
圖解MySQL索引(上)—MySQL有中“8種”索引?
關於MySQL索引相關的內容,一直是一個讓人頭疼的問題,尤其是對於初學者來說。筆者曾在很長一段時間內深陷其中,無法分清“覆蓋索引,輔助索引,唯一索引,Hash索引,B-Tree索引……”到底是些什麼東西,導致在面試過程中進入比較尷尬的局面。
很多人可能會抱怨”面試造火箭,工作擰螺絲,很多知識都是為了面試學的,工作中根本用不到!“。慶幸的是,MySQL中索引不僅是面試必考知識,還是工作中用到最為頻繁的必備技能,在筆者看來,索引是MySQL中價效比最高的一部分內容。
由於MySQL中支援多種儲存引擎,在不同的儲存引擎中實現略微有所差距,索引下文中如果沒有特殊宣告,預設指的都是InnoDB儲存引擎,下文中索引基於這張user表來進行演示。
| id | name | age |
|---|---|---|
| 001 | Lily | 18 |
| 002 | Tom | 20 |
| 003 | Jack | 19 |
| 004 | John | 28 |
| 005 | Alice | 24 |
| 006 | Lucy | 21 |
| 007 | Rose | 18 |
| 008 | Steven | 16 |
一、索引的底層資料結構
首先,索引是高效獲取資料的資料結構。就像書中的目錄一樣,我們可以通過它快速定位到資料所在的位置,從而提高資料查詢的效率。
在MySQL中有許多關於索引的名詞和概念,對於初學者來說很容易被迷惑。為了方便理解,我建立了一張表,從具體的案例中嘗試說清楚這些概念到底是什麼。
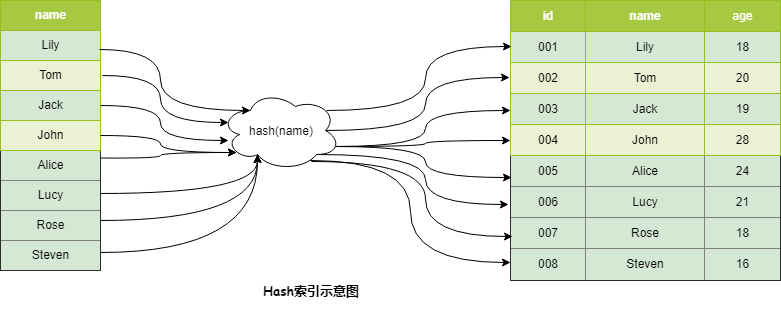
Hash索引
正如上文中說到,索引是提高查詢效率的資料結構,而能夠提高查詢效率的資料結構有很多,如二叉搜尋樹,紅黑樹,跳錶,雜湊表(散列表)等,而MySQL中用到了B+Tree和散列表(Hash表)作為索引的底層資料結構。
需要注意的是,MySQL並沒有顯式支援Hash索引,而是作為內部的一種優化,對於熱點的資料會自動生成Hash索引,也叫自適應Hash索引。
Hash索引在等值查詢中,可以O(1)時間複雜度定位到資料,效率非常高,但是不支援範圍查詢。在許多程式語言以及資料庫中都會用到這個資料結構,如Redis支援的Hash資料結構。具體結構如下:
B+Tree索引
提到B+Tree首先不的不提B-Tree,B-Tree(多路搜尋樹,並不是二叉的)是一種常見的資料結構。使用B-tree結構可以顯著減少定位記錄時所經歷的中間過程,從而加快存取速度。

B+ 樹是基於B-Tree升級後的一種樹資料結構,通常用於資料庫和作業系統的檔案系統中。B+ 樹的特點是能夠保持資料穩定有序,其插入與修改擁有較穩定的對數時間複雜度。B+ 樹元素自底向上插入,這與二叉樹恰好相反。
MySQL索引的實現也是基於這種高效的資料結構。具體資料結構如下:
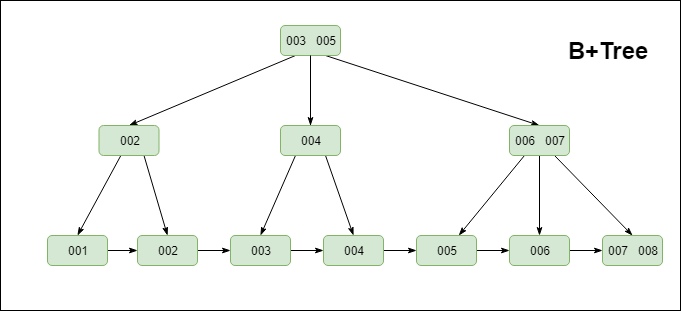
筆者首先要宣告一下,不要將B樹,B-Tree以及B+Tree弄混淆。首先,B-Tree就是B樹,中間的“-”是一箇中劃線,而不是減號,並不存在"B減樹"這種資料結構。其次,就是B+Tree和B-Tree實現索引時有兩個區別,具體可見下圖
①B+Tree只在葉子節點儲存資料,而B-Tree的資料儲存在各個節點中

②B+Tree的葉子節點間通過指標連結,可以通過遍歷葉子節點即可獲取所有資料。
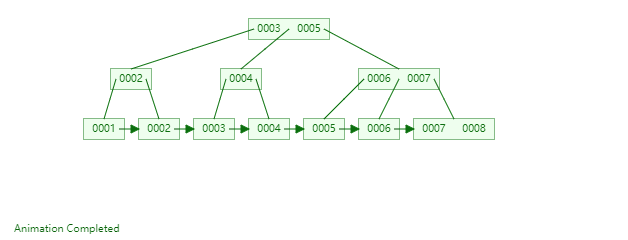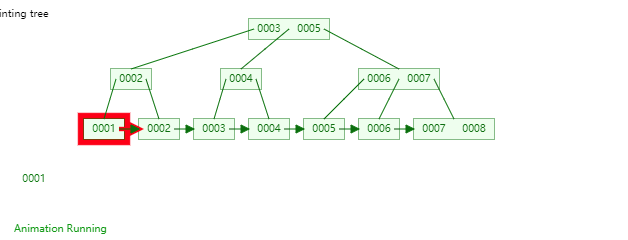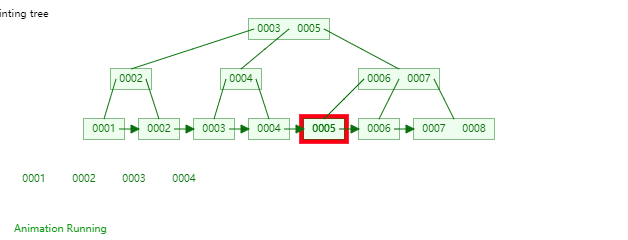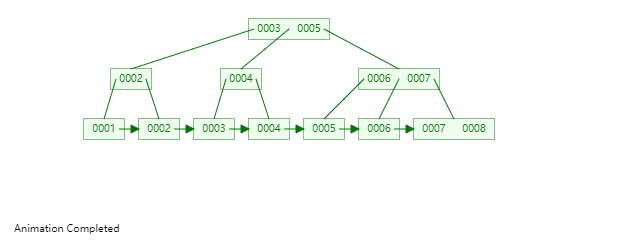
B+Tree是一種神奇的資料結構,如果用語言來講可能會優點費勁,感興趣的同學可以點選這裡進行資料結構視覺化,操作一番後想必會有所收穫,下圖是筆者演示B+Tree的資料插入方式(自下而上)。
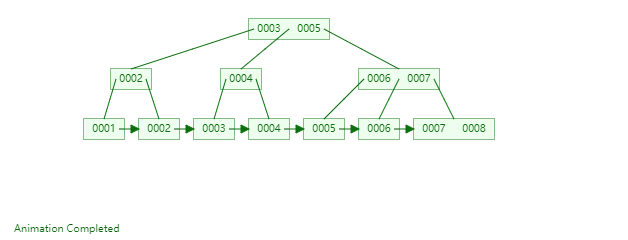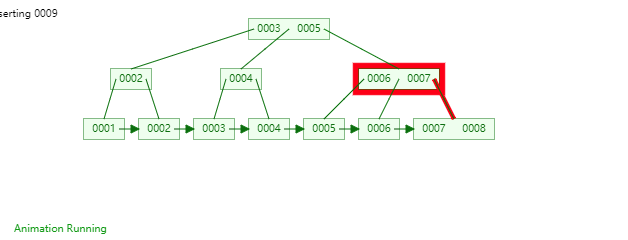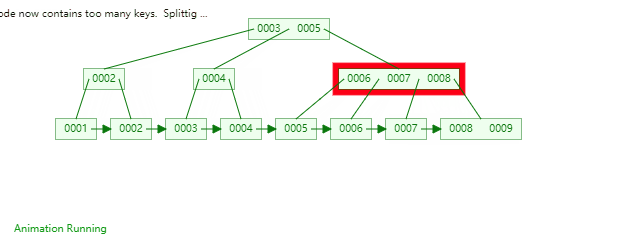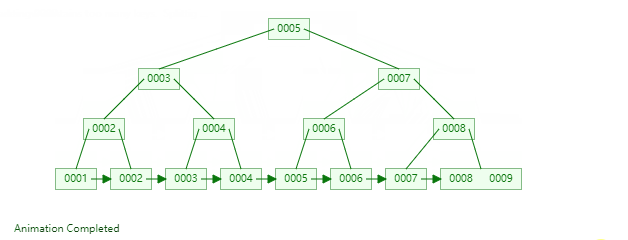
二,資料組織方式
根據資料的組織方式,可以分為聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。如果是索引組織資料,就稱之為聚簇索引,否則稱之為非聚簇索引,簡單來說索引和資料是否儲存在一起。
需要注意的是,這種索引劃分方式通常用來體現不同儲存引擎的組織資料方式的差異(通常指的是InnoDB和MyISAM儲存引擎)。而InnoDB中的輔助索引並不能稱之為非聚簇索引,關於輔助索引的內容,下文會進行詳細介紹。InnoDB中是通過索引來組織資料,為聚簇索引。
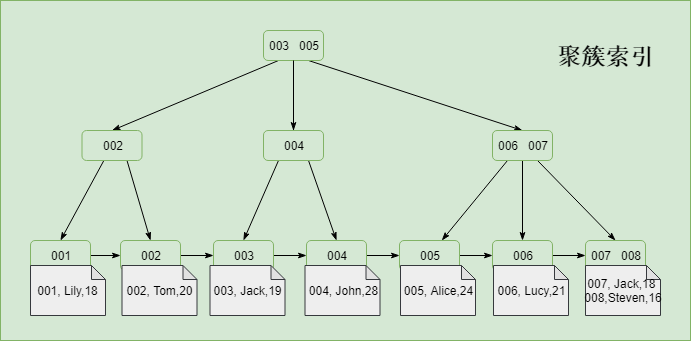
而MyISAM中索引和資料檔案分開儲存,為非聚簇索引。B+Tree的葉子節點儲存的是資料存放的地址,而不是具體的資料 。
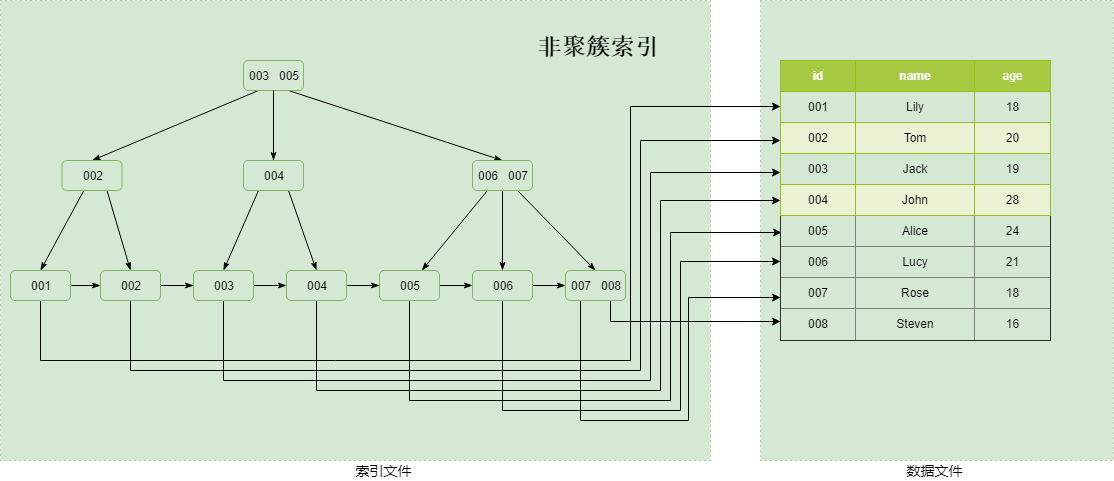
三,索引欄位個數
為了能應對不同的資料檢索需求,索引即可以僅包含一個欄位,也可以同時包含多個欄位。單個欄位組成的索引可以稱為單值索引,否則稱之為複合索引(或者稱為組合索引或多值索引)。上文中演示的都是單值索引,所以接下來展示一下複合索引作為對比。
複合索引的索引的資料順序跟欄位的順序相關,包含多個值的索引中,如果當前面欄位的值重複時,將會按照其後面的值進行排序。
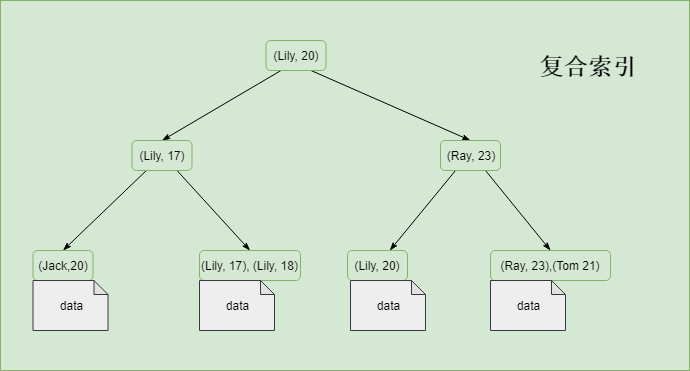
四, 是否儲存完整資料行
MySQL中是根據主鍵來組織資料,所以每張表都必須有主鍵索引,主鍵索引只能有一個,不能為null同時必須保證唯一性。建表時如果沒有指定主鍵索引,則會自動生成一個隱藏的欄位作為主鍵索引。
如果不是主鍵索引,則就可以稱之為非主鍵索引,又可以稱之為輔助索引,二級索引。主鍵索引的葉子節點儲存了完整的資料行,而非主鍵索引的葉子節點儲存的則是主鍵索引值,通過非主鍵索引查詢資料時,會先查詢到主鍵索引,然後再到主鍵索引上去查詢對應的資料,這個過程叫做回表(下文中會再次提到)。
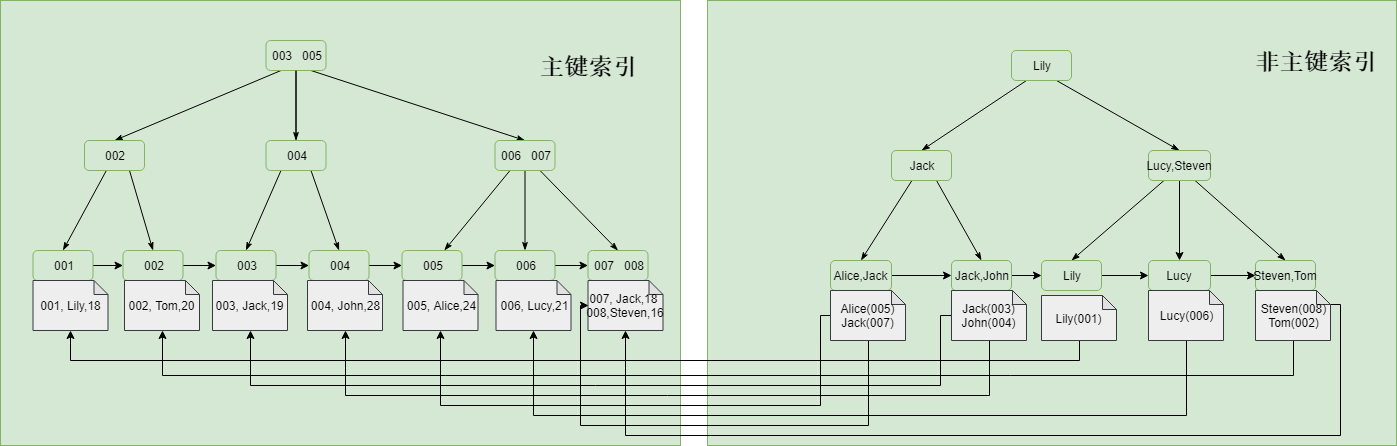
五,其他分類
唯一索引
唯一索引,不允許具有索引值相同的行,從而禁止重複的索引或鍵值。系統在建立該索引時檢查是否有重複的鍵值,並在每次使用 INSERT 或 UPDATE 語句新增資料時進行檢查, 如果有重複的值,則會操作失敗,丟擲異常。
需要注意的時,主鍵索引一定時唯一索引,而唯一索引不一定時主鍵索引。唯一索引可以理解為僅僅是將索引設定一個唯一性的屬性。
覆蓋索引
上文提到了一個回表的概念,既如果通過非主鍵索引查詢資料時,會先查詢到主鍵索引的值,然後再去主鍵索引中查詢具體的資料,整個查詢流程需要掃描兩次索引,顯然回表是一個耗時的操作。
為了減少回表次數,再設計索引時我們可以讓索引中包含要查詢的結果,在輔助索引中檢索到資料後直接返回,而不需要進行回表操作。
但是需要注意的是,使用覆蓋索引的前提是欄位長度比較短,對於值長度較長的欄位則不適合使用覆蓋索引,原因有很多,比如索引一般儲存在記憶體中,如果佔用空間較大,則可能會從磁碟中載入,影響效能。當然還有其他原因,具體情況將會在下一篇文章中介紹。
六,總結
本文從不同維度介紹了MySQL中的索引,索引從不同維度劃分可以有很多種名稱,但是需要明確一個問題就是,索引的本質是一種資料結構,其他索引的劃分則是針對實際應用而言。具體分類如下圖所示:
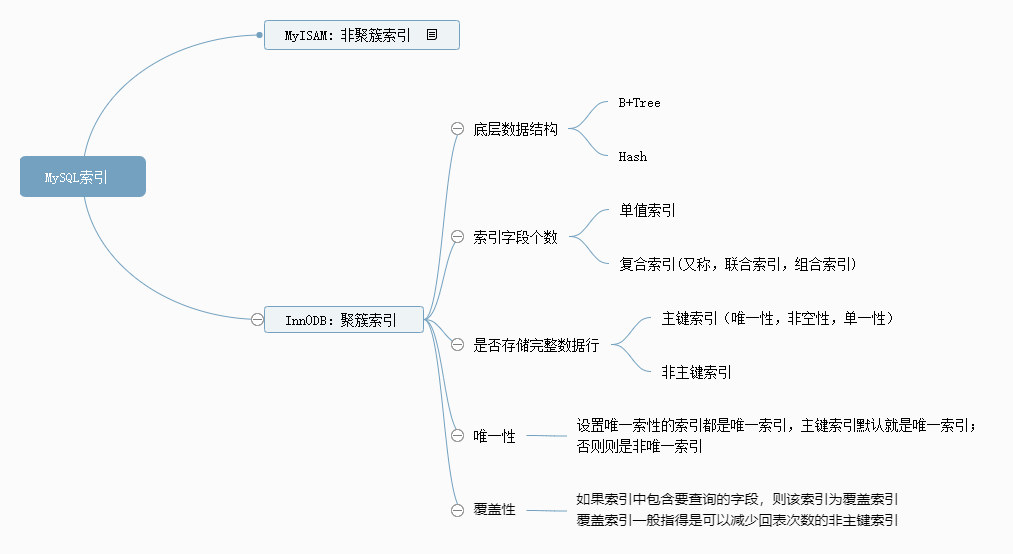
目的是讓大家對於索引有個初步且清晰的認識,解決What的問題。後續將會針對Why以及How,進行深入探討,當然,首先應當能區分本章文章中講述的概念性問題。
七、Q&A
1. 為什麼MySQL索引使用B+Tree實現,而不是搜尋二叉樹,紅黑樹或者跳錶?
這是一個綜合性問題,遠不止看起來那麼簡單,小夥伴們可以把答案寫在留言區我們一起探討,同樣筆者將會在下一篇文章中重點介紹為什麼,以及如何正確使用索引。
