
Linux中的零拷貝
零拷貝
本文圖片和一些內容均來自後面的參考,非原創只是把文章中的一些關鍵內容整理一下,算作是一個學習筆記。
傳統的I/O操作
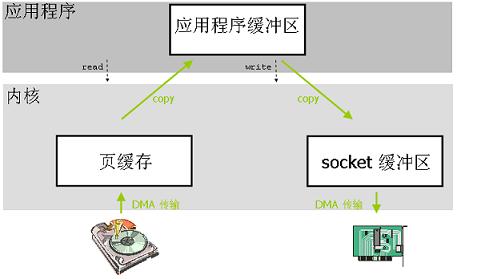
傳統的IO操作是使用者應用程式只是需要呼叫兩個系統呼叫 read() 和 write() 就可以完成這個資料傳輸操作,但是底層會發生很多步驟,這些步驟對上層都是隱藏的。我們來梳理一下。
當應用程式需要訪問某塊資料的時候:
- 應用程式發起系統呼叫
read()讀取檔案(一次上下文切換,或者說是模式切換模式切換1,使用者態切換到核心態) - 作業系統核心會先檢查這塊資料是不是已經被存放在作業系統核心地址空間的緩衝區內,如果存在就直接返回。如果不在就執行下一步。
- 如果在核心緩衝區中找不到這塊資料(叫做缺頁,會觸發缺頁異常),Linux 作業系統核心會先將這塊資料從磁碟讀出來放到作業系統核心的緩衝區裡去(一次DMA2拷貝,硬碟到頁快取)
- 然後核心把這塊資料拷貝到應用程式的地址空間中去(一次CPU拷貝,核心空間到使用者空間)
read()函式返回。(一次上下文切換,或者說是模式切換,核心態切換到使用者態)- 應用程式呼叫
write()函式向socket緩衝區寫資料。(一次上下文切換,或者說是模式切換,使用者態切換到核心態) - 核心需要將資料再一次從使用者應用程式地址空間的緩衝區拷貝到與網路堆疊相關的核心緩衝區(一次CPU拷貝,核心空間內)
- 執行DMA拷貝,把核心的socket緩衝區資料通過DMA方式傳送給物理網絡卡,在執行期間使用者空間應用程式的
write()函式返回。(一次上下文切換,或者說是模式切換,核心態切換到使用者態)
從上面過程來看,經過了4次上下文切換或者是模式切換,4次拷貝操作(2次DMA拷貝,2次CPU拷貝)。
為什麼需要零拷貝
從上面過程來看,4次切換和4次拷貝,整個處理過程比較冗長,但這還不是問題,在網路速度比較慢的時代(56K貓、10/100MB乙太網)其實不需要這種技術,因為內部再快也會被網路速率卡住,木桶效應。但是當網路速度大幅提升出現1Gb、10Gb甚至100Gb網速的時候這種零拷貝技術就迫切需要,因為網路傳輸速度已經遠遠大於計算機內部的資料流轉速度。所以有必要提速,那麼這時候人們就關注如何優化計算機內部資料流轉。
零拷貝解決了什麼問題
零拷貝技術的實現有很多種,但歸根結底其目的是減少資料傳輸的中間環節,尤其是上述過程中的使用者空間和核心空間的資料拷貝。
減少CPU拷貝的方法
直接I/O
快取 I/O 又被稱作標準 I/O,大多數檔案系統的預設 I/O 操作都是快取 I/O。在 Linux 的快取 I/O 機制中,作業系統會將 I/O 的資料快取在檔案系統的頁快取(page cache)。讀取資料的時候先在緩衝中查詢如果命中就直接返回,沒有命中則去磁碟讀取。其實這種機制是一種為了提高速度減少IO操作的良性機制,因為畢竟磁碟屬於低速裝置。
那麼反過來在寫資料的時候應用程式也是先寫到頁快取,至於是否會立即同步到磁碟這取決於採用的寫操作機制,到底是同步寫還是非同步寫。同步寫機制應用程式會立刻得到響應,而非同步寫則會稍晚些得到響應。當然還有另外一種機制就是延遲寫入機制,不過延遲寫入寫到磁碟上的時候不會通知應用程式。
在直接I/O機制中,資料均直接在使用者地址空間的緩衝區和磁碟之間直接進行傳輸,完全不需要頁快取的支援。這類零拷貝技術針對的是作業系統核心並不需要對資料進行直接處理的情況。在某些場景下會使用到這種方式。
Kafka就利用這種快取I/O機制,寫入快取,讀取的時候也從快取讀取,這樣吞吐量非常高,但是資料丟失風險就會比較高,因為大量資料在記憶體中,不過引數可以調整。
mmap
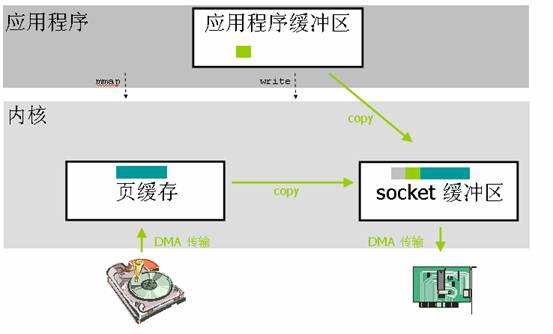
應用程式呼叫了mmap()之後,發生2次上下文切換(呼叫和返回)。資料拷貝除了2次DMA沒有變化之外最主要的就是減少了一次核心到使用者空間的資料拷貝,而是直接從頁快取拷貝到socke緩衝區,所以跟標準I/O比,就變成了2次上下文切換,2次DMA拷貝,1次CPU拷貝。這個優化就減少了中間環節。
但是對檔案進行了記憶體對映,就是應用程式緩衝區和核心空間緩衝區都對映到同一地址範圍的實體記憶體,你也可以說作業系統共享這個緩衝區給應用程式,而且對映操作也是一個開銷很大的虛擬儲存操作,這種操作需要通過更改頁表以及沖刷 TLB (使得 TLB 的內容無效)來維持儲存的一致性。不過這種重新整理TLB的開銷要比。
不過mmap有一個比較大的隱患就是,呼叫 write() 系統呼叫,如果此時其他的程序截斷了這個檔案,那麼 write() 系統呼叫將會被匯流排錯誤訊號 SIGBUS 中斷,因為此時正在執行的是一個錯誤的儲存訪問。這個訊號將會導致程序被殺死。
sendfile
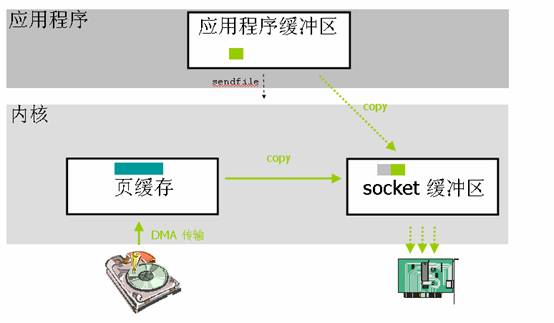
從上圖可以看到應用程式呼叫sendfile()系統呼叫這裡就只發生2次上下文切換(呼叫和返回)。資料拷貝除了2次DMA沒有變化之外最主要的就是減少了一次核心到使用者空間的資料拷貝,而是直接從頁快取拷貝到socke緩衝區,所以跟標準I/O比,就變成了2次上下文切換,2次DMA拷貝,1次CPU拷貝。這個優化就減少了中間環節,提高了內部傳輸效率也解放了CPU。不過這並不是零拷貝,因為還有1次CPU拷貝。
在高階語言中如何使用這種特性就需要去檢視該語言的庫函式,看看那些庫函式底層呼叫的是
sendfile()系統呼叫。
帶DMA的sendfile

這種方式就是為了解決sendfile中的那1次CPU拷貝,也就是核心緩衝區到socket緩衝區的拷貝。不拷貝的話該如何傳送資料呢?就是將核心緩衝區中待發送資料的描述符傳送到網路協議棧中,然後在socket緩衝區中建立資料包的結構,最後通過DMA的收集功能將所有的資料結合成一個網路資料包。網絡卡的 DMA 引擎會在一次操作中從多個位置讀取包頭和資料。Linux 2.4 版本中的 socket 緩衝區就可以滿足這種條件,這也就是用於 Linux 中的眾所周知的零拷貝技術。
- 首先,sendfile() 系統呼叫利用 DMA 引擎將檔案內容拷貝到核心緩衝區去;
- 然後,將帶有檔案位置和長度資訊的緩衝區描述符新增到 socket 緩衝區中去,此過程不需要將資料從作業系統核心緩衝區拷貝到 socket 緩衝區中;
- 最後,DMA 引擎會將資料直接從核心緩衝區拷貝到協議引擎中去,這樣就避免了最後一次資料拷貝。
sendfile的侷限性
首先,sendfile只適用於資料傳送端;其次要傳送的資料中間不能被修改而是原樣傳送的。
參考
Linux 中的零拷貝技術,第 1 部分
Linux 中的零拷貝技術,第 2 部分
Linux 中直接 I/O 機制的介紹
模式切換屬於上下文切換的範圍,只不過不是通常的程序或者執行緒上下文切換。原則上使用者空間應用程式不能直接和硬體互動,只有核心才可以,所以應用程式必須通過系統呼叫來實現對硬體的訪問,其本質就是應用程式程式碼暫時不執行,而是在CPU上執行核心程式碼,核心程式碼執行完成後在切換回來,這也就常說的核心陷入。↩
這裡以讀為例。就是磁碟說:把從第x號扇區開始的y個扇區的資料寫入到從p地址開始的記憶體中,寫完了告訴我(觸發中斷)。這個操作叫做DMA,整個過程不需要CPU參與。不過DMA只能實現頁快取到外設之間的資料拷貝。↩