
《【面試突擊】— Redis篇》-- Redis的主從複製?哨兵機制?
能堅持別人不能堅持的,才能擁有別人未曾擁有的。
關注左上角程式設計大道公眾號,讓我們一同堅持心中所想,一起成長!!
《【面試突擊】— Redis篇》-- Redis的主從複製?哨兵機制?
在這個系列裡,我會整理一些面試題與大家分享,幫助年後和我一樣想要在金三銀四準備跳槽的同學。
我們一起鞏固、突擊面試官常問的一些面試題,加油!!
《【面試突擊】— Redis篇》--Redis資料型別?適用於哪些場景?
《【面試突擊】— Redis篇》--Redis的執行緒模型瞭解嗎?為啥單執行緒效率還這麼高?
面試官在問了上兩次提到的問題之後,可能就會開始更加猛烈的攻勢,一連串的Redis的知識點向你拋過來,你頂的住嗎?
下面就面試經常問到的問題,以問答的方式分享給大家。
Redis如何保證高併發,高可用?
高併發:redis的單機吞吐量可以達到幾萬不是問題,如果想提高redis的讀寫能力,可以用redis的主從架構,redis天熱支援一主多從的準備模式,單主負責寫請求多從負責讀請求,主從之間非同步複製,把主的資料同步到從。
高可用:首先利用redis的主從架構解決redis的單點故障導致的不可用,然後如果使用的是主從架構,那麼只需要增加哨兵機制即可,就可以實現,redis主例項宕機,自動會進行主備切換。以此來達到redis的高可用。
你剛才說主從複製,那你能具體聊一下主從複製的原理嗎?
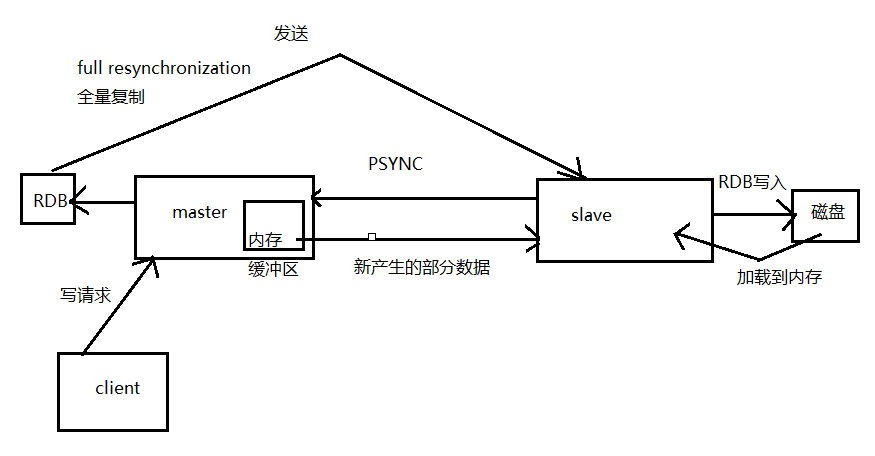
在redis主從架構中,master負責接收寫請求,寫操作成功後返回客戶端OK,然後後將資料非同步的方式傳送給多個slaver進行資料同步,不過從redis 2.8開始,slave node會週期性地確認自己每次複製的資料量。
當啟動一個slave node的時候,它會發送一個PSYNC命令給master node。如果slave node是重新連線master node,那麼master node僅僅會複製給slave部分缺少的資料; 否則如果是slave node第一次連線master node,那麼會觸發一次full resynchronization全量複製。
開始full resynchronization的時候,master會啟動一個後臺執行緒,開始生成一份RDB快照檔案,同時還會將從客戶端收到的所有寫命令快取在記憶體(記憶體緩衝區)中。RDB檔案生成完畢之後,master會將這個RDB傳送給slave,slave會先寫入本地磁碟,然後再從本地磁碟載入到記憶體中。然後master會將記憶體中快取的寫命令傳送給slave,slave也會同步這些資料。
另外slave node做複製的時候,是不會block master node的正常工作的,也不會block對自己的查詢操作,它會用舊的資料集來提供服務; 但是複製完成的時候,需要刪除舊資料集,載入新資料集,這個時候就會暫停對外服務了。slave node主要用來進行橫向擴容,做讀寫分離,擴容的slave node可以提高讀的吞吐量。slave與高可用性有很大的關係。
Tips:邊講邊畫圖最好了。
主從複製的過程中如果因為網路原因停止複製了會怎麼樣?
如果出現網路故障斷開連線了,會自動重連的,從redis 2.8開始,就支援主從複製的斷點續傳,可以接著上次複製的地方,繼續複製下去,而不是從頭開始複製一份。
master如果發現有多個slave node都來重新連線,僅僅會啟動一個rdb save操作,用一份資料服務所有slave node。
master node會在記憶體中建立一個backlog,master和slave都會儲存一個replica offset,還有一個master id,offset就是儲存在backlog中的。如果master和slave網路連線斷掉了,slave會讓master從上次的replica offset開始繼續複製。
但是如果沒有找到對應的offset,那麼就會執行一次resynchronization全量複製。
好的,那你能說說什麼是哨兵有什麼作用嗎?
哨兵是redis叢集架構中非常重要的一個元件,主要功能如下
(1)叢集監控,負責監控redis master和slave程序是否正常工作
(2)訊息通知,如果某個redis例項有故障,那麼哨兵負責傳送訊息作為報警通知給管理員
(3)故障轉移,如果master node掛掉了,會自動轉移到slave node上
(4)配置中心,如果故障轉移發生了,通知client客戶端新的master地址
哨兵本身也是分散式的,作為一個哨兵叢集去執行,互相協同工作
(1)故障轉移時,判斷一個master node是宕機了,需要大部分的哨兵都同意才行,涉及到了分散式選舉的問題
(2)即使部分哨兵節點掛掉了,哨兵叢集還是能正常工作的,因為如果一個作為高可用機制重要組成部分的故障轉移系統本身是單點的,那就很坑爹了。
目前採用的是sentinal 2版本,sentinal 2相對於sentinal 1來說,重寫了很多程式碼,主要是讓故障轉移的機制和演算法變得更加健壯和簡單。
為什麼redis哨兵叢集只有2個節點無法正常工作?
如果兩個哨兵例項,即兩個redis例項,一主一從的模式。
則redis的配置quorum=1,表示一個哨兵認為master宕機即可認為master已宕機。
但是如果是機器1宕機了,那哨兵1和master都宕機了,雖然哨兵2知道master宕機了,但是這個時候,需要majority,也就是大多數哨兵都是執行的,2個哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2個哨兵都執行著,就可以允許執行故障轉移。
但此時哨兵1沒了就只有1個哨兵了了,此時就沒有majority來允許執行故障轉移,所以故障轉移不會執行。
主備切換的時候會有資料丟失的可能嗎?
會有,而且有兩種可能,一種是非同步複製,一種是腦裂導致的資料丟失。
簡單描述一下這兩種資料丟失的過程吧
好的,第一種很好理解,因為master 到 slave的複製是非同步的,所以可能有部分資料還沒複製到slave的時候,master就宕機了,此時這些部分資料就丟失了。雖然master會做持久化,但是哨兵將slave提升為master後,如果舊的master這時候好了,會當做slave掛到新的master上,從新的master同步資料,原來的資料還是會丟失。
第二種,也就是說,某個master所在機器突然脫離了正常的網路,跟其他slave機器不能連線,但是實際上master還執行著,即叢集分割槽現象。此時哨兵可能就會認為master宕機了,然後開啟選舉,將其他slave切換成了master.
這個時候,叢集裡就會有兩個master,也就是所謂的腦裂。
此時雖然某個slave被切換成了master,但是可能client還沒來得及切換到新的master,還繼續向舊master寫資料,這部分資料可能就丟失了。因此舊master再次恢復的加入到主從結構中時,會被作為一個slave掛到新的master上去,自己的資料會清空,重新從新的master複製資料,原來的寫到舊master的資料就丟失了。
那有什麼辦法解決這個資料丟失的問題嗎?
資料丟失的問題是不可避免的,但是我們可以儘量減少。
在redis的配置檔案裡設定引數
min-slaves-to-write 1
min-slaves-max-lag 10
min-slaves-to-write預設情況下是0,min-slaves-max-lag預設情況下是10。
上面的配置的意思是要求至少有1個slave,資料複製和同步的延遲不能超過10秒。如果說一旦所有的slave,資料複製和同步的延遲都超過了10秒鐘,那麼這個時候,master就不會再接收任何請求了。
上面兩個配置可以減少非同步複製和腦裂導致的資料丟失。
設定了這倆引數具體是怎麼減少資料丟失的呢?
以上面配置為例,這兩個引數表示至少有1個salve的與master的同步複製延遲不能超過10s,一旦所有的slave複製和同步的延遲達到了10s,那麼此時master就不會接受任何請求。
我們可以減小min-slaves-max-lag引數的值,這樣就可以避免在發生故障時大量的資料丟失,一旦發現延遲超過了該值就不會往master中寫入資料。
那麼對於client,我們可以採取降級措施,將資料暫時寫入本地快取和磁碟中,在一段時間後重新寫入master來保證資料不丟失;也可以將資料寫入kafka訊息佇列,隔一段時間去消費kafka中的資料。
通過上面兩個引數的設定我們儘可能的減少資料的丟失,具體的值還需要在特定的環境下進行測試設定。
好的,今天回答的還不錯,下一輪面試繼續努力哦~
面試官顯然對你今天的回答比較滿意,已經邀請你下一輪面試了~~~
手機閱讀的使用者可移至公眾號哦,更方便

本系列文章在於面試突擊,不是教程,要是細挖,能講好多,而面試你只需要把這個原理說出來就行了,如果邊講邊畫圖那就更好了。
該系列文章在於快速突擊,快速拾遺,溫習。