSerializer.Deserialize<TestClass>(json: ajsonString, options: options);列舉型別的轉換
System.Text.Json/tests/Serialization/EnumConverterTests.cs#L149 - 官方測試原始碼例子很全
[TestMethod]
[Description(description: "測試列舉反序列化")]
public void TestDeserializeEnum()
{
// 場景: 前端傳過來字串, 轉成列舉
JsonSerializerOptions options = new System.Text.Json.JsonSerializerOptions();
options.Converters.Add(item: new JsonStringEnumConverter(namingPolicy: null, allowIntegerValues: false));
string jsonString = "{\"State\":\"2\"}";
Some aJsonObject = Newtonsoft.Json.JsonConvert.DeserializeObject<Some>(value: jsonString);
Some bJsonObject = System.Text.Json.JsonSerializer.Deserialize<Some>(json: jsonString, options: options);
Assert.AreEqual(expected: aJsonObject.State, actual: bJsonObject.State, message: "測試列舉反序列化失敗");
}
[TestMethod]
[Description(description: "測試列舉序列化")]
public void TestSerializeEnum()
{
// 場景: 後端列舉返回前端, 需要數值
Some some = new Some
{
State = State.Delete
};
string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: some);
string bJsonString = System.Text.Json.JsonSerializer.Serialize(value: some);
Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試列舉序列化失敗");
}
public enum State
{
Create = 1,
Update = 2,
Delete = 4,
}
public class Some
{
public State State { get; set; }
}不過這裡延伸了一個問題, 在 ASP.NET Core 中的全域性 JsonOptions 中怎麼處理輸入序列化和輸出序列化設定不同的問題?
解決辦法
解決中文會被 Unicode 編碼的問題
這個問題是在部落格園裡找到的一種答案: .NET Core 3.0 中使用 System.Text.Json 序列化中文時的編碼問題
[TestMethod]
[Description(description: "測試中文序列化")]
public void TestChinese()
{
object jsonObject = new { chinese = "灰長標準的布咚發" };
string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject);
string bJsonString = System.Text.Json.JsonSerializer.Serialize(
value: jsonObject,
options: new System.Text.Json.JsonSerializerOptions
{
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.Create(allowedRanges: UnicodeRanges.All)
});
Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "測試中文序列化失敗");
}關鍵在於序列化配置加了一句
new System.Text.Json.JsonSerializerOptions
{
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.Create(allowedRanges: UnicodeRanges.All)
}但是一些符號被轉義的問題還是不管用, 尋思了一上午暫時沒找到答案...
至於什麼時候修復此類問題,

我去原始碼 corefx 溜個一圈, 暫時的發現是歸到了 .NET Core 3.1 和 5.0 的開發時間線裡...後面回來發現這不應該啊
但是...難道就這樣了?
懷著受傷的核桃心, 中午又吃了3只大閘蟹...
詭異的是新建 ASP.NET Core API (.NET Core 3.0) 輸出的 JSON 中文和轉義字元都是正常, 如圖:
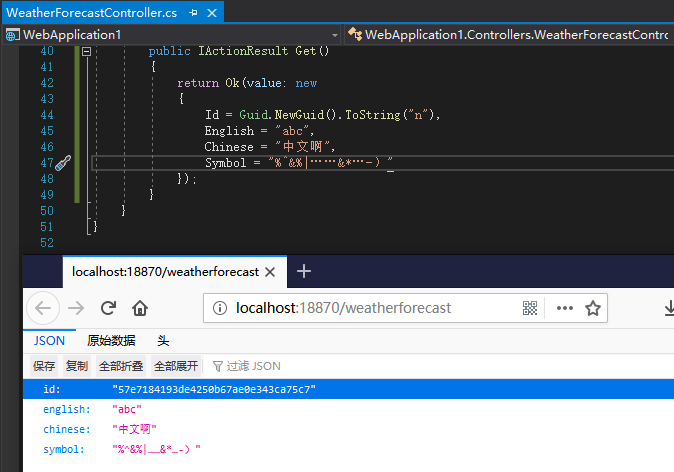
說明一定是我們開啟的方式不對...回孃家找原始碼, 尋尋匿匿最後發現這麼一句
// If the user hasn't explicitly configured the encoder, use the less strict encoder that does not encode all non-ASCII characters.
jsonSerializerOptions = jsonSerializerOptions.Copy(JavaScriptEncoder.UnsafeRelaxedJsonEscaping);less strict ? 那對照的意思是 Newtonsoft.Json 一直使用的就是非嚴格模式咯, 而我們習慣使用的也是這種模式.
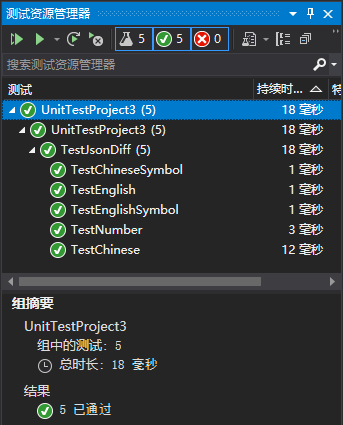
那麼改下, 還報錯的單元測試都加上配置 JavaScriptEncoder.UnsafeRelaxedJsonEscaping, 果然測試結果順眼多了. 連上面的 UnicodeRanges.All 都不需要配置了.
string bJsonString = System.Text.Json.JsonSerializer.Serialize(
value: jsonObject,
options: new System.Text.Json.JsonSerializerOptions
{
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.UnsafeRelaxedJsonEscaping
});
邊上新開了家店, 晚上去吃吃看...

寫在最後
劃重點: 如果之前專案使用的是 Newtonsoft.Json, 升級之後建議還是繼續使用 Newtonsoft.Json, 可以規避上訴N多可能的問題. 如果是新專案或者想少個三方依賴, 可以試試 System.Text.Json, 畢竟更輕量效能更好.