
Solr查詢配置及優化【eDisMax查詢解析器】
一.簡介
Lucene查詢解析器語法支援建立任意複雜的布林查詢,但還有一些缺點,它不是使用者查詢處理的理想解決方案。這裡面最大的問題是Lucene查詢解析器的語法要求嚴格,一旦破壞就會丟擲異常。指望使用者在輸入關鍵詞時能夠理解Lucene查詢語法並始終能輸入完美的查詢表示式,這顯然是不合理的。這意味著,Lucene查詢解析器在許多搜尋應用中對使用者不夠友好。
Lucene查詢解析器的另一個缺點是它不能預設搜尋多個欄位。df引數定義了查詢解析器預設搜尋哪個欄位,但是如果想要以不同權重對多個欄位進行搜尋時,就必須先對查詢進行預處理。對大多數Solr開發人員來說,這樣的查詢預處理工作量過大。為了將使用者查詢直接傳入Solr並優雅地進行處理,擴充套件的析取最大化查詢解析器eDisMax應運而生。
二.eDisMax查詢解析器概述
eDisMax查詢解析器實際上是由Lucene查詢解析器和DisMax查詢解析器組成。DisMax查詢解析器是eDisMax查詢解析器的舊版本,只接受關鍵詞和少數幾個基本的布林運算,允許在多個欄位中搜索關鍵詞。因為DisMax查詢解析器是eDisMax查詢解析器的一個子集,所有不建議使用原始的DisMax查詢解析器。
雖然eDisMax查詢解析器不是Solr的預設查詢解析器,但它具有查詢語法容錯性,不像Lucene查詢解析器那樣嚴格。
三.eDisMax查詢引數
eDisMax查詢解析器支援Lucene查詢解析器的所有查詢語法。它們之間只有一個明顯差異,eDisMax的輸入語法不會丟擲異常,而是將無效的輸入作為文字字串進行搜尋。它還在語法解析上具有一定的容錯性,支援特殊關鍵詞。例如,可以理解小寫轉換後的AND和OR。這種靈活性和容錯性讓它比Lucene查詢解析器更適合處理使用者輸入。

四.搜尋多個欄位
除了安全地處理使用者輸入文字和自由地解析查詢語法,eDisMax查詢解析器最有用的一個功能是對多個欄位進行搜尋。eDisMax查詢解析器會將每個內容放在各自的欄位中。通過指定查詢和查詢欄位。例如:
q=solr in action&qf=title description author
另外,還可以根據意願在每個查詢基礎上調整權重。
q=solr in action&qf=title^1.5 description author^3

五.查詢與短語權重調整
eDisMax查詢解析器的一個重要功能是調整彼此鄰近的詞項的相關度。使用Lucene查詢解析器的典型查詢,不管詞項是否彼此鄰近,或是否視為一個短語,所有詞項的相關度都是一樣的。eDisMax查詢解析器的另一個功能是,對獨立於使用者主查詢的函式進行任意地相關度調整。
1.pf【短語欄位】、pf2和pf3引數
pf引數用於調整那些q引數中所有詞項彼此非常靠近的文件得分。pf引數與qf引數使用相同的格式,獲取欄位列表及可選的相應權重。eDisMax查詢解析器嘗試對q引數中所有詞項進行短語查詢,如果能在任何短語欄位中找到確切的短語,則對匹配的文件調整相應的權重。
除了pf引數,eDisMax查詢解析器還支援pf2和pf3引數。這些引數功能與pf引數類似,不過不需要q引數中所有詞項,它們將詞項分解為二元【pf2】或三元【pf3】,只對包含少量詞項的文件調整權重。例如:在查詢Solr finds relevant documents中,pf3引數會對包含短語"solr finds relevant" 或 "finds relevant documents"的文件調整權重。pf2與之類似,對包含其中任意兩個連續詞短語的文件進行權重調整。
2.ps【短語間隔】、ps2和ps3引數
使用pf引數時,可能不希望查詢中的所有詞項作為一個精確的短語出現。使用ps引數可以指定查詢中的詞項間隔位置界限,以此在短語欄位上判斷匹配情況。eDisMax查詢解析器還支援ps2和ps3引數,允許為ps2和ps3修改短語間隔值。不明確指定時預設為ps引數。
3.qs【查詢短語間隔】引數
qs引數對使用者在主查詢q引數上明確指定短語的處理方式類似。將qs引數視為重新定義要匹配的確切內容,可以將間隔預設值為0修改為更高的數值。
4.tie【決勝局】引數
當查詢的詞項與文件的多個欄位匹配時,tie引數可以決定如何處理這種情況。為匹配到的每個欄位的每個詞項計算其相關度得分,預設情況下,每個文件中得分最高的欄位用於該詞項的相關度計算。這是析取的最大得分,也是該查詢解析器得名“析取最大值”的原因所在。這與Lucene查詢解析器形成鮮明對比,Lucene查詢解析器通常將每個欄位的每個詞項的相關度得分相加,計算出每個文件的綜合相關度得分。
tie引數決定了最匹配的欄位之外的其他欄位的詞項相關度得分有多少應該貢獻給總體相關度得分。tie引數的預設值為0.0,這表示其它欄位不貢獻權重。當tie為1時,表示貢獻全部權重,此時相關等同於Lucene查詢解析器。在這種情況下,相關度評分使用的是析取和而不是析取最大值。
5.bq【提升查詢】引數
bq引數接受查詢字串,其包含在主查詢q引數中,用來影響相關度得分。它不會影響匹配到的文件數,隻影響文件返回的順序。如果想為最近的文件提升相關度,可以在請求中新增一下內容:
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]
這將有效提升日期屬於去年的所有文件的相關度得分。另外,還可以指定多個bq引數,在查詢解析時針對不同子句分別進行提升。
6.bf【提升函式】引數
bf引數能夠通過函式查詢來提升主查詢的相關度。例如,提升最新日期的文件的相關度:
recip(rord(date),1,1000,1000)
bf引數接受Solr支援的所有函式及其權重值。
六.欄位別名
有時候需要在Solr中使用內部欄位名,這些欄位名並不適合顯示給使用者。對於動態欄位來說尤為如此,動態欄位名可能類似title_t_en這樣,但是我們希望在搜尋中使用對使用者更友好的語法,例如,title:"some title"。eDisMax查詢解析器為此提供了欄位別名機制。
eDisMax查詢中的欄位別名通過在請求中新增引數f.{alias}.qf={realfield}來實現。例如:
/select?defType=edismax&q=title:"some title"&f.title.qf=title_t_en
查詢在title_t_en欄位上執行,接下來它會被查詢中出現的title欄位替換。欄位別名引數在預設的qf引數後使用,這意味著,可以將一個別名分別以不同的權重對應到多個內部欄位。在請求中新增任意數量的別名也是可以的。
多別名欄位的搜尋類似於預設欄位的搜尋,其中每個查詢詞項被分佈在別名定義的查詢欄位上。唯一的區別是可以為每個別名定義單獨的qf欄位,而不是為預設欄位定義一個qf引數。因此,與每個別名相關的查詢部分會對欄位列表進行搜尋。
七.可訪問欄位
在許多情況下,使用者只能對預設欄位以及可能的一小部分其它欄位進行關鍵詞搜尋。由於有些內部欄位可能會包含某些敏感資訊【例如,使用者ID或其他內部識別符號】,可能不希望使用者從Solr索引中猜出其他欄位並查詢它們。
雖然eDisMax查詢解析器允許主查詢q引數對任何欄位進行搜尋,但也可以使用uf【使用者欄位】引數來加以限制。預設值是uf=*,允許用field:expression語法查詢所有欄位。如果要限制可用欄位為單個title欄位,指定uf=title即可。多欄位的訪問使用空格隔開:uf=title city date。如果要對使用者禁用所有欄位,則使用否定語法:uf=-*。如果要對指定欄位列表之外的其他欄位進行訪問,則使用uf=* -hiddenField1 -hiddenField2...
為確保完全控制使用者查詢,可以將uf引數和欄位別名引數結合使用。uf引數既接受真實欄位,也接受別名。這樣設定可以保護搜尋引擎不訪問未經授權的欄位。
八.最小匹配
在布林邏輯中使用二元運算子:AND和OR。它們是Lucene對必須匹配和應該匹配的內部表達形式。查詢表示式hello AND world可以改寫為+hello +world,這表示hello和world都必須匹配。OR用法於此類似,表示此中存在匹配的即可。
eDisMax查詢解析器通過mm【最小匹配】引數模糊了傳統布林邏輯的界限。為了讓文件實現匹配,mm引數在查詢中可以定義必須匹配的特定數量的詞項或詞項的百分比。這是對搜尋應用的查準率與查全率進行操作的一個好方式。原因在於,它不要求所有詞項必須匹配【預設運算子為AND】或僅需要匹配其中一個詞項即可【預設運算子為OR】。
mm引數語法非常豐富,很難一下子掌握。例如:

mm可以定義必須匹配的表示式數量【正整數】、遺漏的表示式數量【負整數】、必須匹配的表示式百分比【正百分比】以及遺漏的表示式百分比【負百分比】。要進一步控制的話,根據查詢中現有的表示式數量,可以定義不同的最小匹配規則。以下面的查詢結構為例:
/select?q={!edismax mm="2<50% 4<-45%" v=$example}&example=...
對於該查詢,以下規則將對不同的示例引數值生效:

eDisMax查詢解析器的最小匹配功能可以包含多個關鍵詞的查詢進行匹配質量和數量的細粒度控制。圖解從交集的角度解釋最小匹配閾值的作用:
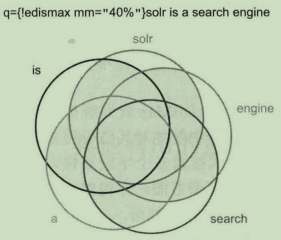
解釋:5個詞項的最小匹配值設定為40%。在這種情況下,5個詞項至少需要匹配2個。與傳統的布林邏輯AND/OR相比,最小匹配支援不同的交集。
mm引數變大通常會提高查準率,mm引數變小通常會提高查全率。
從本質上講,小於1的最小匹配值永遠不會被使用【因為至少需要一個】,大於子句數量的最小匹配值也不會被使用【因為最大值是查詢中的子句數量】。
九.eDisMax查詢解析器的優缺點
eDisMax查詢解析器除了支援Lucene查詢解析器的所有查詢語法外,還提供了許多附加功能。例如:多欄位搜尋、清理使用者輸入、欄位別名和欄位限制,以及通過多查詢修正來改進短語相關度和其它權重因素。
使用eDisMax查詢解析器也有一些缺點。首先是與eDisMax查詢解析器進行多欄位搜尋相關的處理問題。如果將所有詞項放入一個欄位並對其進行搜尋,Lucene查詢解析器的查詢速度比使用eDisMax查詢解析器在相同的查詢表示式搜尋多個欄位要快。當然,eDisMax查詢解析器也可以單欄位搜尋。然而,eDisMax查詢解析器可以實現輕鬆多欄位搜尋的同時,會為許多基於Solr的搜尋應用帶來額外的執行花銷。