
清晰架構(Clean Architecture)的Go微服務: 依賴注入(Dependency Injection)
在清晰架構(Clean Architecture)中,應用程式的每一層(用例,資料服務和域模型)僅依賴於其他層的介面而不是具體型別。 在執行時,程式容器¹負責建立具體型別並將它們注入到每個函式中,它使用的技術稱為依賴注入²。 以下是要求。
容器包的依賴關係:
容器包是唯一依賴於具體型別和許多外部庫的包,因為它需要建立具體型別。 本程式中的所有其他軟體包主要僅依賴於介面。
外部庫可以包括DB和DB連線,gRPC連線,HTTP連線,SMTP伺服器,MQ等。
#2中提到的具體型別的資源連結只需要建立一次並放入登錄檔中,所有後來的請求都將從登錄檔中檢索它們。
只有用例層需要訪問並依賴於容器包。
依賴注入的核心是工廠方法模式(factory method pattern)。
工廠方法模式(Factory Method Pattern):
實現工廠方法模式並不困難,這裡³描述了是如何在Go中實現它的。困難的部分是使其可擴充套件,即如何避免在新增新工廠時修改程式碼。
處理新工廠的方式有很多種,下面是常見的三種:
(1)使用if-else語句⁴
(2) 使用對映(map)儲存不同的工廠⁵
(3) 使用反射生成新的具體型別。
#1不是一個好選擇,因為你需要在新增新型別時修改現有程式碼。 #3是最好的,因為新增新工廠時現有程式碼不需更改。在Java中,我會使用#3,因為Java具有非常優雅的反射實現。你可以執行類似“(Animal)Class.forName(”className“)。newInstance()”的操作,即你可以將類的名稱作為函式中的字串引數傳遞進來,並通過反射從中建立一個型別的新例項,然後將結構轉換為適當的型別(可能是它的一個超級型別(super type),這是非常強大的。由於Go的反射不如Java,#3不是一個好選擇。在Go中,由反射建立的例項是反射型別而不是實際型別,並且你無法在反射型別和實際型別之間轉換型別,它們處於兩個不同的世界中,這使得Go中的反射難以使用。所以我選擇#2,它比#1好,但是在新增新型別時需要更改少部分程式碼。
以下是資料儲存工廠的程式碼。它有一個“dsFbInterface”,其中有一個“Build”函式需要由每個資料儲存工廠實現。 “Build”是工廠的關鍵部分。 “dsFbMap”是每個資料庫(或gRPC)的程式碼(code)與實際工廠之間的對映。這是新增資料庫時需要更改的部分。
// To map "database code" to "database interface builder" // Concreate builder is in corresponding factory file. For example, "sqlFactory" is in "sqlFactory".go var dsFbMap = map[string]dsFbInterface{ config.SQLDB: &sqlFactory{}, config.COUCHDB: &couchdbFactory{}, config.CACHE_GRPC: &cacheGrpcFactory{}, } // DataStoreInterface serve as a marker to indicate the return type for Build method type DataStoreInterface interface{} // The builder interface for factory method pattern // Every factory needs to implement Build method type dsFbInterface interface { Build(container.Container, *config.DataStoreConfig) (DataStoreInterface, error) } //GetDataStoreFb is accessors for factoryBuilderMap func GetDataStoreFb(key string) dsFbInterface { return dsFbMap[key] }
以下是“sqlFactory”的程式,它實現了上面的程式碼中定義的“dsFbInterface”。 它為MySql資料庫建立資料儲存。 在“Build”函式中,它首先從登錄檔中檢索資料儲存(MySql),如果找到,則返回,否則建立一個新的並將其放入登錄檔。
因為登錄檔可以儲存任何型別的資料,所以我們需要在檢索後將返回值轉換為適當的型別(*sql.DB)。 “databasehandler.SqlDBTx”是實現“SqlGdbc”介面的具體型別。 它的建立是為了支援事務管理。 程式碼中呼叫“sql.Open()”來開啟資料庫連線,但它並沒有真正執行任何連線資料庫的操作。 因此,需呼叫“db.Ping()”去訪問資料庫以確保資料庫正在執行。
// sqlFactory is receiver for Build method
type sqlFactory struct{}
// implement Build method for SQL database
func (sf *sqlFactory) Build(c container.Container, dsc *config.DataStoreConfig) (DataStoreInterface, error) {
key := dsc.Code
//if it is already in container, return
if value, found := c.Get(key); found {
sdb := value.(*sql.DB)
sdt := databasehandler.SqlDBTx{DB: sdb}
logger.Log.Debug("found db in container for key:", key)
return &sdt, nil
}
db, err := sql.Open(dsc.DriverName, dsc.UrlAddress)
if err != nil {
return nil, errors.Wrap(err, "")
}
// check the connection
err = db.Ping()
if err != nil {
return nil, errors.Wrap(err, "")
}
dt := databasehandler.SqlDBTx{DB: db}
c.Put(key, db)
return &dt, nil
}資料服務工廠(Data service factory)
資料服務層使用工廠方法模式來建立資料服務型別。 可以有不同的策略來應用此模式。 在構建資料服務工廠時,我使用了三種不同的策略,每種策略都有其優缺點。 我將詳細解釋它們,以便你可以決定在那種情況下使用哪一個。
基礎工廠(Basic factory)
最簡單的是“cacheGrpcFactory”,因為資料儲存只有一個底層實現(即gRPC),所以只建立一個工廠就行了。
二級工廠(Second level factory)
對於資料庫工廠,情況並非如此。 因為我們需要每個資料服務同時支援多個數據庫,所以需要二級工廠,這意味著對於每種資料服務型別,例如“UserDataService”,我們需要為每個支援的資料庫使用單獨的工廠。 現在,由於有兩個資料庫,我們需要兩個工廠。
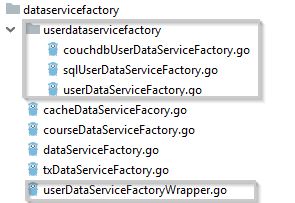
你可以從上面的影象中看到,我們需要四個檔案來完成“UserDataService”,其中“userDataServiceFactoryWrapper.go”是在“userdataservicefactory”資料夾中呼叫實際工廠的封裝器(wrapper)。 “couchdbUserDataServiceFactory.go”和“sqlUserDataServiceFactory.go”是CouchDB和MySql資料庫的真正工廠。 “userDataServiceFactory.go”定義了介面。 如果你有許多資料服務,那麼你將建立許多類似程式碼。
簡化工廠(Simplified factory)
有沒有辦法簡化它? 有的,這是第三種方式,但也帶來一些問題。 以下是“courseDataServiceFactory.go”的程式碼。 你可以看到只需一個檔案而不是之前的四個檔案。 程式碼類似於我們剛才談到的“userDataServiceFactory”。那麼它是如何如何簡化程式碼的呢?
關鍵是為底層資料庫連結建立統一的介面。 在“courseDataServiceFactory.go”中,可以在呼叫“dataStoreFactory”之後獲得底層資料庫連結統一介面,並將“CourseDataServiceInterface”的DB設定為正確的“gdbc”(只要它實現“gdbc”介面,它可以是任何資料庫連結)。
var courseDataServiceMap = map[string]dataservice.CourseDataInterface{
config.COUCHDB: &couchdb.CourseDataCouchdb{},
config.SQLDB: &sqldb.CourseDataSql{},
}
// courseDataServiceFactory is an empty receiver for Build method
type courseDataServiceFactory struct{}
// GetCourseDataServiceInterface is an accessor for factoryBuilderMap
func GetCourseDataServiceInterface(key string) dataservice.CourseDataInterface {
return courseDataServiceMap[key]
}
func (tdsf *courseDataServiceFactory) Build(c container.Container, dataConfig *config.DataConfig) (DataServiceInterface, error) {
dsc := dataConfig.DataStoreConfig
dsi, err := datastorefactory.GetDataStoreFb(dsc.Code).Build(c, &dsc)
if err != nil {
return nil, errors.Wrap(err, "")
}
gdbc := dsi.(gdbc.Gdbc)
gdi := GetCourseDataServiceInterface(dsc.Code)
gdi.SetDB(gdbc)
return gdi, nil
}它的缺點是,對於任何支援的資料庫,需要實現以下程式碼中“SqlGdbc”和“NoSqlGdbc”介面,即使它只使用其中一個,另一個只是空實現(以滿足介面要求)並沒有被使用。 如果你只有少數幾個資料庫需要支援,這可能是一個可行的解決方案,否則它將變得越來越難以管理。
// SqlGdbc (SQL Go database connection) is a wrapper for SQL database handler
type SqlGdbc interface {
Exec(query string, args ...interface{}) (sql.Result, error)
Prepare(query string) (*sql.Stmt, error)
Query(query string, args ...interface{}) (*sql.Rows, error)
QueryRow(query string, args ...interface{}) *sql.Row
// If need transaction support, add this interface
Transactioner
}
// NoSqlGdbc (NoSQL Go database connection) is a wrapper for NoSql database handler.
type NoSqlGdbc interface {
// The method name of underline database was Query(), but since it conflicts with the name with Query() in SqlGdbc,
// so have to change to a different name
QueryNoSql(ctx context.Context, ddoc string, view string) (*kivik.Rows, error)
Put(ctx context.Context, docID string, doc interface{}, options ...kivik.Options) (rev string, err error)
Get(ctx context.Context, docID string, options ...kivik.Options) (*kivik.Row, error)
Find(ctx context.Context, query interface{}) (*kivik.Rows, error)
AllDocs(ctx context.Context, options ...kivik.Options) (*kivik.Rows, error)
}
// gdbc is an unified way to handle database connections.
type Gdbc interface {
SqlGdbc
NoSqlGdbc
}除了上面談到的那個之外,還有另一個副作用。 在下面的程式碼中,“CourseDataInterface”中的“SetDB”函式打破了依賴關係。 因為“CourseDataInterface”是資料服務層介面,所以它不應該依賴於“gdbc”介面,這是下面一層的介面。 這是本程式的依賴關係中的第二個缺陷,第一個是在事物管理⁶模組。 目前對它沒有好的解決方法,如果你不喜歡它,就不要使用它。 可以建立類似於“userFataServiceFactory”的二級工廠,只是程式較長而已。
import (
"github.com/jfeng45/servicetmpl/model"
"github.com/jfeng45/servicetmpl/tool/gdbc"
)
// CourseDataInterface represents interface for persistence service for course data
// It is created for POC of courseDataServiceFactory, no real use.
type CourseDataInterface interface {
FindAll() ([]model.Course, error)
SetDB(gdbc gdbc.Gdbc)
}怎樣選擇?
怎樣選擇是用簡化工廠還是二級工廠?這取決於變化的方向。如果你需要支援大量新資料庫,但新的資料服務不多(由新的域模型型別決定),那麼選二級工廠,因為大多數更改都會發生在資料儲存工廠中。但是如果支援的資料庫不會發生太大變化,並且資料服務的數量可能會增加很多,那麼選擇簡化工廠。如果兩者都可能增加很多呢?那麼只能使用二級工廠,只是程式會比較長。
怎樣選擇使用基本工廠還是二級工廠?實際上,即使你需要支援多個數據庫,但不需同時支援多個數據庫,你仍然可以使用基本工廠。例如,你需要從MySQL切換到MongoDB,即使有兩個不同的資料庫,但在切換後,你只使用MongoDB,那麼你仍然可以使用基本工廠。對於基本工廠,當有多種型別時,你需要更改程式碼以進行切換(但對於二級工廠,你只需更改配置檔案),因此如果你不經常更改程式碼,這是可以忍受的。
備註:上面是我在寫這段程式碼時的想法。但如果現在讓我選擇,我可能不會使用簡化工廠。因為我對程式複雜度有了不同的認識。我依據的原則並沒有變,都是要降低程式碼複雜度。但我以前認為程式碼越長越複雜,但現在我會加上另外一個維度,就是程式碼的結構複雜度。二級工廠雖然程式碼長了很多,但結構簡單,只要完成了一個,就可以拷貝出許多,結構幾乎一模一樣,這樣不論讀寫都非常容易。它的複雜度是線性增加的,而且不會有其他副作用。另外,你可以使用程式碼生成器等工具來自動生成,以提高效率。而“簡化工廠”雖然程式碼量少了,但結構複雜,它的複雜度增加很快,而且副作用太大,很難管理。
依賴注入(Dependency Injection)庫
Go中已經有幾個依賴注入庫,為什麼我不使用它們?我有意在專案初期時不使用任何庫,所以我可以更好地控制程式結構,只有在完成整個程式結構佈局之後,我才會考慮用外部庫替換本程式的某些元件。
我簡要地看了幾個流行的依賴注入庫,一個是來自優步⁷的Dig⁸,另一個是來自谷歌¹⁰的Wire⁹ 。 Dig使用反射,Wire使用程式碼生成。這兩種方法我都不喜歡,但由於Go目前不支援泛型,因此這些是唯一可用的選項。雖然我不喜歡他們的方法,但我不得不承認這兩個庫的依賴注入功能更全。
我試了一下Dig,發現它沒有使程式碼更簡單,所以我決定繼續使用當前的解決方案。在Dig中,你為每個具體型別建立“(build)”函式,然後將其註冊到容器,最後容器將它們自動連線在一起以建立頂級型別。本程式的複雜性是因為我們需要支援兩個資料庫實現,因此每個域模型有兩個不同的資料庫連結和兩組不同的資料服務實現。在Dig中沒有辦法使這部分更簡單,你仍然需要建立所有工廠然後把它們註冊到容器。當然,你可以使用“if-else”方法來實現工廠,這將使程式碼更簡單,但你以後需要付出更多努力來維護程式碼。
我的方法簡單易用,並且還支援從檔案載入配置,但是你需要了解它的原理以擴充套件它。 Dig提供的附加功能是自動載入依賴關係。如果你的應用程式有很多型別並且型別之間有很多複雜的依賴關係,那麼你可能需要切換到Dig或Wire,否則請繼續使用當前的解決方案
介面設計
下面是 “userDataServiceFactoryWrapper”的程式碼.
// DataServiceInterface serves as a marker to indicate the return type for Build method
type DataServiceInterface interface{}
// userDataServiceFactory is a empty receiver for Build method
type userDataServiceFactoryWrapper struct{}
func (udsfw *userDataServiceFactoryWrapper) Build(c container.Container, dataConfig *config.DataConfig)
(DataServiceInterface, error) {
key := dataConfig.DataStoreConfig.Code
udsi, err := userdataservicefactory.GetUserDataServiceFb(key).Build(c, dataConfig)
if err != nil {
return nil, errors.Wrap(err, "")
}
return udsi, nil
}你可能注意到了“Build()”函式的返回型別是“DataServiceInterface”,這是一個空介面,為什麼我們需要一個空介面? 我們可以用“interface {}”替換“DataServiceInterface”嗎?
// userDataServiceFactory is a empty receiver for Build method
type userDataServiceFactoryWrapper struct{}
func (udsfw *userDataServiceFactoryWrapper) Build(c container.Container, dataConfig *config.DataConfig)
(interface{}, error) {
...
}如果將返回型別從“DataServiceInterface”替換為“interface {}”,結果是相同的。 “DataServiceInterface”的好處是它可以告訴我函式的返回型別,即資料服務介面; 實際上,真正的返回型別是“dataservice.UserDataInterface”,但是“DataStoreInterface”現在已經足夠好了,一個小訣竅讓生活變得輕鬆一點。
結論:
程式容器使用依賴注入建立具體型別並將它們注入每個函式。 它的核心是工廠方法模式。 在Go中有三種方法可以實現它,最好的方法是在對映(map)中儲存不同的工廠。 將工廠方法模式應用於資料服務層也有不同的方法,它們各自都有利有弊。 你需要根據應用程式的更改方向選擇正確的方法。
源程式:
完整的源程式連結 github: https://github.com/jfeng45/servicetmpl
索引:
[1][Go Microservice with Clean Architecture: Application Container](https://jfeng45.github.io/posts/application_container/)
[2] Inversion of Control Containers and the Dependency Injection pattern
[3]]Golang Factory Method
[4][Creating a factory method in Java that doesn’t rely on if-else](https://stackoverflow.com/questions/3434466/creating-a-factory-method-in-java-that-doesnt-rely-on-if-else)
[5][Tom Hawtin’s answer](https://stackoverflow.com/questions/3434466/creating-a-factory-method-in-java-that-doesnt-rely-on-if-else/3434505#3434505)
[6][Go Microservice with Clean Architecture: Transaction Support](https://jfeng45.github.io/posts/transaction_support/)
[7][Dependency Injection in Go](https://blog.drewolson.org/dependency-injection-in-go)
[8][Uber’s dig](https://github.com/uber-go/dig)
[9][Go Dependency Injection with Wire](https://blog.drewolson.org/go-dependency-injection-with-wire)
[10][Google’s Wire: Automated Initialization in Go](https://github.com/google/wi