
Kafka體系架構詳細分解
阿新 • • 發佈:2020-03-08
我的個人部落格排版更舒服: https://www.luozhiyun.com/archives/260
## 基本概念
### Kafka 體系架構
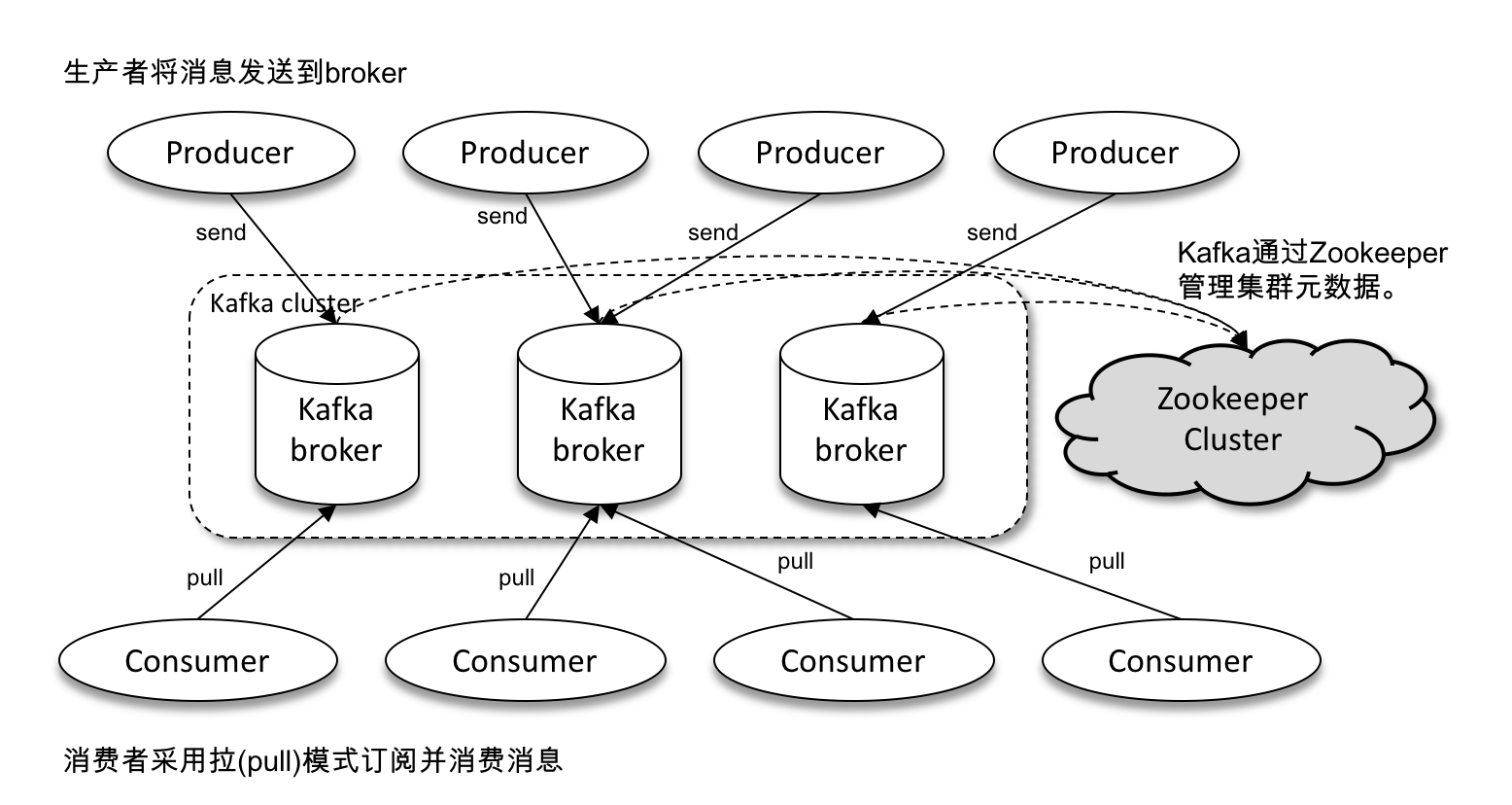
Kafka 體系架構包括若干 Producer、若干 Broker、若干 Consumer,以及一個 ZooKeeper 叢集。
在 Kafka 中還有兩個特別重要的概念—主題(Topic)與分割槽(Partition)。
Kafka 中的訊息以主題為單位進行歸類,生產者負責將訊息傳送到特定的主題(傳送到 Kafka 叢集中的每一條訊息都要指定一個主題),而消費者負責訂閱主題並進行消費。
主題是一個邏輯上的概念,它還可以細分為多個分割槽,一個分割槽只屬於單個主題,很多時候也會把分割槽稱為主題分割槽(Topic-Partition)。
Kafka 為分割槽引入了多副本(Replica)機制,通過增加副本數量可以提升容災能力。同一分割槽的不同副本中儲存的是相同的訊息(在同一時刻,副本之間並非完全一樣),副本之間是“一主多從”的關係,其中 leader 副本負責處理讀寫請求,follower 副本只負責與 leader 副本的訊息同步。當 leader 副本出現故障時,從 follower 副本中重新選舉新的 leader 副本對外提供服務。
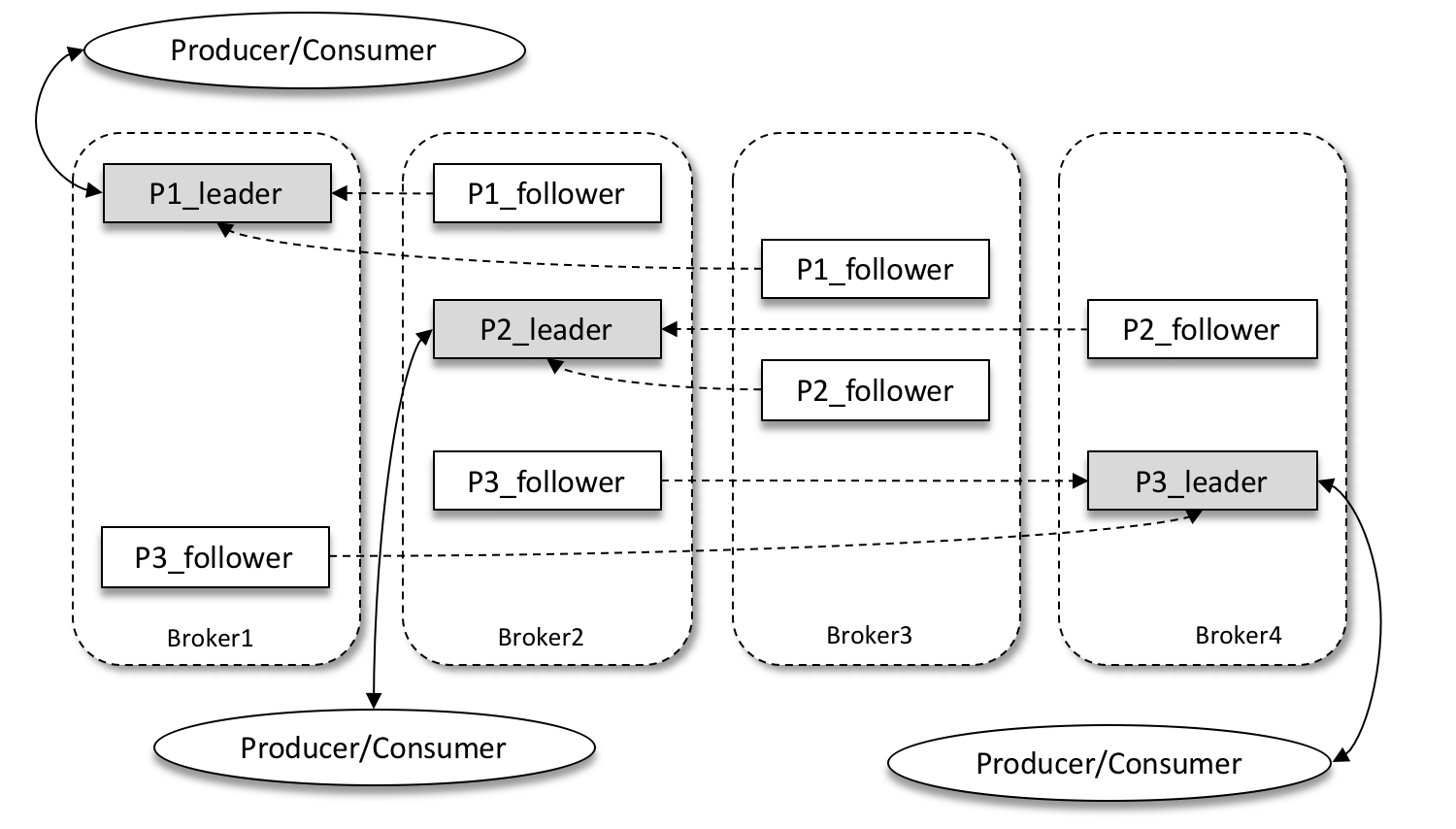
如上圖所示,Kafka 叢集中有4個 broker,某個主題中有3個分割槽,且副本因子(即副本個數)也為3,如此每個分割槽便有1個 leader 副本和2個 follower 副本。
### 資料同步
分割槽中的所有副本統稱為 AR(Assigned Replicas)。所有與 leader 副本保持一定程度同步的副本(包括 leader 副本在內)組成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一個子集。
與 leader 副本同步滯後過多的副本(不包括 leader 副本)組成 OSR(Out-of-Sync Replicas),由此可見,AR=ISR+OSR。在正常情況下,所有的 follower 副本都應該與 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合為空。
Leader 副本負責維護和跟蹤 ISR 集合中所有 follower 副本的滯後狀態,當 follower 副本落後太多或失效時,leader 副本會把它從 ISR 集合中剔除。預設情況下,當 leader 副本發生故障時,只有在 ISR 集合中的副本才有資格被選舉為新的 leader。
HW 是 High Watermark 的縮寫,俗稱高水位,它標識了一個特定的訊息偏移量(offset),消費者只能拉取到這個 offset 之前的訊息。
LEO 是 Log End Offset 的縮寫,它標識當前日誌檔案中下一條待寫入訊息的 offset。
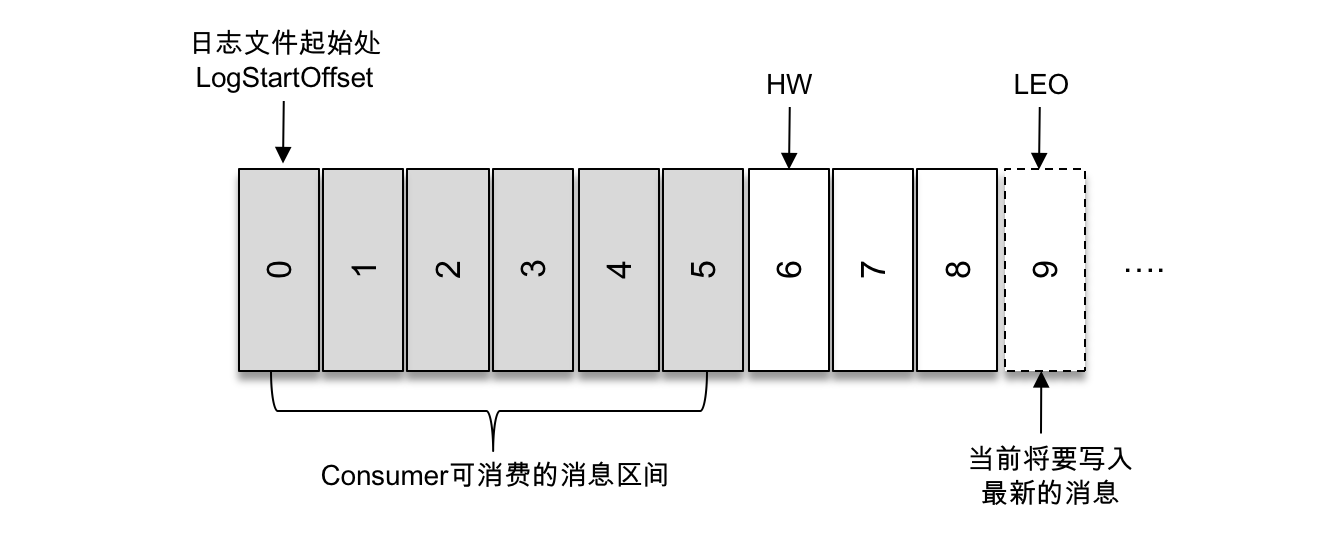
如上圖所示,第一條訊息的 offset(LogStartOffset)為0,最後一條訊息的 offset 為8,offset 為9的訊息用虛線框表示,代表下一條待寫入的訊息。日誌檔案的 HW 為6,表示消費者只能拉取到 offset 在0至5之間的訊息,而 offset 為6的訊息對消費者而言是不可見的。
## Kafka生產者客戶端的整體結構
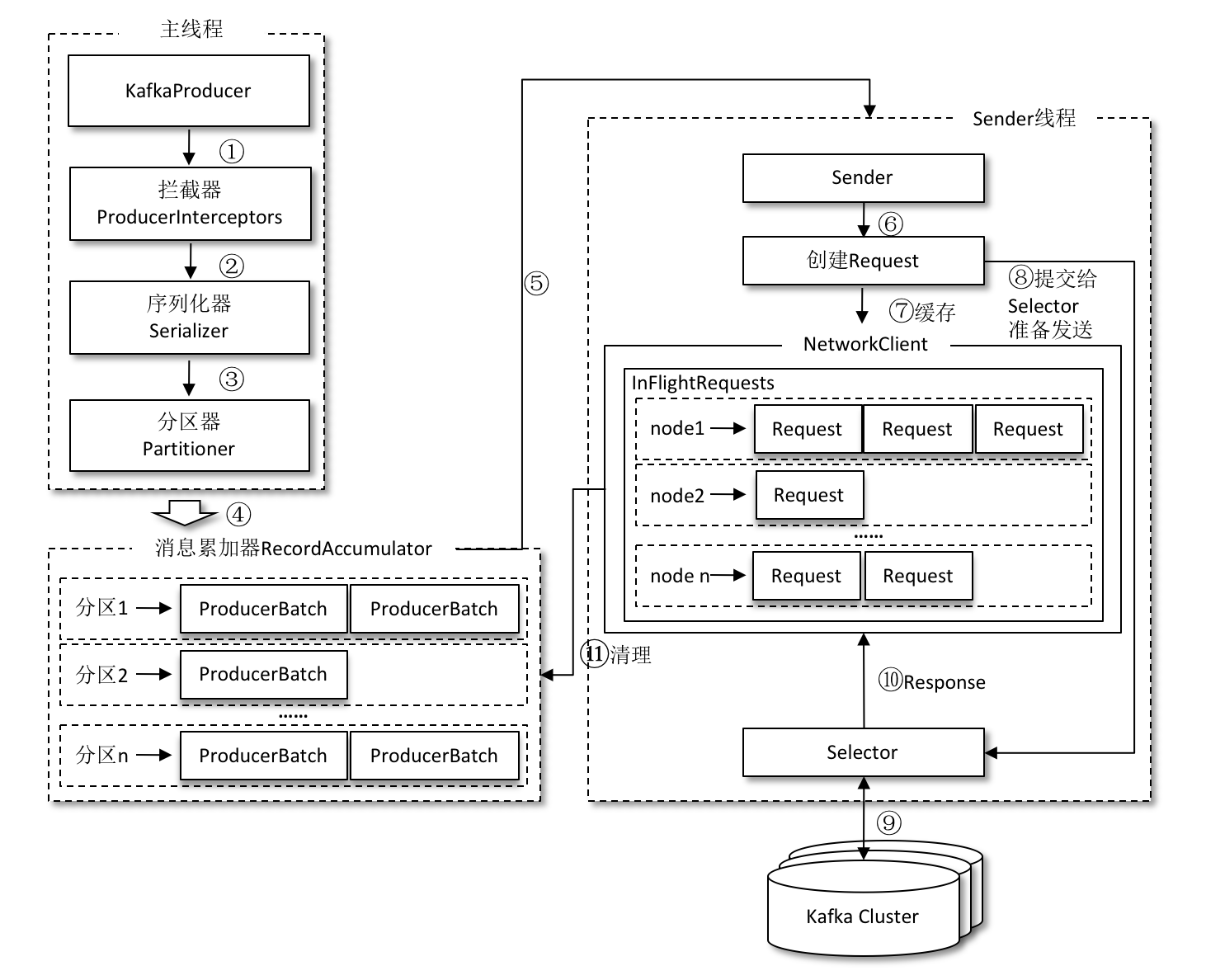
整個生產者客戶端由兩個執行緒協調執行,這兩個執行緒分別為主執行緒和 Sender 執行緒(傳送執行緒)。
在主執行緒中由 KafkaProducer 建立訊息,然後通過可能的攔截器、序列化器和分割槽器的作用之後快取到訊息累加器(RecordAccumulator,也稱為訊息收集器)中。Sender 執行緒負責從 RecordAccumulator 中獲取訊息並將其傳送到 Kafka 中。
**RecordAccumulator**
RecordAccumulator 主要用來快取訊息以便 Sender 執行緒可以批量傳送,進而減少網路傳輸的資源消耗以提升效能。
主執行緒中傳送過來的訊息都會被追加到 RecordAccumulator 的某個雙端佇列(Deque)中,在 RecordAccumulator 的內部為每個分割槽都維護了一個雙端佇列。
訊息寫入快取時,追加到雙端佇列的尾部;Sender 讀取訊息時,從雙端佇列的頭部讀取。
Sender 從 RecordAccumulator 中獲取快取的訊息之後,會進一步將原本<分割槽, Deque< ProducerBatch>> 的儲存形式轉變成 的形式,其中 Node 表示 Kafka 叢集的 broker 節點。
KafkaProducer 要將此訊息追加到指定主題的某個分割槽所對應的 leader 副本之前,首先需要知道主題的分割槽數量,然後經過計算得出(或者直接指定)目標分割槽,之後 KafkaProducer 需要知道目標分割槽的 leader 副本所在的 broker 節點的地址、埠等資訊才能建立連線,最終才能將訊息傳送到 Kafka。
所以這裡需要一個轉換,對於網路連線來說,生產者客戶端是與具體的 broker 節點建立的連線,也就是向具體的 broker 節點發送訊息,而並不關心訊息屬於哪一個分割槽。
**InFlightRequests**
請求在從 Sender 執行緒發往 Kafka 之前還會儲存到 InFlightRequests 中,InFlightRequests 儲存物件的具體形式為 Map,它的主要作用是快取了已經發出去但還沒有收到響應的請求(NodeId 是一個 String 型別,表示節點的 id 編號)。
### 攔截器
生產者攔截器既可以用來在訊息傳送前做一些準備工作,比如按照某個規則過濾不符合要求的訊息、修改訊息的內容等,也可以用來在傳送回撥邏輯前做一些定製化的需求,比如統計類工作。
生產者攔截器的使用也很方便,主要是自定義實現 org.apache.kafka.clients.producer. ProducerInterceptor 介面。ProducerInterceptor 介面中包含3個方法:
```java
public ProducerRecord onSend(ProducerRecord record);
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
public void close();
```
KafkaProducer 在將訊息序列化和計算分割槽之前會呼叫生產者攔截器的 onSend() 方法來對訊息進行相應的定製化操作。一般來說最好不要修改訊息 ProducerRecord 的 topic、key 和 partition 等資訊。
KafkaProducer 會在訊息被應答(Acknowledgement)之前或訊息傳送失敗時呼叫生產者攔截器的 onAcknowledgement() 方法,優先於使用者設定的 Callback 之前執行。這個方法執行在 Producer 的I/O執行緒中,所以這個方法中實現的程式碼邏輯越簡單越好,否則會影響訊息的傳送速度。
close() 方法主要用於在關閉攔截器時執行一些資源的清理工作。
### 序列化器
生產者需要用序列化器(Serializer)把物件轉換成位元組陣列才能通過網路傳送給 Kafka。而在對側,消費者需要用反序列化器(Deserializer)把從 Kafka 中收到的位元組陣列轉換成相應的物件。
生產者使用的序列化器和消費者使用的反序列化器是需要一一對應的,如果生產者使用了某種序列化器,比如 StringSerializer,而消費者使用了另一種序列化器,比如 IntegerSerializer,那麼是無法解析出想要的資料的。
序列化器都需要實現org.apache.kafka.common.serialization.Serializer 介面,此介面有3個方法:
```java
public void configure(Map configs, boolean isKey)
public byte[] serialize(String topic, T data)
public void close()
```
configure() 方法用來配置當前類,serialize() 方法用來執行序列化操作。而 close() 方法用來關閉當前的序列化器。
如下:
```java
public class StringSerializer implements Serializer {
private String encoding = "UTF8";
@Override
public void configure(Map configs, boolean isKey) {
String propertyName = isKey ? "key.serializer.encoding" :
"value.serializer.encoding";
Object encodingValue = configs.get(propertyName);
if (encodingValue == null)
encodingValue = configs.get("serializer.encoding");
if (encodingValue != null && encodingValue instanceof String)
encoding = (String) encodingValue;
}
@Override
public byte[] serialize(String topic, String data) {
try {
if (data == null)
return null;
else
return data.getBytes(encoding);
} catch (UnsupportedEncodingException e) {
throw new SerializationException("Error when serializing " +
"string to byte[] due to unsupported encoding " + encoding);
}
}
@Override
public void close() {
// nothing to do
}
}
```
configure() 方法,這個方法是在建立 KafkaProducer 例項的時候呼叫的,主要用來確定編碼型別。
serialize用來編解碼,如果 Kafka 客戶端提供的幾種序列化器都無法滿足應用需求,則可以選擇使用如 Avro、JSON、Thrift、ProtoBuf 和 Protostuff 等通用的序列化工具來實現,或者使用自定義型別的序列化器來實現。
### 分割槽器
訊息經過序列化之後就需要確定它發往的分割槽,如果訊息 ProducerRecord 中指定了 partition 欄位,那麼就不需要分割槽器的作用,因為 partition 代表的就是所要發往的分割槽號。
如果訊息 ProducerRecord 中沒有指定 partition 欄位,那麼就需要依賴分割槽器,根據 key 這個欄位來計算 partition 的值。分割槽器的作用就是為訊息分配分割槽。
Kafka 中提供的預設分割槽器是 org.apache.kafka.clients.producer.internals.DefaultPartitioner,它實現了 org.apache.kafka.clients.producer.Partitioner 介面,這個介面中定義了2個方法,具體如下所示。
```java
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
public void close();
```
其中 partition() 方法用來計算分割槽號,返回值為 int 型別。partition() 方法中的引數分別表示主題、鍵、序列化後的鍵、值、序列化後的值,以及叢集的元資料資訊,通過這些資訊可以實現功能豐富的分割槽器。close() 方法在關閉分割槽器的時候用來回收一些資源。
在預設分割槽器 DefaultPartitioner 的實現中,close() 是空方法,而在 partition() 方法中定義了主要的分割槽分配邏輯。如果 key 不為 null,那麼預設的分割槽器會對 key 進行雜湊,最終根據得到的雜湊值來計算分割槽號,擁有相同 key 的訊息會被寫入同一個分割槽。如果 key 為 null,那麼訊息將會以輪詢的方式發往主題內的各個可用分割槽。
自定義的分割槽器,只需同 DefaultPartitioner 一樣實現 Partitioner 介面即可。由於每個分割槽下的訊息處理都是有順序的,我們可以利用自定義分割槽器實現在某一系列的key都發送到一個分割槽中,從而實現有序消費。
## Broker
### Broker處理請求流程

在Kafka的架構中,會有很多客戶端向Broker端傳送請求,Kafka 的 Broker 端有個 SocketServer 元件,用來和客戶端建立連線,然後通過Acceptor執行緒來進行請求的分發,由於Acceptor不涉及具體的邏輯處理,非常得輕量級,因此有很高的吞吐量。
接著Acceptor 執行緒採用輪詢的方式將入站請求公平地發到所有網路執行緒中,網路執行緒池預設大小是 3個,表示每臺 Broker 啟動時會建立 3 個網路執行緒,專門處理客戶端傳送的請求,可以通過Broker 端引數 num.network.threads來進行修改。
那麼接下來處理網路執行緒處理流程如下:

當網路執行緒拿到請求後,會將請求放入到一個共享請求佇列中。Broker 端還有個 IO 執行緒池,負責從該佇列中取出請求,執行真正的處理。如果是 PRODUCE 生產請求,則將訊息寫入到底層的磁碟日誌中;如果是 FETCH 請求,則從磁碟或頁快取中讀取訊息。
IO 執行緒池處中的執行緒是執行請求邏輯的執行緒,預設是8,表示每臺 Broker 啟動後自動建立 8 個 IO 執行緒處理請求,可以通過Broker 端引數 num.io.threads調整。
Purgatory元件是用來快取延時請求(Delayed Request)的。比如設定了 acks=all 的 PRODUCE 請求,一旦設定了 acks=all,那麼該請求就必須等待 ISR 中所有副本都接收了訊息後才能返回,此時處理該請求的 IO 執行緒就必須等待其他 Broker 的寫入結果。
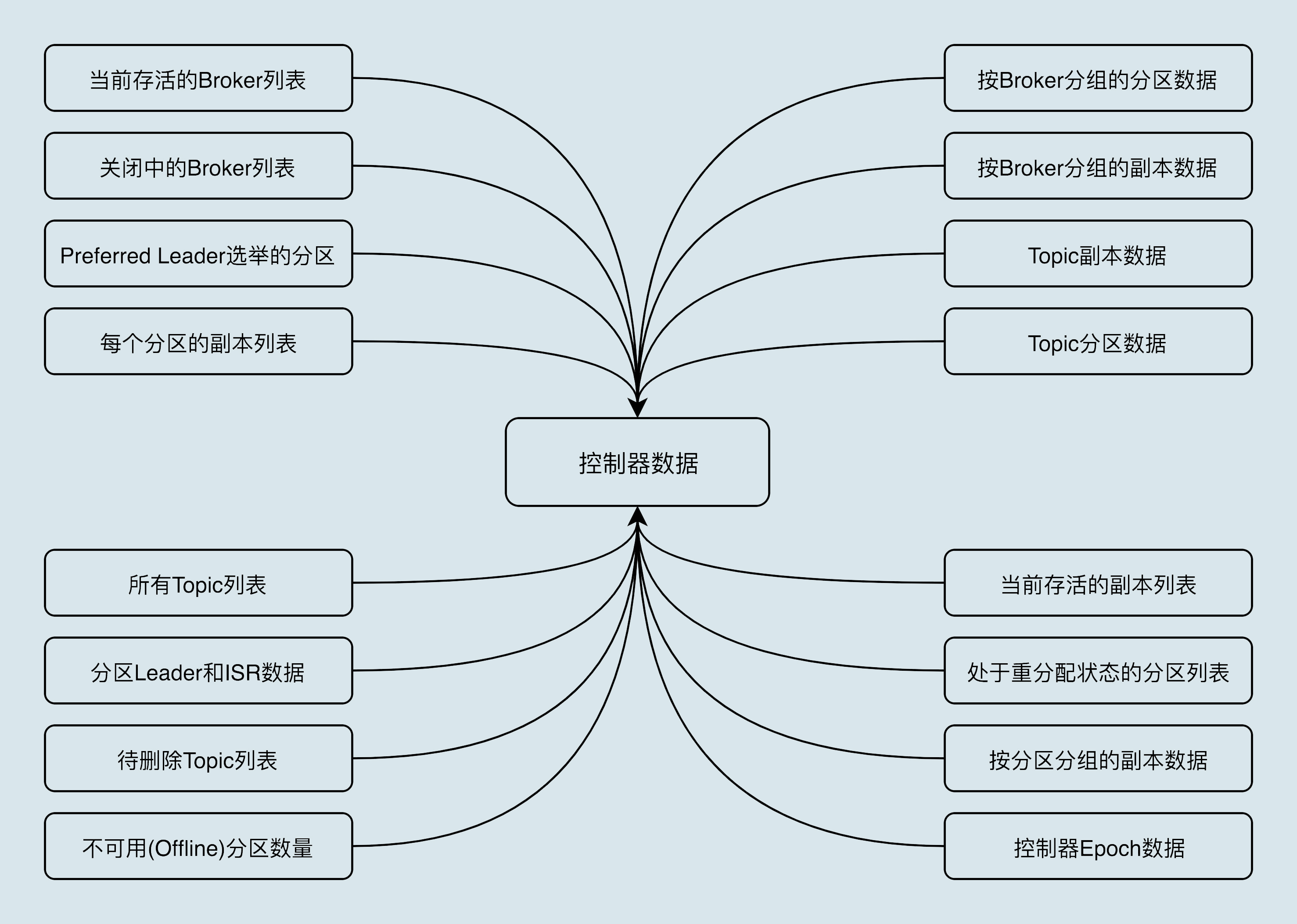
### 控制器
在 Kafka 叢集中會有一個或多個 broker,其中有一個 broker 會被選舉為控制器(Kafka Controller),它負責管理整個叢集中所有分割槽和副本的狀態。
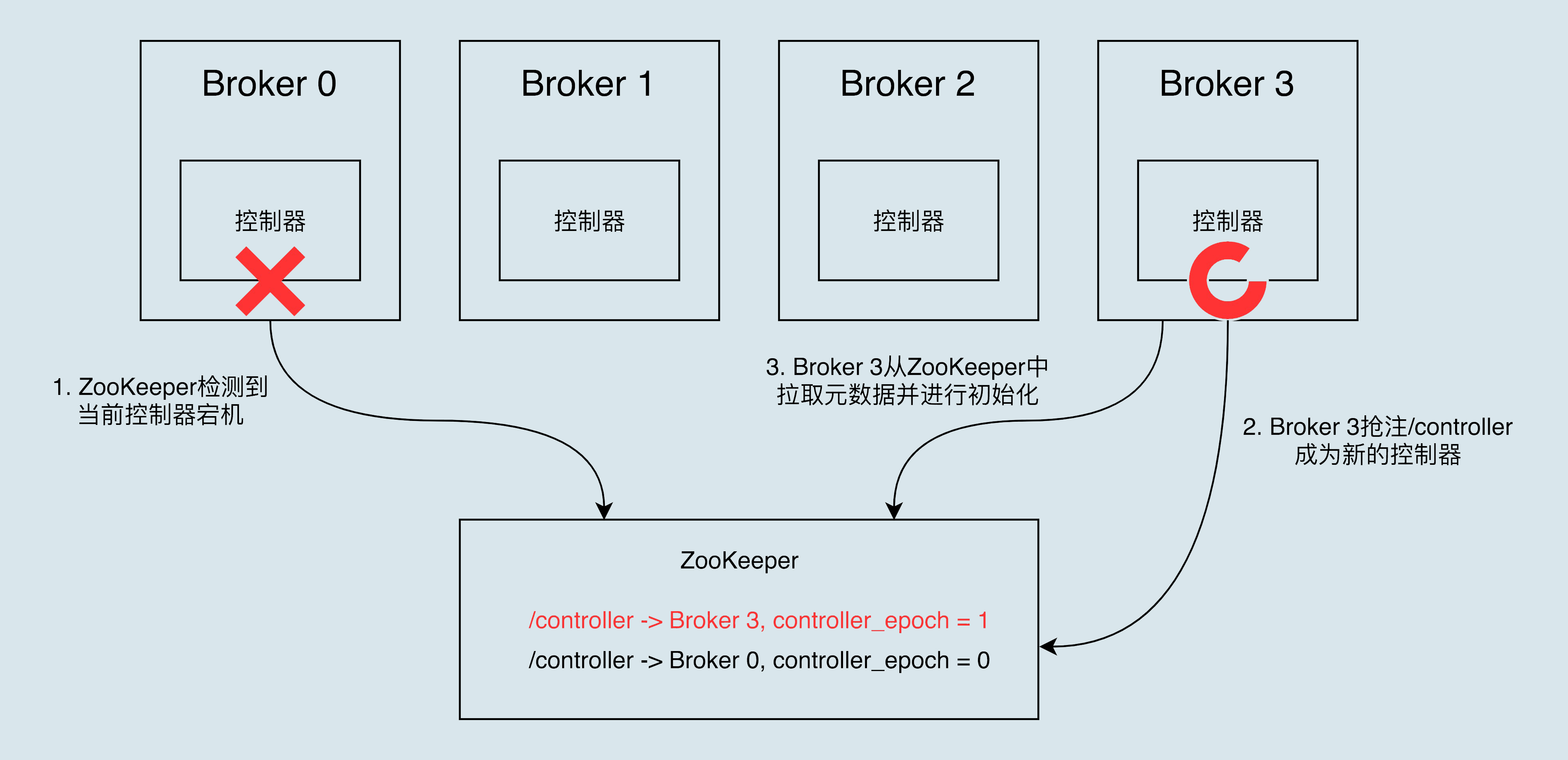
#### 控制器是如何被選出來的?
Broker 在啟動時,會嘗試去 ZooKeeper 中建立 /controller 節點。Kafka 當前選舉控制器的規則是:第一個成功建立 /controller 節點的 Broker 會被指定為控制器。
在ZooKeeper中的 /controller_epoch 節點中存放的是一個整型的 controller_epoch 值。controller_epoch 用於記錄控制器發生變更的次數,即記錄當前的控制器是第幾代控制器,我們也可以稱之為“控制器的紀元”。
controller_epoch 的初始值為1,即叢集中第一個控制器的紀元為1,當控制器發生變更時,每選出一個新的控制器就將該欄位值加1。Kafka 通過 controller_epoch 來保證控制器的唯一性,進而保證相關操作的一致性。
每個和控制器互動的請求都會攜帶 controller_epoch 這個欄位,如果請求的 controller_epoch 值小於記憶體中的 controller_epoch 值,則認為這個請求是向已經過期的控制器所傳送的請求,那麼這個請求會被認定為無效的請求。
如果請求的 controller_epoch 值大於記憶體中的 controller_epoch 值,那麼說明已經有新的控制器當選了。
#### 控制器是做什麼的?
* 主題管理(建立、刪除、增加分割槽)
* 分割槽重分配
* Preferred 領導者選舉
Preferred 領導者選舉主要是 Kafka 為了避免部分 Broker 負載過重而提供的一種換 Leader 的方案。
* 叢集成員管理(新增 Broker、Broker 主動關閉、Broker 宕機)
控制器元件會利用 Watch 機制檢查 ZooKeeper 的 /brokers/ids 節點下的子節點數量變更。目前,當有新 Broker 啟動後,它會在 /brokers 下建立專屬的 znode 節點。一旦建立完畢,ZooKeeper 會通過 Watch 機制將訊息通知推送給控制器,這樣,控制器就能自動地感知到這個變化,進而開啟後續的新增 Broker 作業。
* 資料服務
控制器上儲存了最全的叢集元資料資訊。
#### 控制器宕機了怎麼辦?
當執行中的控制器突然宕機或意外終止時,Kafka 能夠快速地感知到,並立即啟用備用控制器來代替之前失敗的控制器。這個過程就被稱為 Failover,該過程是自動完成的,無需你手動干預。
## 消費者
### 消費組
在Kafka中,每個消費者都有一個對應的消費組。當訊息釋出到主題後,只會被投遞給訂閱它的每個消費組中的一個消費者。每個消費者只能消費所分配到的分割槽中的訊息。而每一個分割槽只能被一個消費組中的一個消費者所消費。
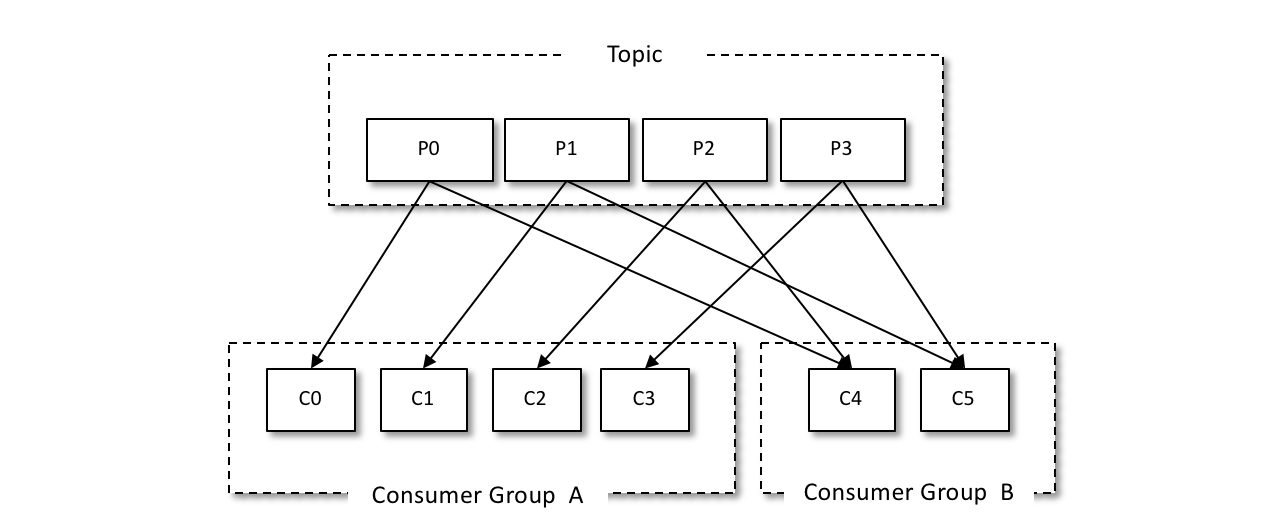
入上圖所示,我們可以設定兩個消費者組來實現廣播訊息的作用,消費組A和組B都可以接受到生產者傳送過來的訊息。
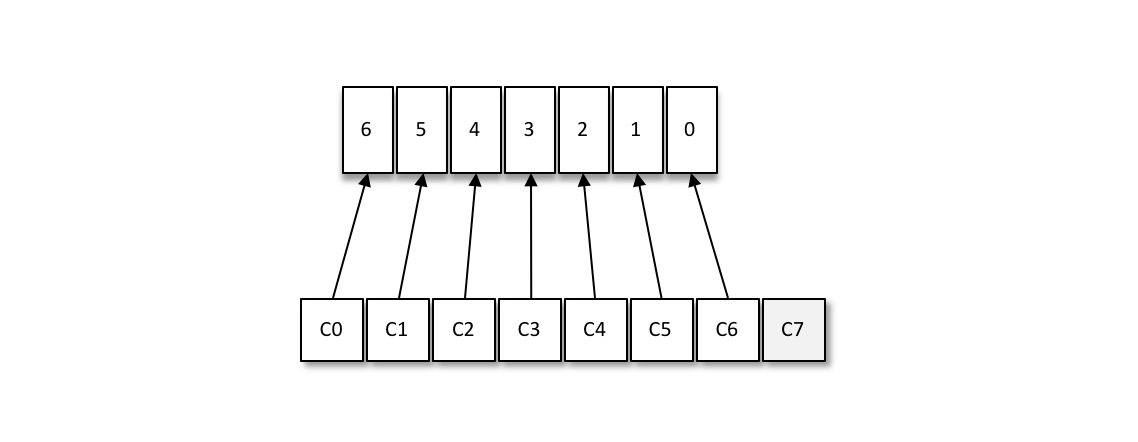
消費者與消費組這種模型可以讓整體的消費能力具備橫向伸縮性,我們可以增加(或減少)消費者的個數來提高(或降低)整體的消費能力。對於分割槽數固定的情況,一味地增加消費者並不會讓消費能力一直得到提升,如果消費者過多,出現了**消費者的個數大於分割槽個數**的情況,就會有消費者分配不到任何分割槽。
如下:一共有8個消費者,7個分割槽,那麼最後的消費者C7由於分配不到任何分割槽而無法消費任何訊息。
### 消費端分割槽分配策略
Kafka 提供了消費者客戶端引數 partition.assignment.strategy 來設定消費者與訂閱主題之間的分割槽分配策略。
**RangeAssignor分配策略**
預設情況下,採用 RangeAssignor 分配策略。
RangeAssignor 分配策略的原理是按照消費者總數和分割槽總數進行整除運算來獲得一個跨度,然後將分割槽按照跨度進行平均分配,以保證分割槽儘可能均勻地分配給所有的消費者。對於每一個主題,RangeAssignor 策略會將消費組內所有訂閱這個主題的消費者按照名稱的字典序排序,然後為每個消費者劃分固定的分割槽範圍,如果不夠平均分配,那麼字典序靠前的消費者會被多分配一個分割槽。
假設消費組內有2個消費者 C0 和 C1,都訂閱了主題 t0 和 t1,並且每個主題都有4個分割槽,那麼訂閱的所有分割槽可以標識為:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最終的分配結果為:
```
消費者C0:t0p0、t0p1、t1p0、t1p1
消費者C1:t0p2、t0p3、t1p2、t1p3
```
假設上面例子中2個主題都只有3個分割槽,那麼訂閱的所有分割槽可以標識為:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最終的分配結果為:
```
消費者C0:t0p0、t0p1、t1p0、t1p1
消費者C1:t0p2、t1p2
```
可以明顯地看到這樣的分配並不均勻。
**RoundRobinAssignor分配策略**
RoundRobinAssignor 分配策略的原理是將消費組內所有消費者及消費者訂閱的所有主題的分割槽按照字典序排序,然後通過輪詢方式逐個將分割槽依次分配給每個消費者。
如果同一個消費組內所有的消費者的訂閱資訊都是相同的,那麼 RoundRobinAssignor 分配策略的分割槽分配會是均勻的。
如果同一個消費組內的消費者訂閱的資訊是不相同的,那麼在執行分割槽分配的時候就不是完全的輪詢分配,有可能導致分割槽分配得不均勻。
假設消費組內有3個消費者(C0、C1 和 C2),t0、t0、t1、t2主題分別有1、2、3個分割槽,即整個消費組訂閱了 t0p0、t1p0、t1p1、t2p0、t2p1、t2p2 這6個分割槽。
具體而言,消費者 C0 訂閱的是主題 t0,消費者 C1 訂閱的是主題 t0 和 t1,消費者 C2 訂閱的是主題 t0、t1 和 t2,那麼最終的分配結果為:
```
消費者C0:t0p0
消費者C1:t1p0
消費者C2:t1p1、t2p0、t2p1、t2p2
```
可以看 到 RoundRobinAssignor 策略也不是十分完美,這樣分配其實並不是最優解,因為完全可以將分割槽 t1p1 分配給消費者 C1。
**StickyAssignor分配策略**
這種分配策略,它主要有兩個目的:
1. 分割槽的分配要儘可能均勻。
2. 分割槽的分配儘可能與上次分配的保持相同。
假設消費組內有3個消費者(C0、C1 和 C2),它們都訂閱了4個主題(t0、t1、t2、t3),並且每個主題有2個分割槽。也就是說,整個消費組訂閱了 t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1 這8個分割槽。最終的分配結果如下:
```
消費者C0:t0p0、t1p1、t3p0
消費者C1:t0p1、t2p0、t3p1
消費者C2:t1p0、t2p1
```
再假設此時消費者 C1 脫離了消費組,那麼分配結果為:
```
消費者C0:t0p0、t1p1、t3p0、t2p0
消費者C2:t1p0、t2p1、t0p1、t3p1
```
StickyAssignor 分配策略如同其名稱中的“sticky”一樣,讓分配策略具備一定的“黏性”,儘可能地讓前後兩次分配相同,進而減少系統資源的損耗及其他異常情況的發生。
### 再均衡(Rebalance)
再均衡是指分割槽的所屬權從一個消費者轉移到另一消費者的行為,它為消費組具備高可用性和伸縮性提供保障,使我們可以既方便又安全地刪除消費組內的消費者或往消費組內新增消費者。
弊端:
1. 在再均衡發生期間,消費組內的消費者是無法讀取訊息的。
2. Rebalance 很慢。如果一個消費者組裡面有幾百個 Consumer 例項,Rebalance 一次要幾個小時。
3. 在進行再均衡的時候消,費者當前的狀態也會丟失。比如消費者消費完某個分割槽中的一部分訊息時還沒有來得及提交消費位移就發生了再均衡操作,之後這個分割槽又被分配給了消費組內的另一個消費者,原來被消費完的那部分訊息又被重新消費一遍,也就是發生了重複消費。
Rebalance 發生的時機有三個:
1. 組成員數量發生變化
2. 訂閱主題數量發生變化
3. 訂閱主題的分割槽數發生變化
後兩類通常是業務的變動調整所導致的,我們一般不可控制,我們主要說說因為組成員數量變化而引發的 Rebalance 該如何避免。
當 Consumer Group 完成 Rebalance 之後,每個 Consumer 例項都會定期地向 Coordinator 傳送心跳請求,表明它還存活著。如果某個 Consumer 例項不能及時地傳送這些心跳請求,Coordinator 就會認為該 Consumer 已經“死”了,從而將其從 Group 中移除,然後開啟新一輪 Rebalance。
Consumer端可以設定**session.timeout.ms**,預設是10s,表示如果 Coordinator 在 10 秒之內沒有收到 Group 下某 Consumer 例項的心跳,它就會認為這個 Consumer 例項已經掛了。
Consumer端還可以設定**heartbeat.interval.ms**,表示傳送心跳請求的頻率。
以及**max.poll.interval.ms** 引數,它限定了 Consumer 端應用程式兩次呼叫 poll 方法的最大時間間隔。它的預設值是 5 分鐘,表示你的 Consumer 程式如果在 5 分鐘之內無法消費完 poll 方法返回的訊息,那麼 Consumer 會主動發起“離開組”的請求,Coordinator 也會開啟新一輪 Rebalance。
所以知道了上面幾個引數後,我們就可以避免以下兩個問題:
1. 非必要 Rebalance 是因為未能及時傳送心跳,導致 Consumer 被“踢出”Group 而引發的。
所以我們在生產環境中可以這麼設定:
* 設定 session.timeout.ms = 6s。
* 設定 heartbeat.interval.ms = 2s。
2. 必要 Rebalance 是 Consumer 消費時間過長導致的。如何消費任務時間達到8分鐘,而max.poll.interval.ms設定為5分鐘,那麼也會發生Rebalance,所以如果有比較重的任務的話,可以適當調整這個引數。
3. Consumer 端的頻繁的 Full GC導致的長時間停頓,從而引發了 Rebalance。
### 消費者組再平衡全流程
重平衡過程是靠消費者端的心跳執行緒(Heartbeat Thread),通知到其他消費者例項的。
當協調者決定開啟新一輪重平衡後,它會將“REBALANCE_IN_PROGRESS”封裝進心跳請求的響應中,發還給消費者例項。當消費者例項發現心跳響應中包含了“REBALANCE_IN_PROGRESS”,就能立馬知道重平衡又開始了,這就是重平衡的通知機制。
所以,實際上heartbeat.interval.ms不止是設定了心跳的間隔時間,還可以控制重平衡通知的頻率。
#### 消費者組狀態機
重平衡一旦開啟,Broker 端的協調者元件就要完成整個重平衡流程,Kafka 設計了一套消費者組狀態機(State Machine)來實現。
Kafka 為消費者組定義了 5 種狀態,它們分別是:Empty、Dead、PreparingRebalance、CompletingRebalance 和 Stable。

狀態機的各個狀態流轉:

當有新成員加入或已有成員退出時,消費者組的狀態從 Stable 直接跳到 PreparingRebalance 狀態,此時,所有現存成員就必須重新申請加入組。當所有成員都退出組後,消費者組狀態變更為 Empty。Kafka 定期自動刪除過期位移的條件就是,組要處於 Empty 狀態。因此,如果你的消費者組停掉了很長時間(超過 7 天),那麼 Kafka 很可能就把該組的位移資料刪除了。
#### 組協調器(GroupCoordinator)
GroupCoordinator 是 Kafka 服務端中用於管理消費組的元件。協調器最重要的職責就是負責執行消費者再均衡的操作。
#### 消費者端重平衡流程
在消費者端,重平衡分為兩個步驟:分別是加入組和等待領導者消費者(Leader Consumer)分配方案。即JoinGroup 請求和 SyncGroup 請求。
1. 加入組
當組內成員加入組時,它會向協調器傳送 JoinGroup 請求。在該請求中,每個成員都要將自己訂閱的主題上報,這樣協調器就能收集到所有成員的訂閱資訊。
2. 選擇消費組領導者
一旦收集了全部成員的 JoinGroup 請求後,協調者會從這些成員中選擇一個擔任這個消費者組的領導者。
這裡的領導者是具體的消費者例項,它既不是副本,也不是協調器。領導者消費者的任務是收集所有成員的訂閱資訊,然後根據這些資訊,制定具體的分割槽消費分配方案。
3. 選舉分割槽分配策略
這個分割槽分配的選舉是根據消費組內的各個消費者投票來決定的。
協調器會收集各個消費者支援的所有分配策略,組成候選集 candidates。每個消費者從候選集 candidates 中找出第一個自身支援的策略,為這個策略投上一票。計算候選集中各個策略的選票數,選票數最多的策略即為當前消費組的分配策略。
如果有消費者並不支援選出的分配策略,那麼就會報出異常 IllegalArgumentException:Member does not support protocol。

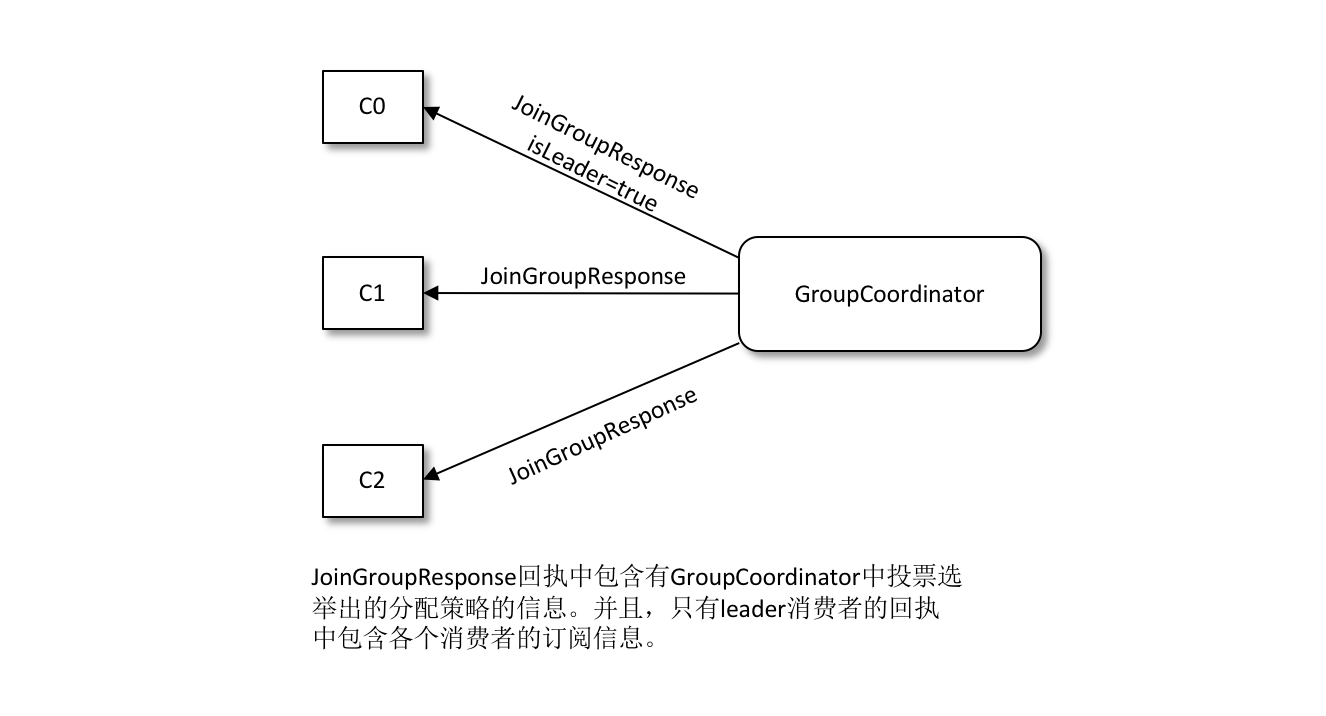
4. 傳送 SyncGroup 請求
協調器會把消費者組訂閱資訊封裝進 JoinGroup 請求的響應體中,然後發給領導者,由領導者統一做出分配方案,然後領導者傳送 SyncGroup 請求給協調器。
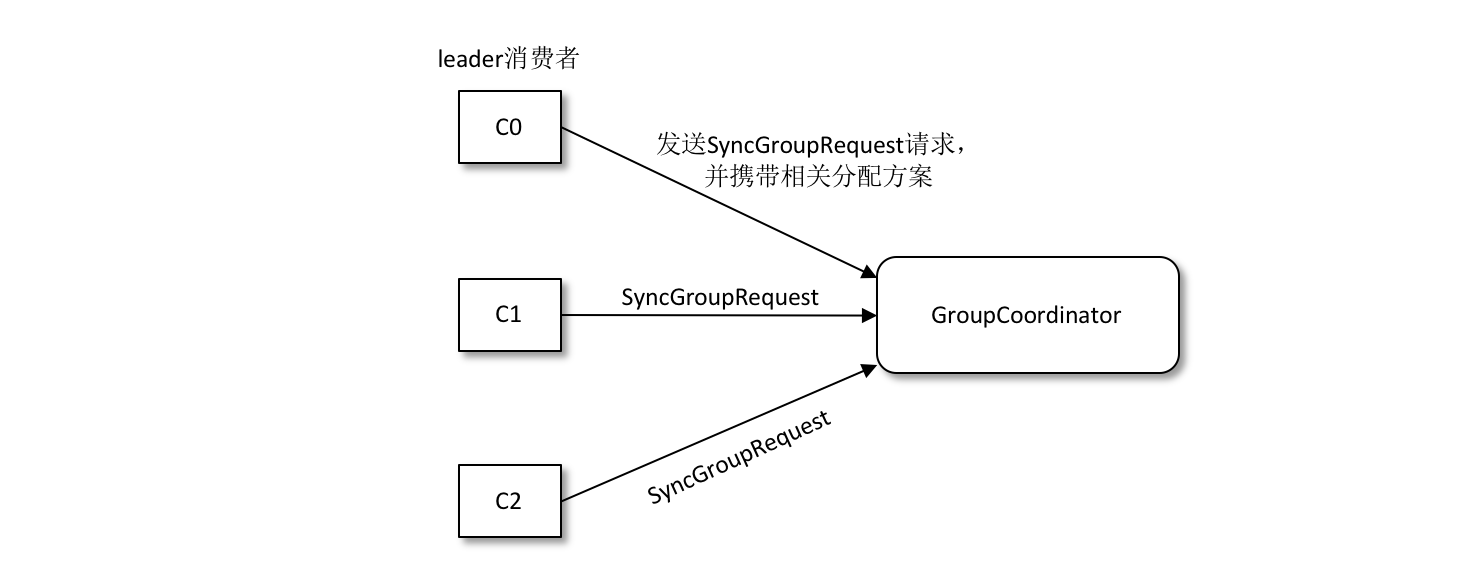
5. 響應SyncGroup
組內所有的消費者都會發送一個 SyncGroup 請求,只不過不是領導者的請求內容為空,然後就會接收到一個SyncGroup響應,接受訂閱信