
1994_An Algorithm To Reconstruct Wideband Speech From Narrowband Speech Based On Codebook Mapping
論文地址:基於碼本對映的窄帶語音寬頻重建演算法
部落格作者:凌逆戰
部落格地址:https://www.cnblogs.com/LXP-Never/p/12144324.html
摘要
本文提出了一種從窄帶語音中重構寬頻語音的新演算法,該演算法有兩個新的特點。第一是基於碼本對映的頻譜包絡重構。第二是利用重構的頻譜包絡進行語音訊號重構。由於該演算法無需使用任何附加的傳送資訊就能生成高質量的語音(盲源),所以它適用於任何網路,如現有的電話網路、支援模擬和ISDN服務的網路等。該演算法應用於20個說話人。通過acoustic distance measure(聲學距離測量)和listening tests confirms(聽力測試驗證)了演算法的良好效能。
引言
近年來,高質量的聲音已經通過CD(小型光碟)和LDs(鐳射光碟)變得熟悉起來,這就提高了現有服務的音質的需求。例如,一些調幅電臺已經開始用立體聲代替單聲道廣播。這些趨勢表明,改進的質量是傳統系統或現有服務中最重要的要求之一。在電話服務方面,一個要求是提供寬頻語音而不是窄帶語音。因為寬頻語音是清晰的,並且精確地保留了說話人的身份,所以使用者可以通過電話線更真實地交流[1][2]。
本文提出了一種從電話語音中產生寬頻語音的方法。因為模擬電話的頻寬限制在300Hz~3.4kHz之間。該演算法產生一個附加的低頻訊號(50hz-300Hz)和一個高頻訊號(3.4kHz-7.3kHz)。這generation基於兩個假設,一是窄帶語音與低頻帶和高頻帶訊號密切相關;二是即使低頻帶和高頻帶訊號不完全正確,也能顯著提高感知語音質量。該演算法的一個優點是可以在不增加任何額外資訊的情況下生成寬頻語音。這使得它適用於任何網路,如現有的電話網、支援模擬和ISDN的網路等。此外,在傳輸頻寬受限的情況下,如在行動通訊中,它也是有效的。
2 重建演算法
該演算法分為兩個步驟,
- 步驟一:高頻帶和低頻帶的頻譜包絡重建。利用寬頻語音集及其窄帶版本生成對映函式,對映功能將窄帶頻譜的向量對映到寬頻頻譜的向量空間[3]的碼書實現的。
- 步驟二:合成低頻帶和高頻帶訊號。低頻帶訊號採用線性預測編碼(LPC)來合成。在高頻帶訊號合成方面,我們考慮了LPC合成和波形疊加兩種方法,最後將高頻帶和低頻帶訊號疊加到電話語音中得到寬頻語音。
下面解釋這兩個過程的細節
2.1 頻譜包絡產生
要從窄帶頻譜包絡中產生寬頻頻譜包絡,需要一對碼本。其中一個碼本包含寬頻頻譜包絡,另一個碼本包含對應的窄帶頻譜包絡。寬頻頻譜包絡碼本的碼向量與窄帶頻譜包絡的碼向量具有一對一的對應關係。碼本的製作步驟如下,下面步驟中的序號對應於圖1中的數字。
- 寬頻語音通過帶通濾波器生成窄帶語音
- 提取寬頻和窄帶語音訊譜包絡
- 使用LBG演算法生成寬頻碼本[4]
- 使用寬頻碼本對寬頻語音中的語音進行向量量化
- 利用時間關係,將窄帶語音的頻譜包絡進行聚類
- 平均每個窄帶群集中的頻譜包絡,然後將其儲存為窄帶碼本的碼向量(當通過波形疊加產生高頻訊號時,需要其它碼本)
- 選擇具有最接近每個碼向量頻譜包絡的寬頻波形,通過高通濾波器和帶通濾波器後,將其儲存為代表波形
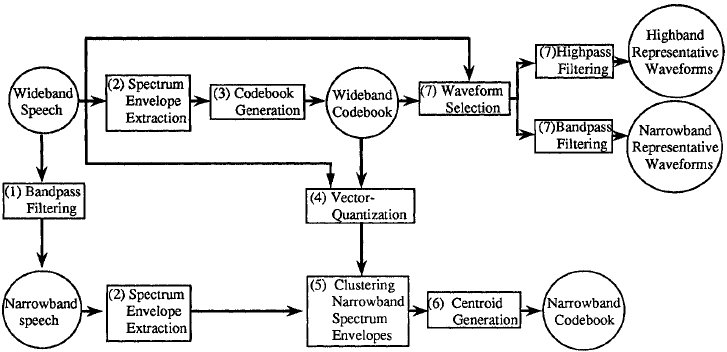
圖1 碼本生成演算法框圖
2.2 從窄帶語音生成寬頻語音
圖2是生成過程的框圖,步驟如下
- 用LPC分析輸入窄帶語音並提取基音、功率和頻譜包絡
- 使用窄帶碼本對每個頻譜包絡進行向量量化,並使用寬頻碼本對向量進行解碼
- 產生低頻訊號。細節將在後面介紹
- 產生高頻訊號。細節將在後面介紹
- 對輸入的窄帶語音進行上取樣
- 在(5)的輸出中加入低頻帶和高頻帶訊號,產生寬頻語音
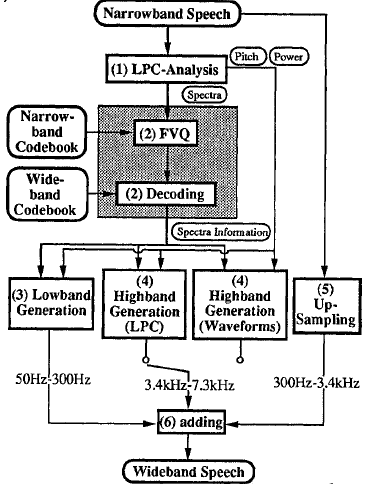
圖2 生成過程框圖
下面解釋低頻帶和高頻帶訊號的產生。利用LPC合成技術合成了低頻訊號。為了合成高頻訊號,提出了兩種方法,一種是使用LPC合成法(方法1),另一種是使用波形形成法(方法2),圖3、4和5分別是低頻訊號生成、高頻訊號生成的框圖(方法1和方法2)。
低頻段產生
- 利用所分析的基音、功率和由寬頻碼本解碼的頻譜包絡,通過LPC進行寬頻語音合成。
- (1)的輸出通過低通濾波器提取低頻帶訊號(在這種情況下,我們使用STFT分析/合成[5]作為低通濾波器)
- 將(2)的輸出乘以一個常數,因為(2)的power(功率)insufficient(缺乏)寬頻語音。這就產生了低頻帶訊號
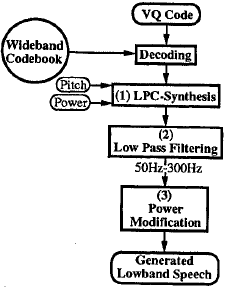
低頻段語音生成
高頻帶生成(方法1)
- 利用寬頻碼本解碼後的基音、功率和頻譜包絡,用LPC合成寬頻訊號
- 通過高通濾波器(1)提取高頻訊號(在這種情況下,我們使用STFT分析/合成作為高通濾波器)
- 將(2)的輸出乘以餘弦函式,以減小由LPC合成引起的脈衝,並使功率正常化。這就產生了高頻訊號
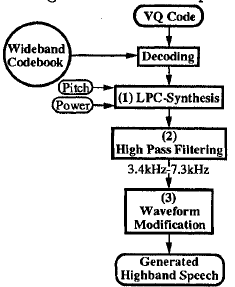
高頻帶訊號生成(方法一)
高頻帶生成(方法2)
- 參考碼向量索引,得到兩個waveform(波形):一個來自窄帶代表碼本,另一個來自高頻代表碼本。
- 檢查波形是否為濁音(voiced)或清音(unvoiced)
- 如果是濁音,則通過基音同步重疊加法來合成窄帶語音。如果沒有濁音,則通過逐幀重疊加法合成窄帶語音
- 計算(3)的輸出與輸入語音之間的功率比
- 用與(3)相同的方法合成高頻訊號
- 將(5)的輸出乘以功率比,得到高頻訊號。
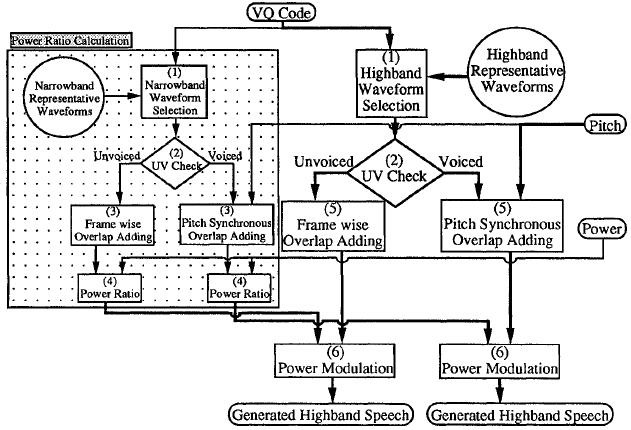
高頻帶訊號生成(方法二)
3 效能評估
頻譜失真和聽覺測試評估了該演算法的效能。 實驗條件如表1所示
“說話人相關”表示模型的訓練資料和測試數來自同一個人,“說話人獨立”表示不同的說話人。
3.1 頻譜失真評估
通過使用寬頻碼本和窄帶碼本來測量頻譜失真,我們使用了10位男性說話人和10位女性說話人。
VQ失真計算如下
(1)從寬頻語音中提取頻譜包絡
(2)使用寬頻碼本進行向量量化(1)
(3)分別計算低頻和高頻訊號(1)和(2)之間的平方誤差。誤差定義如下
$$D=\sum_{t=0}^{T^{\prime}}\left[\frac{1}{2 \pi} \int_{a}^{b}\left[10 \log _{10} \frac{\hat{Y}_{t}(\omega)}{Y_{t}(\omega)}\right]^{2} d \omega\right]^{\frac{1}{2}}$$
重建失真計算方式如下
(4)通過濾波(1)中使用的語音獲得窄帶語音,並提取窄帶頻譜包絡
(5)利用窄帶碼本和寬頻碼本重構(4)輸出相對應的寬頻頻譜包絡
(6)分別計算低頻和高頻訊號(4)和(5)之間的平方誤差。誤差定義見(3)
實驗結果如圖6和圖7所示。每個失真值是所有說話人對的平均值。從結果來看,該演算法可以像向量量化一樣精確地重建低頻譜,並且重建失真隨著碼本尺寸的增大而減小(8bit碼本會導致3.5dB的頻譜失真),在高頻寬重建方面,使用4bit碼本,重建失真的降低在6.5dB處飽和。這表明,高頻訊號和窄帶語音的相關係數沒有低頻訊號和窄帶語音的相關係數高。
表1:測試條件
訓練資料數目:186個單詞平衡了所有音素
分析窗函式:hamming
窗函式長度:21毫秒
幀移長度:3毫秒
LPC階數:12
FFT點的數量:512
失真度量:LPC倒譜的歐氏距離
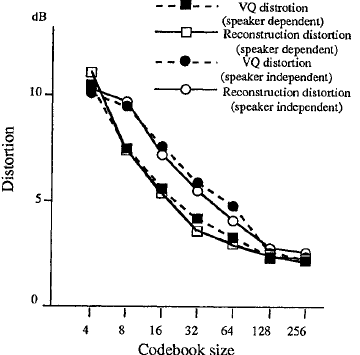
圖6:頻譜失真(低頻段)
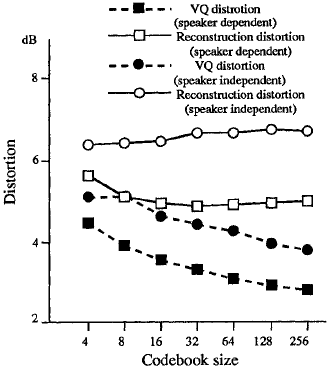
圖7:頻譜失真(高頻段)
3.2 聽力測試評估
進行配對比較聽力測試。基於以上結果,分別用8bit和4bit碼本對低頻和高頻訊號進行了寬頻語音生成。兩名男發言人和兩名女發言人以獨立於發言者的方式受僱。隨機從三個語音集中選擇兩個語音集:電話語音、使用方法1生成的語音和使用方法2生成的語音2。六位聽眾被要求選擇一個比另一個更寬的語音。使用了77對。
實驗結果如圖8所示。結果表明,該演算法能有效地從電話語音中重建寬頻語音。就產生高頻的最佳方法而言,它們之間沒有顯著差異

圖8:偏好得分
4 總結
提出了一種利用碼本對映生成窄帶語音寬頻語音的演算法,並從頻譜失真的角度驗證了演算法的效能,在說話人相關和獨立重構之間沒有效能差異。聽力測試證實,生成的寬頻語音質量優於原始電話語音。我們計劃改進高頻訊號的產生過程,以提高與窄帶訊號的相關性
致謝
我們感謝語音處理部門的成員進行了有價值的討論。我們也感謝語音和聲學實驗室主任北崎駿博士和語音處理小組組長杉村博士對這項工作的持續支援。
參考文獻
[1] Y. Cheng, D. O'Shaughnessy, P. Mermelstein, "Statistical Re covery of Wideband Speech From Narrowband Speech, "Proceedings of ICSLP92, pp. 1577-1480,19922
[2] N. Jayant,"High-Quality Coding of Telephone ech and wideband Audio, Advances in Speech Sign cessing, pp85-108,1992
[3] M. Abe, S. Nakamura, K. Shikano, H. Kuwabara, "Voice conversion through vector quantization, "ICASSP,88, pp. 655-658,1988
[4] Y. Linde, A. Buzo, and R. M. Gray, " An algorithm for vector quantizer design, "IEEE Trans. Commun COM-28, 1, pp 8495(Jan.19805
[5] Lawrence R. Rabiner, Ronald W. Schafer "Digital Processing of Speech Signals”,
&n