
不懂Neo4j?沒關係,先學增刪改查
從上篇文章中我們瞭解到了什麼是Neo4j、為什麼要用Neo4j、什麼場景使用 以及怎麼安裝,如果您還不想熟悉,點選此處,傳送過去哦~
既然Neo4j是一個圖資料庫,那麼毫無疑問,增刪改查是必不可少的,這篇文章,我們就一起學習下Neo4j對節點以及關係的基本操作。
首先我們開啟Neo4j的瀏覽器控制檯(http://xxx.xxx.xxx.xxx:7474/browser),使用者名稱是neo4j,預設密碼也是 neo4j,如果你已經了密碼,那麼,就輸入你修改的密碼即可。登陸進去我們會看到如下的介面的,
沒錯,就是在大家最喜歡的美元符號那裡輸入 CQL語句的。這裡我們拿學生和老師舉例來說明。
一、增加節點
Neo4j使用的是create 命令進行增加,就類似與MySQL中的insert。
1.建立一個學生節點(只有節點,沒有屬性):
create (s:Student)在美元符號輸入完上面的CQL後,回車 或者 點選右側的三角號執行按鈕,會看到如下結果:
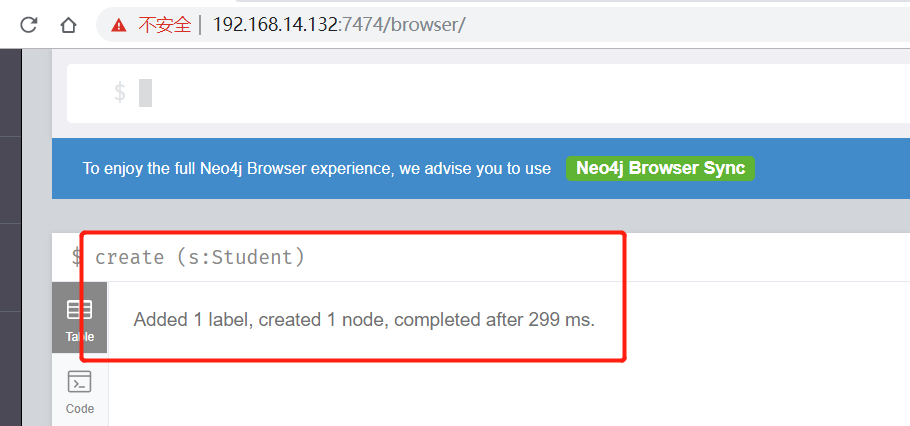
這說明我們已經建立完了學生節點。
不難看出 create 的語法如下:
create (<node-name>:<label-name>)- node-name:它是我們要建立的節點名稱
- label-name:它是我們要建立的標籤名稱
2.建立一個學生節點(建立具有屬性的節點)
建立一個id為10000,名字為張三,年齡為18歲,性別為男的學生節點
create (s:Student{id:10000, name:"張三",age:18,sex:1}) 執行後,會看到如下的結果:
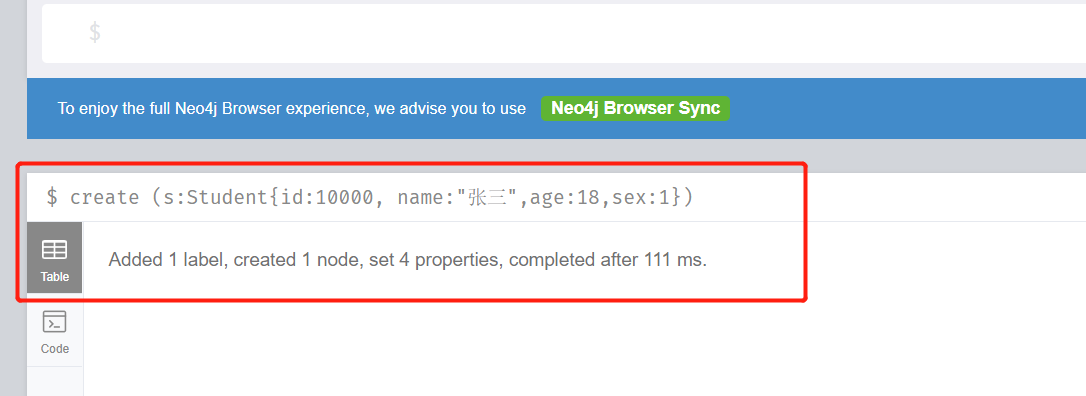
這說明我們建立了一個具有id,name,age,sex四個屬性的s節點。
不難理解,id、name、age、sex,就類似我們MySQL中 表中的欄位一樣。
建立帶屬性的節點語法如下:
create (<node-name>:<label-name> { <property1-name>:<property1-Value>, <property2-name>:<property2-Value>, ..., <property3-name>:<property3-Value> })
property1-name就是屬性名稱,property1-Value就是屬性值。
二、查詢
我們在上一步建立了沒有屬性的節點和有屬性的節點,那麼問題來了,我們怎麼檢視呢?查詢咯~
Neo4j使用的是match ... return ... 命令進行查詢,就類似與MySQL中的select。
我們查詢剛剛建立的節點資訊。
1.全部查詢學生
match (s:Student) return s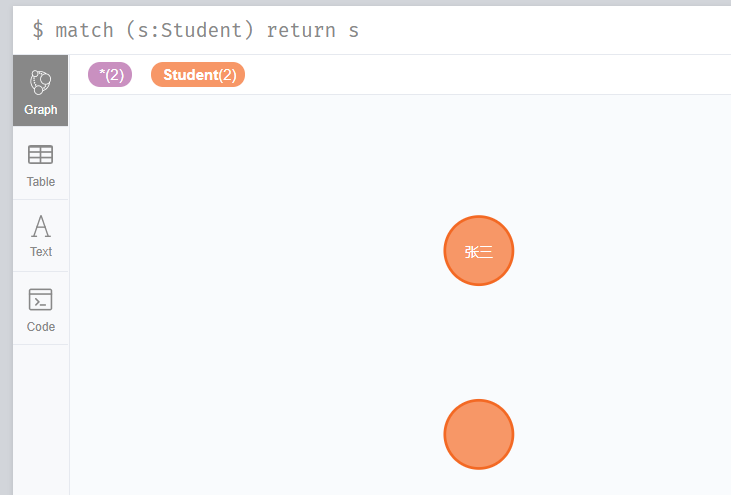
從上圖可以看到我們剛剛建立的兩個節點,一個是沒有屬性節點,一個是有屬性的節點。兩個節點是以圖的形式展示,我們也可以切換左邊的Graph(圖)、Table(表格)、Text(文字)等來以不同的形式展示。
2.查詢全部或者部分欄位
只需要把要展示的欄位以節點名 + 點號 + 屬性欄位 拼接即可,如下:
match (s:Student) return s.id,s.name,s.age,s.sex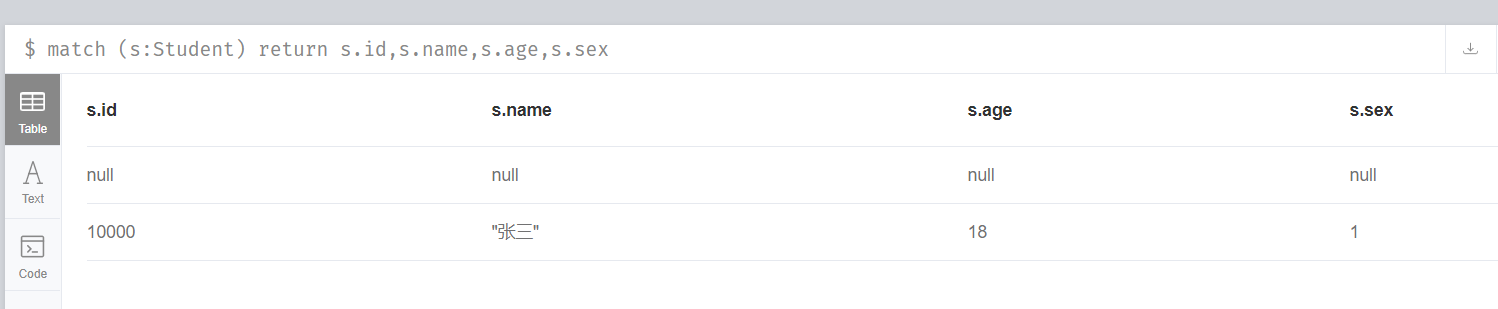
這樣就清楚的看到我們插入的學生屬性資訊。因為有一個是沒有屬性的節點,所以表格中第2行顯示的各個值都是null。
3.查詢滿足年齡age等於18的學生資訊
match (s:Student) where s.age=18 return s.id,s.name,s.age,s.sex
怎麼樣,這條件查詢 是不是和MySQL的很相似。當然還有排序、分組、聯合、分頁等。為了能更好的演示這幾種,我們先插入一部分資料,逐條插入:
create (s:Student{id:10001, name:"李四",age:18,sex:1}) return s
create (s:Student{id:10002, name:"王五",age:19,sex:1}) return s
create (s:Student{id:10003, name:"趙六",age:20,sex:1}) return s
create (s:Student{id:10004, name:"周七",age:17,sex:0}) return s
create (s:Student{id:10005, name:"孫八",age:23,sex:1}) return s
create (s:Student{id:10006, name:"吳九",age:15,sex:1}) return s
create (s:Student{id:10007, name:"鄭十",age:19,sex:0}) return s
create (s:Student{id:10008, name:"徐十一",age:18,sex:1}) return s
create (s:Student{id:10009, name:"朱十二",age:21,sex:1}) return s
create (s:Student{id:10010, name:"譚十三",age:22,sex:1}) return s 這個我們在create 的語句後面加上了return,意思就是我插入完你要把資料返回給我看下,如下:
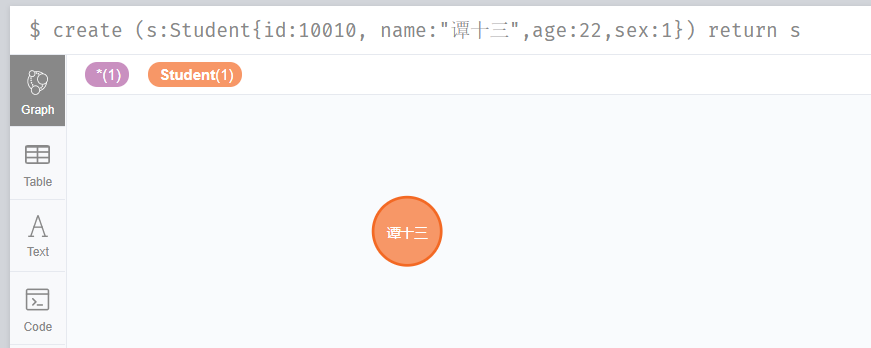
這樣,我們的資料就造好了,我們可以先查詢全部的看下:
match (s:Student) return s.id,s.name,s.age,s.sex
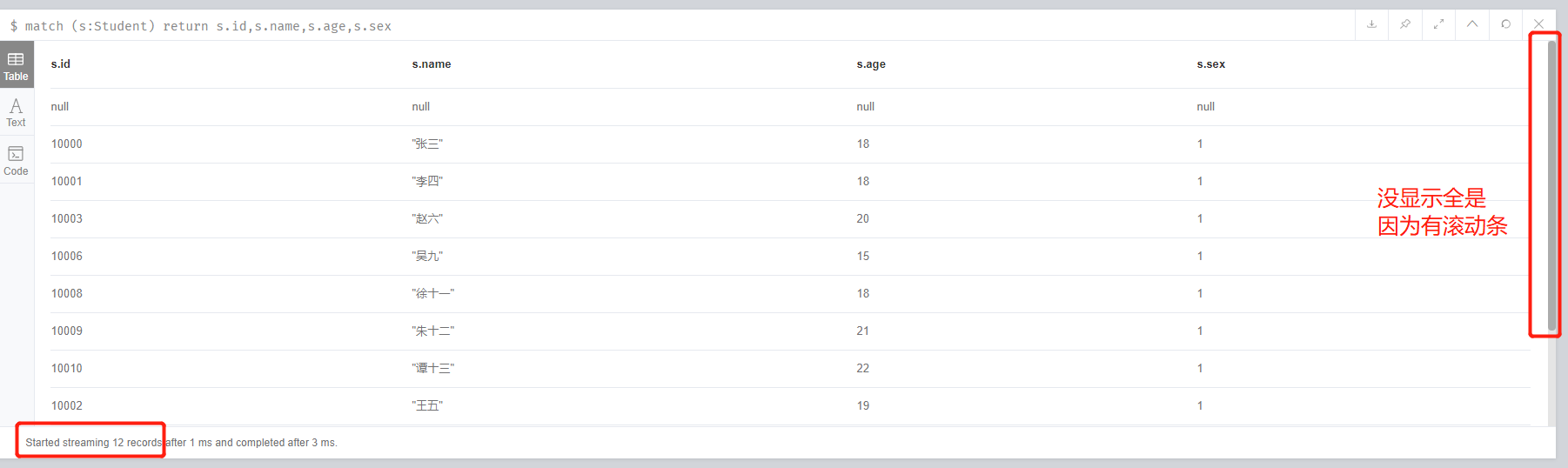
上圖的左下角我們可以看到一共有12條資料。一條沒有屬性的 + 11條有屬性的。
4.查詢出所有的男生(sex=1)並按年齡倒敘排序
match (s:Student) where s.sex=1 return s.id,s.name,s.age,s.sex order by s.age desc
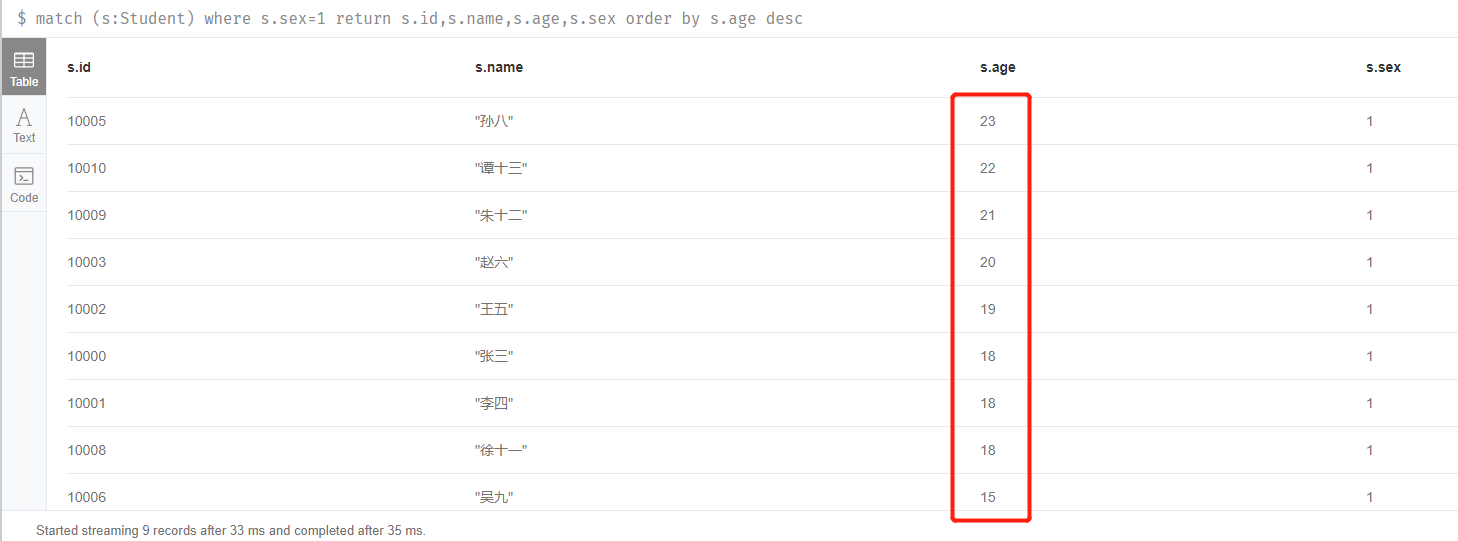
很清晰,是以age倒敘排序的。
5.查詢出名字不為null,且按性別分組
這裡要注意一點,CQL中的分組和SQL是有所差異的,在CQL中不用顯式的寫group by分組欄位,由直譯器自動決定:即未加聚合函式的欄位自動決定為分組欄位。
match (s:Student) where s.name is not null return s.sex,count(*)

不難看出,上面是按sex欄位分組的。
6.union聯合查詢(查詢性別為男或者女的,且年齡為19歲的學生)
match (s:Student) where s.sex=1 and s.age=19 return s.id,s.name,s.sex,s.age
union
match (s:Student) where s.sex=0 and s.age=19 return s.id,s.name,s.sex,s.age

有union,當然也有 union all,這兩個的區別和SQL中也是一樣的。
- union:對兩個結果集進行並集操作,不包括重複行;
- union all:對兩個結果集進行並集操作,包括重複行;
7.分頁查詢(每頁4條,查詢第3頁的資料)
match (s:Student) return s.id,s.name,s.sex,s.age skip 8 limit 4
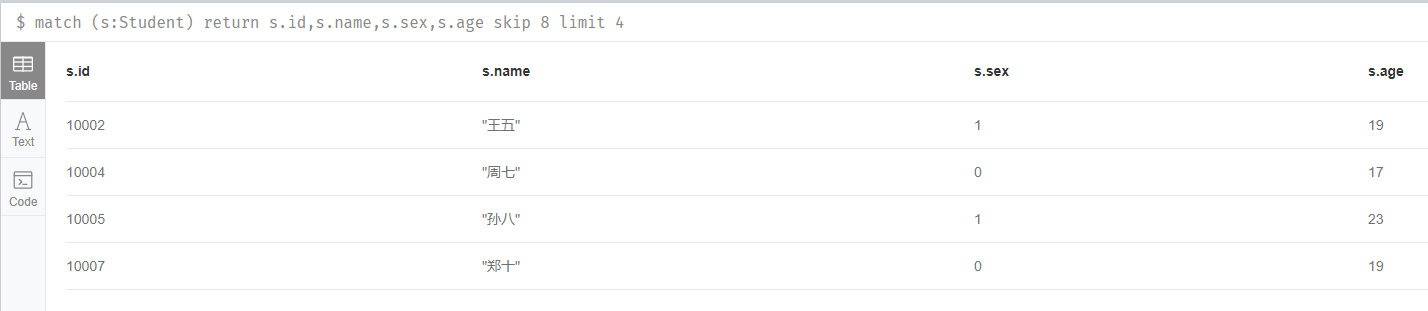
上面CQL中的skip表示跳過多少條,limit表示獲取多少條。每頁4條,查詢第三頁的資料,也就是跳過前8條,查詢4條,或者說從第8條開始,不包括第8條,然後再查詢4條。
8.in操作(查詢id為10001和10005的兩個資料)
match (s:Student) where s.id in [10001,10005] return s.id,s.name,s.sex,s.age

需要注意的是,這裡 用的是中括號,和SQL中是有區別的。
三、增加關係
上面我們介紹了增加單個節點和查詢的知識點。這裡我們介紹下增加關係。為了存在關係,我們先建立一個老師節點。
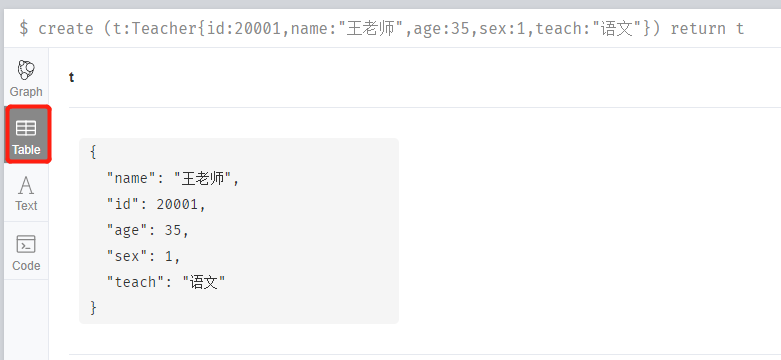
建立一個教語文的年齡為35歲的男的王老師:
create (t:Teacher{id:20001,name:"王老師",age:35,sex:1,teach:"語文"}) return t
1.假設王老師所教的班級有3個學生:張三、李四、王五,這裡我們就要建立王老師 和 3個學生的關係,注意,這裡是為兩個現有節點建立關係。
match (t:Teacher),(s:Student) where t.id=20001 and s.id=10000
create (t)-[teach:Teach]->(s)
return t,teach,s
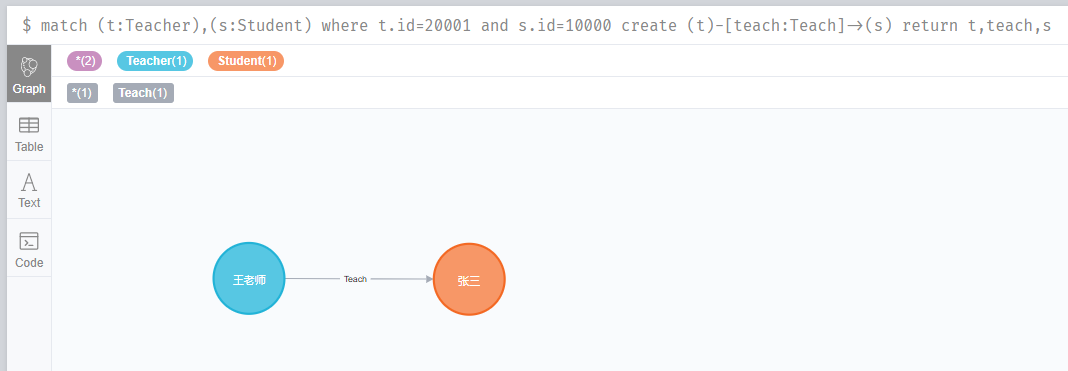
這樣,王老師和張三的關係就建立了。下面,我們再繼續建立王老師 和 李四、王五的關係。
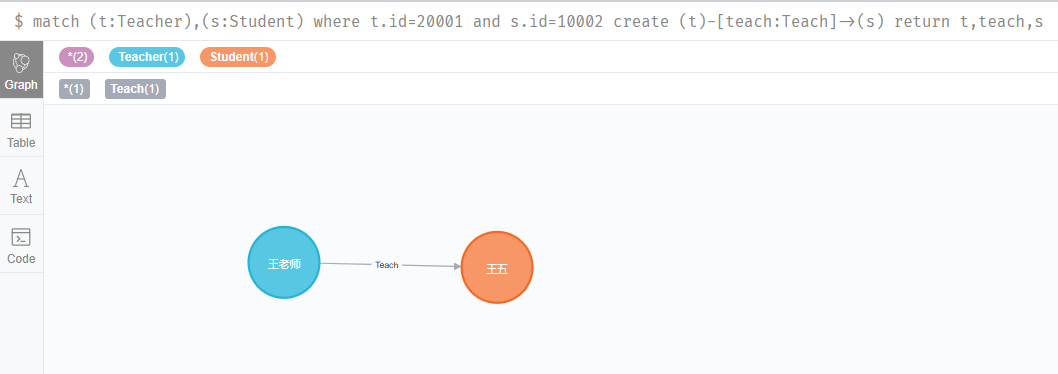
match (t:Teacher),(s:Student) where t.id=20001 and s.id=10001
create (t)-[teach:Teach]->(s)
return t,teach,s
match (t:Teacher),(s:Student) where t.id=20001 and s.id=10002
create (t)-[teach:Teach]->(s)
return t,teach,s
不難發現,建立關係的語法如下:
match (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>)
where <condition>
create (<node1-label-name>)-[<relationship-label-name>:<relationship-name>]
->(<node2-label-name>)
或者
match (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>)
where <condition>
create (<node1-label-name>)-[<relationship-label-name>:<relationship-name>
{<relationship-properties>}]->(<node2-label-name>)
- node1-name表示節點名稱,label1-name表示標籤名稱
- relationship-name表示關係節點名稱,relationship-label-name表示關係標籤名稱
- node2-name表示節點名稱,label2-name表示標籤名稱
老師和學生的關係增加了,我們查詢下:
match (t:Teacher)-[teach:Teach]-(s:Student) return t,teach,s
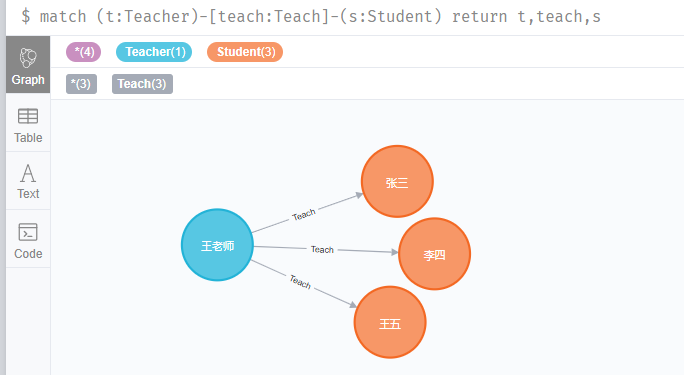
這關係就很顯然了吧。王老師教張三、李四、王五。
2.我們給廣東和深圳建立關係,深圳是屬於廣東省的。但是並沒有廣東省份節點和深圳市節點,沒錯,我們就是為兩個不存在的節點建立關係。
create (c:City{id:30000,name:"深圳市"})-[belongto:BelongTo{type:"屬於"}]->(p:Province{id:40000,name:"廣東省"})

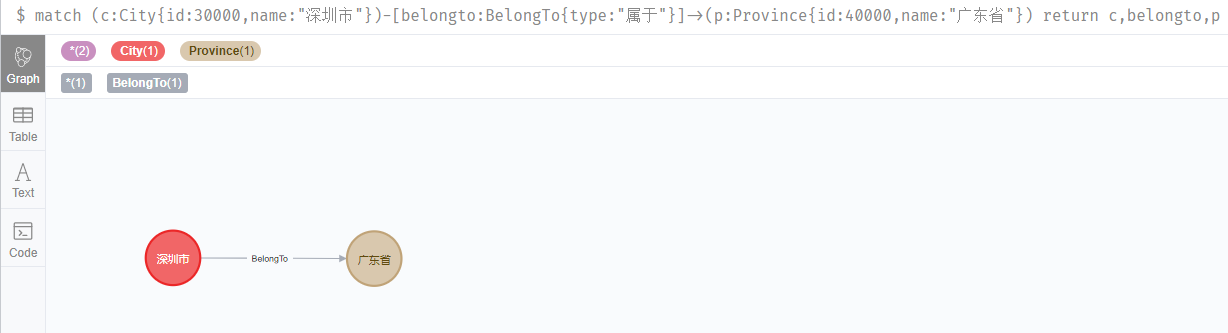
我們查詢下我們建立的深圳和廣東的關係。
match (c:City{id:30000,name:"深圳市"})-[belongto:BelongTo{type:"屬於"}]->(p:Province{id:40000,name:"廣東省"}) return c,belongto,p
為兩個不存在的節點建立關係的語法如下:
create (<node1-name>:<label1-name>
{<property1-name>:<property1-Value>,
<property1-name>:<property1-Value>})-
[(<relationship-name>:<relationship-label-name>{<property-name>:<property-Value>})]
->(<node2-name>:<label2-name>
{<property1-name>:<property1-Value>,
<property1-name>:<property1-Value>})
當然,屬性都非必填的,只是為了更加準確。
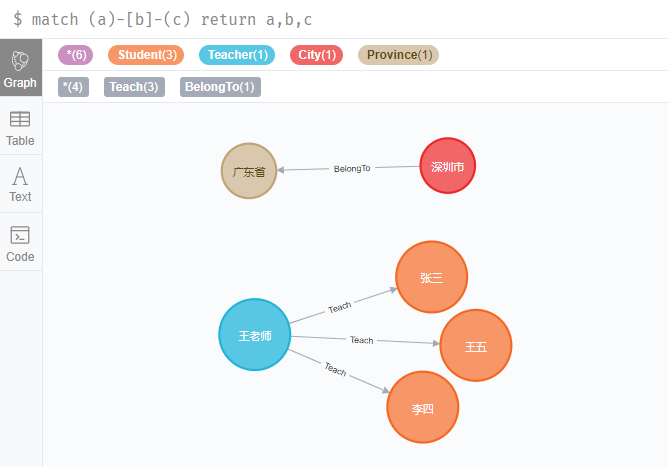
如果我們要查詢Neo4j中全部的關係需要怎麼寫CQL呢,如下:
match (a)-[b]-(c) return a,b,c
三、修改
Neo4j中的修改也和SQL中的是很相似的,都是用set子句。和es一樣,Neo4j CQL set子句也可以向現有節點或關係新增新屬性。
通過上面的查詢,我們已經熟記了學生張三的年齡是18歲,2020年了,張三也長大了一歲,所以我們就需要把張三的年齡改為19。
match (s:Student) where s.name="張三" set s.age=19 return s
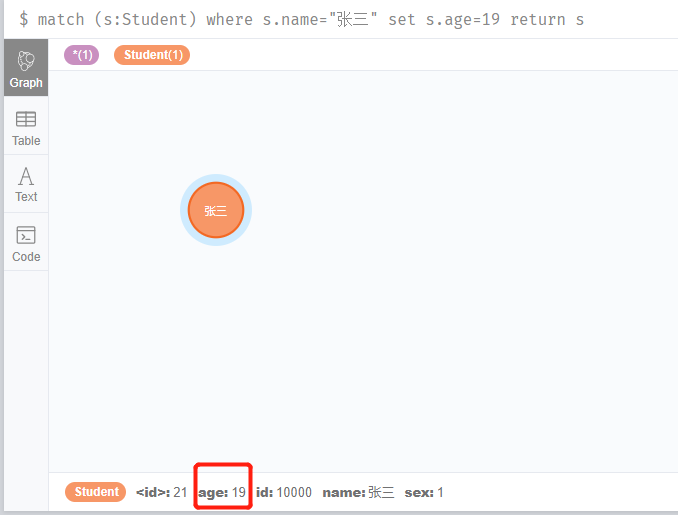
從上圖的紅色框中我們可以清晰的看到張三的年齡已經更新到19了。
四、刪除
Neo4j中的刪除也和SQL中的是很相似的,都是delete,當然,除了delete刪除,還有remove刪除。
1.刪除單個節點
這裡以刪除學生節點中沒有屬性的來舉例:
先查詢下學生中沒有屬性的節點
match (s:Student) where s.name is null return s
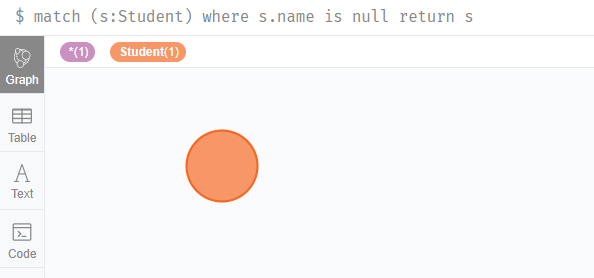
然後我們再刪除這個節點:
match (s:Student) where s.name is null delete s
把上面查詢的CQL中的return 改為 delete 就OK了。
執行完上面的刪除CQL後,我們再重新查詢下:
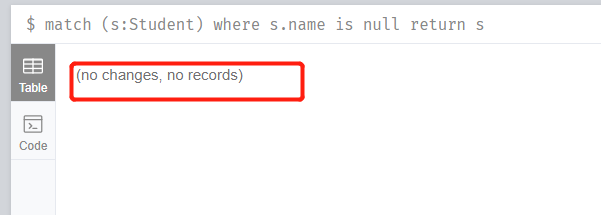
發現已經不存在沒有屬性的學生節點了,這說明我們已經刪除成功了。
2.刪除帶關係的節點
這裡我們以刪除廣東和深圳的關係來舉例:
match (c:City{id:30000,name:"深圳市"})-[belongto]->(p:Province{id:40000,name:"廣東省"}) return c,belongto,p
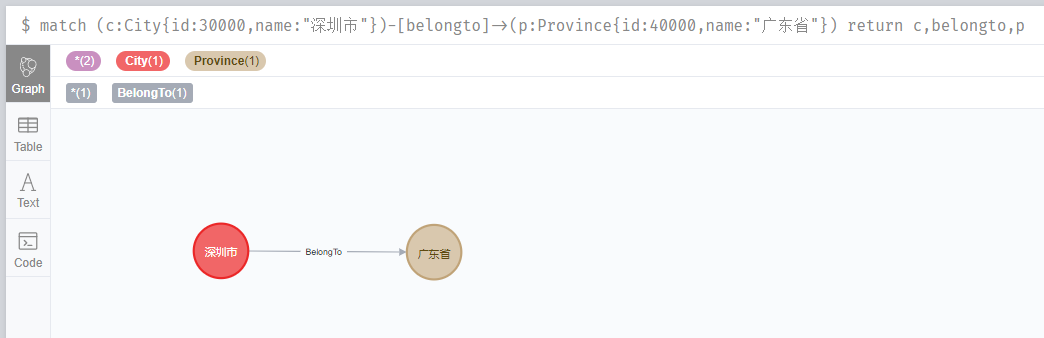
這個時候是有資料的。
然後我們執行下面的刪除CQL,把上面的查詢CQL中的return 改為 delete哦:
match (c:City{id:30000,name:"深圳市"})-[belongto]->(p:Province{id:40000,name:"廣東省"}) delete c,belongto,p
執行完上面的刪除CQL後我,我們重新再查詢下:
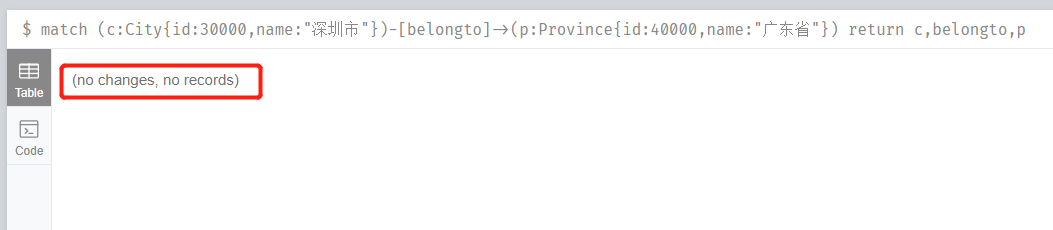
發現已經不存在廣東和深圳這兩個節點以及關係了。
3.刪除全部節點已經關係
這裡這個CQL主要用作測試的,生產環境可不要執行,否則,真的是從刪庫到跑路了~
match (n) detach delete n
這個CQL就不演示了。
4.刪除節點或關係的現有屬性
可以通過remove來刪除節點或關係的現有屬性。
例如,我們刪除學生李四節點中的sex屬性:
match (s:Student{id:10001}) remove s.sex
執行完上面的remove CQL後,我們重新查詢下:
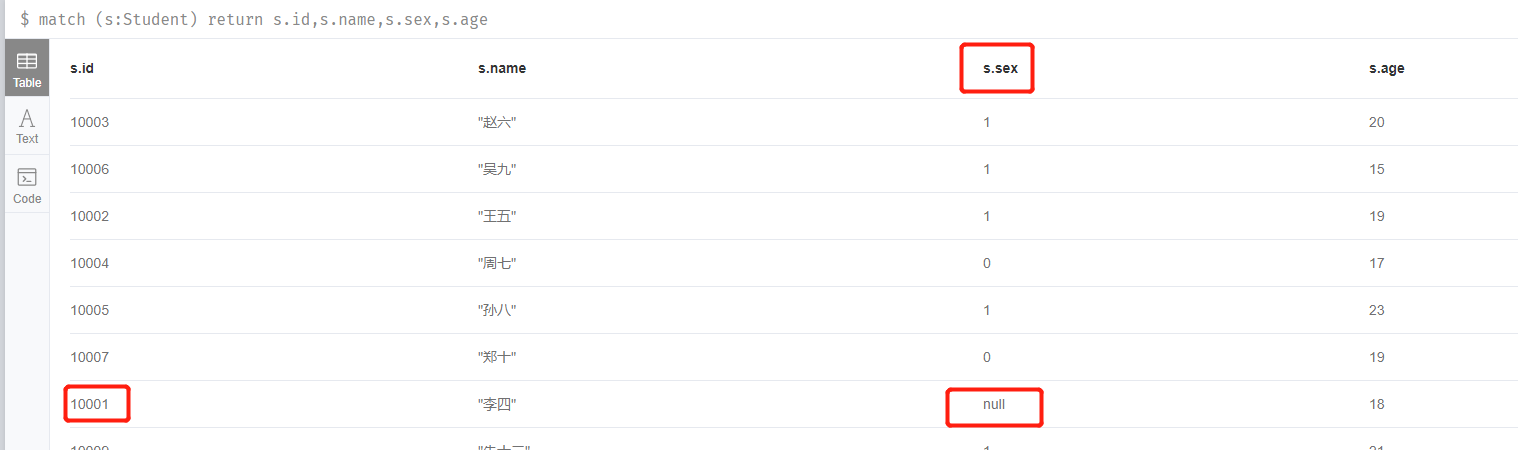
看到李四的sex屬性為null了。
五、總結
這篇文章就介紹了下Neo4j中的CQL,以及增刪改查,我們也在實踐中和MySQL中的某些SQL做了對比。下篇文章繼續介紹,neo4j在springboot中的應用。