
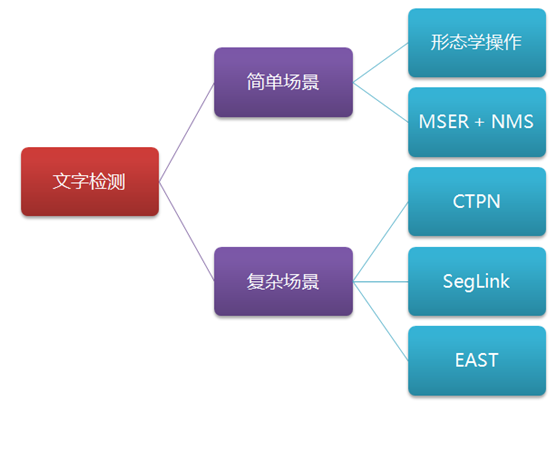
OCR場景文字識別:文字檢測+文字識別
一. 應用背景
OCR(Optical Character Recognition)文字識別技術的應用領域主要包括:證件識別、車牌識別、智慧醫療、pdf文件轉換為Word、拍照識別、截圖識別、網路圖片識別、無人駕駛、無紙化辦公、稿件編輯校對、物流分揀、輿情監控、文件檢索、字幕識別文獻資料檢索等。OCR文字識別主要可以分為:印刷體文字識別和手寫體文字識別。文字識別方法的一般流程為:識別出文字區域、對文字區域矩形分割成不同的字元、字元分類、識別出文字、後處理識別矯正。
二. 文字檢測
文字檢測是文字識別過程中的一個非常重要的環節,文字檢測的主要目標是將圖片中的文字區域位置檢測出來,以便於進行後面的文字識別,只有找到了文字所在區域,才能對其內容進行識別。
1.【CTPN】
CTPN,全稱是“Detecting Text in Natural Image with Connectionist Text Proposal Network”,將文字行在水平方向解耦成slices進行檢測,再將slices區域合併成文字框。CTPN接面構與Faster R-CNN類似,但加入了RNN(LSTM層)用於序列的特徵識別來提高檢測精度,目前CTPN針對水平長行文字的檢測是工業級的,演算法魯棒。

演算法流程:
Feature Map:N(images) - C(channels) - H(height) - W(width)
(1). 骨幹網路VGG16提取特徵,第5個block的第三個卷積層conv5(stride=16,size=N×C×H×W)作為特徵圖;
(2). 在con5上做3×3滑窗,每個點都結合周圍3×3區域生成3×3×C特徵向量,輸出N×9C×H×W空間特徵圖;
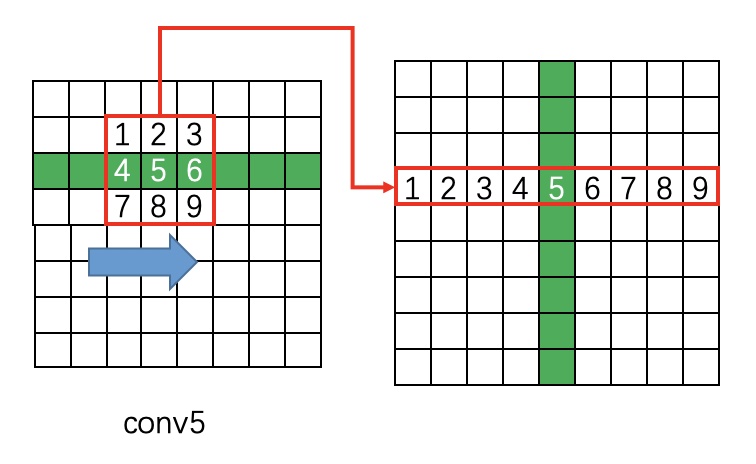
(3). Reshape特徵圖:N×9C×H×W -> (NH)×W×9C;
(4). 以batch=NH,Tmax=W的資料流輸入雙向LSTM,學習每一行的序列特徵(注:LSTM/Reverse-LSTM都包含128個hidden layer),BLSTM輸出(NH)×W×256空間序列混合特徵圖;
(5). Reshape特徵圖:(NH)×W×256 -> N×256×H×W;
(6). 將RNN的結果輸入到FC層(256×512的矩陣引數),變為N×512×H×W的特徵;
(7). 將FC層得到的特徵輸入類似Faster R-CNN的RPN網路,獲得text proposals。2k vertical coordinate和k side-refinement用來回歸k個anchor的位置資訊並進行校準,2k scores表示k個anchor的類別。
(8). 採用文字線構造辦法,把text proposal連線成一個文字檢測框。
關鍵策略:
(1). text proposals網路。
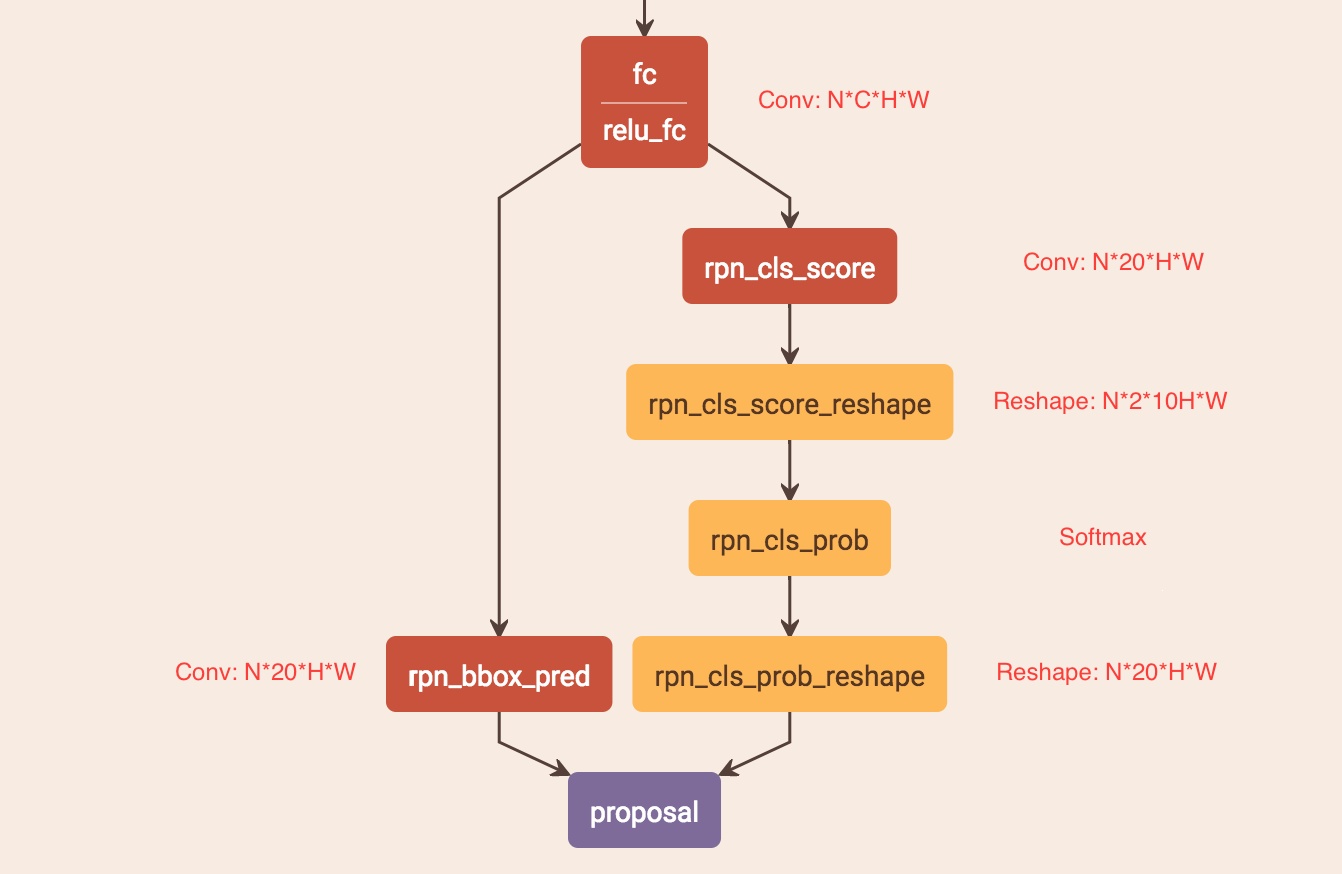
左側分支用於b-box迴歸,FC特徵圖每個點配備了10個對應原圖尺度的Anchor(紅色小矩形框確定字元位置),寬度相等(width=[16]),高度10個尺度([11,16,23,33,48,68,97,138,198,283]),保證Anchor在x方向上覆蓋原圖每個點且不相互重疊並在y方向上覆蓋差異較大的不同高度文字目標。獲得Anchor後,b-box regression只修正並預測包含文字的Anchor的中心y座標與高度h(沒預測起始座標x是因為在構造標籤時有固定偏移),故rpn_bbox_pred有20個channels。右邊分支用於Softmax分類,判斷Anchor中是否包含文字,選出score大的正Anchor。
(2). 標籤構造。
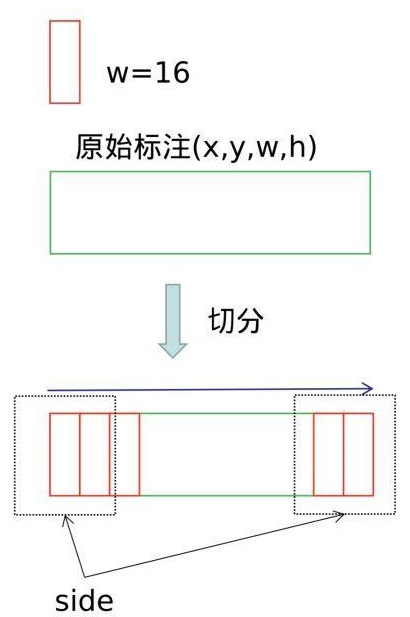
如圖,給定一個文字的標註框(x, y, w, h),沿著水平方向進行切分,偏移為16個畫素(conv5的stride為16,特徵圖中的一個畫素對應標籤的16的寬度),得到了一系列的文字小片。將左右標記為紅色的小片(兩端50畫素以內)作為side-refinement時候的標籤,約束網路對文字起始和終止點的矯正。
(3). 文字線構造。
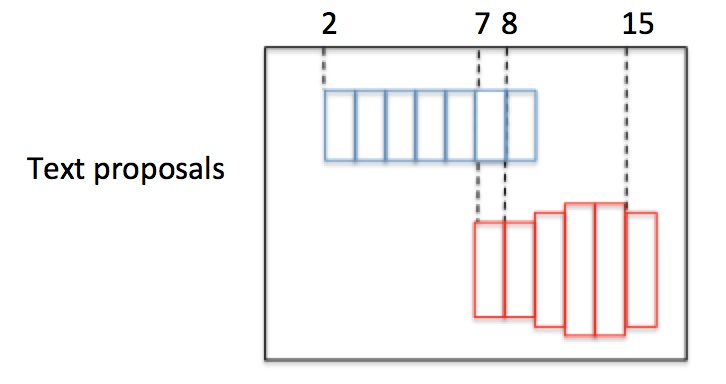
如圖,有2個text proposal,包含紅藍2組Anchor。首先按水平x座標排序Anchor。然後按照規則依次計算每個boxi的pair(boxj),組成pair(boxi,boxj),規則如下:
正向尋找:1. 沿水平正方向,尋找和boxi水平距離小於50的候選Anchor;2. 從候選Anchor中,挑出與boxi豎直方向overlapv>0.7的Anchor;3. 挑出符合條件2中Softmax score最大的boxj。
再反向尋找:1. 沿水平負方向,尋找和boxj水平距離小於50的候選Anchor;2. 從候選Anchor中,挑出與boxj豎直方向overlapv>0.7的Anchor;3. 挑出符合條件2中Softmax score最大的boxk。
最後對比scorei和scorek:如果scorei>=scorek,這是一個最長連線,設定Graph(i,j)=True;如果scorei<scorek,不是一個最長連線。
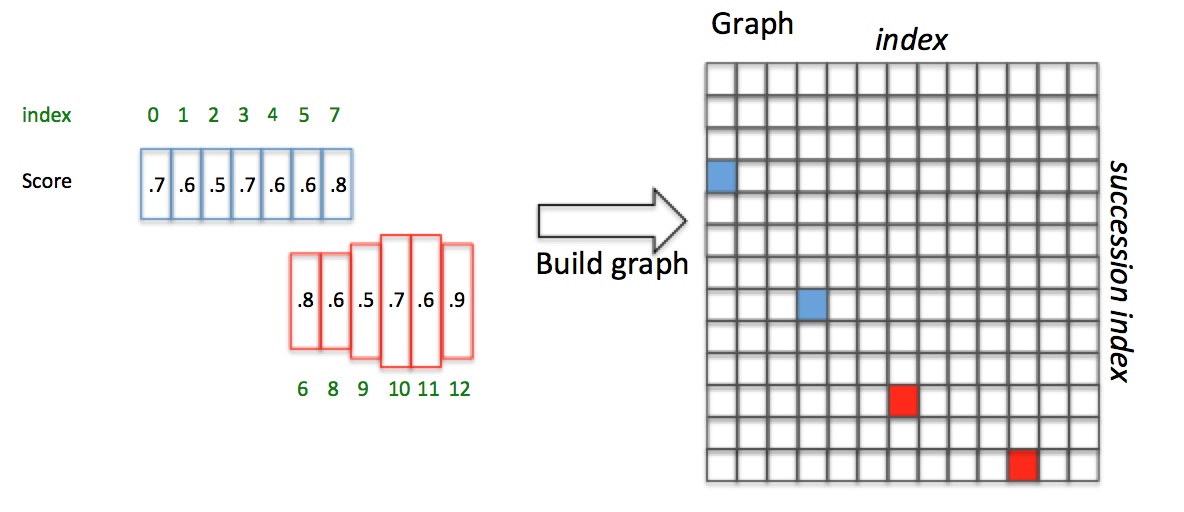 如上圖,Anchor已經按照x座標排序且Softmax score已知。對於box3(i=3),向前尋找50畫素,滿足overlapv>0.7且score最大的是box7(j=7);box7反向尋找,滿足overlapv>0.7且score最大的是box3(k=3)。因為scorei=3>=scorek=3,pair(box3,box7)是一個最長連線,設定Graph(3,7)=True。對於box4,正向尋找得到box7;box7反向尋找得到box3,但scorei=4>=scorek=3,所以pair(box4,box7)不是最長連線,包含在pair(box3,box7)中。
如上圖,Anchor已經按照x座標排序且Softmax score已知。對於box3(i=3),向前尋找50畫素,滿足overlapv>0.7且score最大的是box7(j=7);box7反向尋找,滿足overlapv>0.7且score最大的是box3(k=3)。因為scorei=3>=scorek=3,pair(box3,box7)是一個最長連線,設定Graph(3,7)=True。對於box4,正向尋找得到box7;box7反向尋找得到box3,但scorei=4>=scorek=3,所以pair(box4,box7)不是最長連線,包含在pair(box3,box7)中。
以這種方式,建立一個N×N(N是正Anchor數量)的connect graph,並遍歷graph。Graph(0,3)=True且Graph(3,7)=True,所以Anchor index 0->3->7組成藍色文字區域;Graph(6,10)=True且Graph(10,12)=True,所以Anchor index 6->10->12組成紅色文字區域。
綜上,我們通過Text proposals確定了文字檢測框。
2.【SegLink】
Seglink是在SSD基礎上改進的,基本思想是:一次性檢測整個文字行比較困難,就先檢測區域性片段,然後通過規則將所有的片段進行連線,得到最終的文字行。可以檢測任意長度和多方向的文字行,CTPN只能檢測水平方向。
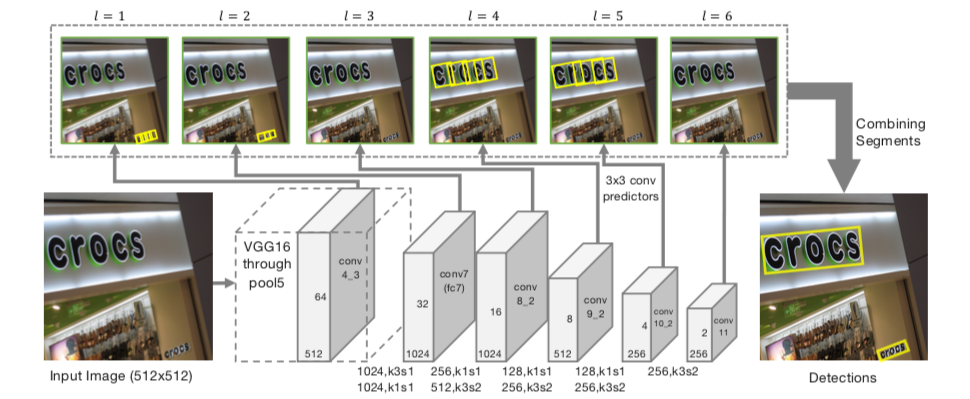
全卷積網路。輸入:任意尺寸影象;輸出:segments和links。
演算法流程:
(1). 沿用SSD網路結構,VGG16作為backbone並將最後兩個全連線層改成卷積層(fc6,fc7->conv6,conv7),再額外增加conv8, conv9, conv10, conv11,用於提取更深的特徵,最後的修改SSD的Pooling層,將其改為卷積層;
(2). 提取conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11不同層的特徵圖,尺寸1/2倍遞減;
(3). 對不同層的特徵圖使用3×3卷積,產生segments和links來檢測不同尺度文字行;
(4). 通過融合規則,將segment的box資訊和link資訊進行融合,得到最終的文字行。
關鍵策略:
(1). Segment檢測。
segment可以看作是增加了方向資訊的b-box,可以表示為:b = (xb,yb,wb,hb,θb)。卷積後輸出通道數為7,包含segment相對於預設框(default boxes)的偏移量(xs,ys,ws,hs,θs)及segment是否為文字的置信度(0,1)。特徵圖上的點在原圖中的對映,就是預設框的位置。6層特徵圖,每層都要輸出segments,例如:l層尺寸為 wl× hl,一個點在特徵圖上的座標為(x,y),對應原圖座標(xa,ya)的點,那麼一個預設框的中心座標就是(xa,ya):

不同於SSD,特徵圖每個位置只有一個長寬比為1的預設框,根據當前層的感受野通過經驗等式進行設定。最後,通過預設框和特徵圖迴歸segment的位置,預測的offsets裡除了Δx, Δy, Δw, Δh, 多了一個Δθ。

(2). Link檢測。
links分為Within-Layer Link和Cross-Layer Link:
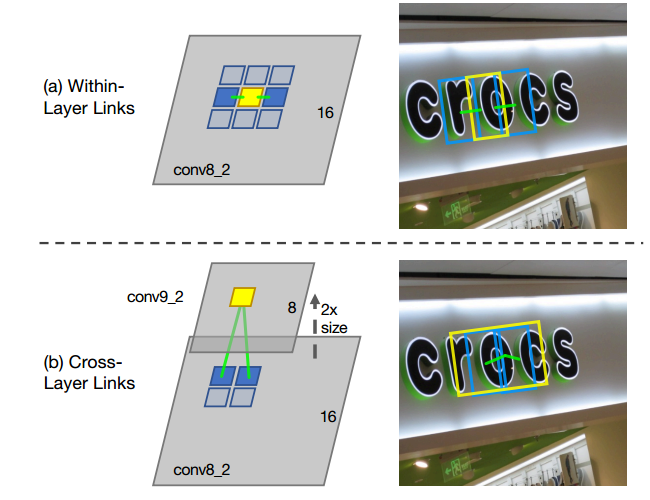
within-layer link在同一個feature map層,特徵圖中每個位置只預測一個segment,所以對於層內link,我們只考慮當前segment與它周圍的8連通鄰域的segment的連線情況,每個link有正負兩個分數,正分用來表示二者是否屬於同一個單詞,負分表示二者是否屬於不同單詞(應斷開連線)。這樣,每個segment的link是8*2=16維的向量,links就是每個特徵圖卷積後輸出16個通道,每兩個通道表示segment與鄰近的一個segment的link。

segment可能會被不同的feature map檢測到,如果不同層輸出segment是同一個位置,只是大小不一樣,會造成重複檢測的冗餘問題。cross-layer link連線的是相鄰兩層feature map產生的segments。前一層特徵圖的size是後一層的特徵圖的兩倍,這個size必須是偶數,所以輸入影象的寬和高必須是128的倍數。對於跨層link,特徵圖的每個位置需要預測2*4=8個權重,4表示與上一層的4個鄰域。

綜上,conv4_3層輸出的link維度為2*8=16;conv7, conv8_2, conv9_2, conv10_2, conv11其輸出的link維度為2*8+2*4=24。
(3). 合併演算法。
每層特徵圖提取出來後,再經過卷積,輸出既有segments又有links的預測。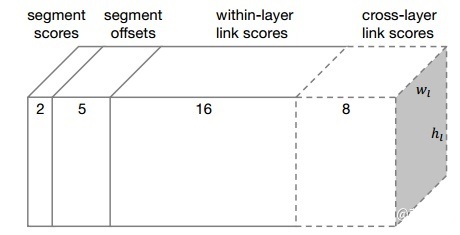 2表示二分類分數(是不是字元),5表示位置資訊(x, y, w, h, θ),16表示8個同層的neighbor連線或不連線的2種情況,8表示前一層的4個neighbor連線與不連線情況。對於conv4_3:其預測輸出維度為:2+5+2×8=23 ,因為該層沒有cross-layer link;對於conv7, conv8_2, conv9_2, conv10_2, conv11,其預測輸出維度為:2+5+2×8+2×4=31。
2表示二分類分數(是不是字元),5表示位置資訊(x, y, w, h, θ),16表示8個同層的neighbor連線或不連線的2種情況,8表示前一層的4個neighbor連線與不連線情況。對於conv4_3:其預測輸出維度為:2+5+2×8=23 ,因為該層沒有cross-layer link;對於conv7, conv8_2, conv9_2, conv10_2, conv11,其預測輸出維度為:2+5+2×8+2×4=31。

輸出一系列的segments和links後,1. 首先人工設定α和β(對應segments和links的置信度設定不同的閾值)過濾噪聲;2. 再採用DFS(depth first search)將segments看做node,links看做edge,將他們連線起來;3. 將連線後的所有結果作為輸入,將連線在一起的segments當作是一個小的集合,稱為B;4. 將B集合中所有segment的旋轉角求平均值作為文字框的旋轉角稱為θb;5. 求tanθb作為斜率,得到一系列的平行線,求得B集合中所有segment的中心點到直線距離的和最小的那條直線;6. 將B集合中所有segment的中心點垂直投影到3步驟中找到的直線上;7. 在投影中找到距離最遠的兩個點(xp,yp),(xq,yq);8. 上述兩點的均值作為框的中心點,距離為框的寬,B集合中所有segment的高的均值就是高。
注:3-5其實就是最小二乘法線性迴歸。
(4). 訓練。
訓練當前網路需要生成groundtruth,包括default box的label,偏移(x, y, w, h, θ),層內link及跨層link的label。求segments和links的標籤前先確定與其對應的default box的標籤值。影象只有一個文字框時,滿足如下2點就是正樣本(否則負樣本):1. default box的中心在當前文字行內;2. default box的大小al與文字框的高h滿足公式: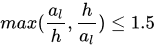 。影象中有多個文字框時,default box對於任意文字框都不滿足上述條件時為負樣本,否則為正樣本,滿足多個文字框時,該default box為與其大小最相近的文字框的正樣本,大小相近指的是:
。影象中有多個文字框時,default box對於任意文字框都不滿足上述條件時為負樣本,否則為正樣本,滿足多個文字框時,該default box為與其大小最相近的文字框的正樣本,大小相近指的是: 。通過上述規則得到default box的正樣本後,基於這些正樣本計算segments相對於default box的位置偏移量。offset只對正樣本有效,負樣本不需要計算。
。通過上述規則得到default box的正樣本後,基於這些正樣本計算segments相對於default box的位置偏移量。offset只對正樣本有效,負樣本不需要計算。
 將文字框順時針旋轉θ與default box進行水平對齊,然後進行裁剪,寬度保留與default box相交的部分,最後再繞文字框中心點逆時針轉回到原來的角度,就可以得到一個segment。根據公式(segment檢測),就可以求出segment和default box的偏移量,用來訓練segment。link的標籤值只要滿足下面兩個條件即為真:1. link連線的兩個default box都為正樣本;2. 兩個default box屬於同一個文字框。
將文字框順時針旋轉θ與default box進行水平對齊,然後進行裁剪,寬度保留與default box相交的部分,最後再繞文字框中心點逆時針轉回到原來的角度,就可以得到一個segment。根據公式(segment檢測),就可以求出segment和default box的偏移量,用來訓練segment。link的標籤值只要滿足下面兩個條件即為真:1. link連線的兩個default box都為正樣本;2. 兩個default box屬於同一個文字框。
損失函式定義如下:
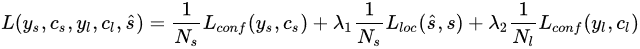
ys表示所有的segments的標籤值,如果第i個default box為正樣本,yis=1,否則為0;yl表示所有links的標籤值;cs,cl分別為segments和links的預測值;Lconf為softmax loss,用於計算segments和links置信度的損失;Lloc為為Smooth L1 regression loss,用於計算segments預測偏移量和標籤值的損失;Ns為影象中所有正樣本的default box的數量;Nl為影象中所有正樣本的links的個數;λ1=λ2=1。關於Data Augmentation和Online Hard Negative Mining,做法和SSD中一致。
3.【EAST/AdvancedEAST】
EAST可以實現端到端文字檢測。
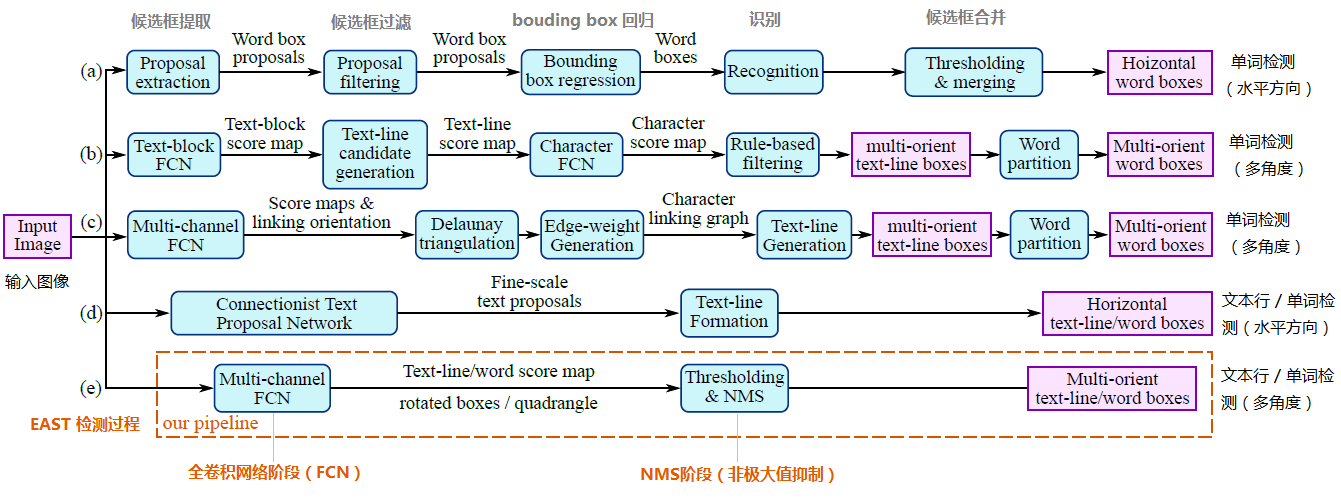
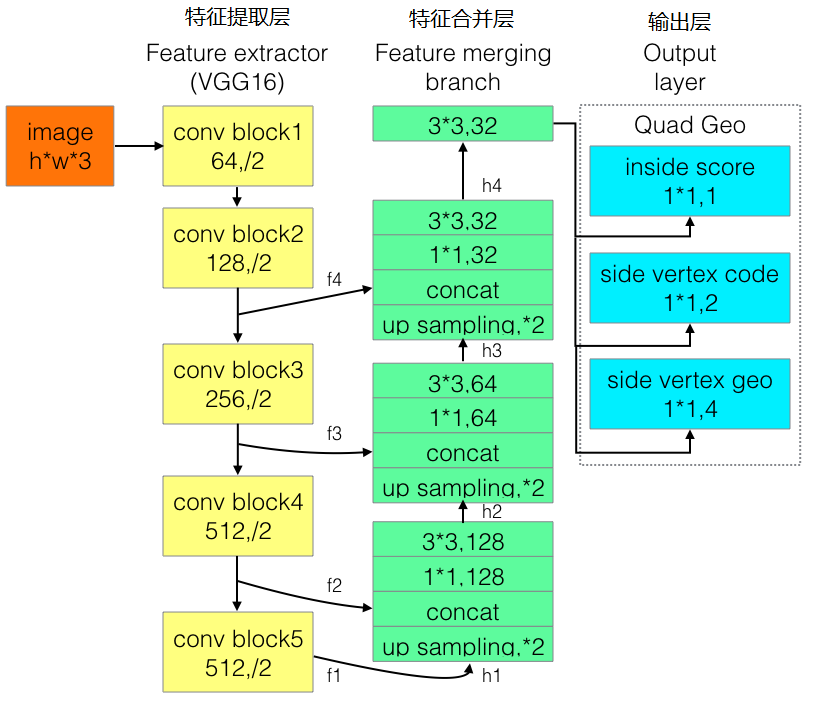
a~d是幾種常見的文字檢測過程,典型的檢測過程包括候選框提取、候選框過濾、b-box迴歸、候選框合併等階段,中間過程比較冗長。EAST模型檢測過程簡化為只有FCN,NMS階段,中間過程大大縮減,且輸出結果支援文字行、單詞的多角度檢測,高效準確,適應性強。EAST模型的網路結構分為特徵提取層、特徵融合層、輸出層三大部分。
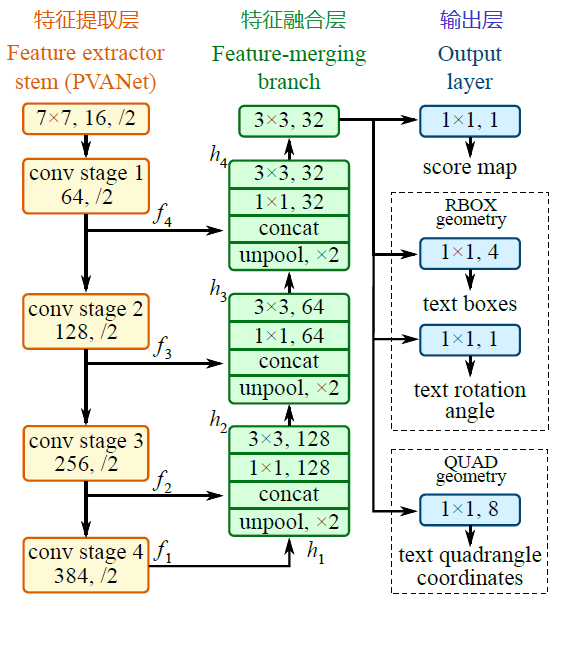
演算法流程:
(1). PVANet(也可採用VGG16,Resnet等)作為主幹網路提取特徵,並借鑑FPN思想,抽取4個尺度(1/4,1/8,1/16,1/32 input)的特徵圖;
(2). 參考UNet的方法,從feature extractor頂部按規則向下合併特徵;
(3). 輸出文字得分和文字形狀。檢測形狀為RBOX時,輸出檢測框置信度、檢測框的位置角度(x,y,w,h,θ)共6個引數;檢測形狀為QUAD時,輸出檢測框置信度、任意四邊形檢測框(定位扭曲變形文字行)的位置座標(x1, y1), (x2, y2), (x3, y3), (x4, y4)共9個引數。
關鍵策略:
(1). 特徵融合規則。
最後一層特徵圖被最先送入uppooling層放大2倍,再與前一層的特徵圖進行concatenate,然後依次進行1×1和3×3卷積;再重複上述過程2次,卷積核的個數(128,64,32)依次遞減;最後經過3×3,32的卷積層。
(2). 訓練。
QUAD訓練樣本生成:
通常資料集提供的標註為平行四邊形的四個頂點(x1, y1), (x2, y2), (x3, y3), (x4, y4),訓練網路時,需要的將其轉化為網路需要的形式,即這個平行四邊形生成的9個單通道圖片。
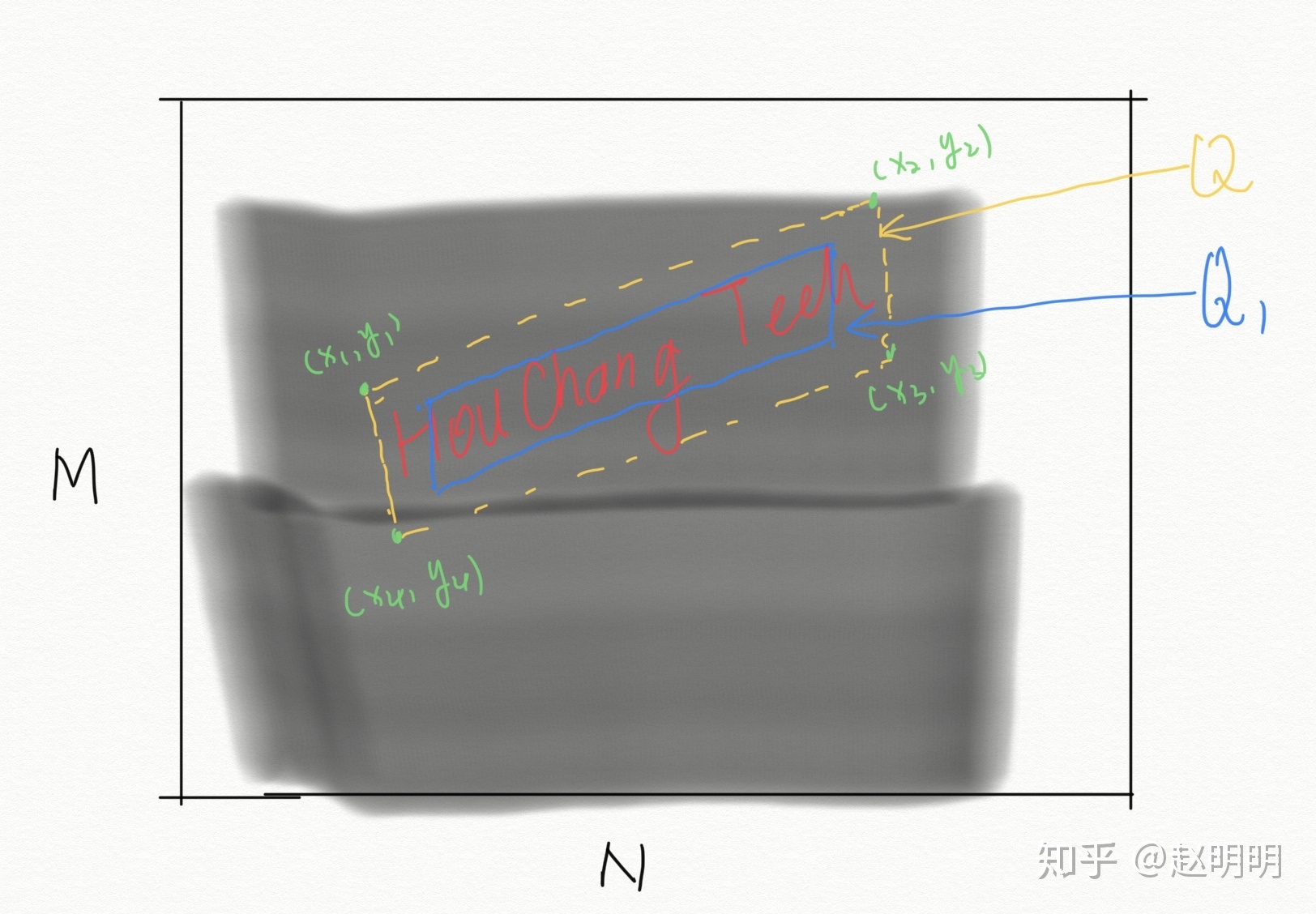

通道1:置信度score map。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將平行四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 將這個四邊形向內縮小0.3,得到Q1;4. 將四邊形Q1內的點置為1;5. 將矩陣A按比例縮小為原圖的1/4,得到score map(長M/4,寬N/4)。
通道2:四邊形位置germety map_1。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = x1-xi;將矩陣A按比例縮小為原圖的1/4,得到germety map_1(長M/4,寬N/4)。
通道3:四邊形位置germety map_2。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = y1-yi;將矩陣A按比例縮小為原圖的1/4,得到germety map_2(長M/4,寬N/4)。
通道4:四邊形位置germety map_3。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = x2-xi;將矩陣A按比例縮小為原圖的1/4,得到germety map_3(長M/4,寬N/4)。
通道5:四邊形位置germety map_4。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = y2-yi;將矩陣A按比例縮小為原圖的1/4,得到germety map_4(長M/4,寬N/4)。
通道6:四邊形位置germety map_5。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = x3-xi;將矩陣A按比例縮小為原圖的1/4,得到germety map_5(長M/4,寬N/4)。
通道7:四邊形位置germety map_6。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = y3-yi;將矩陣A按比例縮小為原圖的1/4,得到germety map_6(長M/4,寬N/4)。
通道8:四邊形位置germety map_7。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = x4-xi;將矩陣A按比例縮小為原圖的1/4,得到germety map_7(長M/4,寬N/4)。
通道9:四邊形位置germety map_8。
1. 生成一個大小為MxN的全零矩陣A,M,N為原圖的長和寬;2. 將四邊形的四個頂點兩兩相連,連成一個四邊形Q;3. 給四邊形Q內的每一個畫素賦值,A(xi,yi) = y4-yi;將矩陣A按比例縮小為原圖的1/4,得到germety map_8(長M/4,寬N/4)。
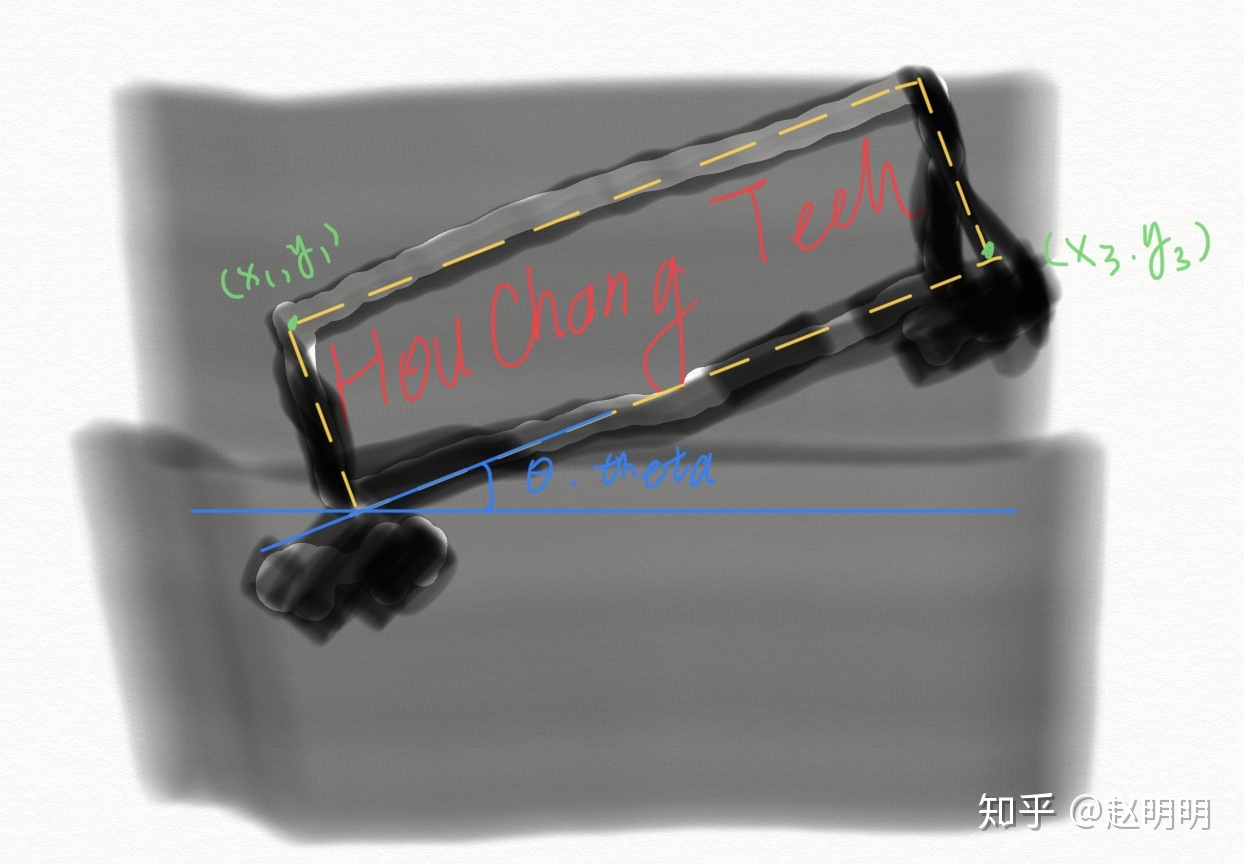
RBOX訓練樣本生成:
通常資料集提供的標註為5個值Theta,x1,y1,x3,y3,訓練網路時,需要的將其轉化為網路需要的形式,即這個旋轉的矩陣生成的6個單通道圖片。在此之前,先利用theta,x1,y1,x2,y2,生成矩形的另外兩個頂點(x2,y2),(x4,y4),這樣,矩形的四個頂點可以表示為(x1,y1),(x2,y2),(x3,y3),(x4,y4)。
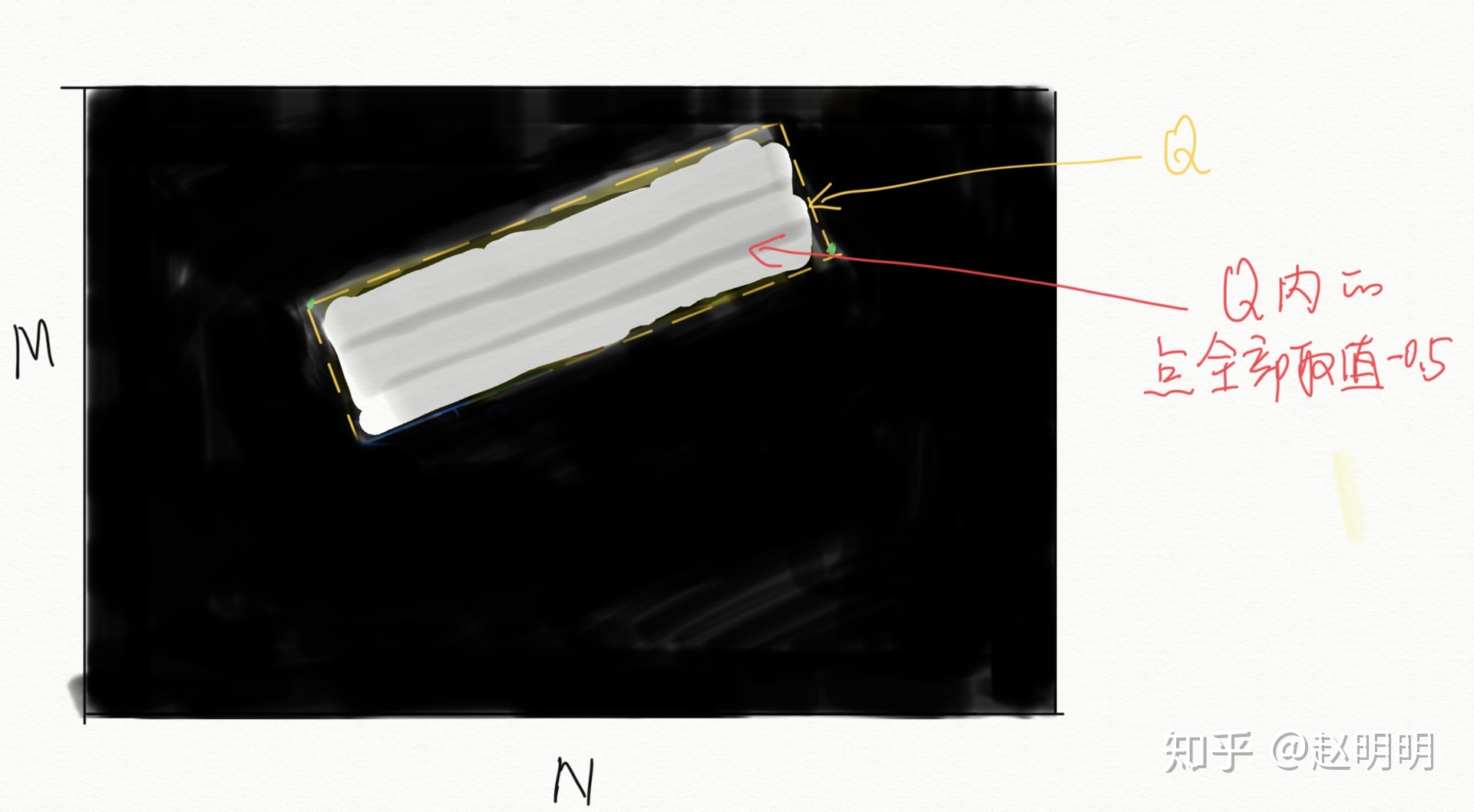

通道1:置信度score map。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將矩形的四個頂點兩兩相連,形成一個矩形Q;3. 將矩形Q內的點置為1;4. 將矩陣A按比例縮小為原圖的1/4,得到score map(長M/4,寬N/4)。
通道2:角度angle map。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將矩形的四個頂點兩兩相連,形成一個矩形Q;3. 將矩形Q內的點置為theta,如果theta=-0.5,那麼Q內的所有點都為-0.5;4. 將矩陣A按比例縮小為原圖的1/4,得到angle map(長M/4,寬N/4)。
通道3:矩形位置germety map_1。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將矩形的四個頂點兩兩相連,形成一個矩形Q;3. 給矩形Q內的每一個畫素賦值,A(xi,yi) = distance[ A(xi,yi), 直線A(x1,y1)A(x2,y2)] ;4. 將矩陣A按比例縮小為原圖的1/4,得到germety map_1(長M/4,寬N/4)。
通道4:矩形位置germety map_2。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將矩形的四個頂點兩兩相連,形成一個矩形Q;3. 給矩形Q內的每一個畫素賦值,A(xi,yi) = distance[ A(xi,yi), 直線A(x2,y2)A(x3,y3)] ;4. 將矩陣A按比例縮小為原圖的1/4,得到germety map_2(長M/4,寬N/4)。
通道5:矩形位置germety map_3。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將矩形的四個頂點兩兩相連,形成一個矩形Q;3. 給矩形Q內的每一個畫素賦值,A(xi,yi) = distance[ A(xi,yi), 直線A(x3,y3)A(x4,y4)] ;4. 將矩陣A按比例縮小為原圖的1/4,得到germety map_3(長M/4,寬N/4)。
通道6:矩形位置germety map_4。
1. 生成一個大小MxN為全零矩陣A,M,N為原圖的長和寬;2. 將矩形的四個頂點兩兩相連,形成一個矩形Q;3. 給矩形Q內的每一個畫素賦值,A(xi,yi) = distance[ A(xi,yi), 直線A(x4,y4)A(x1,y1)] ;4. 將矩陣A按比例縮小為原圖的1/4,得到germety map_4(長M/4,寬N/4)。
訓練Loss:
loss由分數圖損失(score map loss)和幾何形狀損失(geometry loss)兩部分組成。分數圖損失採用的是類平衡交叉熵,用於解決類別不平衡訓練,具體實戰中,一般採用dice loss,收斂速度更快。幾何形狀損失,針對RBOX loss採用IoU損失,針對QUAD loss採用smoothed-L1損失。本文中幾何體數量較多,普通的NMS計算複雜度過高,EAST提出了基於行合併幾何體的方法,locality-aware NMS。
為改進EAST的長文字檢測效果不佳的缺陷,有人提出了Advanced EAST。Advanced EAST以VGG16作為網路結構的骨幹,同樣由特徵提取層、特徵合併層、輸出層三部分構成,比EAST,尤其是在長文字上的檢測準確性更好。
三. 文字識別
文字識別,根據待識別的文字特點一般分為定長文字、不定長文字兩大類,前者(如:驗證碼識別)相對簡單,這裡不做分析。
1.【LSTM+CTC】
LSTM(Long Short Term Memory,長短期記憶網路)是一種特殊結構的RNN,用於解決RNN的隨著輸入資訊的時間間隔不斷增大,出現“梯度消失”或“梯度爆炸”的長期依賴問題。CTC(Connectionist Temporal Classifier,聯接時間分類器),主要用於解決輸入特徵與輸出標籤的對齊問題。由於字元變形等原因,分塊識別時,相鄰塊可能會識別為同個結果,字元重複出現。通過CTC來解決對齊問題,模型訓練後,對結果中去掉間隔字元、去掉重複字元。

2.【CRNN】
CRNN(Convolutional Recurrent Neural Network,卷積迴圈神經網路)是目前比較流行的文字識別模型,可以進行端到端的訓練,不需要對樣本資料進行字元分割,可識別任意長度的文字序列,模型速度快、效能好。
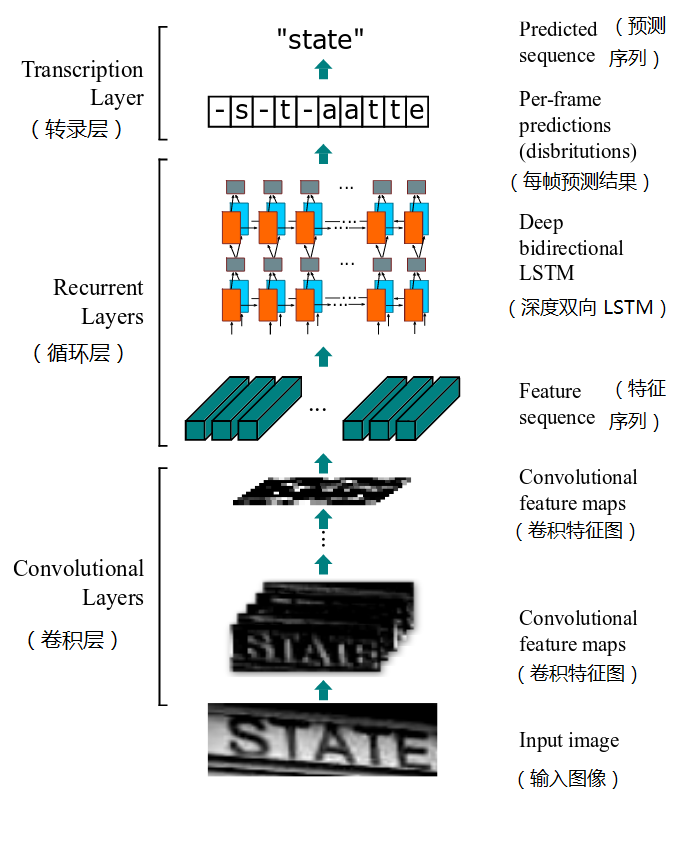

演算法流程:
(1). 卷積層:從輸入影象中提取出特徵序列;
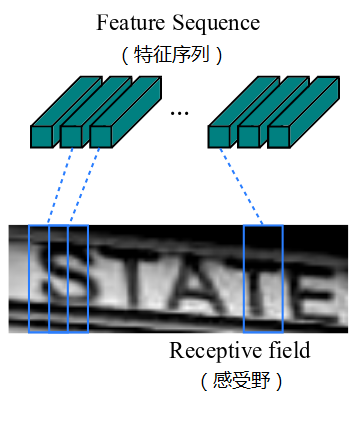
先做預處理,把所有輸入影象縮放到相同高度,預設是32,寬度可任意長;然後進行卷積運算(由類似VGG的卷積、最大池化和BN層組成);再從左到右提取序列特徵,作為迴圈層的輸入,每個特徵向量表示了影象上一定寬度內的特徵,預設是單個畫素1(由於CRNN已將輸入影象縮放到同樣高度了,因此只需按照一定的寬度提取特徵即可)。
(2). 迴圈層:預測從卷積層獲取的特徵序列的標籤分佈;
迴圈層由一個雙向LSTM構成,預測特徵序列中的每一個特徵向量的標籤分佈。由於LSTM需要時間維度,模型中把序列的width當作time steps。“Map-to-Sequence”層用於特徵序列的轉換,將誤差從迴圈層反饋到卷積層,是卷積層和迴圈層之間的橋樑。
(3). 轉錄層:把從迴圈層獲取的標籤分佈通過去重、整合等操作轉換成最終的識別結果。
轉錄層是將LSTM網路預測的特徵序列的結果進行整合,轉換為最終輸出的結果。在CRNN模型中雙向LSTM網路層的最後連線上一個CTC模型,從而做到了端對端的識別。
四. 程式碼實現
CTPN:https://github.com/eragonruan/text-detection-ctpn
SegLink:https://github.com/dengdan/seglink
EAST:https://github.com/argman/EAST
AdvancedEAST:https://github.com/huoyijie/AdvancedEAST
CRNN:https://github.com/Belval/CRNN
五. Reference
https://my.oschina.net/u/876354
https://zhuanlan.zhihu.com/p/34757009
https://www.jianshu.com/p/109231be4a24
https://zhuanlan.zhihu.com/p/37781277
https://me.csdn.net/imPlok
&n