
NLP(二十五)實現ALBERT+Bi-LSTM+CRF模型
阿新 • • 發佈:2020-03-13
在文章[NLP(二十四)利用ALBERT實現命名實體識別](https://blog.csdn.net/jclian91/article/details/104806598)中,筆者介紹了ALBERT+Bi-LSTM模型在命名實體識別方面的應用。
在本文中,筆者將介紹如何實現ALBERT+Bi-LSTM+CRF模型,以及在人民日報NER資料集和CLUENER資料集上的表現。
功能專案方面的介紹裡面不再多介紹,筆者只介紹模型訓練和模型預測部分的程式碼。專案方面的程式碼可以參考文章[NLP(二十四)利用ALBERT實現命名實體識別](https://blog.csdn.net/jclian91/article/details/104806598),模型為ALBERT+Bi-LSTM+CRF,結構圖如下:
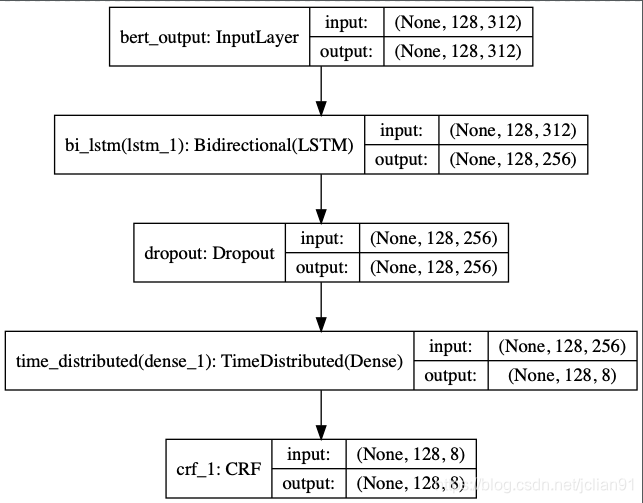
模型訓練的程式碼(albert_model_train.py)中新增匯入keras-contrib模組中的CRF層:
```python
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_accuracy, crf_viterbi_accuracy
```
模型方面的程式碼如下:
```python
# Build model
def build_model(max_para_length, n_tags):
# Bert Embeddings
bert_output = Input(shape=(max_para_length, 312, ), name="bert_output")
# LSTM model
lstm = Bidirectional(LSTM(units=128, return_sequences=True), name="bi_lstm")(bert_output)
drop = Dropout(0.1, name="dropout")(lstm)
dense = TimeDistributed(Dense(n_tags, activation="softmax"), name="time_distributed")(drop)
crf = CRF(n_tags)
out = crf(dense)
model = Model(inputs=bert_output, outputs=out)
# model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.compile(loss=crf.loss_function, optimizer='adam', metrics=[crf.accuracy])
# 模型結構總結
model.summary()
plot_model(model, to_file="albert_bi_lstm.png", show_shapes=True)
return model
```
設定文字的最大長度MAX_SEQ_LEN = 128,訓練10個epoch,在測試集上的F1值(利用seqeval模組評估)輸出如下:
```
precision recall f1-score support
LOC 0.9766 0.9032 0.9385 3658
ORG 0.9700 0.9465 0.9581 2185
PER 0.9880 0.9721 0.9800 1864
micro avg 0.9775 0.9321 0.9543 7707
macro avg 0.9775 0.9321 0.9541 7707
```
之前用ALBERT+Bi-LSTM模型得到的F1值為91.96%,而ALBERT+Bi-LSTM+CRF模型能達到95.43%,提升效果不錯。
模型預測程式碼(model_predict.py)如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-11 13:16
import json
import numpy as np
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_accuracy, crf_viterbi_accuracy
from keras.models import load_model
from collections import defaultdict
from pprint import pprint
from utils import MAX_SEQ_LEN, event_type
from albert_zh.extract_feature import BertVector
# 讀取label2id字典
with open("%s_label2id.json" % event_type, "r", encoding="utf-8") as h:
label_id_dict = json.loads(h.read())
id_label_dict = {v: k for k, v in label_id_dict.items()}
# 利用ALBERT提取文字特徵
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=MAX_SEQ_LEN)
f = lambda text: bert_model.encode([text])["encodes"][0]
# 載入模型
custom_objects = {'CRF': CRF, 'crf_loss': crf_loss, 'crf_viterbi_accuracy': crf_viterbi_accuracy}
ner_model = load_model("%s_ner.h5" % event_type, custom_objects=custom_objects)
# 從預測的標籤列表中獲取實體
def get_entity(sent, tags_list):
entity_dict = defaultdict(list)
i = 0
for char, tag in zip(sent, tags_list):
if 'B-' in tag:
entity = char
j = i+1
entity_type = tag.split('-')[-1]
while j < min(len(sent), len(tags_list)) and 'I-%s' % entity_type in tags_list[j]:
entity += sent[j]
j += 1
entity_dict[entity_type].append(entity)
i += 1
return dict(entity_dict)
# 輸入句子,進行預測
while 1:
# 輸入句子
text = input("Please enter an sentence: ").replace(' ', '')
# 利用訓練好的模型進行預測
train_x = np.array([f(text)])
y = np.argmax(ner_model.predict(train_x), axis=2)
y = [id_label_dict[_] for _ in y[0] if _]
# 輸出預測結果
pprint(get_entity(text, y))
```
在網上找幾條新聞,預測結果如下:
```
Please enter an sentence: 驢媽媽旅遊網創始人洪清華近日接受媒體採訪談及驢媽媽的發展模式時表示:現在,電商有兩種做法——小而美的電商追求盈利,大而全的電商鍾情規模。
{'PER': ['洪清華']}
Please enter an sentence: EF英孚教育集團是全球最大的私人英語教育機構,主要致力於英語培訓、留學旅遊以及英語文化交流等方面。
{'ORG': ['EF英孚教育集團']}
Please enter an sentence: 宋元時期起,在臺灣早期開發的過程中,中華文化傳統已隨著大陸墾民傳入臺灣。
{'LOC': ['臺灣', '中華', '臺灣']}
Please enter an sentence: 吸引了眾多投資者來津發展,康師傅紅燒牛肉麵就是於1992年在天津誕生。
{'LOC': ['天津']}
Please enter an sentence: 經過激烈角逐,那英戰隊成功晉級16強的學員有實力非凡的姚貝娜、摯情感打動觀眾的朱克、音樂創作能力十分突出的侯磊。
{'PER': ['姚貝娜', '朱克', '侯磊']}
```
接下來我們看看該模型在CLUENER資料集上的表現。CLUENER資料集是在清華大學開源的文字分類資料集THUCTC基礎上,選出部分資料進行細粒度命名實體標註,原資料來源於Sina News RSS,實體有:地址(address),書名(book),公司(company),遊戲(game),政府(goverment),電影(movie),姓名(name),組織機構(organization),職位(position),景點(scene),該資料集的介紹網站為:[https://www.cluebenchmarks.com/introduce.html](https://www.cluebenchmarks.com/introduce.html) 。
下載資料集,用指令碼將其處理成模型支援的資料格式,因為缺少test資料集,故模型評測的時候用dev資料集代替。設定模型的文字最大長度MAX_SEQ_LEN = 128,訓練10個epoch,在測試集上的F1值(利用seqeval模組評估)輸出如下:
```
sentences length: 10748
last sentence: 藝術家也討厭畫廊的老闆,內心恨他們,這樣的話,你是在這樣的狀態下,兩年都是一次性合作,甚至兩年、
start ALBERT encding
end ALBERT encoding
sentences length: 1343
last sentence: 另外義大利的PlayGeneration雜誌也剛剛給出了92%的高分。
start ALBERT encding
end ALBERT encoding
sentences length: 1343
last sentence: 另外義大利的PlayGeneration雜誌也剛剛給出了92%的高分。
start ALBERT encding
end ALBERT encoding
......
.......
precision recall f1-score support
book 0.9343 0.8421 0.8858 152
position 0.9549 0.8965 0.9248 425
government 0.9372 0.9180 0.9275 244
game 0.6968 0.6725 0.6844 287
organization 0.8836 0.8605 0.8719 344
company 0.8659 0.7760 0.8184 366
address 0.8394 0.8187 0.8289 364
movie 0.9217 0.7067 0.8000 150
name 0.8771 0.8071 0.8406 451
scene 0.9939 0.8191 0.8981 199
micro avg 0.8817 0.8172 0.8482 2982
macro avg 0.8835 0.8172 0.8482 2982
```
在網上找幾條新聞,預測結果如下:
```
Please enter an sentence: 據中山外僑局訊息,近日,祕魯國會議員、祖籍中山市開發區的瑪利亞·洪大女士在祕魯國會大廈親切會見了中山市人民政府副市長馮煜榮一行,對中山市友好代表團的來訪表示熱烈的歡迎。
{'address': ['中山市開發區', '祕魯國會大廈'],
'government': ['中山外僑局', '祕魯國會', '中山市人民政府'],
'name': ['瑪利亞·洪大', '馮煜榮'],
'position': ['議員', '副市長']}
Please enter an sentence: “隔離結束回來,發現公司不見了”,網上的段子,真發生在了崑山達鑫電子有限公司員工身上。
{'company': ['崑山達鑫電子有限公司']}
Please enter an sentence: 由黃子韜、易烊千璽、胡冰卿、王子騰等一眾青年演員主演的熱血勵志劇《熱血同行》正在熱播中。
{'game': ['《熱血同行》'], 'name': ['黃子韜', '易烊千璽', '胡冰卿', '王子騰'], 'position': ['演員']}
Please enter an sentence: 近日,由作家出版社主辦的韓作榮《天生我才——李白傳》新書釋出會在京舉行
{'book': ['《天生我才——李白傳》'], 'name': ['韓作榮'], 'organization': ['作家出版社']}
```
本專案已經開源,Github網址為:[https://github.com/percent4/ALBERT_NER_KERAS](https://github.com/percent4/ALBERT_NER_KERAS) 。
本文到此結束,感謝大家閱讀,歡迎關注筆者的微信公眾號:Python爬蟲與