
mysql那些事之索引篇
阿新 • • 發佈:2020-03-19
### mysql那些事之索引篇
上一篇部落格已經簡單從廣的方面介紹了一下mysql整體架構以及物理結構的內容.
本篇部落格的內容是mysql的索引,索引無論是在面試還是我們日常工作中都是非常的重要一環.
#### 索引是什麼?
- 官方介紹索引是幫助MySQL高效獲取資料的資料結構.打個比方來說的話相當於我們生活中字典.
#### 索引的優勢和劣勢
- 優勢:
- 可以加快資料的檢索速度,降低磁碟的IO,提高查詢效率.
- 索引列可以對資料進行排序,減低cpu的消耗
- 劣勢:
- 索引是需要佔用磁碟空間的.
- 索引只是針對查詢會提升效能.對增刪改反而會降低.原因是因為要維護索引,會產生磁碟IO.
#### 索引的分類
- 單列索引
- 普通索引:mysql中的基本索引型別,只是為了查詢快一些.
- 主鍵索引:mysql主鍵列上新增索引.不允許有null和空值
- 唯一索引:唯一列上新增索引,允許有null和空值
- 組合索引
- 在同一張表裡多個列上新增索引
- 需要遵循最左字首原則
- 建議使用組合索引替代單列索引,主鍵索引分情況.
#### 索引的使用
##### 索引的建立
首先說明我們有一張user表,欄位分別為主鍵id,name,age.
- 單列普通索引
``` sql
create index idx_name on user(name(10));
```
這裡想說明一下,我們在工作中對某個欄位新增索引時,目標欄位由於是varchar型別,可能比較長,為了更好的維護索引和減少索引佔用磁碟空間的大小,我們可以在列後面加上索引的長度.
- 唯一索引
``` sql
create unique index idx_id on user(id);
```
主鍵索引是唯一索引的特殊型別,建議主鍵索引使用整數,整數佔用空間比較小.同樣可以為索引指定長度,如果是int型別就不需要指定了.
- 組合索引
``` sql
create index idx_id_name_age on user(id,name(10),age);
```
- 最左字首原則:
- 說明一點我們建立了以上組合索引的時候,相當於建立了是三個索引:
- id,name,age
- id,name
- id
``` sql
select * from user where age = 13 and id =1 and name = 'VN';
```
此時是否使用到了組合索引?
這種情況下是違反了最左字首原則,由於我們建立的索引的順序是id,name,age.我們在使用組合索引的時候應該也要遵循這個順序,如果打亂順序那麼就會導致索引失效.正確使用組合索引應該是以下sql語句:
``` sql
select * from user where id = 1 and name = 'VN' and age = 13;
```
還有以下情況,是否使用到了索引.
``` sql
select * from user where id =1 and name = 'VN';
```
``` sql
select * from user where id =1;
```
以上兩條sql語句是正確使用了索引的,因為組合索引也可以拆開使用,但一定是有順序的,不能打亂,從打亂索引順序的時候開始,往後的索引就是失效了.
###### 切記:如果索引順序是以上情況,直接拿name,或者age來用,索引是失效的.因為違背的最左字首原則,即使把組合索引拆開來用,也一定是有序的.
#### 刪除索引
``` sql
drop index idx_id_name_age on user;
```
#### 檢視索引
``` sql
show index from user \G;
```
*****
#### 索引的資料結構
在開始具體說索引的資料結構前,要說明一下,因為索引是mysql引擎中實現的,所以不同的儲存引擎有不同的實現.由於現在mysql中InnoDB是預設的資料庫引擎,並且我們大部分場景下使用的也是InnoDB引擎,所以在索引的資料結構這裡,我們只針對於InnoDB引擎來說.
索引的資料結構是什麼,相信我們大家都知道是B+tree,可具體什麼是B+TREE呢?B+TREE長什麼樣子呢?B-TREE和B+TREE的區別是什麼?這些問題大家就不一定都能回答上來了吧?
##### B-tree:(也叫做多路平衡樹)

##### B+TREE:
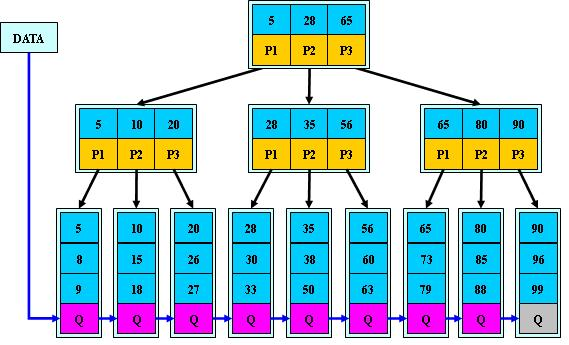
以上兩種是b-tree和B+tree的樣子
###### b+tree在MyISAM的實現:

MyISAM非聚集索引.非葉子節點只存放著指向具體的資料的地址值.
###### b+tree在InnoDB的實現:

InnoDB聚集索引,非葉子節點存放有具體的資料.
###### b-tree和b+tree的區別
- b-tree葉子節點也是存放資料的,而b+tree只有非葉子節點存放資料,葉子節點存放的都是指向下一個節點的指標.
- b+tree非葉子節點使用連結串列結構相鄰的兩個非葉子節點相連.
#### 索引失效
在說索引失效之前,不得不先說一下explain檢視執行計劃.
##### 執行計劃
MySQL 提供了一個 EXPLAIN 命令, 它可以對 SELECT 語句的執行計劃進行分析, 並輸出 SELECT 執行的
詳細資訊, 以供開發人員針對性優化.
使用explain這個命令來檢視一個這些SQL語句的執行計劃,檢視該SQL語句有沒有使用上了索引,有沒
有做全表掃描,這都可以通過explain命令來檢視。
可以通過explain命令深入瞭解MySQL的基於開銷的優化器,還可以獲得很多可能被優化器考慮到的訪
問策略的細節,以及當執行SQL語句時哪種策略預計會被優化器採用。
用法如下:
.jpg)
其中各列的含義如下:
- id:select查詢的識別符號,每一個select有一個唯一的識別符號.標識查詢的執行順序.
- id相同,執行順序從上往下
- id不同,如果是子查詢,id越大,優先順序越高
- select_type:select查詢的型別.
- simple:簡單的select查詢
- parmary:一個union或者子查詢的操作,最外層的就是parmary
- union:連線的兩個都是查詢,第一個是派生表dervied,往後的都是union
- dependent union:出現在連線查詢中,受外部查詢影響
- subquery:除了from中的子查詢,其他地方的子查詢
- derived:from中出現的子查詢,和之前提到的一樣派生表
- table:查詢的那張表.
- 如果使用了別名,這裡顯示別名
- 如果出現了尖括號,那說明是臨時表
- 如果不涉及表的操作,這裡顯示為null
- partitions:匹配的分割槽.
- type:連線型別
**效能從好到差排序**
- system:只有一行資料或者是空表
- const:使用唯一索引或者主鍵
- eq_ref:出現在多表關聯查詢,對於前表的每一個結果抖只能匹配到一條結果
- ref:非唯一索引,使用了組合索引符合最左字首
- fulltext:全文索引檢索
- ref_or_null:ref類似
- unique_subquery:where中的in的子查詢
- index_subquery:子查詢in形式子查詢使用到了輔助索引
- range:索引範圍掃描
- index_merge:使用了兩個以上的索引
- index:結果列中使用到了索引
- index
- ALL:全表掃描
- 只有all沒有使用到索引,其他都使用到了索引
- 建議使用到range級別
- possible_keys: 此次查詢中可能選用的索引
- key: 此次查詢中確切使用到的索引.
- ref: 哪個欄位或常數與 key 一起被使用
- rows: 顯示此查詢一共掃描了多少行. 這個是一個估計值.
- filtered: 表示此查詢條件所過濾的資料的百分比
- extra: 額外的資訊
- using index:索引覆蓋,不需要回表掃描
- using where:對storage engine提取的結果進行過濾,改欄位沒有索引
- using filesort:排序中沒有使用到索引
- using temporary:使用了臨時表存結果
#### 索引下推
大家都知道mysql架構分為了server層和引擎層.索引下推也叫做ICP.
##### 如何處理where條件
- index_key:確定索引中的連續範圍,根據索引來確定範圍
- index_filter:index_key確定了索引範圍之後,還有一部分不符合條件,通過index_filter篩選
- table_filter:索引不能過濾的交給table_filter,也就是回表過濾
**torage層**:
首先將index key條件滿足的索引記錄區間確定,然後在索引上使用index filter進行過濾
將滿足的index filter條件的索引記錄才去回表取出整行記錄返回server層
不滿足index filter條件的索引記錄丟棄,不回表、也不會返回server層
**server 層**:
對返回的資料,使用table filter條件做最後的過濾。
.jpg)
使用ICP的好處:
- 直接去掉了不滿足index_filter的記錄,避免了回表和傳到server層
#### 索引失效
- 違反了最左字首原則會導致索引失效
- 索引上不要做計算,會導致索引失效
- 範圍條件右邊的列索引失效
- 索引欄位不要使用不等,會導致索引失效
- 索引欄位使用is null或者not null會導致索引失效
- 索引欄位使用or會導致索引失效
關於索引的資料結構推薦大家一片博文,講解的會更全面,本篇部落格中一部分圖片取自於該部落格.
地址是:https://www.cnblogs.com/aligege/p/11589398.html
> 下一篇:mysql那些事之鎖