
Go併發程式設計
概述
簡而言之,所謂併發程式設計是指在一臺處理器上“同時”處理多個任務。
隨著硬體的發展,併發程式變得越來越重要。Web伺服器會一次處理成千上萬的請求。平板電腦和手機app在渲染使用者畫面同時還會在後臺執行各種計算任務和網路請求。即使是傳統的批處理問題--讀取資料,計算,寫輸出--現在也會用併發來隱藏掉I/O的操作延遲以充分利用現代計算機裝置的多個核心。計算機的效能每年都在以非線性的速度增長。
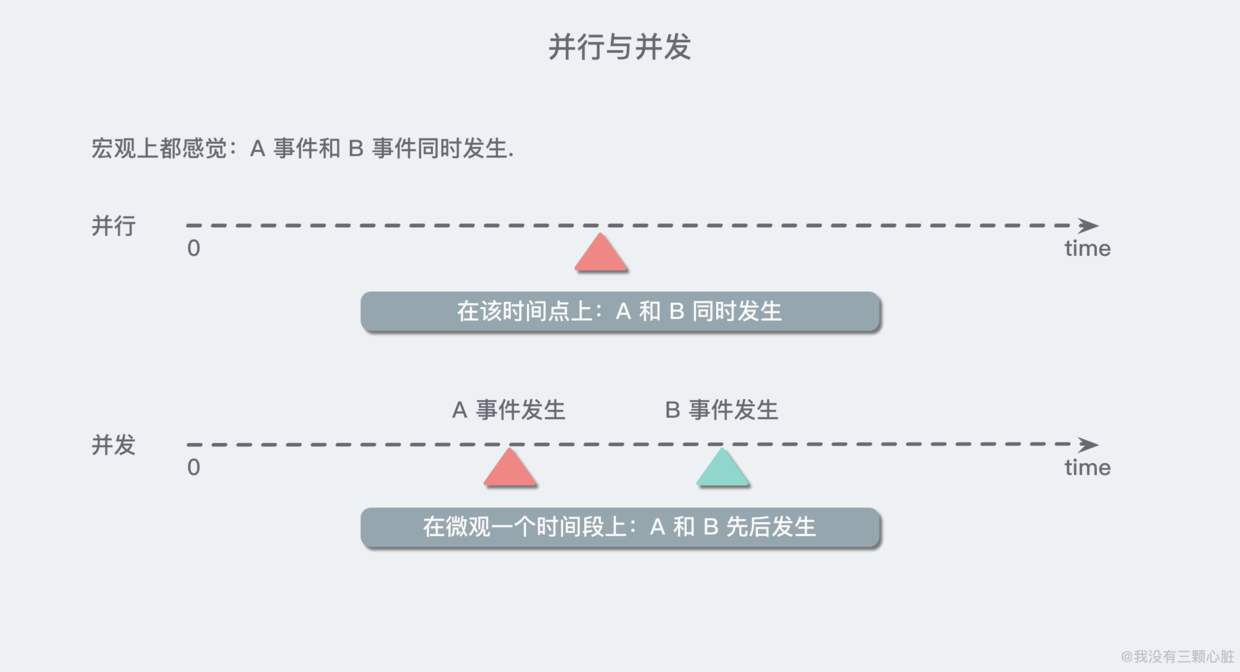
巨集觀的併發是指在一段時間內,有多個程式在同時執行。
併發在微觀上,是指在同一時刻只能有一條指令執行,但多個程式指令被快速的輪換執行,使得在巨集觀上具有多個程序同時執行的效果,但在微觀上並不是同時執行的,只是把時間分成若干段,使多個程式快速交替的執行。
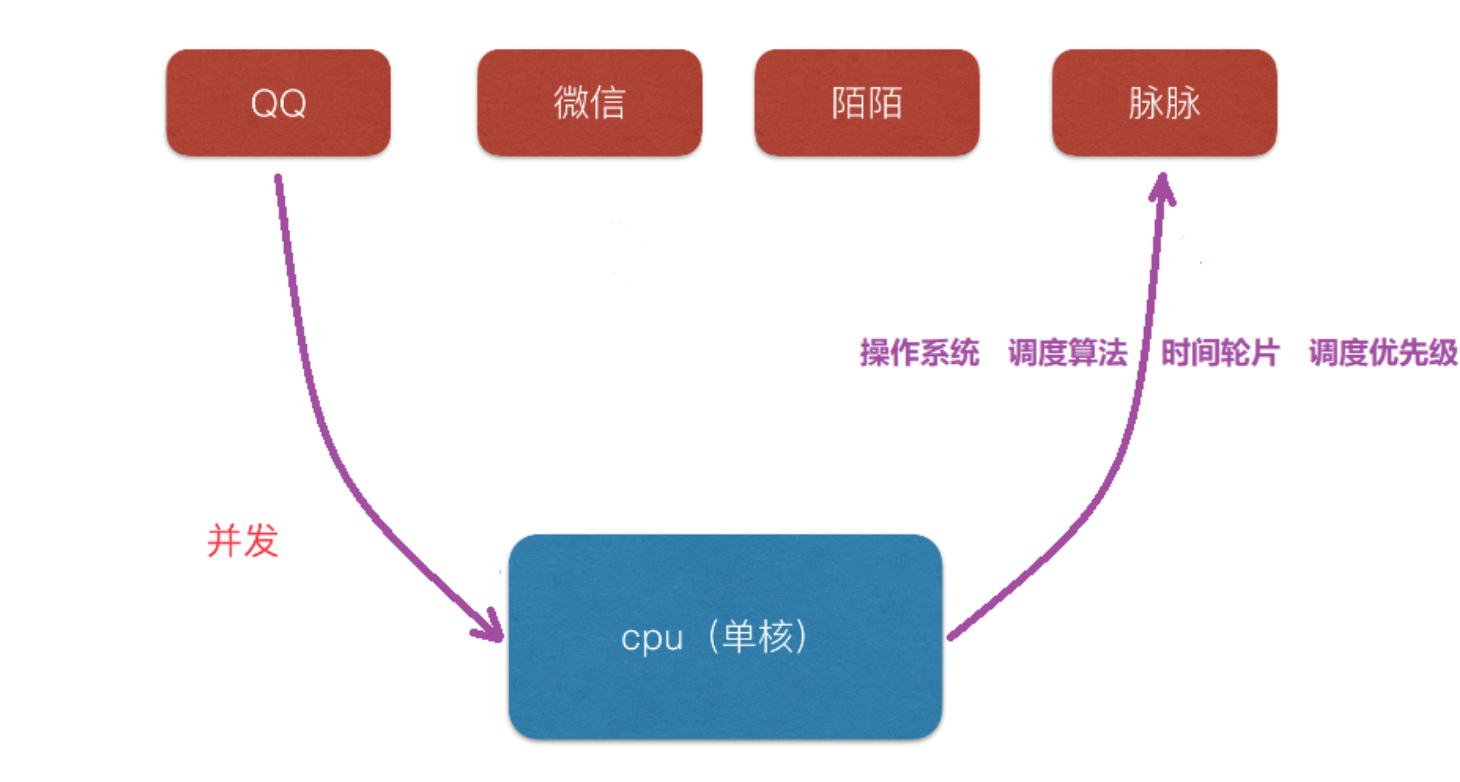
並行和併發
並行(parallel):指在同一時刻,有多條指令在多個處理器上同時執行。

併發(concurrency):指在同一時刻只能有一條指令執行,但多個程序指令被快速的輪換執行,使得在巨集觀上具有多個程序同時執行的效果,但在微觀上並不是同時執行的,只是把時間分成若干段,通過cpu時間片輪轉使多個程序快速交替的執行。
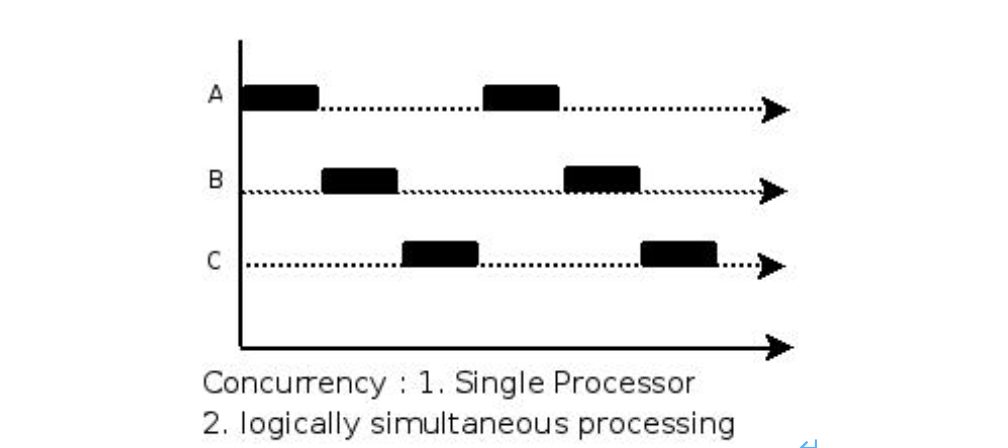
大師曾以咖啡機的例子來解釋並行和併發的區別。
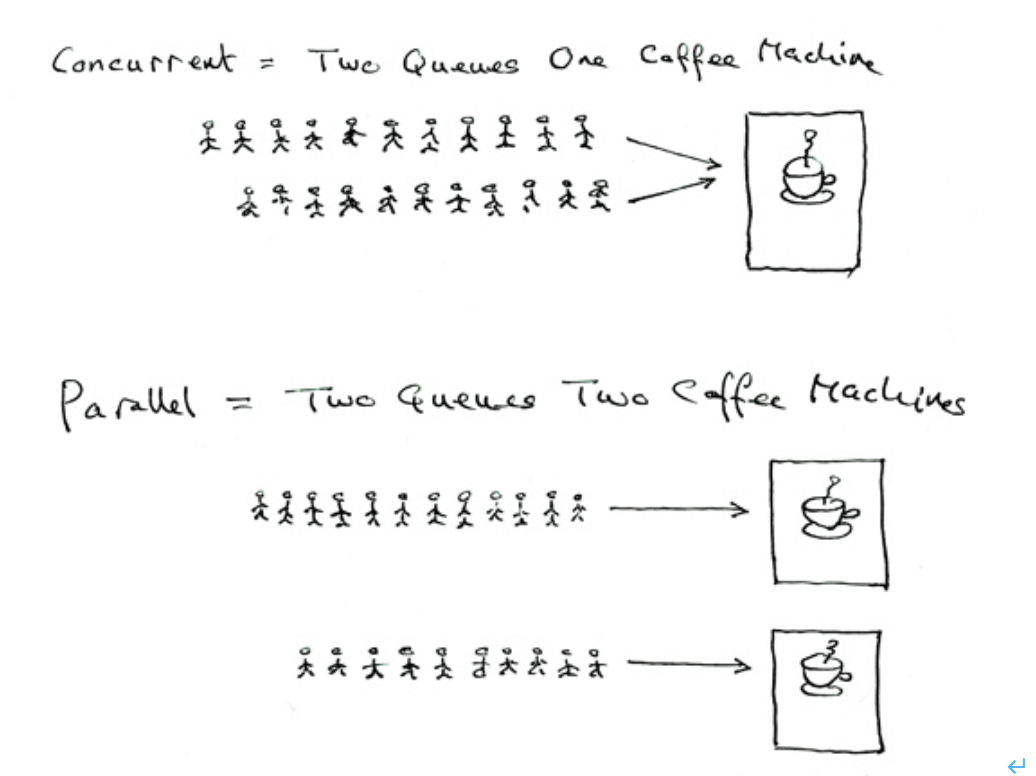
- 並行是兩個佇列同時使用兩臺咖啡機 (真正的多工)
- 併發是兩個佇列交替使用一臺咖啡機 ( 假 的多工)
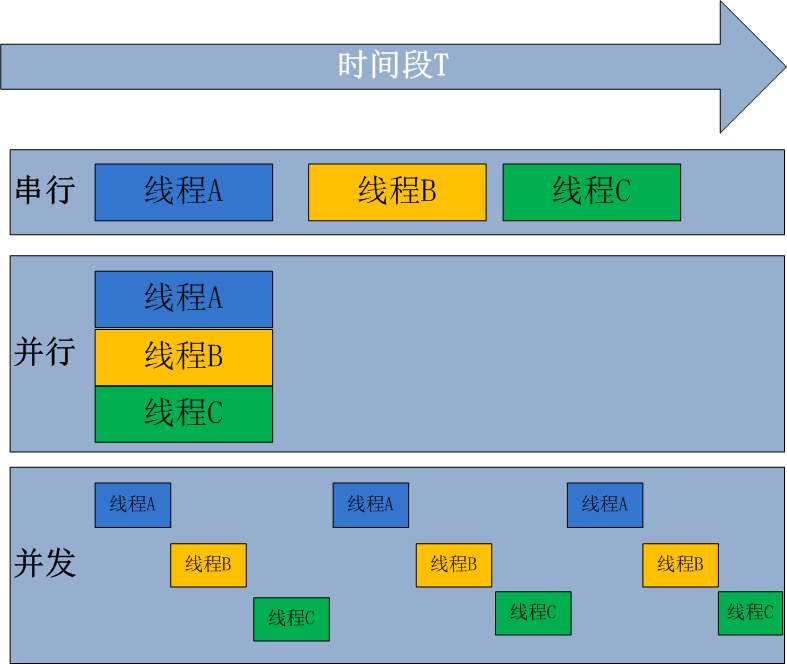
下面的兩張圖是國人做的一些不錯的比較並行與併發區別的圖。
常見併發程式設計技術
程序併發
程式和程序
程式,是指編譯好的二進位制檔案,在磁碟上,不佔用系統資源(cpu、記憶體、開啟的檔案、裝置、鎖....)
程序,是一個抽象的概念,與作業系統原理聯絡緊密。程序是活躍的程式,佔用系統資源。在記憶體中執行。(程式執行起來,產生一個程序)
我們可以把程式比作劇本(紙),把程序比作一場戲(舞臺、演員、燈光、道具...)
同一個劇本可以在多個舞臺同時上演。同樣,同一個程式也可以載入為不同的程序(彼此之間互不影響)
如:同時開兩個終端。各自都有一個bash但彼此ID不同。
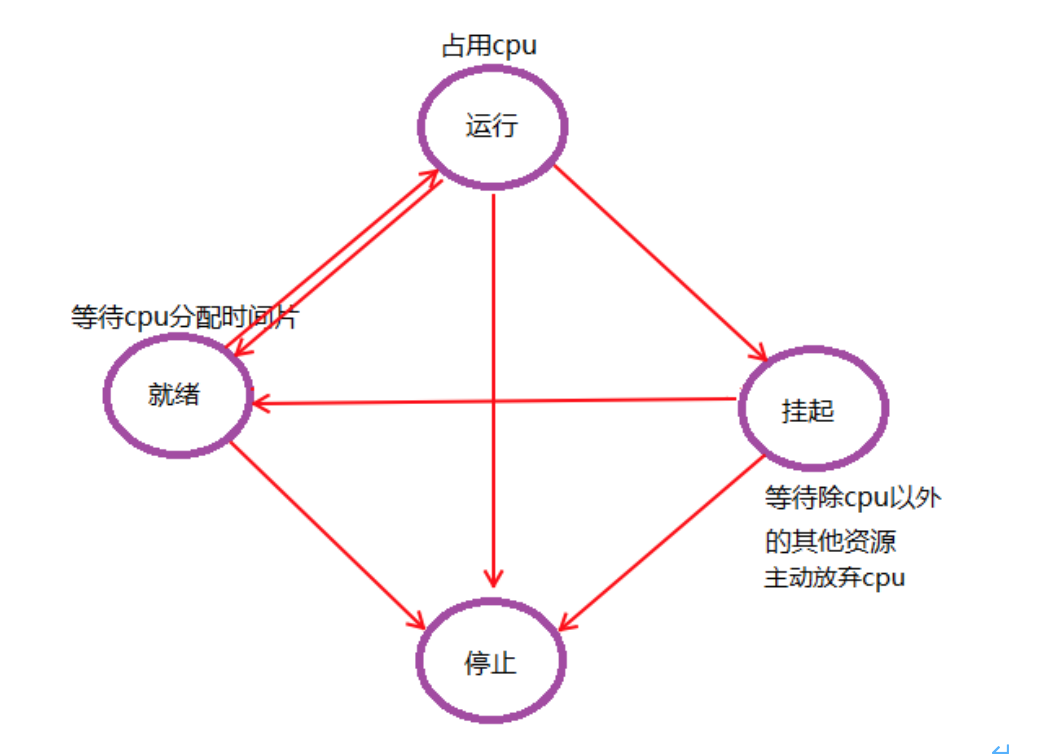
程序狀態
程序基本的狀態有5種。分別為初始態,就緒態,執行態,掛起態與終止態。其中初始態為程序準備階段,常與就緒態結合來看。
程序併發
在使用程序 實現併發時會出現什麼問題呢?
- 系統開銷比較大,佔用資源比較多,開啟程序數量比較少。
- 在unix/linux系統下,還會產生“孤兒程序”和“殭屍程序”。
我們知道在作業系統中,可以產生很多的程序。在unix/linux系統中,正常情況下,子程序是通過父程序fork建立的,子程序再建立新的程序。
並且父程序永遠無法預測子程序 到底什麼時候結束。 當一個 程序完成它的工作終止之後,它的父程序需要呼叫系統呼叫取得子程序的終止狀態。
孤兒程序
父程序先於子程序結束,則子程序成為孤兒程序,子程序的父程序成為init程序,稱為init程序領養孤兒程序。
殭屍程序
程序終止,父程序尚未回收,子程序殘留資源(PCB)存放於核心中,變成殭屍(Zombie)程序。
Windows下的程序和Linux下的程序是不一樣的,它比較懶惰,從來不執行任何東西,只是為執行緒提供執行環境。然後由執行緒負責執行包含在程序的地址空間中的程式碼。當建立一個程序的時候,作業系統會自動建立這個程序的第一個執行緒,稱為主執行緒。
執行緒併發
什麼是執行緒
LWP:light weight process 輕量級的程序,本質仍是程序 (Linux下)
程序:獨立地址空間,擁有PCB
執行緒:有獨立的PCB,但沒有獨立的地址空間(共享)
區別:在於是否共享地址空間。獨居(程序);合租(執行緒)。
- 執行緒:最小的執行單位
- 程序:最小分配資源單位,可看成是隻有一個執行緒的程序。
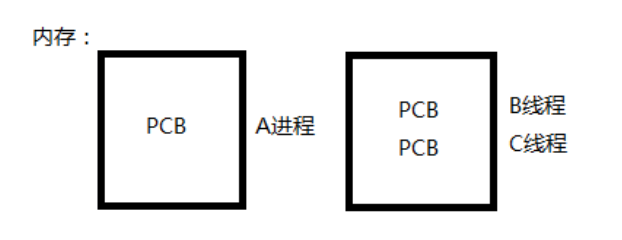
Windows系統下,可以直接忽略程序的概念,只談執行緒。因為執行緒是最小的執行單位,是被系統獨立排程和分派的基本單位。而程序只是給執行緒提供執行環境。
執行緒同步
同步即協同步調,按預定的先後次序執行。
執行緒同步,指一個執行緒發出某一功能呼叫時,在沒有得到結果之前,該呼叫不返回。同時其它執行緒為保證資料一致性,不能呼叫該功能。
舉例1: 銀行存款 5000。櫃檯,折:取3000;提款機,卡:取 3000。剩餘:2000
舉例2: 記憶體中100位元組,執行緒T1欲填入全1, 執行緒T2欲填入全0。但如果T1執行了50個位元組失去cpu,T2執行,會將T1寫過的內容覆蓋。當T1再次獲得cpu繼續 從失去cpu的位置向後寫入1,當執行結束,記憶體中的100位元組,既不是全1,也不是全0。
產生的現象叫做“與時間有關的錯誤”(time related)。為了避免這種資料混亂,執行緒需要同步。
“同步”的目的,是為了避免資料混亂,解決與時間有關的錯誤。實際上,不僅執行緒間需要同步,程序間、訊號間等等都需要同步機制。
因此,所有“多個控制流,共同操作一個共享資源”的情況,都需要同步。
鎖的應用
互斥量mutex
Linux中提供一把互斥鎖mutex(也稱之為互斥量)。
每個執行緒在對資源操作前都嘗試先加鎖,成功加鎖才能操作,操作結束解鎖。
資源還是共享的,執行緒間也還是競爭的,
但通過“鎖”就將資源的訪問變成互斥操作,而後與時間有關的錯誤也不會再產生了。

但,應注意:同一時刻,只能有一個執行緒持有該鎖。
當A執行緒對某個全域性變數加鎖訪問,B在訪問前嘗試加鎖,拿不到鎖,B阻塞。C執行緒不去加鎖,而直接訪問該全域性變數,依然能夠訪問,但會出現資料混亂。
所以,互斥鎖實質上是作業系統提供的一把“建議鎖”(又稱“協同鎖”),建議程式中有多執行緒訪問共享資源的時候使用該機制。但,並沒有強制限定。
因此,即使有了mutex,如果有執行緒不按規則來訪問資料,依然會造成資料混亂。
讀寫鎖
與互斥量類似,但讀寫鎖允許更高的並行性。其特性為:寫獨佔,讀共享。
讀寫鎖狀態:
特別強調:讀寫鎖只有一把,但其具備兩種狀態:
- 讀模式下加鎖狀態 (讀鎖)
- 寫模式下加鎖狀態 (寫鎖)
讀寫鎖特性:
- 讀寫鎖是“寫模式加鎖”時, 解鎖前,所有對該鎖加鎖的執行緒都會被阻塞。
- 讀寫鎖是“讀模式加鎖”時, 如果執行緒以讀模式對其加鎖會成功;如果執行緒以寫模式加鎖會阻塞。
- 讀寫鎖是“讀模式加鎖”時, 既有試圖以寫模式加鎖的執行緒,也有試圖以讀模式加鎖的執行緒。那麼讀寫鎖會阻塞隨後的讀模式鎖請求。優先滿足寫模式鎖。讀鎖、寫鎖並行阻塞,寫鎖優先順序高
讀寫鎖也叫共享-獨佔鎖。當讀寫鎖以讀模式鎖住時,它是以共享模式鎖住的;當它以寫模式鎖住時,它是以獨佔模式鎖住的。寫獨佔、讀共享。
讀寫鎖非常適合於對資料結構讀的次數遠大於寫的情況。
協程併發
協程:coroutine。也叫輕量級執行緒。
與傳統的系統級執行緒和程序相比,協程最大的優勢在於“輕量級”。可以輕鬆建立上萬個而不會導致系統資源衰竭。而執行緒和程序通常很難超過1萬個。這也是協程別稱“輕量級執行緒”的原因。
一個執行緒中可以有任意多個協程,但某一時刻只能有一個協程在執行,多個協程分享該執行緒分配到的計算機資源。
多數語言在語法層面並不直接支援協程,而是通過庫的方式支援,但用庫的方式支援的功能也並不完整,比如僅僅提供協程的建立、銷燬與切換等能力。如果在這樣的輕量級執行緒中呼叫一個同步 IO 操作,比如網路通訊、本地檔案讀寫,都會阻塞其他的併發執行輕量級執行緒,從而無法真正達到輕量級執行緒本身期望達到的目標。
在協程中,呼叫一個任務就像呼叫一個函式一樣,消耗的系統資源最少!但能達到程序、執行緒併發相同的效果。
在一次併發任務中,程序、執行緒、協程均可以實現。從系統資源消耗的角度出發來看,程序相當多,執行緒次之,協程最少。
Go併發
Go 在語言級別支援協程,叫goroutine。Go 語言標準庫提供的所有系統呼叫操作(包括所有同步IO操作),都會出讓CPU給其他goroutine。這讓輕量級執行緒的切換管理不依賴於系統的執行緒和程序,也不需要依賴於CPU的核心數量。
有人把Go比作21世紀的C語言。第一是因為Go語言設計簡單,第二,21世紀最重要的就是並行程式設計,而Go從語言層面就支援並行。同時,併發程式的記憶體管理有時候是非常複雜的,而Go語言提供了自動垃圾回收機制。
Go語言為併發程式設計而內建的上層API基於順序通訊程序模型CSP(communicating sequential processes)。這就意味著顯式鎖都是可以避免的,因為Go通過相對安全的通道傳送和接受資料以實現同步,這大大地簡化了併發程式的編寫。
Go語言中的併發程式主要使用兩種手段來實現。goroutine和channel。
goroutine
什麼是goroutine
goroutine是Go並行設計的核心。goroutine說到底其實就是協程,它比執行緒更小,十幾個goroutine可能體現在底層就是五六個執行緒,Go語言內部幫你實現了這些goroutine之間的記憶體共享。執行goroutine只需極少的棧記憶體(大概是4~5KB),當然會根據相應的資料伸縮。也正因為如此,可同時執行成千上萬個併發任務。goroutine比thread更易用、更高效、更輕便。
一般情況下,一個普通計算機跑幾十個執行緒就有點負載過大了,但是同樣的機器卻可以輕鬆地讓成百上千個goroutine進行資源競爭。
goroutine的建立
只需在函式調⽤語句前新增 go 關鍵字,就可建立併發執⾏單元。開發⼈員無需瞭解任何執⾏細節,排程器會自動將其安排到合適的系統執行緒上執行。
在併發程式設計中,我們通常想將一個過程切分成幾塊,然後讓每個goroutine各自負責一塊工作,當一個程式啟動時,主函式在一個單獨的goroutine中執行,我們叫它main goroutine。新的goroutine會用go語句來建立。而go語言的併發設計,讓我們很輕鬆就可以達成這一目的。
示例程式碼:
package main
import (
"fmt"
"time"
)
func newTask() {
i := 0
for {
i++
fmt.Printf("new goroutine: i = %d\n", i)
time.Sleep(time.Second) //延時1秒
}
}
func main() {
//建立一個goroutine,啟動另外一個任務
go newTask()
//迴圈列印
for i := 0; i < 5; i++ {
fmt.Printf("main goroutine: i = %d\n", i)
time.Sleep(time.Second) //延時1秒
i++
}
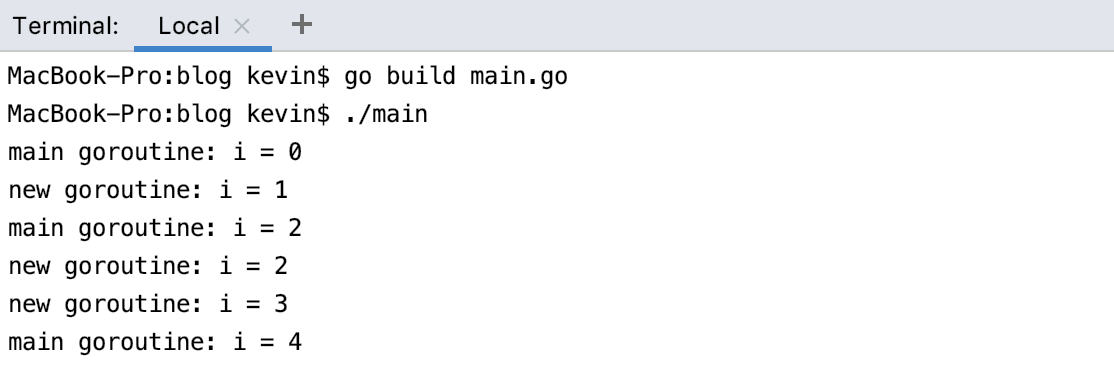
}程式執行結果:
goroutine特性
主goroutine退出後,其它的工作的子goroutine也會自動退出:
可以看出,由於主goroutine(main函式)執行太快了,所以導致newTask還沒執行,程式就退出了
package main
import (
"fmt"
"time"
)
func newTask() {
i := 0
for {
i++
fmt.Printf("new goroutine: i = %d\n", i)
time.Sleep(time.Second) //延時1秒
}
}
func main() {
//建立一個goroutine,啟動另外一個任務
go newTask()
fmt.Println("hello world")
}程式執行結果:

通過執行結果(運行了三次)可以看出來,其中有一次newTask得到了執行,但是也只輸出了一次程式就退出了。另外兩次newTask完全完全沒有執行就退出程式了。
runtime包
Gosched
runtime.Gosched() 用於讓出CPU時間片,讓出當前goroutine的執行許可權,排程器安排其他等待的任務執行,並在下次再獲得cpu時間輪片的時候,從該出讓cpu的位置恢復執行。
有點像跑接力賽,A跑了一會碰到程式碼runtime.Gosched() 就把接力棒交給B了,A歇著了,B繼續跑。
示例程式碼:
package main
import (
"fmt"
"runtime"
)
func main() {
//建立一個goroutine
go func(s string) {
for i := 0; i < 2; i++ {
fmt.Println(s)
}
}("world")
for i := 0; i < 2; i++ {
runtime.Gosched() //import "runtime"包
fmt.Println("hello")
}
/*
遮蔽runtime.Gosched()執行結果如下:
hello
hello
沒有runtime.Gosched()執行結果如下:
world
world
hello
hello
*/
}以上程式的執行過程如下:
主協程進入main()函式,進行程式碼的執行。當執行到go func()匿名函式時,建立一個新的協程,開始執行匿名函式中的程式碼,主協程繼續向下執行,執行到runtime.Gosched( )時會暫停向下執行,直到其它協程執行完後,再回到該位置,主協程繼續向下執行。
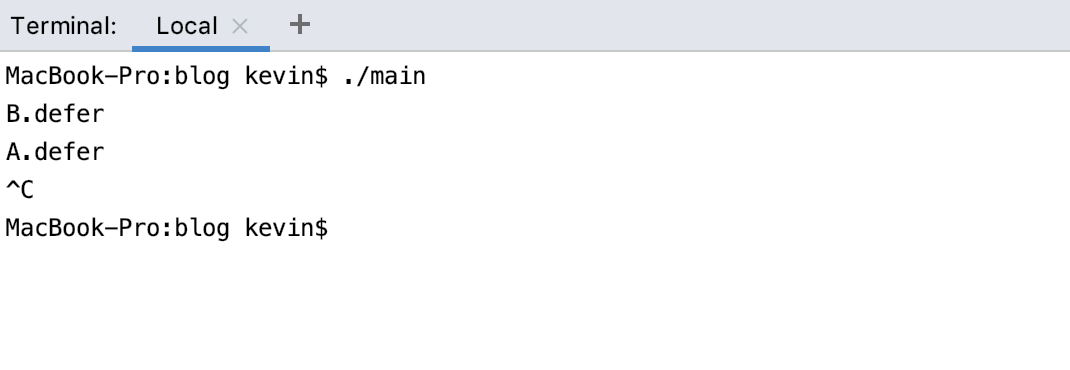
Goexit
呼叫 runtime.Goexit() 將立即終止當前 goroutine 執⾏,排程器確保所有已註冊 defer延遲呼叫被執行。
示例程式碼:
package main
import (
"fmt"
"runtime"
)
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit()//終止當前 goroutine, import "runtime"
fmt.Println("B") //不會執行
}()
fmt.Println("A") //不會執行
}()
//死迴圈,目的不讓主goroutine結束
for {}
}程式執行結果:
GOMAXPROCS
呼叫 runtime.GOMAXPROCS() 用來設定可以平行計算的CPU核數的最大值,並返回之前的值。(預設是跑滿整個CPU)
示例程式碼:
package main
import (
"fmt"
"runtime"
)
func main() {
//n := runtime.GOMAXPROCS(1) //第一次 測試
//列印結果: 111111111111111111111111110000000000000000000000000....
n := runtime.GOMAXPROCS(2) //第二次 測試
//列印結果: 1111111111111111111111110000000000000011111110000100000000111100001111
fmt.Println(n)
for {
go fmt.Print(0)
fmt.Print(1)
}
}在第一次執行runtime.GOMAXPROCS(1) 時,最多同時只能有一個goroutine被執行。所以會列印很多1。過了一段時間後,GO排程器會將其置為休眠,並喚醒另一個goroutine,這時候就開始列印很多0了,在列印的時候,goroutine是被排程到作業系統執行緒上的。
在第二次執行runtime.GOMAXPROCS(2) 時, 我們使用了兩個CPU,所以兩個goroutine可以一起被執行,以同樣的頻率交替列印0和1。
channel
channel是Go語言中的一個核心型別,可以把它看成管道。併發核心單元通過它就可以傳送或者接收資料進行通訊,這在一定程度上又進一步降低了程式設計的難度。
channel是一個數據型別,主要用來解決協程的同步問題以及協程之間資料共享(資料傳遞)的問題。
goroutine執行在相同的地址空間,因此訪問共享記憶體必須做好同步。goroutine 奉行通過通訊來共享記憶體,而不是共享記憶體來通訊。
引⽤型別 channel可用於多個 goroutine 通訊。其內部實現了同步,確保併發安全。
定義channel變數
和map類似,channel也一個對應make建立的底層資料結構的引用。
當我們複製一個channel或用於函式引數傳遞時,我們只是拷貝了一個channel引用,因此呼叫者和被呼叫者將引用同一個channel物件。和其它的引用型別一樣,channel的零值也是nil。
定義一個channel時,也需要定義傳送到channel的值的型別。channel可以使用內建的make()函式來建立:
chan是建立channel所需使用的關鍵字。Type 代表指定channel收發資料的型別。
make(chan Type) //等價於make(chan Type, 0)
make(chan Type, capacity)當我們複製一個channel或用於函式引數傳遞時,我們只是拷貝了一個channel引用,因此呼叫者和被呼叫者將引用同一個channel物件。和其它的引用型別一樣,channel的零值也是nil。
當 引數capacity= 0 時,channel 是無緩衝阻塞讀寫的;當capacity > 0 時,channel 有緩衝、是非阻塞的,直到寫滿 capacity個元素才阻塞寫入。
channel非常像生活中的管道,一邊可以存放東西,另一邊可以取出東西。channel通過操作符 <- 來接收和傳送資料,傳送和接收資料語法:
channel <- value //傳送value到channel
<- channel //取出channel裡的一個值並丟棄
x := <-channel //從channel中接收資料,並賦值給x
x, ok := <-channel //功能同上,同時檢查通道是否已關閉或者是否為空預設情況下,無緩衝的channel接收和傳送資料都是阻塞的,除非另一端已經準備好,這樣就使得goroutine同步變的更加的簡單,而不需要顯式的lock。
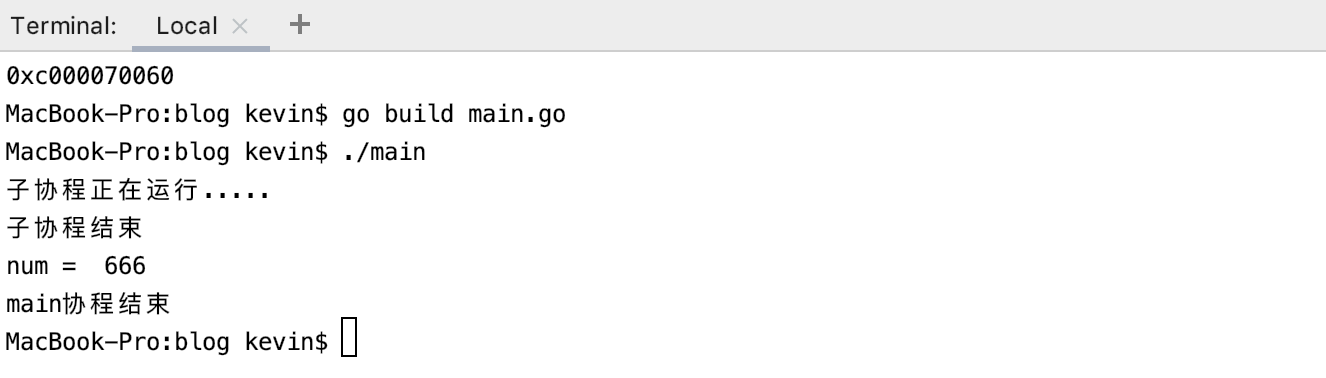
示例程式碼:
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
defer fmt.Println("子協程結束")
fmt.Println("子協程正在執行.....")
c <- 666 //666傳送到c
}()
num := <-c //從c中接收資料,並賦值給num
fmt.Println("num = ", num)
fmt.Println("main協程結束")
}程式執行結果:
無緩衝的channel
無緩衝的通道(unbuffered channel)是指在接收前沒有能力儲存任何值的通道。
這種型別的通道要求傳送goroutine和接收goroutine同時準備好,才能完成傳送和接收操作。否則,通道會導致先執行傳送或接收操作的 goroutine 阻塞等待。
這種對通道進行傳送和接收的互動行為本身就是同步的。其中任意一個操作都無法離開另一個操作單獨存在。
阻塞:由於某種原因資料沒有到達,當前協程(執行緒)持續處於等待狀態,直到條件滿足,才接觸阻塞。
同步:在兩個或多個協程(執行緒)間,保持資料內容一致性的機制。
下圖展示兩個 goroutine 如何利用無緩衝的通道來共享一個值:

- 在第 1 步,兩個 goroutine 都到達通道,但哪個都沒有開始執行傳送或者接收。
- 在第 2 步,左側的 goroutine 將它的手伸進了通道,這模擬了向通道傳送資料的行為。這時,這個 goroutine 會在通道中被鎖住,直到交換完成。
- 在第 3 步,右側的 goroutine 將它的手放入通道,這模擬了從通道里接收資料。這個 goroutine 一樣也會在通道中被鎖住,直到交換完成。
- 在第 4 步和第 5 步,進行交換,並最終,在第 6 步,兩個 goroutine 都將它們的手從通道里拿出來,這模擬了被鎖住的 goroutine 得到釋放。兩個 goroutine 現在都可以去做別的事情了。
無緩衝的channel建立格式:
make(chan Type) //等價於make(chan Type, 0)如果沒有指定緩衝區容量,那麼該通道就是同步的,因此會阻塞到傳送者準備好傳送和接收者準備好接收。
示例程式碼:
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan int, 0) //建立無緩衝的通道c
//內建函式len返回未被讀取的緩衝元素數量,cap返回緩衝區大小
fmt.Printf("len(c) = %d, cap(c) = %d\n", len(c), cap(c))
go func() {
defer fmt.Println("子協程結束")
for i := 0; i < 3; i++ {
c <- i
fmt.Printf("子協程正在執行[%d]: len(c) = %d, cap(c) = %d\n", i, len(c), cap(c))
}
}()
time.Sleep(time.Second * 2) //延時2s
for i := 0; i < 3; i++ {
num := <-c //從c中接收資料,並複製給num
fmt.Printf("num = %d\n", num)
}
fmt.Println("main協程結束")
}
有緩衝的channel
有緩衝的通道(buffered channel)是一種在被接收前能儲存一個或者多個數據值的通道。
這種型別的通道並不強制要求 goroutine 之間必須同時完成傳送和接收。通道會阻塞傳送和接收動作的條件也不同。
只有通道中沒有可以接收的值時,接收動作才會阻塞。
只有通道沒有可用緩衝區容納被髮送的值時,傳送動作才會阻塞。
這導致有緩衝的通道和無緩衝的通道之間的一個很大的不同:無緩衝的通道保證進行傳送和接收的 goroutine 會在同一時間進行資料交換;有緩衝的通道沒有這種保證。
示例如下:
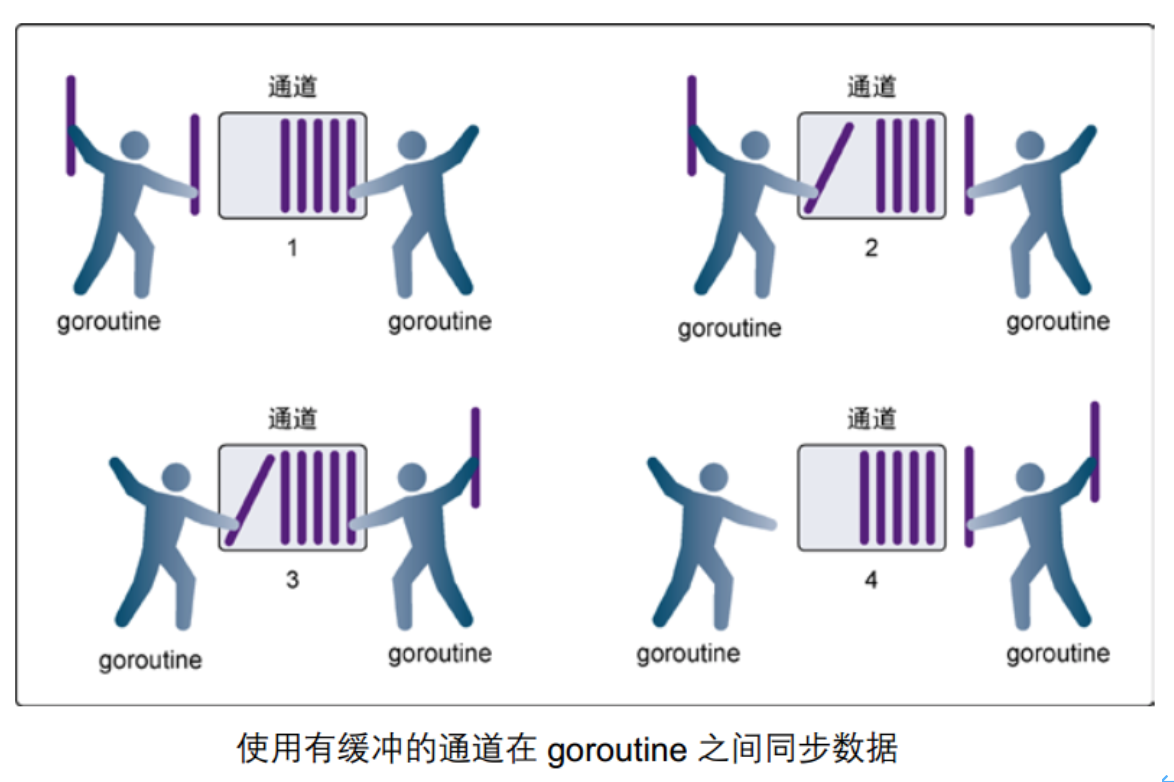
- 在第 1 步,右側的 goroutine 正在從通道接收一個值。
- 在第 2 步,右側的這個 goroutine獨立完成了接收值的動作,而左側的 goroutine 正在傳送一個新值到通道里。
- 在第 3 步,左側的goroutine 還在向通道傳送新值,而右側的 goroutine 正在從通道接收另外一個值。這個步驟裡的兩個操作既不是同步的,也不會互相阻塞。
- 最後,在第 4 步,所有的傳送和接收都完成,而通道里還有幾個值,也有一些空間可以存更多的值。
有緩衝的channel建立格式:
make(chan Type, capacity)如果給定了一個緩衝區容量,通道就是非同步的。只要緩衝區有未使用空間用於傳送資料,或還包含可以接收的資料,那麼其通訊就會無阻塞地進行。
示例程式碼:
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan int, 3) //建立無緩衝的通道c
//內建函式len返回未被讀取的緩衝元素數量,cap返回緩衝區大小
fmt.Printf("len(c) = %d, cap(c) = %d\n", len(c), cap(c))
go func() {
defer fmt.Println("子協程結束")
for i := 0; i < 3; i++ {
c <- i
fmt.Printf("子協程正在執行[%d]: len(c) = %d, cap(c) = %d\n", i, len(c), cap(c))
}
}()
time.Sleep(time.Second * 2) //延時2s
for i := 0; i < 3; i++ {
num := <-c //從c中接收資料,並複製給num
fmt.Printf("num = %d\n", num)
}
fmt.Println("main協程結束")
}
關閉channel
如果傳送者知道,沒有更多的值需要傳送到channel的話,那麼讓接收者也能及時知道沒有多餘的值可接收將是有用的,因為接收者可以停止不必要的接收等待。這可以通過內建的close函式來關閉channel實現。
示例程式碼:
注意:
- channel不像檔案一樣需要經常去關閉,只有當你確實沒有任何傳送資料了,或者你想顯式的結束range迴圈之類的,才去關閉channel;
- 關閉channel後,無法向channel 再發送資料(引發 panic 錯誤後導致接收立即返回channel型別的零值);
- 關閉channel後,可以繼續從channel接收資料;
- 對於nil channel,無論收發都會被阻塞。
可以使用 range 來迭代不斷操作channel:
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
//把close(c)註釋掉,程式會死鎖
//close(c)
}()
for {
//ok為true說明channel沒有關閉,為false說明channel已經關閉
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("main協程結束")
}單向channel
有的時候我們會將通道作為引數在多個任務函式間傳遞,很多時候我們在不同的任務函式中使用通道都會對其進行限制,比如限制通道在函式中只能傳送或只能接收。
Go語言中提供了單向通道來處理這種情況。例如,我們把上面的例子改造如下:
package main
import (
"fmt"
)
func counter(in chan<- int) {
for i := 0; i < 100; i++ {
in <- i
}
close(in)
}
func squarer(in chan<- int, out <-chan int) {
for i := range out {
in <- i * i
}
close(in)
}
func printer(in <-chan int) {
for i := range in {
fmt.Println(i)
}
}
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go counter(ch1)
go squarer(ch2, ch1)
printer(ch2)
}其中
chan<- int是一個只能傳送的通道,可以傳送但是不能接收;<-chan int是一個只能接收的通道,可以接收但是不能傳送。
在函式傳參及任何賦值操作中將雙向通道轉換為單向通道是可以的,但反過來是不可以的。
channel總結

定時器
time.Timer
Timer是一個定時器,代表未來的一個單一事件,你可以告訴timer你需要等待多長事件,它提供一個channel,在將來的那個時間那個channel提供了一個時間值。

它提供一個channel,在定時時間到達之前,沒有資料寫入timer.C會一直阻塞。直到定時時間到,向channel寫入值,阻塞解除,可以從中讀取資料。
示例程式碼:
package main
import (
"fmt"
"time"
)
func main() {
//建立定時器,2秒後,定時器就會向自己的C欄位傳送一個time.Time型別的元素值
timer1 := time.NewTimer(time.Second * 2)
t1 := time.Now() //當前時間
fmt.Printf("t1: %v\n", t1)
t2 := <-timer1.C
fmt.Printf("t2: %v\n", t2)
//如果只是想單純的等待的話,可以使用time.Sleep來實現
timer2 := time.NewTimer(time.Second * 2)
<-timer2.C
fmt.Println("2s後")
time.Sleep(time.Second * 2)
fmt.Println("再一次2s後")
<-time.After(time.Second * 2)
fmt.Println("再再一次2s後")
timer3 := time.NewTimer(time.Second)
go func() {
<-timer3.C
fmt.Println("Timer 3 expired")
}()
stop := timer3.Stop() //停止定時器
if stop {
fmt.Println("Timer 3 stopped")
}
fmt.Println("before")
timer4 := time.NewTimer(time.Second * 5) //原來設定5秒
timer4.Reset(time.Second * 1) //重新設定時間
<-timer4.C
fmt.Println("after")
}定時器的常用操作:
- 實現延遲功能
(1) <-time.After(time.Second * 2) //定時2s,阻塞2s, 2s後產生一個事件,往channel寫內容
fmt.Println("時間到") (2) time.Sleep(time.Second * 2)
fmt.Println("時間到")(3) 延時2s後列印一句話
timer := time.NewTimer(time.Second * 2)
<-timer.C
fmt.Println("時間到") 定時器停止
timer := time.NewTimer(time.Second * 3) go func() { <-timer.C fmt.Println("子協程可以列印了,因為定時器的時間到") }() timer.Stop() //停止定時器 for { }定時器重置
timer := time.NewTimer(3 * time.Second) ok := timer.Reset(1 * time.Second) //重新設定為1s fmt.Println("ok = ", ok) <-timer.C fmt.Println("時間到")
time.Ticker
Ticker是一個定時觸發的計時器,它會以一個間隔(interval)往channel傳送一個事件(當前時間),而channel的接受者可以以固定的時間間隔從channel中讀取事件。

示例程式碼:
package main
import (
"fmt"
"time"
)
func main() {
//建立定時器,每隔1s後,定時器就會給channel傳送一個事件(當前時間)
ticker := time.NewTicker(1 * time.Second)
go func() {
i := 0
for { //迴圈
<-ticker.C
i++
fmt.Println("i =", i)
if i == 5 {
ticker.Stop() //停止定時器
}
}
}()
//死迴圈,特地不讓main goroutine結束
for {
}
}select
select作用
Go裡面提供了一個關鍵字select,通過select可以監聽channel上的資料流動。
select的用法與switch語言非常類似,由select開始一個新的選擇塊,每個選擇條件由case語句來描述。
與switch語句相比, select有比較多的限制,其中最大的一條限制就是每個case語句裡必須是一個IO操作,大致的結構如下:
select {
case <-chan1:
// 如果chan1成功讀到資料,則進行該case處理語句
case chan2 <- 1:
// 如果成功向chan2寫入資料,則進行該case處理語句
default:
// 如果上面都沒有成功,則進入default處理流程
}在一個select語句中,Go語言會按順序從頭至尾評估每一個傳送和接收的語句。
如果其中的任意一語句可以繼續執行(即沒有被阻塞),那麼就從那些可以執行的語句中任意選擇一條來使用。
如果沒有任意一條語句可以執行(即所有的通道都被阻塞),那麼有兩種可能的情況:
- 如果給出了default語句,那麼就會執行default語句,同時程式的執行會從select語句後的語句中恢復。
- 如果沒有default語句,那麼select語句將被阻塞,直到至少有一個通訊可以進行下去。
示例程式碼:
package main
import "fmt"
func fibonacci(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <-x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 6; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}執行結果如下:
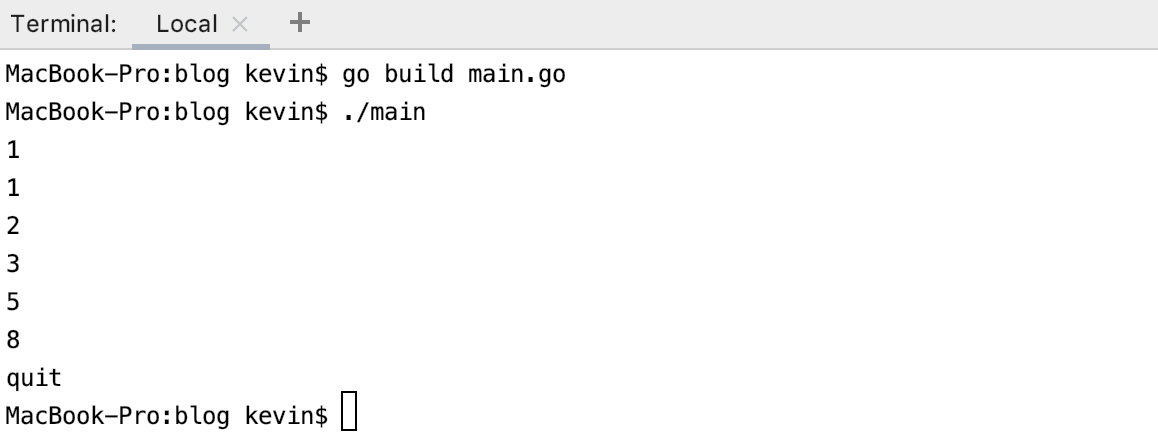
示例2:
package main
import "fmt"
func main() {
var ch = make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch:
fmt.Println(x)
case ch <- i:
}
}
}使用select語句能提高程式碼的可讀性。
- 可處理一個或多個channel的傳送/接收操作。
- 如果多個
case同時滿足,select會隨機選擇一個。 - 對於沒有
case的select{}會一直等待,可用於阻塞main函式。
超時
有時候會出現goroutine阻塞的情況,那麼我們如何避免整個程式進入阻塞的情況呢?我們可以利用select來設定超時,通過如下的方式實現:
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan int)
o := make(chan bool)
go func() {
for {
select {
case v := <-c:
fmt.Println(v)
case <-time.After(5 * time.Second):
fmt.Println("timeout")
o <- true
break
}
}
}()
//c <- 666 //註釋掉,引發timeout
<-o
}鎖
前面我們為了解決協程同步的問題我們使用了channel,但是GO也提供了傳統的同步工具。
它們都在GO的標準庫程式碼包sync和sync/atomic中。
什麼是鎖呢?就是某個協程(執行緒)在訪問某個資源時先鎖住,防止其它協程的訪問,等訪問完畢解鎖後其他協程再來加鎖進行訪問。這和我們生活中加鎖使用公共資源相似,例如:公共衛生間。
死鎖
死鎖是指兩個或兩個以上的程序在執行過程中,由於競爭資源或者由於彼此通訊而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去。此時稱系統處於死鎖狀態或系統產生了死鎖
示例程式碼:
package main
import "fmt"
func main() {
ch := make(chan int)
ch <- 1 // I'm blocked because there is no channel read yet.
fmt.Println("send")
go func() {
<-ch // I will never be called for the main routine is blocked!
fmt.Println("received")
}()
fmt.Println("over")
}互斥鎖
每個資源都對應於一個可稱為 "互斥鎖" 的標記,這個標記用來保證在任意時刻,只能有一個協程(執行緒)訪問該資源。其它的協程只能等待。
互斥鎖是傳統併發程式設計對共享資源進行訪問控制的主要手段,它由標準庫sync中的Mutex結構體型別表示。sync.Mutex型別只有兩個公開的指標方法,Lock和Unlock。Lock鎖定當前的共享資源,Unlock進行解鎖。
在使用互斥鎖時,一定要注意:對資源操作完成後,一定要解鎖,否則會出現流程執行異常,死鎖等問題。
有時候在Go程式碼中可能會存在多個goroutine同時操作一個資源(臨界區),這種情況會發生競態問題(資料競態)。類比現實生活中的例子有十字路口被各個方向的的汽車競爭;還有火車上的衛生間被車廂裡的人競爭。
舉個例子:
package main
import (
"fmt"
"sync"
)
var (
x int64
wg sync.WaitGroup
)
func add() {
defer wg.Done()
for i := 0; i < 5000; i++ {
x = x + 1
}
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}上面的程式碼中我們開啟了兩個goroutine去累加變數x的值,這兩個goroutine在訪問和修改x變數的時候就會存在資料競爭,導致最後的結果與期待的不符。
互斥鎖是一種常用的控制共享資源訪問的方法,它能夠保證同時只有一個goroutine可以訪問共享資源。Go語言中使用sync包的Mutex型別來實現互斥鎖。 使用互斥鎖來修復上面程式碼的問題:
package main
import (
"fmt"
"sync"
)
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
)
func add() {
defer wg.Done()
for i := 0; i < 5000; i++ {
lock.Lock() //加鎖
x = x + 1
lock.Unlock() //解鎖
}
}
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}使用互斥鎖能夠保證同一時間有且只有一個goroutine進入臨界區,其他的goroutine則在等待鎖;當互斥鎖釋放後,等待的goroutine才可以獲取鎖進入臨界區,多個goroutine同時等待一個鎖時,喚醒的策略是隨機的。
讀寫鎖
互斥鎖的本質是當一個goroutine訪問的時候,其他goroutine都不能訪問。這樣在資源同步,避免競爭的同時也降低了程式的併發效能。程式由原來的並行執行變成了序列執行。
其實,當我們對一個不會變化的資料只做“讀”操作的話,是不存在資源競爭的問題的。因為資料是不變的,不管怎麼讀取,多少goroutine同時讀取,都是可以的。
所以問題不是出在“讀”上,主要是修改,也就是“寫”。修改的資料要同步,這樣其他goroutine才可以感知到。所以真正的互斥應該是讀取和修改、修改和修改之間,讀和讀是沒有互斥操作的必要的。
因此,衍生出另外一種鎖,叫做讀寫鎖。
讀寫鎖可以讓多個讀操作併發,同時讀取,但是對於寫操作是完全互斥的。也就是說,當一個goroutine進行寫操作的時候,其他goroutine既不能進行讀操作,也不能進行寫操作。
GO中的讀寫鎖由結構體型別sync.RWMutex表示。此型別的方法集合中包含兩對方法:
一組是對寫操作的鎖定和解鎖,簡稱“寫鎖定”和“寫解鎖”:
func (*RWMutex)Lock()
func (*RWMutex)Unlock()另一組表示對讀操作的鎖定和解鎖,簡稱為“讀鎖定”與“讀解鎖”:
func (*RWMutex)RLock()
func (*RWMutex)RUlock()讀寫鎖基本示例:
package main
import (
"fmt"
"sync"
"time"
)
var (
x int64
wg sync.WaitGroup
rwlock sync.RWMutex
)
func write() {
defer wg.Done()
rwlock.Lock() //加寫鎖
x = x + 1
time.Sleep(time.Millisecond * 10) //假設寫操作耗時10毫秒
rwlock.Unlock() //解寫鎖
}
func read() {
defer wg.Done()
rwlock.RLock() //加讀鎖
time.Sleep(time.Millisecond) //假設讀操作耗時一毫秒
rwlock.RUnlock() //解讀鎖
}
func main() {
var start = time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
var end = time.Now()
fmt.Println(end.Sub(start))
}我們在read裡使用讀鎖,也就是RLock和RUnlock,寫鎖的方法名和我們平時使用的一樣,是Lock和Unlock。這樣,我們就使用了讀寫鎖,可以併發地讀,但是同時只能有一個寫,並且寫的時候不能進行讀操作。
需要注意的是讀寫鎖非常適合讀多寫少的場景,如果讀和寫的操作差別不大,讀寫鎖的優勢就發揮不出來。
總結:讀寫鎖控制下的多個寫操作之間都是互斥的,並且寫操作與讀操作之間也都是互斥的。但是,多個讀操作之間不存在互斥關係。
從互斥鎖和讀寫鎖的原始碼可以看出,它們是同源的。讀寫鎖的內部用互斥鎖來實現寫鎖定操作之間的互斥。可以把讀寫鎖看作是互斥鎖的一種擴充套件。
sync.WaitGroup
在程式碼中生硬的使用time.Sleep肯定是不合適的,Go語言中可以使用sync.WaitGroup來實現併發任務的同步。 sync.WaitGroup有以下幾個方法:
| 方法名 | 功能 |
|---|---|
| (wg *WaitGroup) Add(delta int) | 計數器+delta |
| (wg *WaitGroup) Done() | 計數器-1 |
| (wg *WaitGroup) Wait() | 阻塞直到計數器變為0 |
sync.WaitGroup內部維護著一個計數器,計數器的值可以增加和減少。例如當我們啟動了N 個併發任務時,就將計數器值增加N。每個任務完成時通過呼叫Done()方法將計數器減1。通過呼叫Wait()來等待併發任務執行完,當計數器值為0時,表示所有併發任務已經完成。
我們利用sync.WaitGroup將上面的程式碼優化一下:
package main
import (
"fmt"
"sync"
)
func sayHello(wg *sync.WaitGroup) {
defer wg.Done()
fmt.Println("Hello")
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1)
go sayHello(&wg)
}
fmt.Println("main goroutine done!")
wg.Wait()
}需要注意sync.WaitGroup是一個結構體,傳遞的時候要傳遞指標。
sync.Once
說在前面的話:這是一個進階知識點。
在程式設計的很多場景下我們需要確保某些操作在高併發的場景下只執行一次,例如只加載一次配置檔案、只關閉一次通道等。
Go語言中的sync包中提供了一個針對只執行一次場景的解決方案–sync.Once。
sync.Once只有一個Do方法,其簽名如下:
func (o *Once) Do(f func()) {}備註:如果要執行的函式f需要傳遞引數就需要搭配閉包來使用。
載入配置檔案示例
延遲一個開銷很大的初始化操作到真正用到它的時候再執行是一個很好的實踐。因為預先初始化一個變數(比如在init函式中完成初始化)會增加程式的啟動耗時,而且有可能實際執行過程中這個變數沒有用上,那麼這個初始化操作就不是必須要做的。我們來看一個例子:
var icons map[string]image.Image
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 被多個goroutine呼叫時不是併發安全的
func Icon(name string) image.Image {
if icons == nil {
loadIcons()
}
return icons[name]
}多個goroutine併發呼叫Icon函式時不是併發安全的,現代的編譯器和CPU可能會在保證每個goroutine都滿足序列一致的基礎上自由地重排訪問記憶體的順序。loadIcons函式可能會被重排為以下結果:
func loadIcons() {
icons = make(map[string]image.Image)
icons["left"] = loadIcon("left.png")
icons["up"] = loadIcon("up.png")
icons["right"] = loadIcon("right.png")
icons["down"] = loadIcon("down.png")
}在這種情況下就會出現即使判斷了icons不是nil也不意味著變數初始化完成了。考慮到這種情況,我們能想到的辦法就是新增互斥鎖,保證初始化icons的時候不會被其他的goroutine操作,但是這樣做又會引發效能問題。
使用sync.Once改造的示例程式碼如下:
var icons map[string]image.Image
var loadIconsOnce sync.Once
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 是併發安全的
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)
return icons[name]
}併發安全的單利模式
下面是藉助sync.Once實現的併發安全的單例模式:
package main
import "sync"
type singleton struct{}
var (
instance *singleton
once sync.Once
)
func GetInstance() *singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}sync.Once其實內部包含一個互斥鎖和一個布林值,互斥鎖保證布林值和資料的安全,而布林值用來記錄初始化是否完成。這樣設計就能保證初始化操作的時候是併發安全的並且初始化操作也不會被執行多次。
sync.Map
Go語言中內建的map不是併發安全的。請看下面的示例:
package main
import (
"fmt"
"strconv"
"sync"
)
var m = make(map[string]int)
func get(key string) int {
return m[key]
}
func set(key string, value int) {
m[key] = value
}
func main() {
var wg = sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
key := strconv.Itoa(n)
set(key, n)
fmt.Printf("k: %v, v: %v\n", key, get(key))
}(i)
}
wg.Wait()
}上面的程式碼開啟少量幾個goroutine的時候可能沒什麼問題,當併發多了之後執行上面的程式碼就會報fatal error: concurrent map writes錯誤。
像這種場景下就需要為map加鎖來保證併發的安全性了,Go語言的sync包中提供了一個開箱即用的併發安全版map–sync.Map。開箱即用表示不用像內建的map一樣使用make函式初始化就能直接使用。同時sync.Map內建了諸如Store、Load、LoadOrStore、Delete、Range等操作方法。
package main
import (
"fmt"
"strconv"
"sync"
)
func main() {
var m = sync.Map{}
var wg = sync.WaitGroup{}
for i := 0; i < 40; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
key := strconv.Itoa(n)
m.Store(key, n)
value, _ := m.Load(key)
fmt.Printf("k: %v, v: %v\n", key, value)
}(i)
}
wg.Wait()
}原子操作
程式碼中的加鎖操作因為涉及核心態的上下文切換會比較耗時、代價比較高。針對基本資料型別我們還可以使用原子操作來保證併發安全,因為原子操作是Go語言提供的方法它在使用者態就可以完成,因此效能比加鎖操作更好。Go語言中原子操作由內建的標準庫sync/atomic提供。
atomic包
| 方法 | 解釋 |
|---|---|
| func LoadInt32(addr int32) (val int32) func LoadInt64(addr int64) (val int64) func LoadUint32(addr uint32) (val uint32) func LoadUint64(addr uint64) (val uint64) func LoadUintptr(addr uintptr) (val uintptr) func LoadPointer(addr unsafe.Pointer) (val unsafe.Pointer) |
讀取操作 |
| func StoreInt32(addr int32, val int32) func StoreInt64(addr int64, val int64) func StoreUint32(addr uint32, val uint32) func StoreUint64(addr uint64, val uint64) func StoreUintptr(addr uintptr, val uintptr) func StorePointer(addr unsafe.Pointer, val unsafe.Pointer) |
寫入操作 |
| func AddInt32(addr int32, delta int32) (new int32) func AddInt64(addr int64, delta int64) (new int64) func AddUint32(addr uint32, delta uint32) (new uint32) func AddUint64(addr uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) |
修改操作 |
| func SwapInt32(addr int32, new int32) (old int32) func SwapInt64(addr int64, new int64) (old int64) func SwapUint32(addr uint32, new uint32) (old uint32) func SwapUint64(addr uint64, new uint64) (old uint64) func SwapUintptr(addr uintptr, new uintptr) (old uintptr) func SwapPointer(addr unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) |
交換操作 |
| func CompareAndSwapInt32(addr int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) |
比較並交換操作 |
示例
我們通過一個示例來比較下互斥鎖和原子操作的效能。
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
type Counter interface {
Inc()
Load() int64
}
//普通版
type NormalCounter struct {
x int64
}
func (normal *NormalCounter) Inc() {
normal.x++
}
func (normal *NormalCounter) Load() int64 {
return normal.x
}
//互斥鎖版
type MutexCounter struct {
x int64
lock sync.Mutex
}
func (m *MutexCounter) Inc () {
m.lock.Lock()
m.x++
m.lock.Unlock()
}
func (m *MutexCounter) Load() int64 {
m.lock.Lock()
defer m.lock.Unlock()
return m.x
}
//原子操作版
type AtomicCounter struct {
x int64
}
func (a *AtomicCounter) Inc() {
atomic.AddInt64(&a.x, 1)
}
func (a *AtomicCounter) Load() int64 {
return atomic.LoadInt64(&a.x)
}
func test(c Counter) {
var wg sync.WaitGroup
var start = time.Now()
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
c.Inc()
}()
}
wg.Wait()
var end = time.Now()
fmt.Printf("執行用時: %v, 結果為: %v\n", end.Sub(start), c.Load())
}
func main() {
var c1 = NormalCounter{} // 非併發安全
test(&c1)
var c2 = MutexCounter{} // 使用互斥鎖實現併發安全
test(&c2)
var c3 = AtomicCounter{} // 併發安全且比互斥鎖效率更高
test(&c3)
}
atomic包提供了底層的原子級記憶體操作,對於同步演算法的實現很有用。這些函式必須謹慎地保證正確使用。除了某些特殊的底層應用,使用通道或者sync包的函式/型別實現同步更好