
原始碼詳解系列(八) ------ 全面講解HikariCP的使用和原始碼
簡介
HikariCP 是用於建立和管理連線,利用“池”的方式複用連線減少資源開銷,和其他資料來源一樣,也具有連線數控制、連線可靠性測試、連線洩露控制、快取語句等功能,另外,和 druid 一樣,HikariCP 也支援監控功能。
HikariCP 是目前最快的連線池,就連風靡一時的 BoneCP 也停止維護,主動讓位給它,SpringBoot 也把它設定為預設連線池。
看過 HikariCP 原始碼的同學就會發現,相比其他連線池,它真的非常輕巧且簡單,有許多值得我們學習的地方,尤其效能提升方面,本文也就針對這一方面重點分析。
本文將包含以下內容(因為篇幅較長,可根據需要選擇閱讀):
- HikariCP 的使用方法(入門案例、JDNI 使用、JMX 使用)
- HikariCP 的配置引數詳解
- HikariCP 原始碼分析
其他連線池的內容也可以參考我的系列部落格:
原始碼詳解系列(四) ------ DBCP2的使用和分析(包括JNDI和JTA支援)
原始碼詳解系列(五) ------ C3P0的使用和分析(包括JNDI)
原始碼詳解系列(六) ------ 全面講解druid的使用和原始碼
使用例子-入門
需求
使用 HikariCP 連線池獲取連線物件,對使用者資料進行簡單的增刪改查(sql 指令碼專案中已提供)。
工程環境
JDK:1.8.0_231
maven:3.6.1
IDE:Spring Tool Suite 4.3.2.RELEASE
mysql-connector-java:8.0.15
mysql:5.7 .28
Hikari:2.6.1
主要步驟
編寫 hikari.properties,設定資料庫連線引數和連線池基本引數等;
通過
HikariConfig載入 hikari.properties 檔案,並建立HikariDataSource物件;通過
HikariDataSource物件獲得Connection物件;使用
Connection物件對使用者表進行增刪改查。
建立專案
專案型別Maven Project,打包方式war(其實jar也可以,之所以使用war是為了測試 JNDI)。
引入依賴
這裡引入日誌包,主要為了列印配置資訊,不引入不會有影響的。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hikari -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>2.6.1</version>
</dependency>
<!-- mysql驅動 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<!-- log -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<type>jar</type>
</dependency>編寫hikari.properties
配置檔案路徑在resources目錄下,因為是入門例子,這裡僅給出資料庫連線引數和連線池基本引數,後面會對所有配置引數進行詳細說明。另外,資料庫 sql 指令碼也在該目錄下。
#-------------基本屬性--------------------------------
jdbcUrl=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#JDBC驅動使用的Driver實現類類名
#預設為空。會根據jdbcUrl來解析
driverClassName=com.mysql.cj.jdbc.Driver
#-------------連線池大小相關引數--------------------------------
#最大連線池數量
#預設為10。可通過JMX動態修改
maximumPoolSize=10
#最小空閒連線數量
#預設與maximumPoolSize一致。可通過JMX動態修改
minimumIdle=0獲取連線池和獲取連線
專案中編寫了JDBCUtil來初始化連線池、獲取連線、管理事務和釋放資源等,具體參見專案原始碼。
路徑:cn.zzs.hikari
HikariConfig config = new HikariConfig("/hikari.properties");
DataSource dataSource = new HikariDataSource(config);編寫測試類
這裡以儲存使用者為例,路徑在 test 目錄下的cn.zzs.hikari。
@Test
public void save() {
// 建立sql
String sql = "insert into demo_user values(null,?,?,?,?,?)";
Connection connection = null;
PreparedStatement statement = null;
try {
// 獲得連線
connection = JDBCUtil.getConnection();
// 開啟事務設定非自動提交
JDBCUtil.startTrasaction();
// 獲得Statement物件
statement = connection.prepareStatement(sql);
// 設定引數
statement.setString(1, "zzf003");
statement.setInt(2, 18);
statement.setDate(3, new Date(System.currentTimeMillis()));
statement.setDate(4, new Date(System.currentTimeMillis()));
statement.setBoolean(5, false);
// 執行
statement.executeUpdate();
// 提交事務
JDBCUtil.commit();
} catch(Exception e) {
JDBCUtil.rollback();
log.error("儲存使用者失敗", e);
} finally {
// 釋放資源
JDBCUtil.release(connection, statement, null);
}
}使用例子-通過JNDI獲取資料來源
需求
本文測試使用 JNDI 獲取HikariDataSource物件,選擇使用tomcat 9.0.21作容器。
如果之前沒有接觸過 JNDI ,並不會影響下面例子的理解,其實可以理解為像 spring 的 bean 配置和獲取。
引入依賴
本文在入門例子的基礎上增加以下依賴,因為是 web 專案,所以打包方式為 war:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>javax.servlet.jsp-api</artifactId>
<version>2.2.1</version>
<scope>provided</scope>
</dependency>編寫context.xml
在webapp檔案下建立目錄META-INF,並建立context.xml檔案。這裡面的每個 resource 節點都是我們配置的物件,類似於 spring 的 bean 節點。其中jdbc/hikariCP-test可以看成是這個 bean 的 id。
HikariCP 提供了HikariJNDIFactory來支援 JNDI 。
注意,這裡獲取的資料來源物件是單例的,如果希望多例,可以設定singleton="false"。
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resource
name="jdbc/hikariCP-test"
factory="com.zaxxer.hikari.HikariJNDIFactory"
auth="Container"
type="javax.sql.DataSource"
jdbcUrl="jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true"
username="root"
password="root"
driverClassName="com.mysql.cj.jdbc.Driver"
maximumPoolSize="10"
minimumIdle="0"
/>
</Context>編寫web.xml
在web-app節點下配置資源引用,每個resource-ref指向了我們配置好的物件。
<!-- JNDI資料來源 -->
<resource-ref>
<res-ref-name>jdbc/hikariCP-test</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>編寫jsp
因為需要在web環境中使用,如果直接建類寫個main方法測試,會一直報錯的,目前沒找到好的辦法。這裡就簡單地使用jsp來測試吧。
<body>
<%
String jndiName = "java:comp/env/jdbc/druid-test";
InitialContext ic = new InitialContext();
// 獲取JNDI上的ComboPooledDataSource
DataSource ds = (DataSource) ic.lookup(jndiName);
JDBCUtils.setDataSource(ds);
// 建立sql
String sql = "select * from demo_user where deleted = false";
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
// 查詢使用者
try {
// 獲得連線
connection = JDBCUtils.getConnection();
// 獲得Statement物件
statement = connection.prepareStatement(sql);
// 執行
resultSet = statement.executeQuery();
// 遍歷結果集
while(resultSet.next()) {
String name = resultSet.getString(2);
int age = resultSet.getInt(3);
System.err.println("使用者名稱:" + name + ",年齡:" + age);
}
} catch(SQLException e) {
System.err.println("查詢使用者異常");
} finally {
// 釋放資源
JDBCUtils.release(connection, statement, resultSet);
}
%>
</body>測試結果
打包專案在tomcat9上執行,訪問 http://localhost:8080/hikari-demo/testJNDI.jsp ,控制檯列印如下內容:
使用者名稱:zzs001,年齡:18
使用者名稱:zzs002,年齡:18
使用者名稱:zzs003,年齡:25
使用者名稱:zzf001,年齡:26
使用者名稱:zzf002,年齡:17
使用者名稱:zzf003,年齡:18使用例子-通過JMX管理連線池
需求
開啟 HikariCP 的 JMX 功能,並使用 jconsole 檢視。
修改hikari.properties
在例子一基礎上增加如下配置。這要設定 registerMbeans 為 true,JMX 功能就會開啟。
#-------------JMX--------------------------------
#是否允許通過JMX掛起和恢復連線池
#預設為false
allowPoolSuspension=false
#是否開啟JMX
#預設false
registerMbeans=true
#資料來源名,一般用於JMX。
#預設自動生成
poolName=zzs001編寫測試類
為了檢視具體效果,這裡讓主執行緒進入睡眠,避免結束。
public static void main(String[] args) throws InterruptedException {
new HikariDataSourceTest().findAll();
Thread.sleep(60 * 60 * 1000);
}使用jconsole檢視
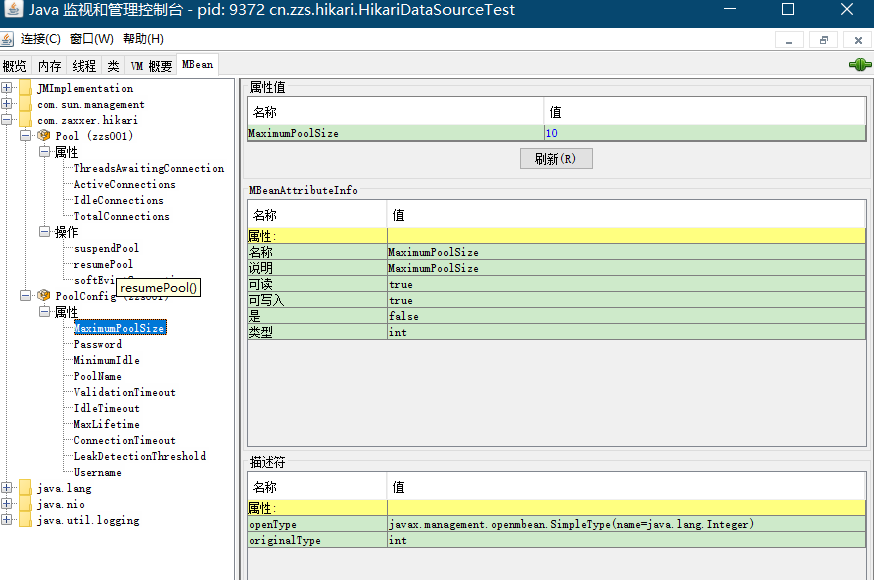
執行專案,開啟 jconsole,選擇我們的專案後點連線,在 MBean 選項卡可以看到我們的專案。通過 PoolConfig 可以動態修改配置(只有部分引數允許修改);通過 Pool 可以獲取連線池的連線數(活躍、空閒和所有)、獲取等待連線的執行緒數、掛起和恢復連線池、丟棄未使用連線等。
想了解更多 JMX 功能可以參考我的部落格文章: 如何使用JMX來管理程式?
配置檔案詳解編寫
相比其他連線池,HikariCP 的配置引數非常簡單,其中有幾個功能需要注意:HikariCP 強制開啟借出測試和空閒測試,不開啟回收測試,可選的只有洩露測試。
資料庫連線引數
注意,這裡在url後面拼接了多個引數用於避免亂碼、時區報錯問題。 補充下,如果不想加入時區的引數,可以在mysql命令視窗執行如下命令:set global time_zone='+8:00'。
#-------------基本屬性--------------------------------
jdbcUrl=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#JDBC驅動使用的Driver實現類類名
#預設為空。會根據jdbcUrl來解析
driverClassName=com.mysql.cj.jdbc.Driver連線池資料基本引數
這兩個引數都比較常用,建議根據具體專案調整。
#-------------連線池大小相關引數--------------------------------
#最大連線池數量
#預設為10。可通過JMX動態修改
maximumPoolSize=10
#最小空閒連線數量
#預設與maximumPoolSize一致。可通過JMX動態修改
minimumIdle=0連線檢查引數
針對連線失效的問題,HikariCP 強制開啟借出測試和空閒測試,不開啟回收測試,可選的只有洩露測試。
#-------------連線檢測情況--------------------------------
#用來檢測連線是否有效的sql,要求是一個查詢語句,常用select 'x'
#如果驅動支援JDBC4,建議不設定,因為這時預設會呼叫Connection.isValid()方法來檢測,該方式效率會更高
#預設為空
connectionTestQuery=select 1 from dual
#檢測連線是否有效的超時時間,單位毫秒
#最小允許值250 ms
#預設5000 ms。可通過JMX動態修改
validationTimeout=5000
#連線保持空閒而不被驅逐的最小時間。單位毫秒。
#該配置只有再minimumIdle < maximumPoolSize才會生效,最小允許值為10000 ms。
#預設值10000*60 = 10分鐘。可通過JMX動態修改
idleTimeout=600000
#連線物件允許“洩露”的最大時間。單位毫秒
#最小允許值為2000 ms。
#預設0,表示不開啟洩露檢測。可通過JMX動態修改
leakDetectionThreshold=0
#連線最大存活時間。單位毫秒
#最小允許值30000 ms
#預設30分鐘。可通過JMX動態修改
maxLifetime=1800000
#獲取連線時最大等待時間,單位毫秒
#獲取時間超過該配置,將丟擲異常。最小允許值250 ms
#預設30000 ms。可通過JMX動態修改
connectionTimeout=300000
#在啟動連線池前獲取連線的超時時間,單位毫秒
#>0時,會嘗試獲取連線。如果獲取時間超過指定時長,不會開啟連線池,並丟擲異常
#=0時,會嘗試獲取並驗證連線。如果獲取成功但驗證失敗則不開啟池,但是如果獲取失敗還是會開啟池
#<0時,不管是否獲取或校驗成功都會開啟池。
#預設為1
initializationFailTimeout=1事務相關引數
建議保留預設就行。
#-------------事務相關的屬性--------------------------------
#當連線返回池中時是否設定自動提交
#預設為true
autoCommit=true
#當連線從池中取出時是否設定為只讀
#預設值false
readOnly=false
#連線池建立的連線的預設的TransactionIsolation狀態
#可用值為下列之一:NONE,TRANSACTION_READ_UNCOMMITTED, TRANSACTION_READ_COMMITTED, TRANSACTION_REPEATABLE_READ, TRANSACTION_SERIALIZABLE
#預設值為空,由驅動決定
transactionIsolation=TRANSACTION_REPEATABLE_READ
#是否在事務中隔離內部查詢。
#autoCommit為false時才生效
#預設false
isolateInternalQueries=falseJMX引數
建議不開啟 allowPoolSuspension,對效能影響較大,後面原始碼分析會解釋原因。
#-------------JMX--------------------------------
#是否允許通過JMX掛起和恢復連線池
#預設為false
allowPoolSuspension=false
#是否開啟JMX
#預設false
registerMbeans=true
#資料來源名,一般用於JMX。
#預設自動生成
poolName=zzs001其他
注意,這裡的 dataSourceJndiName 不是前面例子中的 jdbc/hikariCP-test,這個資料來源是用來建立原生連線物件的,一般用不到。
#-------------其他--------------------------------
#資料庫目錄
#預設由驅動決定
catalog=github_demo
#由JDBC驅動提供的資料來源類名
#不支援XA資料來源。如果不設定,預設會採用DriverManager來獲取連線物件
#注意,如果設定了driverClassName,則不允許再設定dataSourceClassName,否則會報錯
#預設為空
#dataSourceClassName=
#JNDI配置的資料來源名
#預設為空
#dataSourceJndiName=
#在每個連接獲取後、放入池前,需要執行的初始化語句
#如果執行失敗,該連線會被丟棄
#預設為空
#connectionInitSql=
#-------------以下引數僅支援通過IOC容器或程式碼配置的方式--------------------------------
#TODO
#預設為空
#metricRegistry
#TODO
#預設為空
#healthCheckRegistry
#用於Hikari包裝的資料來源例項
#預設為空
#dataSource
#用於建立執行緒的工廠
#預設為空
#threadFactory=
#用於執行定時任務的執行緒池
#預設為空
#scheduledExecutor=原始碼分析
HikariCP 的原始碼輕巧且簡單,讀起來不會太吃力,所以,這次不會從頭到尾地分析程式碼邏輯,更多地會分析一些設計巧妙的地方。
在閱讀 HiakriCP 原始碼之前,需要掌握:CopyOnWriteArrayList、AtomicInteger、SynchronousQueue、Semaphore、AtomicIntegerFieldUpdater等工具。
注意:考慮篇幅和可讀性,以下程式碼經過刪減,僅保留所需部分 。
HikariCP為什麼快?
結合原始碼分析以及參考資料,相比 DBCP 和 C3P0 等連線池,HikariCP 快主要有以下幾個原因:
- 通過程式碼設計和優化大幅減少執行緒間的鎖競爭。這一點主要通過
ConcurrentBag來實現,下文會展開。 - 引入了更多 JDK 的特性,尤其是 concurrent 包的工具。DBCP 和 C3P0 出現時間較早,基於早期的 JDK 進行開發,也就很難享受到後面更新帶來的福利;
- 使用 javassist 直接修改 class 檔案生成動態代理,精簡了很多不必要的位元組碼,提高代理方法執行速度。相比 JDK 和 cglib 的動態代理,通過 javassist 直接修改 class 檔案生成的代理類在執行上會更快一些(這是網上找到的說法,但是目前 JDK 和 cglib 已經經過了多次優化,在代理類的執行速度上應該不會差一個數量級,我抽空再測試下吧)。HikariCP 涉及 javassist 的程式碼在
JavassistProxyFactory類中,相關內容請自行查閱; - 重視程式碼細節對效能的影響。下文到的 fastPathPool 就是一個例子,仔細琢磨 HikariCP 的程式碼就會發現許多類似的細節優化,除此之外還有 FastList 等自定義集合類;
接下來,本文將在分析原始碼的過程中對以上幾點展開討論。
HikariCP的架構
在分析具體程式碼之前,這裡先介紹下 HikariCP 的整體架構,和 DBCP2 的有點類似(可見 HikariCP 與 DBCP2 效能差異並不是由於架構設計)。
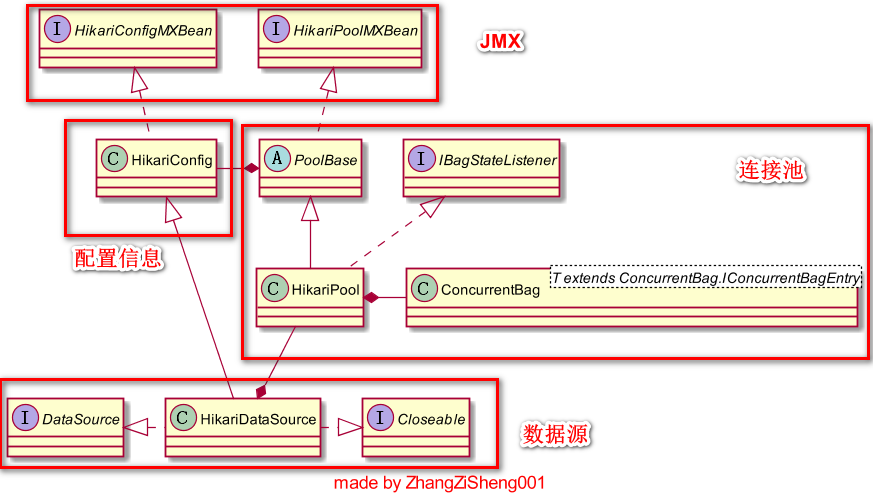
我們和 HikariCP 打交道,一般通過以下幾個入口:
通過 JMX 呼叫
HikariConfigMXBean來動態修改配置(只有部分引數允許修改,在配置詳解裡有註明);通過 JMX 呼叫
HikariPoolMXBean來獲取連線池的連線數(活躍、空閒和所有)、獲取等待連線的執行緒數、掛起和恢復連線池、丟棄未使用連線等;使用
HikariConfig載入配置檔案,或手動配置HikariConfig的引數,一般它會作為入參來構造HikariDataSource物件;使用
HikariDataSource獲取和丟棄連線物件,另外,因為繼承了HikariConfig,我們也可以通過HikariDataSource來配置引數,但這種方式不支援配置檔案。
為什麼HikariDataSource持有HikariPool的兩個引用
在圖中可以看到,HikariDataSource持有了HikariPool的引用,看過原始碼的同學可能會問,為什麼屬性裡會有兩個HikariPool,如下:
public class HikariDataSource extends HikariConfig implements DataSource, Closeable
{
private final HikariPool fastPathPool;
private volatile HikariPool pool;
}這裡補充說明下,其實這裡的兩個HikariPool的不同取值代表了不同的配置方式:
配置方式一:當通過有參構造new HikariDataSource(HikariConfig configuration)來建立HikariDataSource時,fastPathPool 和 pool 是非空且相同的;
配置方式二:當通過無參構造new HikariDataSource()來建立HikariDataSource並手動配置時,fastPathPool 為空,pool 不為空(在第一次 getConnectionI() 時初始化),如下;
public Connection getConnection() throws SQLException
{
if (isClosed()) {
throw new SQLException("HikariDataSource " + this + " has been closed.");
}
if (fastPathPool != null) {
return fastPathPool.getConnection();
}
// 第二種配置方式會在第一次 getConnectionI() 時初始化pool
HikariPool result = pool;
if (result == null) {
synchronized (this) {
result = pool;
if (result == null) {
validate();
LOGGER.info("{} - Starting...", getPoolName());
try {
pool = result = new HikariPool(this);
}
catch (PoolInitializationException pie) {
if (pie.getCause() instanceof SQLException) {
throw (SQLException) pie.getCause();
}
else {
throw pie;
}
}
LOGGER.info("{} - Start completed.", getPoolName());
}
}
}
return result.getConnection();
}針對以上兩種配置方式,其實使用一個 pool 就可以完成,那為什麼會有兩個?我們比較下這兩種方式的區別:
private final T t1;
private volatile T t2;
public void method01(){
if (t1 != null) {
// do something
}
}
public void method02(){
T result = t2;
if (result != null) {
// do something
}
}上面的兩個方法中,執行的程式碼幾乎一樣,但是 method02 在效能上會比 method01 稍差。當然,主要問題不是出在 method02 多定義了一個變數,而在於 t2 的 volatile 性質,正因為 t2 被 volatile 修飾,為了實現資料一致性會出現不必要的開銷,所以 method02 在效能上會比 method01 稍差。pool 和 fastPathPool 的問題也是同理,所以,第二種配置方式不建議使用。
通過上面的問題就會發現,HiakriCP 在追求效能方面非常重視細節,怪不得能夠成為最快的連線池!
HikariPool--管理連線的池塘
HikariPool 是一個非常重要的類,它負責管理連線,涉及到比較多的程式碼邏輯。這裡先簡單介紹下這個類,對下文程式碼的具體分析會有所幫助。
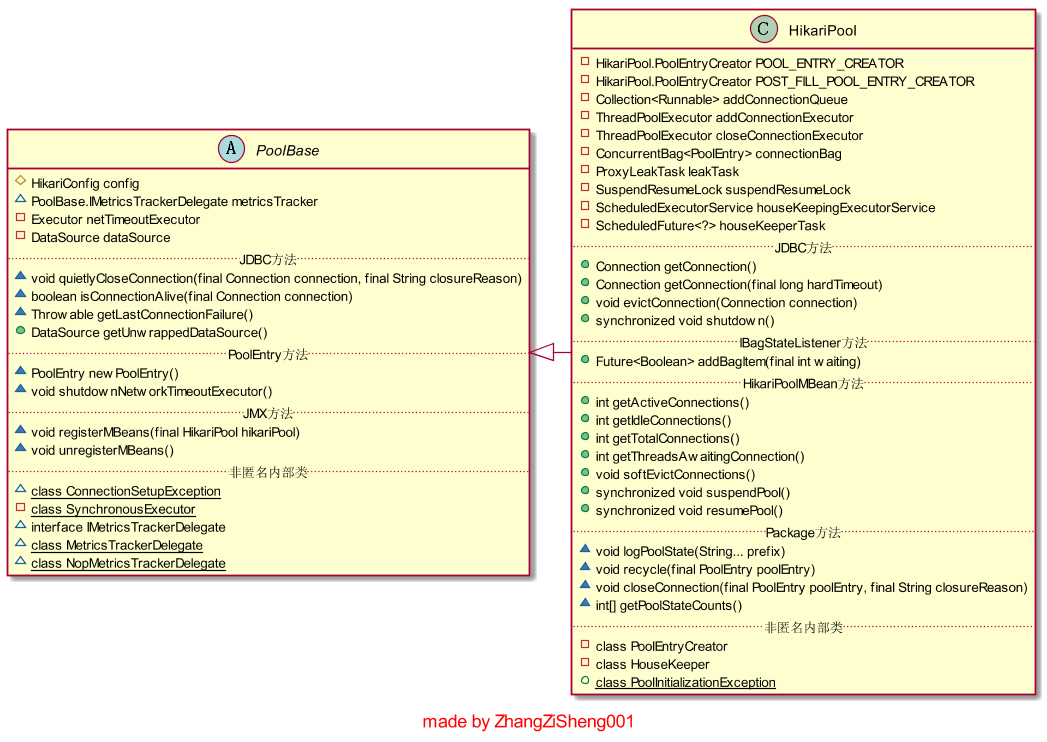
HikariPool 的幾個屬性說明如下:
| 屬性型別和屬性名 | 說明 |
|---|---|
| HikariConfig config | 配置資訊。 |
| PoolBase.IMetricsTrackerDelegate metricsTracker | 指標記錄器包裝類。HikariCP支援Metrics監控,但需要額外引入jar包,本文不會涉及這一部分內容 |
| Executor netTimeoutExecutor | 用於執行設定連線超時時間的任務。如果是mysql驅動,實現為PoolBase.SynchronousExecutor,如果是其他驅動,實現為ThreadPoolExecutor,為什麼mysql不同,原因見: https://bugs.mysql.com/bug.php?id=75615 |
| DataSource dataSource | 用於獲取原生連線物件的資料來源。一般我們不指定的話,使用的是DriverDataSource |
| HikariPool.PoolEntryCreator POOL_ENTRY_CREATOR | 建立新連線的任務,Callable實現類。一般呼叫一次建立一個連線 |
| HikariPool.PoolEntryCreator POST_FILL_POOL_ENTRY_CREATOR | 建立新連線的任務,Callable實現類。一般呼叫一次建立一個連線,與前者區別在於它建立最後一個連線,會列印日誌 |
| Collection<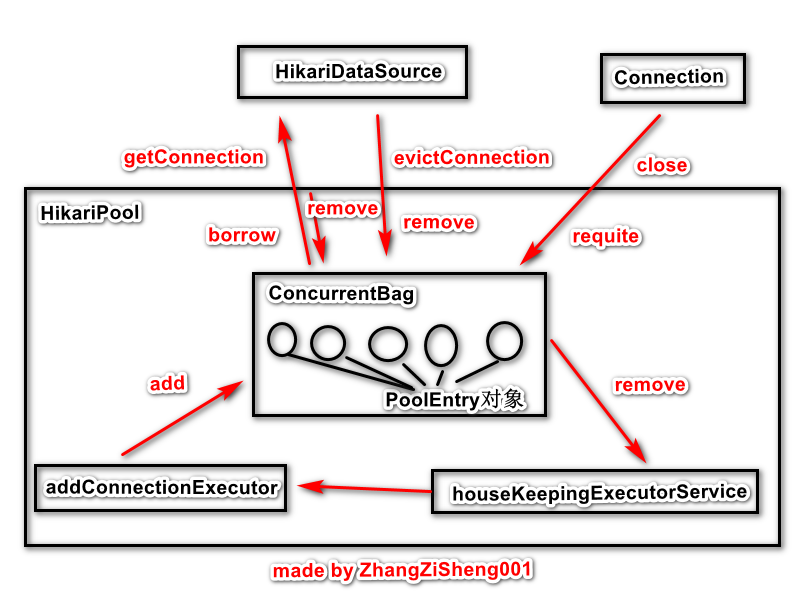
borrow 和 requite 對於 ConcurrentBag 而言是隻讀的操作,addConnectionExecutor 只開啟一個執行緒執行任務,所以 add 操作是單執行緒的,唯一存在鎖競爭的就是 remove 方法。接下來會具體講解 ConcurrentBag。
ConcurrentBag--更少的鎖衝突
在 HikariCP 中ConcurrentBag用於存放PoolEntry物件(封裝了Connection物件,IConcurrentBagEntry實現類),本質上可以將它就是一個資源池。

下面簡單介紹下幾個欄位的作用:
| 屬性 | 描述 |
|---|---|
| CopyOnWriteArrayList<![CDATA[ |
存放著狀態為使用中、未使用和保留三種狀態的PoolEntry物件。注意,CopyOnWriteArrayList是一個執行緒安全的集合,在每次寫操作時都會採用複製陣列的方式來增刪元素,讀和寫使用的是不同的陣列,避免了鎖競爭。 |
| ThreadLocal<List<![CDATA[ | 存放著當前執行緒返還的PoolEntry物件。如果當前執行緒再次借用資源,會先從這個列表中獲取。注意,這個列表的元素可以被其他執行緒“偷走”。 |
| SynchronousQueue<![CDATA[ |
這是一個無容量的阻塞佇列,每個插入操作需要阻塞等待刪除操作,而刪除操作不需要等待,如果沒有元素插入,會返回null,如果設定了超時時間則需要等待。 |
| AtomicInteger waiters | 當前等待獲取元素的執行緒數 |
| IBagStateListener listener | 新增元素的監聽器,由HikariPool實現,在該實現中,如果waiting - addConnectionQueue.size() >= 0,則會讓addConnectionExecutor執行PoolEntryCreator任務 |
| boolean weakThreadLocals | 元素是否使用弱引用。可以通過系統屬性com.zaxxer.hikari.useWeakReferences進行設定 |
這幾個欄位在ConcurrentBag中如何使用呢,我們來看看borrow的方法:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 1. 首先從threadList獲取物件
// 獲取繫結在當前執行緒的List<Object>物件,注意這個集合的實現一般為FastList,這是HikariCP自己實現的,後面會講到
final List<Object> list = threadList.get();
// 遍歷結合
for (int i = list.size() - 1; i >= 0; i--) {
// 獲取當前元素,並將它從集合中刪除
final Object entry = list.remove(i);
// 如果設定了weakThreadLocals,則存放的是WeakReference物件,否則為我們一開始設定的PoolEntry物件
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
// 採用CAS方式將獲取的物件狀態由未使用改為使用中,如果失敗說明其他執行緒正在使用它,這裡可知,threadList上的元素可以被其他執行緒“偷走”。
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 2.如果還沒獲取到,會從sharedList中獲取物件
// 等待獲取連線的執行緒數+1
final int waiting = waiters.incrementAndGet();
try {
// 遍歷sharedList
for (T bagEntry : sharedList) {
// 採用CAS方式將獲取的物件狀態由未使用改為使用中,如果當前元素正在使用,則無法修改成功,進入下一迴圈
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 通知監聽器新增包元素。如果waiting - addConnectionQueue.size() >= 0,則會讓addConnectionExecutor執行PoolEntryCreator任務
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
// 通知監聽器新增包元素。
listener.addBagItem(waiting);
// 3.如果還沒獲取到,會從輪訓進入handoffQueue佇列獲取連線物件
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 從handoffQueue佇列中獲取並刪除元素。這是一個無容量的阻塞佇列,插入操作需要阻塞等待刪除操作,而刪除操作不需要等待,如果沒有元素插入,會返回null,如果設定了超時時間則需要等待
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
// 這裡會出現三種情況,
// 1.超時,返回null
// 2.獲取到元素,但狀態為正在使用,繼續執行
// 3.獲取到元素,元素狀態未未使用,修改未使用並返回
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
// 計算剩餘超時時間
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
// 超時返回null
return null;
}
finally {
// 等待獲取連線的執行緒數-1
waiters.decrementAndGet();
}
}在以上方法中,唯一可能出現執行緒切換到就是handoffQueue.poll(timeout, NANOSECONDS),除此之外,我們沒有看到任何的 synchronized 和 lock。之所以可以做到這樣主要由於以下幾點:
- 元素狀態的引入,以及使用CAS方法修改狀態。在
ConcurrentBag中,使用使用中、未使用、刪除和保留等表示元素的狀態,而不是使用不同的集合來維護不同狀態的元素。元素狀態這一概念的引入非常關鍵,為後面的幾點提供了基礎。ConcurrentBag的方法中多處呼叫 CAS 方法來判斷和修改元素狀態,這一過程不需要加鎖。 - threadList 的使用。當前執行緒歸還的元素會被繫結到
ThreadLocal,該執行緒再次獲取元素時,在該元素未被偷走的前提下可直接獲取到,不需要去 sharedList 遍歷獲取; - 採用
CopyOnWriteArrayList來存放元素。在CopyOnWriteArrayList中,讀和寫使用的是不同的陣列,避免了兩者的鎖競爭,至於多個執行緒寫入,則會加ReentrantLock鎖。 - sharedList 的讀寫控制。borrow 和 requite 對 sharedList 來說都是不加鎖的,缺點就是會犧牲一致性。使用者執行緒無法進行增加元素的操作,只有 addConnectionExecutor 可以,而 addConnectionExecutor 只會開啟一個執行緒執行任務,所以 add 操作不會存在鎖競爭。至於 remove 是唯一會造成鎖競爭的方法,這一點我認為也可以參照 addConnectionExecutor 來處理,在加入任務佇列前把
PoolEntry的狀態標記為刪除中。
其實,我們會發現,ConcurrentBag在減少鎖衝突的問題上,除了設計改進,還使用了比較多的 JDK 特性。
如何載入配置
在HikariCP 中,HikariConfig用於載入配置,具體的程式碼並不複雜,但相比其他專案,它的載入要更加簡潔一些。我們直接從PropertyElf.setTargetFromProperties(Object, Properties)方法開始看,如下:
// 這個方法就是將properties的引數設定到HikariConfig中
public static void setTargetFromProperties(final Object target, final Properties properties)
{
if (target == null || properties == null) {
return;
}
// 在這裡會利用反射獲取
List<Method> methods = Arrays.asList(target.getClass().getMethods());
// 遍歷
properties.forEach((key, value) -> {
// 如果是dataSource.*的引數,直接加入到dataSourceProperties屬性
if (target instanceof HikariConfig && key.toString().startsWith("dataSource.")) {
((HikariConfig) target).addDataSourceProperty(key.toString().substring("dataSource.".length()), value);
}
else {
// 如果不是,則通過set方法設定
setProperty(target, key.toString(), value, methods);
}
});
}進入到PropertyElf.setProperty(Object, String, Object, List<Method>)方法:
private static void setProperty(final Object target, final String propName, final Object propValue, final List<Method> methods)
{
// 拼接引數的setter方法名
String methodName = "set" + propName.substring(0, 1).toUpperCase(Locale.ENGLISH) + propName.substring(1);
// 獲取對應的Method 物件
Method writeMethod = methods.stream().filter(m -> m.getName().equals(methodName) && m.getParameterCount() == 1).findFirst().orElse(null);
// 如果不存在,按另一套規則拼接引數的setter方法名
if (writeMethod == null) {
String methodName2 = "set" + propName.toUpperCase(Locale.ENGLISH);
writeMethod = methods.stream().filter(m -> m.getName().equals(methodName2) && m.getParameterCount() == 1).findFirst().orElse(null);
}
// 如果該引數setter方法不存在,則丟擲異常,從這裡可以看出,HikariCP 中不能存在配錯引數名的情況
if (writeMethod == null) {
LOGGER.error("Property {} does not exist on target {}", propName, target.getClass());
throw new RuntimeException(String.format("Property %s does not exist on target %s", propName, target.getClass()));
}
// 接下來就是呼叫setter方法來配置具體引數了。
try {
Class<?> paramClass = writeMethod.getParameterTypes()[0];
if (paramClass == int.class) {
writeMethod.invoke(target, Integer.parseInt(propValue.toString()));
}
else if (paramClass == long.class) {
writeMethod.invoke(target, Long.parseLong(propValue.toString()));
}
else if (paramClass == boolean.class || paramClass == Boolean.class) {
writeMethod.invoke(target, Boolean.parseBoolean(propValue.toString()));
}
else if (paramClass == String.class) {
writeMethod.invoke(target, propValue.toString());
}
else {
writeMethod.invoke(target, propValue);
}
}
catch (Exception e) {
LOGGER.error("Failed to set property {} on target {}", propName, target.getClass(), e);
throw new RuntimeException(e);
}
}我們會發現,相比其他專案(尤其是 druid),HikariCP 載入配置的過程非常簡潔,不需要按照引數名一個個地載入,這樣後期會更好維護。當然,這種方式我們也可以運用到實際專案中。
獲取一個連線物件的過程
現在簡單介紹下獲取連線物件的過程,我們進入到HikariPool.getConnection(long)方法:
public Connection getConnection(final long hardTimeout) throws SQLException
{ // 如果我們設定了allowPoolSuspension為true,則這個鎖會生效
// 它採用Semaphore實現,MAX_PERMITS = 10000,正常情況不會用完,除非你掛起了連線池(通過JMX等方式),這時10000個permits會一次被消耗完
suspendResumeLock.acquire();
// 獲取開始時間
final long startTime = currentTime();
try {
// 剩餘超時時間
long timeout = hardTimeout;
PoolEntry poolEntry = null;
try {
// 迴圈獲取,除非獲取到了連線或者超時
do {
// 從ConcurrentBag中借出一個元素
poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
// 前面說過,只有超時情況才會返回空,這時會跳出迴圈並丟擲異常
if (poolEntry == null) {
break;
}
final long now = currentTime();
// 如果元素被標記為丟棄或者空閒時間過長且連線無效則會丟棄該元素,並關閉連線
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection))) {
closeConnection(poolEntry, "(connection is evicted or dead)"); // Throw away the dead connection (passed max age or failed alive test)
// 計算剩餘超時時間
timeout = hardTimeout - elapsedMillis(startTime);
}
else {
// 這一步用於支援metrics監控,本文不涉及
metricsTracker.recordBorrowStats(poolEntry, startTime);
// 建立Connection代理類,該代理類就是使用Javassist生成的
return poolEntry.createProxyConnection(leakTask.schedule(poolEntry), now);
}
} while (timeout > 0L);
// 不涉及
metricsTracker.recordBorrowTimeoutStats(startTime);
}
catch (InterruptedException e) {
// 獲取連線過程如果中斷,則回收連線並丟擲異常
if (poolEntry != null) {
poolEntry.recycle(startTime);
}
Thread.currentThread().interrupt();
throw new SQLException(poolName + " - Interrupted during connection acquisition", e);
}
}
finally {
// 釋放一個permit
suspendResumeLock.release();
}
// 丟擲超時異常
throw createTimeoutException(startTime);
}以上就是獲取連線物件的過程,沒有太複雜的邏輯。這裡需要注意,使用 HikariCP 最好不要開啟 allowPoolSuspension ,否則每次連線都會有獲取和釋放 permit 的過程。另外,HikariCP 預設 testOnBorrow,有點難以理解。
以上,HikariCP 的使用例子和原始碼分析基本講完,後續有空再做補充。
參考資料
微信公眾號【工匠小豬豬的技術世界】的追光者系列文章
相關原始碼請移步:https://github.com/ZhangZiSheng001/hikari-demo
本文為原創文章,轉載請附上原文出處連結: https://www.cnblogs.com/ZhangZiSheng001/p/12329937.html