
基於決策樹的簡單驗證碼識別
原理
核心思想:相似的輸入必會產生相似的輸出。
原理:首先從訓練樣本矩陣中選擇第一個特徵進行劃分,使每個子表中該特徵的值全部相同(比如第一個特徵是男女,則可以劃分出兩個子表,男表和女表),然後再在每個子表中選擇下一個特徵按照同樣的規則繼續劃分更小的子表(比如第二個特徵是年齡,我可以劃分成三個子表(當然根據情況的不同而不同),小於18,大於18小於60,大於60,則在男女表中分別又有三個子表,每個子表下的特徵值都相同),不斷重複直到所有的特徵全部使用完為止,此時便得到葉級子表,其中所有樣本的特徵值全部相同。
解釋:決策樹是一種分類方法,用於對樣本的特徵分類。而分類完成之後,得到的結果是同一類(或者稱為表)的所有特徵基本相同,然後根據某一類的所有樣本通過平均(迴歸)或者投票(分類)得到一個輸出。那麼,當有新的待預測樣本需要預測輸出時,我只需知道樣本屬於哪個類(表)。
工程優化(剪枝):不必用盡所有的特徵,葉級子表中允許混雜不同的特徵值,以此降低決策樹的層數,在精度犧牲可接受的前提下,提高模型的效能。通常情況下,可以優先選擇使資訊熵減少量最大的特徵作為劃分子表的依據。(通俗的講就是有些特徵值並不區分,比如第一個特徵是男女,我並不分成兩個表,而是放在一個表裡,這種情況一般是男女這個特徵對輸出的影響不大),如何區分有用特徵和無用特徵或者說影響不大的特徵呢?通過資訊熵或基尼指數來區分。也可以用PCA和ICA等方法對特徵先進行降維操作。
sklearn api
class sklearn.tree.DecisionTreeClassifier()
引數
- criterion:選值{“gini”, “entropy”},即基尼指數和資訊熵,預設'gini'
- splitter: 選值{'best', 'random'}, 預設'best',random是為了防止過擬合
- max_depth: 樹的最大深度,如果不給定則會用進所有特徵構建樹,或者滿足引數min_samples_split時停止
- min_samples_split:節點拆分的最小樣本數,可以是int和float,float表示 ceil(min_samples_split * n_samples), 即該小數為總樣本的佔比
- min_samples_leaf:每個節點的最小樣本數,可以是int和float
- min_weight_fraction_leaf:float,預設值= 0.0,在所有葉節點處(所有輸入樣本)的權重總和中的最小加權分數。如果未提供sample_weight,則樣本的權重相等
- max_features :考慮的最大特徵數,int,float或{“ auto”,“ sqrt”,“ log2”}
1. 如果為int,則max_features在每個分割處考慮特徵。
2. 如果為float,max_features則為小數,並 在每次拆分時考慮要素。int(max_features * n_features)
3. 如果是"auto",則max_features=sqrt(n_features)。
4. 如果是"sqrt",則max_features=sqrt(n_features)。
5. 如果為"log2",則為max_features=log2(n_features)。
6. 如果是None,則max_features=n_features。 - random_state : 隨機種子,int或RandomState。為了防止過擬合,原理不知道
- max_leaf_nodes:最大的葉子節點數,具體取值依情況除錯
- min_impurity_decrease : 限制資訊增益的大小,資訊增益小於設定數值的分枝不會發生。
- min_impurity_split: 在0.19前使用,現由min_impurity_decrease代替
- class_weight :樣本權重
- ccp_alpha:看不懂
屬性 - classes_ :標籤陣列
- feature_importances_:特徵重要性(基於基尼指數和資訊熵)
- max_features_ :模型使用的最大特徵數的推斷值
- n_classes_ :樣本數
- n_features_ : 特徵數
- n_outputs_:
- tree_:tree物件
方法 - apply(X[, check_input]):返回X被預測的葉子索引
- cost_complexity_pruning_path(X, y[, …]):沒看懂
- decision_path(X[, check_input]):返回樹中的決策路徑
- fit(X, y[, sample_weight, …]):訓練
- get_depth():獲取模型深度
- get_n_leaves():獲取模型葉子數
- get_params([deep]):獲取模型引數
- predict(X[, check_input]):預測
- predict_log_proba(X):預測X的對數概率
- predict_proba(X[, check_input]):預測X的概率
- score(X, y[, sample_weight]):返回預測y和輸出y的正確率佔比
- set_params(params):設定模型引數
驗證碼識別
前面使用的驗證碼特徵和類別對應過於明顯,所以我們選擇介面的另一種驗證碼,即70x25大小的,如下:
雖然同樣很簡單,但是加入了字元。
至於預處理和數字驗證碼一樣,正常驗證碼->灰度圖->二值化->切割->標註。不過經過測試發現,無論我如何調參,準確率都比較低。看了所有的字元才發現,圖片的字元雖然沒有傾斜變形但有粗體和細體的區別,而我在標註的時候並沒有嚴格讓粗體和細體的樣本數一樣。而且字元的位置不在圖片的中間,字元大小也不一樣,有的偏上,有的偏下,有的偏小,有的又偏大。即使重新標註的準確率還是難達到我要的標準。
對於這種分割線和字元邊緣明顯的驗證碼來說,我們可以將字元從切割後的圖片中提取出來,也就是去掉邊緣外的空白,然後都調整到一樣的大小。這樣就去掉了字元位置和大小對演算法的干擾,至於粗體和細體,只要保證這兩個的訓練樣本數量相同就可以了。程式碼如下:
def img_preprocess(file):
img1 = Image.open(file)
pix = np.array(img1)
pix = (pix > 180) * 255
width, height = pix.shape
for i in range(width):
if np.sum(pix[i]==0):
xstart = i
break
for i in range(width-1, 0, -1):
if np.sum(pix[i]==0):
xend = i + 1
break
for i in range(height):
if np.sum(pix[:,i]==0):
ystart = i
break
for i in range(height-1, 0, -1):
if np.sum(pix[:,i]==0):
yend = i + 1
break
new_pix = pix[xstart:xend, ystart:yend]
img = Image.fromarray(new_pix).convert('L')
if new_pix.size != (8, 10):
img = img.resize((8, 10), resample=Image.NEAREST)
img.save(file)接著我們使用決策樹重新訓練樣本並調整引數,我們先看max_depth這個引數,程式碼如下:
from sklearn.tree import DecisionTreeClassifier
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as mp
def func(k):
x = []
y = []
for label in os.listdir('train'):
for file in os.listdir(f'train/{label}'):
im = Image.open(f'train/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
pix = pix.ravel()
x.append(list(pix))
y.append(label)
train_x = np.array(x)
train_y = np.array(y)
model = DecisionTreeClassifier(max_depth=k)
model.fit(train_x, train_y)
x = []
y = []
for label in os.listdir('test'):
for file in os.listdir(f'test/{label}'):
im = Image.open(f'test/{label}/{file}')
pix = np.array(im)
pix = (pix > 180) * 1
pix = pix.ravel()
x.append(list(pix))
y.append(label)
test_x = np.array(x)
test_y = np.array(y)
score = model.score(test_x, test_y)
return score
if __name__ == "__main__":
os.chdir('G:\\knn\\字元驗證碼\\')
x = list(range(1, 15))
y = [func(i) for i in x]
mp.scatter(x, y)
mp.show()執行結果:
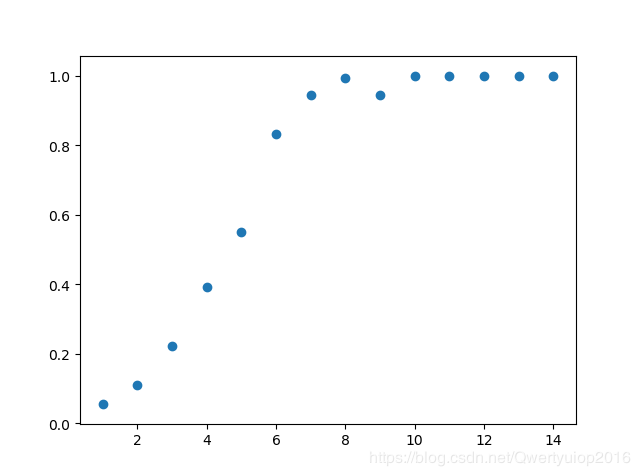
可以看到當max_depth=8的時候,準確率已經很接近1了,所以我們直接將max_depth取8就行了。既然識別的準確率已經接近1,其他的引數調不調整好像並不重要了,不過因為這是驗證碼的識別,不容易出現過擬合的情況,在其他情況下,如果準確率接近1就更要去調整隨機引數(random_state和splitter)和剪枝引數(min_samples_leaf等)來防止過擬合。我後面也試著調整了一下其他引數,發現模型的準確率變化不大,預設即可。
訓練測試資料集:https://www.lanzous.com/i8joo0f
最後,我正在學習一些機器學習的演算法,對於一些我需要記錄的內容我都會分享到部落格和微信公眾號(python成長路),歡迎關注。平時的話一般分享一些爬蟲或者Python的內容。

相關推薦
基於TensorFlow的簡單驗證碼識別
mini shu nal array pool 利用 imp 大小寫 標註 TensorFlow 可以用來實現驗證碼識別的過程,這裏識別的驗證碼是圖形驗證碼,首先用標註好的數據來訓練一個模型,然後再用模型來實現這個驗證碼的識別。 生成驗證碼 首先生成驗證碼,這裏使用
基於決策樹的簡單驗證碼識別
原理 核心思想:相似的輸入必會產生相似的輸出。 原理:首先從訓練樣本矩陣中選擇第一個特徵進行劃分,使每個子表中該特徵的值全部相同(比如第一個特徵是男女,則可以劃分出兩個子表,男表和女表),然後再在每個子表中選擇下一個特徵按照同樣的規則繼續劃分更小的子表(比如第二個特徵是年齡,我可以劃分成三個子表(當然根據情況
基於SVM的字母驗證碼識別
區域 總結 nim 系列 red clust 記錄 完成 form 基於SVM的字母驗證碼識別 摘要 本文研究的問題是包含數字和字母的字符驗證碼的識別。我們采用的是傳統的字符分割識別方法,首先將圖像中的字符分割出來,然後再對單字符進行識別。首先通過圖像的初步去噪、濾波、形態
macOS python3 簡單驗證碼識別
1,tesseract 庫安裝 brew search tesseract brew install tesseract 2,pytesseract 安裝 pip3 search pytesseract pip3 install pytesseract $
Java簡單驗證碼識別(附原始碼)
學習目的:熟悉java類集與IO流操作,熟悉影象基本知識 可識別的圖形: 思路:這個驗證碼比較規則,數字都是顯示在固定的區域,數字也無粘連,實現步驟如下 1.對影象進行分割,分割成一個影象顯示一個數字 2.對每個影象進行灰化處理,就是設定一個
簡單驗證碼識別
驗證碼識別主要包括兩部分:去除干擾和識別。其中最麻煩的是去除干擾。對於識別有現成的庫:tesseract。在進行驗證碼識別之前,首先需要得到驗證碼資料,如果從網上下載是在太麻煩,就寫了一個生成驗證碼的程式,用來生成各種隨機驗證碼。 一、生成驗證碼資料集 1)驗證碼的隨機性
Java實現超簡單驗證碼識別
閒來想實現程式模擬登陸一個系統,說白了,就是寫個簡單的爬蟲,但是無奈,遇到了數字圖片驗證碼,在查閱了一些方案以後,遂決定自己手寫程式碼實現驗證碼識別,分享一下整個過程。 圖片驗證碼是什麼 圖片驗證碼,這個大家應該都見過。最普遍的圖片驗證碼就是一張
Python 新手實戰之機器學習實現簡單驗證碼識別(一):用PIL簡單繪製驗證碼
驗證碼生成 from PIL import Image, ImageDraw, ImageFont import random, os def draw(): #隨機生成背景顏色 (RGB顏色範圍為0-255,越高越接近白色),背景顏色不宜過深,
基於SVM的python簡單實現驗證碼識別
save def lse highlight pro imp bubuko uac 如果 1. 爬取驗證碼圖片 from urllib import request def download_pics(pic_name): url = ‘http://wsbs
基於樸素貝葉斯識別簡單驗證碼
樸素貝葉斯定理 原理請參考: http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.html https://www.cnblogs.com/TimVerion/p/11197043.html 即 後驗概率 = 先驗概率 * 調整
驗證碼識別(最簡單之印刷體數字)
轉化 end double show ray app def 藍色 代碼實現 # -*- coding: utf-8 -*- import numpy from PIL import Image image = Image.open("5.gif") heigh
驗證碼識別 Tesseract的簡單使用和總結
參數說明 stdout all 令行 github output 一個個 其中 簡單 Tesseract是什麽 OCR即光學字符識別,是指通過電子設備掃描紙上的打印的字符,然後翻譯成計算機文字的過程。也就是說通過輸入圖片,經過識別引擎,去識別圖片上的文字。Tesseract
2.CNN圖片多標籤分類(基於TensorFlow實現驗證碼識別OCR)
上一篇實現了圖片CNN單標籤分類(貓狗圖片分類任務) 地址:juejin.im/post/5c0739… 預告:下一篇用LSTM+CTC實現不定長文字的OCR,本質上是一種不固定標籤個數的多標籤分類問題 本文所用到的10w驗證碼資料集百度網盤下載地址(也可使用下文程式碼自行生成): pan.baidu
驗證碼識別處理--基於java(二)
先給出要處理的驗證碼地址(地址後面為隨機數字,便於生成不同的驗證碼)http://vote.sun0769.com/include/ ... 1025&rid=866359 (圖示應該為bmp的,因為論壇限制,給存為jpg格式上傳了)看到此驗證碼,開始想到的步驟就
selenium和Appium的簡單驗證碼自動識別方法
用到tesseract-ocr和PIL兩個工具。 系統為Windows 64位,因此再安裝PIL的時候有點小問題,步驟如下: 1、下載 tesseract-ocr-setup-3.02.02.exe安裝(雙擊一路下一步然後finish),然後把tesseract-oc
簡單驗證碼的識別(matlab實現)
驗證碼採集地址:http://www.quanjing.com/createImg.aspx 識別思路:這個驗證碼比較規則,數字都是顯示在固定的區域,數字也無粘連,實現步驟如下 1.對影象進
python爬蟲實現登陸簡單圖片驗證碼識別(Tesseract識別)
Tesseract下載與安裝 附:德國曼海姆大學發行的3.05版本下載 安裝與配置PATH環境變數 安裝略,環境變數只要將目錄新增到PATH路徑,PATH路徑針對於命令列解析。 tesseract 1.png output-l eng -psm 7 -ps
基於慣性大水滴滴水演算法和支援向量機的粘連字元驗證碼識別
這幾天閒來無事,在等雅思成績出來的過程中,只能寫點東西來打發時間。剛好在上影象處理這門課,於是就想寫個驗證碼識別,普通的驗證碼識別難度太低,於是想要做粘連扭曲的驗證碼識別,如12306的驗證碼識別,此外,這個演算法同樣也可以適用於手寫體識別,反而我覺得手寫體比12306的驗
基於python語言的tensorflow的‘端到端’的字元型驗證碼識別原始碼整理(github原始碼分享)
4 本文工作 解釋了原作者程式碼註釋中提到的關於sigmoid選型的困惑問題並應用到程式碼中 將原作者的程式碼進行模組工程化,成為整體專案,方便研究的同學直接進行模式套用 原作者程式碼中: def train_crack_captcha_cnn(): outp
卷積神經網路(CNN)學習演算法之----基於LeNet網路的中文驗證碼識別
由於公司需要進行了中文驗證碼的圖片識別開發,最近一段時間剛忙完上線,好不容易閒下來就繼上篇《基於Windows10 x64+visual Studio2013+Python2.7.12環境下的Caffe配置學習 》文章,記錄下利用caffe進行中文驗證碼圖片識別的開發過程。由於這裡主要介紹開發和實現過程,