
forkjoin及其效能分析,是否比for迴圈快?
最近看了網上的某公開課,其中有講到forkjoin框架。在這之前,我絲毫沒聽說過這個東西,很好奇是什麼東東。於是,就順道研究了一番。
總感覺這個東西,用的地方很少,也有可能是我才疏學淺。好吧,反正問了身邊一堆猿,沒有一個知道的。
因此,我也沒有那麼深入的去了解底層,只是大概的瞭解了其工作原理,並分析了下它和普通的for迴圈以及JDK8的stream流之間的效能對比(稍後會說明其中踩到的坑)。
一、forkjoin介紹
forkjoin是JDK7提供的並行執行任務的框架。 並行怎麼理解呢,就是可以充分利用多核CPU的計算能力,讓多個CPU同時進行任務的執行,從而使單位時間內執行的任務數儘量多,因此表現上就提高了執行效率。
它的主要思想就是,先把任務拆分成一個個小任務,然後再把所有任務彙總起來,簡而言之就是分而治之。如果你瞭解過hadoop的MapReduce,就能理解這種思想了。不瞭解也沒關係,下面畫一張圖,你就能明白了。
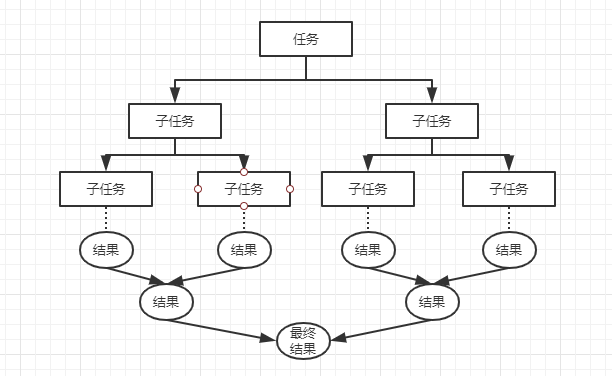
上邊的任務拆分為多個子任務的過程就是fork,下邊結果的歸併操作就是join。(注意子任務和多執行緒不是一個概念,而是一個執行緒下會有多個子任務)
另外,forkjoin有一個工作竊取的概念。簡單理解,就是一個工作執行緒下會維護一個包含多個子任務的雙端佇列。而對於每個工作執行緒來說,會從頭部到尾部依次執行任務。這時,總會有一些執行緒執行的速度較快,很快就把所有任務消耗完了。那這個時候怎麼辦呢,總不能空等著吧,多浪費資源啊。
於是,先做完任務的工作執行緒會從其他未完成任務的執行緒尾部依次獲取任務去執行。這樣就可以充分利用CPU的資源。這個非常好理解,就比如有個妹子程式設計師做任務比較慢,那麼其他猿就可以幫她分擔一些任務,這簡直是雙贏的局面啊,妹子開心了,你也開心了。
二、實操測試效能
話不多說,先上程式碼,計算的是從0加到10億的結果。
public class ForkJoinWork extends RecursiveTask<Long> { private long start; private long end; //臨界點 private static final long THRESHOLD = 1_0000L; public ForkJoinWork(long start, long end) { this.start = start; this.end = end; } @Override protected Long compute() { long len = end - start; //不大於臨界值直接計算結果 if(len < THRESHOLD){ long sum = 0L; for (long i = start; i <= end; i++) { sum += i; } return sum; }else{ //大於臨界值時,拆分為兩個子任務 Long mid = (start + end) /2; ForkJoinWork task1 = new ForkJoinWork(start,mid); ForkJoinWork task2 = new ForkJoinWork(mid+1,end); task1.fork(); task2.fork(); //合併計算 return task1.join() + task2.join(); } } } public class ForkJoinTest { public static void main(String[] args) throws Exception{ long start = 0L; long end = 10_0000_0000L; testSum(start,end); testForkJoin(start,end); testStream(start,end); } /** * 普通for迴圈 - 1273ms * @param start * @param end */ public static void testSum(Long start,Long end){ long l = System.currentTimeMillis(); long sum = 0L; for (long i = start; i <= end ; i++) { sum += i; } long l1 = System.currentTimeMillis(); System.out.println("普通for迴圈結果:"+sum+",耗時:"+(l1-l)); } /** * forkjoin方式 - 917ms * @param start * @param end * @throws Exception */ public static void testForkJoin(long start,long end) throws Exception{ long l = System.currentTimeMillis(); ForkJoinPool forkJoinPool = new ForkJoinPool(); ForkJoinWork task = new ForkJoinWork(start,end); long invoke = forkJoinPool.invoke(task); long l1 = System.currentTimeMillis(); System.out.println("forkjoin結果:"+invoke+",耗時:"+(l1-l)); } /** * stream流 - 676ms * @param start * @param end */ public static void testStream(Long start,Long end){ long l = System.currentTimeMillis(); long reduce = LongStream.rangeClosed(start, end).parallel().reduce(0, (x, y) -> x + y); long l1 = System.currentTimeMillis(); System.out.println("stream流結果:"+reduce+",耗時:"+(l1-l)); } }
這裡解釋下,首先我們需要建立一個ForkJoinTask,自定義一個類來繼承ForkJoinTask的子類RecursiveTask,這是為了拿到返回值。另外還有一個子類RecursiveAction是不帶返回值的,這裡我們暫時用不到。
然後,需要建立一個ForkJoinPool來執行task,最後呼叫invoke方法來獲取最終執行的結果。它還有兩種執行方式,execute和submit。這裡不展開,感興趣的可以自行檢視原始碼。
鐺鐺,重點來了。
我測試了下比較傳統的普通for迴圈,來對比forkjoin的執行速度。計算的是從0加到10億,在我的win7電腦上確實是forkjoin計算速度快。這時,坑來了,同樣的程式碼,沒有任何改動,我搬到mac電腦上,計算結果卻大大超出我的意外——forkjoin竟然比for迴圈慢了一倍,對的沒錯,執行時間是for迴圈的二倍。
這就讓我特別頭大了,這到底是什麼原因呢。經過多次測試,終於搞明白了。forkjoin這個框架針對的是大任務執行,效率才會明顯的看出來有提升,於是我把總數調大到20億。
另外還有個關鍵點,通過設定不同的臨界點值,會有不同的結果。逐漸的加大臨界點值,效率會進一步提升。比如,我分別把THRESHOLD設定為1萬,10萬和100萬,執行時間會逐步縮短,並且會比for迴圈時間短。感興趣的,可自己手動操作一下,感受這個微妙的變化。
因此,最終修改為從0加到20億,臨界值設定為100萬,就出現了以下結果:
普通for迴圈結果:2000000001000000000,耗時:1273
forkjoin結果:2000000001000000000,耗時:917
stream流結果:2000000001000000000,耗時:676可以明顯看出來,forkjoin確實是比for迴圈快的。當然,逐步的再加大總數到100億或者更大,然後調整合適的臨界值,這種對比會更加明顯。(就是心疼電腦會冒煙,不敢這樣測試)
最後,說下JDK8提供的Stream流計算,可以看到,這個計算速度是三種方式中最快的。奈你forkjoin再牛逼,通常還是比不過Stream的,從這個方法parallel的名字就看出來,也是平行計算。所以,這也是我感覺forkjoin好像沒什麼存在感的原因,Stream不香嗎。(當然,也有可能是forkjoin還有更牛逼的功能待我去發掘。