
心跳與超時:高併發高效能的時間輪超時器
目錄
- 心跳與超時:高併發高效能的時間輪超時器
- 引言
- JDK 原生提供的超時任務支援
- java.util.Timer
- ScheduledThreadPoolExecutor
- 更高效的資料結構
- 基本原理
- 支撐更多超過範圍的延遲時間
- Netty 的時間輪實現
- 介面定義
- 構建迴圈陣列
- 新增延遲任務
- 工作執行緒workerThread
- 思考總結
心跳與超時:高併發高效能的時間輪超時器
引言
在許多業務場景中,我們都會碰到延遲任務,定時任務這種需求。特別的,在網路連線的場景中,常常會出現一些超時控制。由於服務端的連線數量很大,這些超時任務的數量往往也是很龐大的。實現對大量任務的超時管理並不是一個容易的事情。
本章我們將介紹幾種用於實現超時任務的資料結構,並且最後分析 Netty 在超時任務上採取的結構和程式碼。
歡迎加入技術交流群186233599討論交流,也歡迎關注筆者公眾號:風火說。
JDK 原生提供的超時任務支援
java.util.Timer
JDK 在 1.3 的時候引入了Timer
Timer的實現思路比較簡單,其內部有兩個主要屬性:
TaskQueue:定時任務抽象類TimeTask的列表。TimerThread:用於執行定時任務的執行緒。
Timer結構還定義了一個抽象類TimerTask並且繼承了Runnable介面。業務系統實現了這個抽象類的run方法用於提供具體的延時任務邏輯。
TaskQueue內部採用大頂堆的方式,依據任務的觸發時間進行排序。而TimerThread則以死迴圈的方式從TaskQueue獲取佇列頭,等待佇列頭的任務的超時時間到達後觸發該任務,並且將任務從佇列中移除。
Timer的資料結構和演算法都很容易理解。所有的超時任務都首先進入延時佇列。後臺超時執行緒不斷的從延遲佇列中獲取任務並且等待超時時間到達後執行任務。延遲佇列採用大頂堆排序,在延遲任務的場景中有三種操作,分別是:新增任務,提取佇列頭任務,檢視佇列頭任務。
檢視佇列頭任務的事件複雜度是 O(1) 。而新增任務和提取佇列頭任務的時間複雜度都是 O(Log2n) 。當任務數量較大時,新增和刪除的開銷也是比較大的。此外,由於Timer內部只有一個處理執行緒,如果有一個延遲任務的處理消耗了較多的時間,會對應的延遲後續任務的處理。
ScheduledThreadPoolExecutor
由於Timer只有一個執行緒用來處理延遲任務,在任務數量很多的時候顯然是不足夠的。在 JDK1.5 引入執行緒池介面ExecutorService後,也對應的提供了一個用於處理延時任務的ScheduledExecutorService子類介面。該介面內部也一樣使用了一個使用小頂堆進行排序的延遲佇列存放任務。執行緒池中的執行緒會在這個佇列上等待直到有任務可以提取。
ScheduledExecutorService的實現上有一些特殊,只有一個執行緒能夠提取到延遲佇列頭的任務,並且根據任務的超時時間進行等待。在這個等待期間,其他的執行緒是無法獲取任務的。這樣的實現是為了避免多個執行緒同時獲取任務,導致超時時間未到達就任務觸發或者在等待任務超時時間時有新的任務被加入而無法響應。
由於ScheduledExecutorService可以使用多個執行緒,這樣也緩解了因為個別任務執行時間長導致的後續任務被阻塞的情況。不過延遲佇列也是一樣採用小頂堆的排序方式,因此新增任務和刪除任務的時間複雜度都是 O(Log2n) 。在任務數量很大的情況下,效能表現比較差。
更高效的資料結構
雖然Timer和ScheduledThreadPoolExecutor都提供了對延遲任務的支撐能力,但是由於新增任務和提取任務的時間複雜度都是 O(Log2n) ,在任務數量很大,比如幾萬,十幾萬的時候,效能的開銷就變得很巨大。
那麼,是否存在新增任務和提取任務比 O(Log2n) 複雜度更低的資料結構呢?答案是存在的。在論文《Hashed and Hierarchical Timing Wheels》中設計了一種名為時間輪( Timing Wheels )的資料結構,這種結構在處理延遲任務時,其新增任務和刪除任務的時間複雜度降低到了 O(1) 。
基本原理
時間輪的資料結構很類似於我們鐘錶上的資料指標,故而得名時間輪。其資料結構用圖示意如下
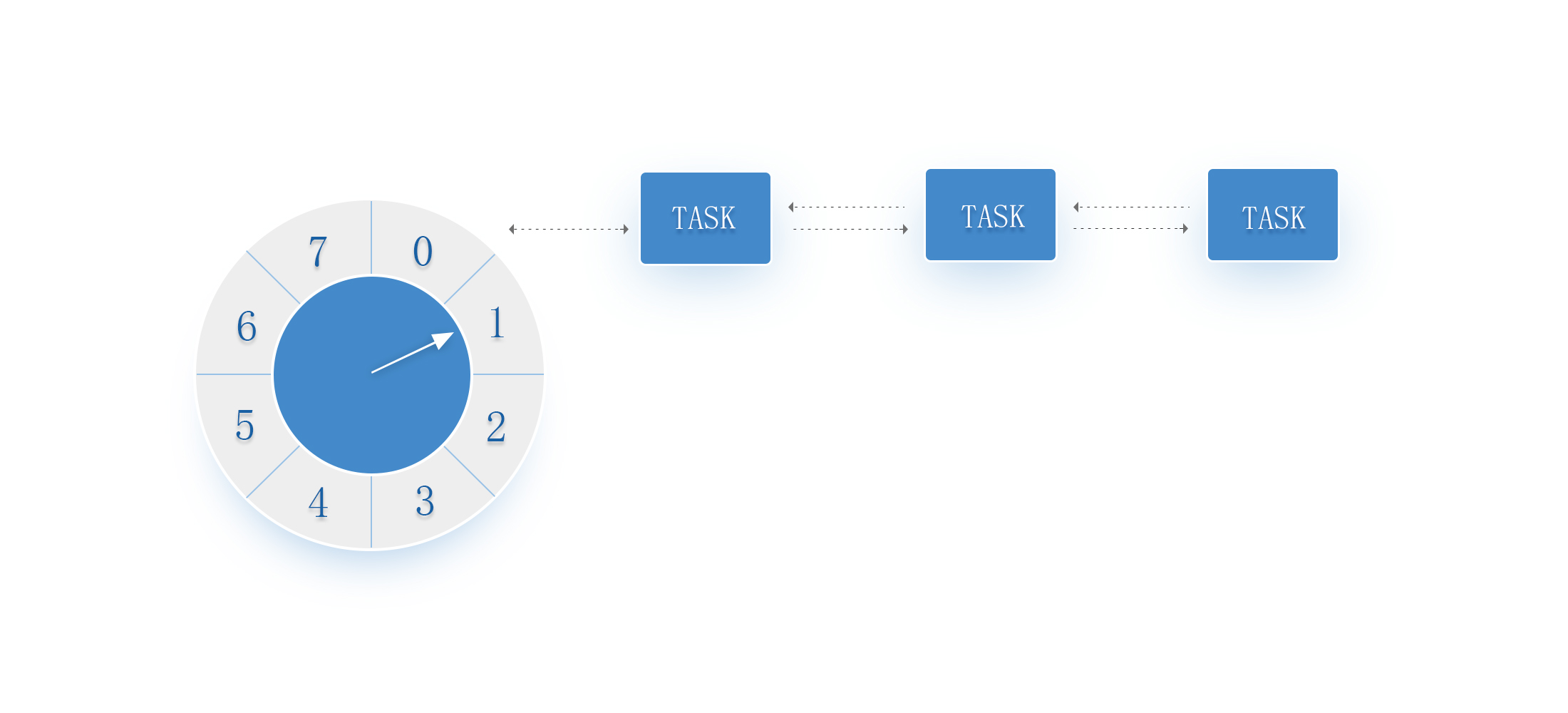
每一個時間“格子”我們稱之為槽位,槽位中存放著延遲任務佇列。槽位本身代表著一個時間單位,比如 1 秒。時間輪擁有的槽位個數就是該時間輪能夠處理的最大延遲跨度的任務,槽位的時間單位代表著時間輪的精度。這意味著小於時間單位的時間在該時間輪是無法被區分的。
槽位上的延遲任務佇列中的任務都有相同的延遲時間。每一個單位時間,指標都會移動到下一個槽位。當指標指向某一個槽位時,該槽位的延遲任務佇列中的任務都會被觸發。
當有一個延遲任務要插入時間輪時,首先計算其延遲時間與單位時間的餘值,從指標指向的當前槽位移動餘值的個數槽位,就是該延遲任務需要被放入的槽位。
舉個例子,時間輪有8個槽位,編號為 0 ~ 7 。指標當前指向槽位 2 。新增一個延遲時間為 4 秒的延遲任務,4 % 8 = 4,因此該任務會被插入 4 + 2 = 6,也就是槽位6的延遲任務佇列。
時間輪的槽位實現可以採用迴圈陣列的方式達成,也就是讓指標在越過陣列的邊界後重新回到起始下標。概括來說,可以將時間輪的演算法描述為
用佇列來儲存延遲任務,同一個佇列中的任務,其延遲時間相同。用迴圈陣列的方式來儲存元素,陣列中的每一個元素都指向一個延遲任務佇列。
有一個當前指標指向陣列中的某一個槽位,每間隔一個單位時間,指標就移動到下一個槽位。被指標指向的槽位的延遲佇列,其中的延遲任務全部被觸發。
在時間輪中新增一個延遲任務,將其延遲時間除以單位時間得到的餘值,從當前指標開始,移動餘值對應個數的槽位,就是延遲任務被放入的槽位。
基於這樣的資料結構,插入一個延遲任務的時間複雜度就下降到 O(1) 。而當指標指向到一個槽位時,該槽位連線的延遲任務佇列中的延遲任務全部被觸發。
延遲任務的觸發和執行不應該影響指標向後移動的時間精確性。因此一般情況下,用於移動指標的執行緒只負責任務的觸發,任務的執行交由其他的執行緒來完成。比如,可以將槽位上的延遲任務佇列放入到額外的執行緒池中執行,然後在槽位上新建一個空白的新的延遲任務佇列用於後續任務的新增。
支撐更多超過範圍的延遲時間
在基本原理中我們分析了時間輪的基礎結構。不過當時我們假設需要插入的延遲任務的時間不會超過時間輪的長度,也就是說每一個槽位上的延遲任務佇列中的任務的延遲時間都是相同的。
在這種情況下,要支援更大時間跨度的延遲任務,要麼增加時間輪的槽位數,要麼減少時間輪的精度,也就是每一個槽位代表的單位時間。時間輪的精度顯然是一個業務上的硬性要求,那麼只能增加槽位數。假設要求精度為 1 秒,要能支援延遲時間為 1 天的延遲任務,時間輪的槽位數需要 60 × 60 × 24 = 86400 。這就需要消耗更多的記憶體。顯然,單純增加槽位數並不是一個好的解決方案。
在論文中,針對大跨度的延遲任務支援,提供了兩種擴充套件方案。
方案一:不同輪次的延遲任務共存相同的延遲佇列
在該方案中,演算法引入了“輪次”的概念,延遲任務的延遲時間除以時間輪長度得到的商值為輪次。延遲任務的延遲時間除以時間輪長度得到的餘數為要插入的槽位偏移量。
當插入延遲任務時首先計算輪次和槽位偏移量,通過槽位偏移量確定延遲任務插入的槽位。當指標指向某一個槽位時,對槽位指向的延遲任務佇列進行遍歷,其中輪次為0的延遲任務全部觸發,其餘任務則等待下一個週期。
通過引入輪次,就可以在有限的槽位上支援無窮時間範圍的延遲任務。但是雖然插入任務的時間複雜度仍然是 O(1) ,但是在延遲任務觸發時卻需要遍歷延遲任務佇列來確認其輪次是否為0。任務觸發時的時間複雜卻上升為了 O(n) 。
對於這個情況,還有一個變化的細節可以採用,就是將延遲任務佇列按照輪次進行排序,比方說使用小頂堆對延遲任務佇列進行排序。這樣,當指標指向一個槽位觸發延遲任務時,只需要不斷的從佇列頭取出任務進行輪次檢查,一旦任務輪次不等於0就可以停止。任務觸發的時間複雜度下降為 O(1) 。對應的,由於佇列是排序的了,任務插入的時候除了需要定位插入的槽位,還需要定位在佇列中的插入位置。插入的時間複雜度變化為 O(1) 和 O(Log2n) ,n 為該槽位上延遲任務佇列的長度。
方案二:多層次時間輪
看看手錶的設計,有秒針,分針,時針。像秒針與分針,雖然都有 60 格 ,但是各自的格子代表的時間長度不同。參考這個思路,我們可以宣告多個不同層級的時間輪,每一個時間輪的槽位的時間跨度是其次級時間輪的整體時間範圍。
當低層級的時間輪的指標完整的走完一圈,其對應的高層級時間輪對應的移動一個槽位。並且高層級時間輪指標指向的槽位中的任務按照延遲時間計算,重新放入到低層級時間輪的不同槽位中。這樣的方式,保證了每一個時間輪中的每一個槽位的延遲任務佇列中的任務都具備相同時間精度的延遲時間。
以精度為 1 秒,時間範圍為 1 天的時間輪為例子,可以設計三級時間輪:秒級時間輪有 60 個槽位,每個槽位的時間為 1 秒;分鐘級時間輪有 60 個槽位,每個槽位的時間為 60 秒;小時級時間輪有24個槽位,每個槽位的時間為 60 分鐘。當秒級時間輪走完 60 秒後,秒級時間輪的指標再次指向下標為0的槽位,而分鐘級時間輪的指標向後移動一個槽位,並且將該槽位上的延遲任務全部取出並且重新計算後放入秒級時間輪。
總共只需要 60 + 60 + 24 = 144 個槽位即可支撐。對比上面提到的單級時間輪需要 86400 個槽位而言,節省了相當的記憶體。
層級時間輪有兩種常見的做法:
- 固定時間範圍:時間輪的個數,以及不同層級的時間輪的槽位數是通過構造方法的入參指定,這意味著時間輪整體能夠支撐的時間範圍是在構造方法的時候被確定。
- 非固定時間範圍:定義好一個時間輪的槽位個數,以及最小的時間輪的槽位時間。當插入的延遲任務的時間超過時間輪範圍時則動態生成更高層級的時間輪。由於時間輪是在執行期生成,並且根據任務的延遲時間計算,當已經存在的時間輪不滿足其延遲時間範圍要求時,動態生成高層級時間輪,因此整體能夠支撐的時間範圍是沒有上限的。
Netty 的時間輪實現
時間輪演算法的核心思想就是通過迴圈陣列和指標移動的方式,將新增延遲任務的時間複雜度下降到 O(1) ,但是在具體實現上,包括如何處理更大時間跨度的延遲任務上,各家不同的實現都會有一些細節上的變化。下面我們以 Netty 中都時間輪實現為例子來進行程式碼分析。
介面定義
Netty 的實現自定義了一個超時器的介面io.netty.util.Timer,其方法如下
public interface Timer
{
//新增一個延時任務,入參為定時任務TimerTask,和對應的延遲時間
Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);
//停止時間輪的執行,並且返回所有未被觸發的延時任務
Set < Timeout > stop();
}
public interface Timeout
{
Timer timer();
TimerTask task();
boolean isExpired();
boolean isCancelled();
boolean cancel();
}Timeout介面是對延遲任務的一個封裝,其介面方法說明其實現內部需要維持該延遲任務的狀態。後續我們分析其實現內部程式碼時可以更容易的看到。
Timer介面有唯一實現HashedWheelTimer。首先來看其構造方法,如下
構建迴圈陣列
public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection, long maxPendingTimeouts)
{
//省略程式碼,省略引數非空檢查內容。
wheel = createWheel(ticksPerWheel);
mask = wheel.length - 1;
//省略程式碼,省略槽位時間範圍檢查,避免溢位以及小於 1 毫秒。
workerThread = threadFactory.newThread(worker);
//省略程式碼,省略資源洩漏追蹤設定以及時間輪例項個數檢查
}首先是方法createWheel,用於建立時間輪的核心資料結構,迴圈陣列。來看下其方法內容
private static HashedWheelBucket[] createWheel(int ticksPerWheel)
{
//省略程式碼,確認 ticksPerWheel 處於正確的區間
//將 ticksPerWheel 規範化為 2 的次方冪大小。
ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);
HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];
for(int i = 0; i < wheel.length; i++)
{
wheel[i] = new HashedWheelBucket();
}
return wheel;
}陣列的長度為 2 的次方冪方便進行求商和取餘計算。
HashedWheelBucket內部儲存著由HashedWheelTimeout節點構成的雙向連結串列,並且儲存著連結串列的頭節點和尾結點,方便於任務的提取和插入。
新增延遲任務
方法HashedWheelTimer#newTimeout用於新增延遲任務,下面來看下程式碼
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit)
{
//省略程式碼,用於引數檢查
start();
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
if(delay > 0 && deadline < 0)
{
deadline = Long.MAX_VALUE;
}
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}可以看到,在新增任務的時候,任務並不是直接進入到迴圈陣列中,而是首先被放入到一個佇列,也就是屬性timeouts,該佇列是一個 MPSC 型別的佇列,採用這個模式主要出於提升併發效能考慮,因為這個佇列只有執行緒workerThread會進行任務提取操作。
該執行緒是在構造方法中通過呼叫workerThread = threadFactory.newThread(worker)被建立。但是建立之後並不是馬上執行執行緒的start方法,其啟動的時機是這個時間輪第一次新增延遲任務的時候,也就是本方法中的start方法的內容。下面是其程式碼
public void start()
{
switch(WORKER_STATE_UPDATER.get(this))
{
case WORKER_STATE_INIT:
if(WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED))
{
workerThread.start();
}
break;
case WORKER_STATE_STARTED:
break;
case WORKER_STATE_SHUTDOWN:
throw new IllegalStateException("cannot be started once stopped");
default:
throw new Error("Invalid WorkerState");
}
while(startTime == 0)
{
try
{
startTimeInitialized.await();
}
catch(InterruptedException ignore)
{
// Ignore - it will be ready very soon.
}
}
}方法很明顯的分為兩個部分,第一部分為Switch方法塊,通過對狀態變數的 CAS 操作,確保只有一個執行緒能夠執行workerThread.start()方法來啟動工作執行緒,避免併發異常。第二部分為阻塞等待,通過CountDownLatch型別變數startTimeInitialized執行阻塞等待,用於等待工作執行緒workerThread真正進入工作狀態。
從newTimeout方法的角度來看,插入延遲任務首先是放入佇列中,之前分析資料結構的時候也說過任務的觸發是指標指向時間輪中某個槽位時進行,那麼必然存在一個需要將佇列中的延遲任務放入到時間輪的陣列之中的工作。這個動作顯然就是就是由workerThread工作執行緒來完成。下面就來看下這個執行緒的具體程式碼內容。
工作執行緒workerThread
工作執行緒是依託於HashedWheelTimer.Worker這個實現了Runnable介面的類進行工作的,那下面看下其對run方法的實現程式碼,如下
public void run()
{
{//程式碼塊①
startTime = System.nanoTime();
if(startTime == 0)
{
//使用startTime==0 作為執行緒進入工作狀態模式標識,因此這裡重新賦值為1
startTime = 1;
}
//通知外部初始化工作執行緒的執行緒,工作執行緒已經啟動完畢
startTimeInitialized.countDown();
}
{//程式碼塊②
do {
final long deadline = waitForNextTick();
if(deadline > 0)
{
int idx = (int)(tick & mask);
processCancelledTasks();
HashedWheelBucket bucket = wheel[idx];
transferTimeoutsToBuckets();
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
}
{//程式碼塊③
for(HashedWheelBucket bucket: wheel)
{
bucket.clearTimeouts(unprocessedTimeouts);
}
for(;;)
{
HashedWheelTimeout timeout = timeouts.poll();
if(timeout == null)
{
break;
}
if(!timeout.isCancelled())
{
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}
}執行緒啟動與準備工作
為了方便閱讀,這邊將run方法的內容分為三個程式碼塊。首先來看程式碼塊①。通過系統呼叫System.nanoTime為啟動時間startTime設定初始值,該變數代表了時間輪的基線時間,用於後續相對時間的計算。賦值完畢後,通過startTimeInitialized變數對外部的等待執行緒進行通知。
驅動指標和任務觸發
接著來看程式碼塊②。這是主要的工作部分,整體是在一個while迴圈中,確保工作執行緒只在時間輪沒有被終止的時候工作。首先來看方法waitForNextTick,在時間輪中,指標移動一次,稱之為一個tick,這個方法顯然內部應該是用於等待指標移動到下一個tick,來看具體程式碼,如下
private long waitForNextTick()
{
long deadline = tickDuration * (tick + 1);
for(;;)
{
final long currentTime = System.nanoTime() - startTime;
long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;
if(sleepTimeMs <= 0)
{
if(currentTime == Long.MIN_VALUE)
{
return -Long.MAX_VALUE;
}
else
{
return currentTime;
}
}
if(PlatformDependent.isWindows())
{
sleepTimeMs = sleepTimeMs / 10 * 10;
}
try
{
Thread.sleep(sleepTimeMs);
}
catch(InterruptedException ignored)
{
if(WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN)
{
return Long.MIN_VALUE;
}
}
}
}整個方法的思路很簡單,前面說過,時間輪每移動一次指標,意味著一個tick。這裡tick可以看成是指標移動的次數。由於槽位的時間範圍是固定的,因此可以簡單的計算出來指標移動到下一個槽位,理論上應該經過的時間,也就是long deadline = tickDuration * (tick + 1) 。之後再計算從時間輪啟動到當前,實際經過的時間,也就是long currentTime = System.nanoTime() - startTime 。二者的差值就是執行緒所需要睡眠的時間。
如果差值小於0,意味著實際經過的時間超過了理論時間,此時已經超出了應該休眠的範圍,方法需要立即返回。由於在這個方法的執行過程中,可能會遇到時間輪被停止的情況,因此使用一個特殊值來表達這個事件,也就是Long.MIN_VALUE,這也是為什麼currentTime要避開這個值的原因。
還有一點需要注意,Thread.sleep方法的實現是依託於作業系統提供的中斷檢查,也就是作業系統會在每一箇中斷的時候去檢查是否有執行緒需要喚醒並且提供CPU資源。預設情況下 Linux 的中斷間隔是 1 毫秒,而 Windows 的中斷間隔是 10 毫秒或者 15 毫秒,具體取決於硬體識別。
如果是在 Windows 平臺下,當方法呼叫Thread.sleep傳入的引數不是10的整數倍時,其內部會呼叫系統方法timeBeginPeriod()和timeEndPeriod()來修改中斷週期為 1 毫秒,並且在休眠結束後再次設定回預設值。這樣的目的是為了保證休眠時間的準確性。但是在 Windows 平臺下,頻繁的呼叫修改中斷週期會導致 Windows 時鐘出現異常,大多數時候的表現是導致時鐘加快。這將導致比如嘗試休眠 10 秒時,實際上只休眠了 9 秒。所以在這裡,通過sleepTimeMs = sleepTimeMs / 10 * 10保證了sleepTimeMs 是 10 的整數倍,從而避免了 Windows 的這個 BUG 。
當方法waitForNextTick返回後,並且返回的值是正數,意味著當前tick的休眠等待已經完成,可以進行延遲任務的觸發處理了。通過int idx = (int)(tick & mask)呼叫,確定下一個被觸發延遲任務的槽位在迴圈陣列中的下標。在處理觸發任務之前,首先將已經取消的延遲任務從槽位所指向的延遲任務佇列中刪除。每次呼叫HashedWheelTimer#newTimeout新增延遲任務時都會返回一個Timeout物件,可以通過cancle方法將這個延遲任務取消。當執行取消動作的時候,並不會直接從延遲佇列中刪除,而是將這個物件放入到取消佇列,也就是HashedWheelTimer.cancelledTimeouts屬性。在準備遍歷槽位上延遲任務佇列之前,通過方法processCancelledTasks來遍歷這個取消佇列,將其中的延遲任務從各自槽位上的延遲任務佇列中刪除。使用這種方式的好處在於延遲任務的刪除只有一個執行緒會進行,避免了多執行緒帶來的併發干擾,減少了開發難度。
在處理完取消的延遲任務後,呼叫方法transferTimeoutsToBuckets來將新增延遲任務佇列HashedWheelTimer.timeouts中的延遲任務分別新增到合適其延遲時間的槽位中。方法的程式碼很簡單,就是迴圈不斷從timeouts取出任務,並且計算其延遲時間與時間輪範圍的商值和餘數,結果分別為其輪次與槽位下標。根據槽位下標將該任務新增到槽位對應的延遲任務佇列中。
在這裡可以看到 Netty 作者對時間輪這一結構的併發設計,新增任務是向 MPSC 佇列新增元素實現。而槽位上的延遲任務佇列只有時間輪本身的執行緒能夠進行新增和刪除,設計為了 SPSC 模式。前者是為了提高無鎖併發下的效能,後者則是通過約束,減少了設計難度。
transferTimeoutsToBuckets方法每次最多隻會轉移 100000 個延遲任務到合適的槽位中,這是為了避免外部迴圈新增任務導致的餓死。方法執行完畢後,就到了槽位上延遲任務的觸發處理,也就是方法HashedWheelBucket#expireTimeouts的功能,方法內的邏輯也很簡單。遍歷佇列,如果延遲任務的輪次不為 0,則減 1。否則觸發任務執行方法,也就是HashedWheelTimeout#expire。該方法內部依然通過 CAS 方式對狀態進行更新,避免方法的觸發和取消之間的競爭衝突。從這個方法的實現可以看到,Netty 採用了輪次的方式來對超出時間輪範圍的延遲時間進行支援。多層級時間輪的實現相比輪次概念的實現更為複雜,考慮到在網路IO應用中,超出時間輪範圍的場景比較少,使用輪次的方式去支撐更大的時間,是一個相對容易實現的方案。
當需要被觸發的延遲任務都被觸發後,通過tick加 1 來表達指標移動到下一個槽位。
時間輪停止
外部執行緒通過呼叫HashedWheelTimer#stop方法來停止時間輪,停止的方式很簡單,就是通過 CAS 呼叫來修改時間輪的狀態屬性。而在程式碼塊②中通過迴圈的方式在每一次tick都會檢查這個狀態位。程式碼塊③的內容很簡單,遍歷所有的槽位,並且遍歷槽位的延遲任務佇列,將所有未到達延遲時間並且未取消的任務,都放入到一個集合中,最終將這個集合返回。這個集合記憶體儲的就是所有未能執行的延遲任務。
思考總結
在處理大量延遲任務的場景中,時間輪是一個很高效的演算法與資料結構。Netty 在對時間輪的實現上,在新增任務,過期任務,刪除任務等環節進行了一些細節上的調整。實際上,不同中介軟體中都有對時間輪的一些實現,各自也都有區別,但是核心都是圍繞在迴圈陣列與槽位過期這個概念上。不同的細節變化有各自適合的場景和考量。