Spark學習筆記(四)—— Yarn模式
1、Yarn執行模式介紹
Yarn執行模式就是說Spark客戶端直接連線Yarn,不需要額外構建Spark叢集。如果Yarn是分散式部署的,那麼Spark就跟隨它形成了分散式部署的效果。有yarn-client和yarn-cluster兩種模式,主要區別在於:Driver程式的執行節點。
yarn-client:Driver程式執行在客戶端,適用於互動、除錯,希望立即看到app的輸出
yarn-cluster:Driver程式執行在由RM(ResourceManager)啟動的AP(APPMaster)適用於生產環境。
其實簡單說來,就是用Spark替換掉了Hadoop中的MapReduce;或者理解成,用Yarn替換掉了Spark的資源排程器。都是一回事,取長補短的結果。
2、安裝配置
1)修改hadoop配置檔案yarn-site.xml,新增如下內容:
<!--是否啟動一個執行緒檢查每個任務正使用的實體記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,預設是true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
2)修改spark-env.sh,新增如下配置,指定Yarn的配置 :
[simon@hadoop102 conf]$ vi spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop3)分發配置檔案
[simon@hadoop102 conf]$ xsync /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
#spark-env.sh可分發可不分發,因為Yarn是叢集模式,Spark執行在Yarn上
[simon@hadoop102 conf]$ xsync spark-env.sh4)啟動Hadoop叢集:
[simon@hadoop102 hadoop-2.7.2]$ start-dfs.sh
#在ResourceManager上啟動Yarn
[simon@hadoop103 module]$ start-yarn.sh5)執行一個應用程式:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100我們比較一下,它和local模式有什麼不一樣的地方:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100引數說明:
- --master 指定Master的地址,預設為Local
- --class: 你的應用的啟動類 (如 org.apache.spark.examples.SparkPi)
- --deploy-mode: 是否釋出你的驅動到worker節點(cluster) 或者作為一個本地客戶端 (client) (default: client)*
- --conf: 任意的Spark配置屬性, 格式key=value. 如果值包含空格,可以加引號“key=value”
- application-jar: 打包好的應用jar,包含依賴. 這個URL在叢集中全域性可見。 比如hdfs:// 共享儲存系統, 如果是 file:// path, 那麼所有的節點的path都包含同樣的jar
- application-arguments: 傳給main()方法的引數
- --executor-memory 1G 指定每個executor可用記憶體為1G
- --total-executor-cores 2 指定每個executor使用的cup核數為2個
不同的地方很明顯:指定了master為Yarn模式,--deploy-mode,為client模式,預設的代表是Local模式。
3、Yarn模式執行流程
畫了一張圖,感受一下:
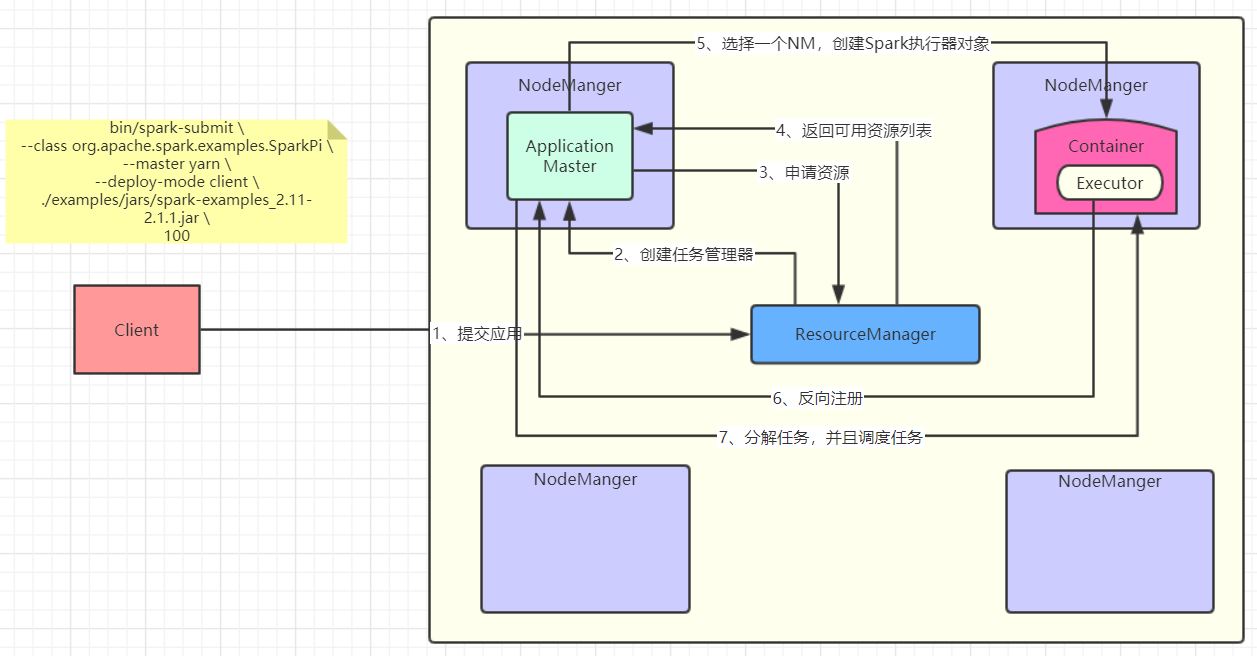
其實我感覺圖畫的已經挺清楚的了,再嘗試用文字解釋一下吧,以後看原始碼會對圖的理解更加深刻:
1)客戶端提交應用給Yarn的ResourceManager(RM);
2)RM選擇一個NodeManager(NM)建立ApplicationMaster(AM);
3)AM向RM索要執行任務的資源;
4)RM返回給AM可用的資源列表(例如:NM1、NM2、NM3);
5)AM選擇一個NM,建立Spark的執行器物件Executor;
6)那麼AM怎麼知道這個Executor建立了以及它的狀態呢,這時候Executor反向註冊到AM;
7)AM知道了Executor的狀態,開始分解任務,交給它執行。
先有一個大致的印象,方便之後看原始碼去理解,這樣整個程式碼的邏輯才更加清晰,反過來對整個流程也能理解的更加深刻。
4、日誌檢視
有時候我們需要對任務進行實時的監控,或者返回來看任務的執行流程,那麼就需要檢視日誌了。由於我們現在使用的Yarn模式,那麼就自然而然的想到,日誌資訊應該是在Yarn的web UI中檢視。也就是:使得Yarn能夠看到Spark的執行日誌。
1)修改配置檔案spark-defaults.conf
新增如下內容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=180802)重啟spark歷史服務
[simon@hadoop102 spark]$ sbin/stop-history-server.sh
#輸出
stopping org.apache.spark.deploy.history.HistoryServer
[simon@hadoop102 spark]$ sbin/start-history-server.sh
#輸出
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark/logs/spark-simon-org.apache.spark.deploy.history.HistoryServer-1-hadoop102.out3)提交任務到Yarn執行
[simon@hadoop102 spark]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
1004)Web頁面檢視日誌