
我的Keras使用總結(1)——Keras概述與常見問題整理
今天整理了自己所寫的關於Keras的部落格,有沒釋出的,有釋出的,但是整體來說是有點亂的。上週有空,認真看了一週Keras的中文文件,稍有心得,整理於此。這裡附上Keras官網地址:
Keras英文文件:https://keras.io/#installationKeras
Keras中文文件:https://keras.io/zh/
下面回顧一下自己以前寫的有關Keras的部落格:
Python機器學習筆記:利用Keras進行分類預測
Python機器學習筆記:使用Keras進行迴歸預測
首先是上面兩篇部落格,這兩篇寫出來,其實是整理筆記,單純的學習一下基礎的迴歸和分類,使用Keras建立一個簡單的迴歸問題的神經網路模型和多類分類的模型。使用了最經典的迴歸資料波士頓房價資料集和分類資料鳶尾花資料集。建立一個簡單的模型進行訓練。其重點是學習基礎的分類迴歸思想,順便使用別人的Keras程式碼進行實現。
深入學習Keras中Sequential模型及方法
其次是這篇部落格,當時學習Keras的時候對序貫模型不懂,就做了一個簡單的筆記對此進行整理。主要整理了序貫模型的函式及其引數的意義,包括使用Keras進行模型訓練的部分簡單的過程,最後整理了Keras官網文件的幾個例子。此時也只是對Keras有個大概的瞭解。
Keras深度學習之卷積神經網路(CNN)
然後上面這篇部落格還是學習卷積神經網路,為什麼上面這篇部落格起這個一個怪異的名字呢,我當時知道自己不太懂,所以我希望自己懂了後回顧一下。而且這篇文章我沒有釋出,我將其從隨筆改為文章,就是說是自己摘抄的筆記,希望懂後,回首一下,也算是做了個交代。
這篇雜文主要是以學習卷積神經網路為主,回顧了典型的CNN,常用的CNN框架,和Keras如何實現CNN等。主要實現了兩件事情,一個是使用Keras搭建了一個卷積神經網路,一個是學習了卷積神經網路實現的過程。內容以摘抄為主,但是摘抄的確實是好文,講解細膩,循序漸進,值得去看。
Python機器學習筆記:深入理解Keras中序貫模型和函式模型
然後就是這篇部落格了,我是先學習的sklearn,然後再學習的tensorflow,Keras。所以對照著sklearn的機器學習流程學習Keras的使用流程。然後對序貫模型和函式模型進行詳細學習和對比,最後整理了Keras如何儲存模型。相對來說我的思路還是比較清晰了。會使用Keras搭建模型了。
那麼說完了這麼多,為什麼還要寫呢?
其實從18年九月開始,自己的機器學習之路就開始了,當時前途一片迷茫,學到哪裡算哪裡。到19年一月又寫了幾篇部落格,當然後面也寫了只是沒有釋出而已,到現在已經是20年三月了。囉嗦這麼多,就是感覺自己走了彎路,讓看到部落格的人能少走點彎路,而且最主要的是自己整理回顧。
首先說起Keras,都知道它是基於Theano和TensorFlow的深度學習庫,所以這裡我們先說一說TensorFlow,上面聊過,我是先學習sklearn,再學習的TensorFlow的。通過對比sklearn的訓練過程,學習Keras的訓練過程。其實大同小異,那麼同在哪裡,異又在哪裡?
上面部落格只是簡單的學習了一下其兩者的機器學習使用流程和區別,這裡從根上回顧一下機器學習和深度學習的區別。這裡內容我就不寫自己的拙見了,直接拿網友現成的東西(https://www.zhihu.com/question/53740695/answer/284428668)
1,機器學習和深度學習的總結
首先我們看sklearn和TensorFlow的區別。 這個問題其實等價於:現在深度學習那麼火,那麼是否還有必要學習傳統的機器學習方法。
理論上來說,深度學習技術也是機器學習的一個組成部分,學習其他傳統的機器學習方法對深入理解深度學習技術有很大的幫助,知道模型凸的條件,才能更好的理解神經網路的非凸,知道傳統模型的優點,才能更好的理解深度學習並不是萬能的,也有很多問題和場景直接使用深度學習方法會遇到瓶頸和問題,需要傳統方法來解決。
從實踐上來說,深度學習方法一般需要大量的GPU機器,工業界哪怕大公司的GPU資源也是有限的,一般只有深度學習方法效果遠好於傳統方法並且對業務提升很大的情況下,才會考慮使用深度學習方法,例如語音識別,影象識別等任務現在深度學習方法用的比較多,而NPL領域除了機器翻譯以外,其他大部分任務仍然更常使用傳統方法,傳統方法一般有著更好的可解釋性,這對檢查除錯模型也是非常有幫助的。工業上一般喜歡招能解決問題的人,而不是掌握最火技術的人,因此在瞭解深度學習技術的同時,學習一下傳統的方法是很有好處的。
1.1 Sklearn和TensorFlow的區別
Scikit-learn(Sklearn)的定位是通過機器學習庫,而TensorFlow(tf)的定位主要是深度學習庫。一個顯而易見的不同:tf並未提供sklearn那種強大的特徵工程,如維度壓縮,特徵選擇等。
傳統機器學習:利用特徵工程(feature enginerring),人為對資料進行提煉清洗
深度學習:利用表示學習(representation learning),機器學習模型自身對資料進行提煉
sklearn更傾向於使用者可以自行對資料進行處理,比如選擇特徵,壓縮維度,轉換格式,是傳統機器學庫,而以tf為代表的深度學習庫會自動從資料中抽取有效特徵,而不需要人為的來做這件事情,因此並未提供類似的功能。
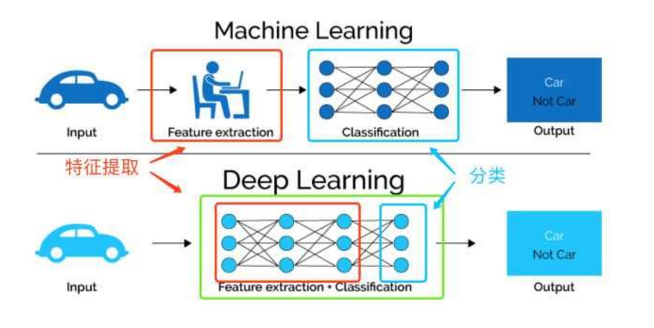
上面這幅圖直觀的對比了我們提到的兩種對於資料的學習方法,傳統的機器學習方法主要依賴人工特徵處理與提取,而深度學習依賴模型自身去學習資料的表示。
1.2 模型封裝的抽象化程度不同,給予使用者自由度不同
sklearn中的模組都是高度抽象化,所有的分類器基本都可以在3~5行內完成,所有的轉換器(如scaler和transformer)也有固定的格式,這種抽象化限制了使用者的自由度,但是增加了模型的效率,降低了批量化,標準化的難度。
比如svm分類器:
clf = svm.SVC() # 初始化一個分類器 clf.fit(X_train, y_train) # 訓練分類器 y_predict = clf.predict(X_test) # 使用訓練好的分類器進行預測
而tf不同,雖然是深度學習庫,但是它由很高的自由度。你依然可以使用它做傳統機器學習所做的事情,程式碼是你需要自己實現演算法。因此用tf類比sklearn不適合,封裝在tf等工具庫的Keras更像深度學習界的sklearn。
從自由度來看,tf更高;而從抽象化,封裝程度來看,sklearn更高;從易用性角度來看,sklearn更高。
1.3 深度的群體,專案不同
sklearn主要適合中小型的,實用機器學習專案,尤其是那種資料量不大且需要使用者手動對資料進行處理,並選擇合適模型的專案,這類專案往往在CPU上就可以完成,對硬體要求低。
tf主要適合已經明確瞭解需要用深度學習,且資料處理需求不高的專案。這類專案往往資料量較大,且最終需要的精度更高,一般都需要GPU加速運算。對於深度學習做“小樣”可以在取樣的小資料集上用Keras做快速的實驗。
下面我們看一個使用Keras搭建的網路,程式碼如下:
model = Sequential() # 定義模型
model.add(Dense(units=64, activation='relu', input_dim=100)) # 定義網路結構
model.add(Dense(units=10, activation='softmax')) # 定義網路結構
model.compile(loss='categorical_crossentropy', # 定義loss函式、優化方法、評估標準
optimizer='sgd',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=32) # 訓練模型
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128) # 評估模型
classes = model.predict(x_test, batch_size=128) # 使用訓練好的資料進行預測
不難看出,sklearn和tf還是有很大的區別,雖然sklearn中也有神經網路模組,但是做大型的深度學習是不可能依靠sklearn的。
1.4 sklearn和TensorFlow結合使用
更常見的情況,可以把sklearn和tf,甚至Keras結合起來使用。sklearn肩負基本的資料清理任務,Keras用於對問題進行小規模試驗驗證想法,而tf用於在完整的資料上進行嚴肅的調參任務。
而單獨把sklearn拿出來看的話,它的文件做的特別好,初學者跟著看一遍sklearn支援的功能就可以大概對機器學習包括的很多內容有了基本的瞭解。舉個簡單的例子,sklearn很多時候對單獨的知識點有概述,比如簡單的異常檢測。因此,sklearn不僅僅是簡單的工具庫,它的文件更像是一份簡單的新手入門指南。
因此,以sklearn為代表的傳統機器學習庫和以tf為代表的自由靈活更具有針對性的深度學習庫都是機器學習者必須要了解的工具。
那麼如何結合sklearn庫和Keras模型做機器學習任務呢?
Keras是Python中比較流行的深度學習庫,但是Keras本身關注的是深度學習。而Python中的scikit-learn庫是建立在Scipy上的,有著比較有效的數值計算能力。Sklearn是一個具有全特徵的通用性機器學習庫,它提供了很多在深度學習中可以用到的工具,舉個例子:
- 1,可以用sklearn中的 K-fold 交叉驗證方法來對模型進行評估
- 2,模型引數的評估和尋找
Keras提供了深度學習模型的簡便包裝,可以在Sklearn中被用來做分類和迴歸,在本文中我們舉這麼一個例子:使用Keras建立神經網路分類器——KerasClassifier,並在scikit-learn庫中使用這個分類器對UCI的Pima Indians資料集進行分類。
利用Keras進行分類或者回歸,主要利用Keras中兩個類,一個是KerasClassifier,另一個是KerasRegressor。這兩個類有引數build_fn。build_fn是你建立的Keras名稱,在建立一個Keras模型時,務必要把完成模型的定義,編譯和返回。在這裡我們假設建立的模型叫做create_model(),則:
def create_model():
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, init='uniform', activation='relu'))
model.add(Dense(8, init='uniform', activation='relu'))
model.add(Dense(1, init='uniform', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
將建立好的模型通過引數build_fn傳遞到KerasClassifier中,並且定義其他的引數選項nb_epoch = 150,batch_size = 10 。KerasClassifier會自動呼叫fit方法。
在Sklearn中,我們使用它cross_validation的包中的StratifiedKFold來進行10折交叉驗證,使用cross_val_score來對模型進行評價。
kfold = StratifiedKFold(y=Y, n_folds=10, shuffle=True, random_state=seed) results = cross_val_score(model, X, Y, cv=kfold)
總結來說,機器學習和深度學習均需要學習,只會呼叫工具包的程式設計師不是好的機器學習者。
扯了這麼多,我們明白sklearn和keras結合使用,相得益彰。
2,Keras的概述
而我之前的筆記主要的針對點就是序貫模型和卷積神經網路這塊,那今天我們不學習這些東西。從架構上整體的瞭解一下Keras。
Keras是Python中一個以CNTK、TensorFlow或者Theano為計算後臺的深度學習建模環境。相對於常見的幾種深度學習計算軟體,比如TensorFlow、Theano、Caffe、CNTK、Torch等,Keras在實際應用中有如下幾個顯著的優點。Keras在設計時以人為本,強調快速建模,使用者能快速地將所需模型的結構對映到Keras程式碼中,儘可能減少編寫程式碼的工作量,特別是對於成熟的模型型別,從而加快開發速度。支援現有的常見結構,比如卷積神經網路、時間遞迴神經網路等,足以應對大量的常見應用場景。高度模組化,使用者幾乎能夠任意組合各個模組來構造所需的模型。
在Keras中,任何神經網路模型都可以被描述為一個圖模型或者序列模型,其中的部件被劃分為以下模組:神經網路層、損失函式、啟用函式、初始化方法、正則化方法、優化引擎。這些模組可以以任意合理地方式放入圖模型或者序列模型中來構造所需的模型,使用者並不需要知道每個模組後面的細節。這種方式相比其他軟體需要使用者編寫大量程式碼或者用特定語言來描述神經網路結構的方法效率高很多,也不容易出錯。基於Python,使用者也可以使用Python程式碼來描述模型,因此易用性、可擴充套件性都非常高。使用者可以非常容易地編寫自己的定製模組,或者對已有模組進行修改或者擴充套件,因此可以非常方便地開發和應用新的模型與方法,加快迭代速度。能在CPU和GPU之間無縫切換,適用於不同的應用環境。當然,我們強烈推薦GPU環境。
首先這個思維導圖是對Keras中文文件的整體概述,也可以叫做目錄:
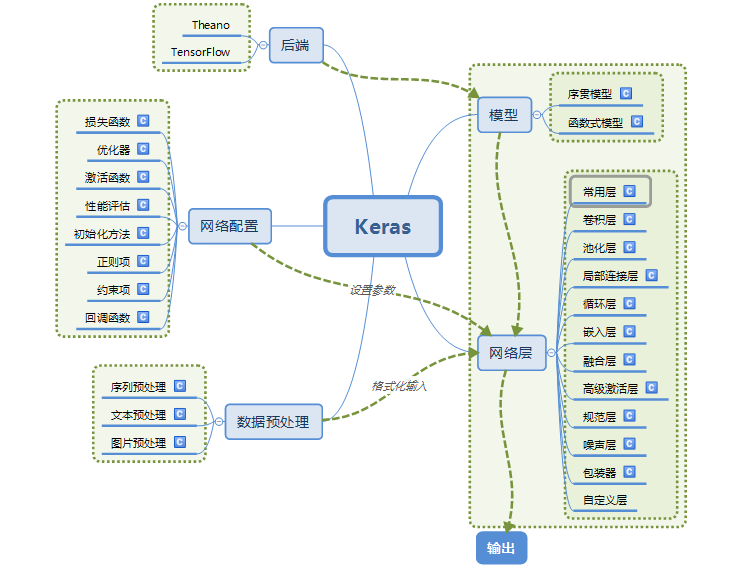
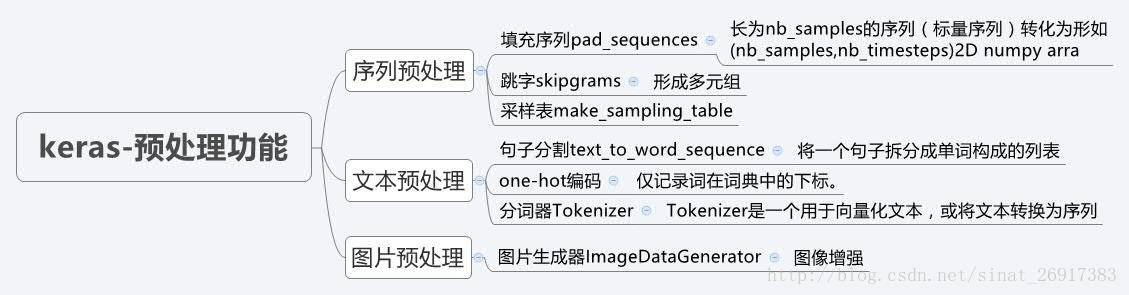
上面從上面導圖我們可以直觀的看到Keras官網文件主要分為五個方面寫:模型,後端,網路層,網路配置,資料預處理。模型分為序貫模型和函式式模型,我們之前學習過就不贅述了;下面利用三個思維導圖展示一下網路配置,網路層,資料預處理。(原圖地址:https://blog.csdn.net/sinat_26917383/article/details/72857454?locationNum=1&fps=1)


注意:回撥函式 callbacks應該是Keras的精髓。。
3,一個簡單的Keras訓練模型過程
使用Keras訓練模型的步驟圖示如下:
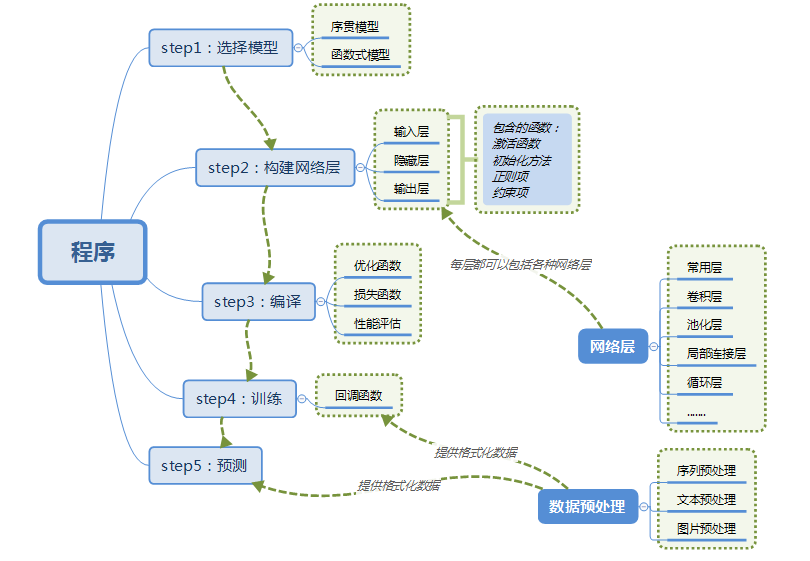
Keras的核心資料結構是model,一種組織網路層的方式,最簡單的模型是Sequential順序模型,它由多個網路層線性堆疊。對於更復雜的結構,你應該使用Keras函式式API,它允許構建任意的神經網路圖。
3.1,選擇模型
Sequential順序模型如下所示:
from keras.models import Sequential model = Sequential()
3.2,構建網路層
可以簡單地使用.add()來堆疊模型:
from keras.layers import Dense model.add(Dense(units=64, activation='relu', input_dim=100)) model.add(Dense(units=10, activation='softmax'))
3.3,編譯
在完成了模型的構建後,可以使用.compile()來配置學習過程。編譯模型時必須指明損失函式和優化器,如果有需要的話也可以自己定製損失函式。
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
如果需要,我們還可以進一步的配置我們的優化器,Keras的核心原則是使事情變得相當簡單,同時又允許使用者在需要的時候能夠進行完全的控制(終控的控制是原始碼的易擴充套件性)。
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True))
3.4 訓練
現在我們可以批量的在訓練資料上進行迭代了:
# x_train 和 y_train 是 Numpy 陣列 -- 就像在 Scikit-Learn API 中一樣。 model.fit(x_train, y_train, epochs=5, batch_size=32)
或者,你可以手動地將批次的資料提供給模型:
model.train_on_batch(x_batch, y_batch)
只需一行程式碼就能評估模型效能:
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)
3.5 預測
或者對新的資料生成預測:
classes = model.predict(x_test, batch_size=128)
構建一個問答系統,一個圖形分類模型,一個神經圖靈機,或者其他的任何模型,就是這麼的快。我們利用一個小的程式碼展示了一個Keras完整的訓練過程,後面就不再贅述了。
4,一些Keras中常見的問題
4.1 為什麼訓練誤差比測試誤差高很多?
一個Keras的模型有兩個模式:訓練模式和測試模式。一些正則機制,如Dropout,L1/L2正則項在測試模式下將不被啟用。
另外,訓練誤差是訓練資料每個batch的誤差的平均。在訓練過程中,每個 epoch 起始時的batch的誤差要大一些,而後面的batch的誤差要小一些。另一方面,每個 epoch 結束時計算的測試誤差是由模型在 epoch結束時的狀態決定的,這時候的網路將產生較小的誤差。
Tips:可以通過定義回撥函式將每個 epoch的訓練誤差和測試誤差並作圖,如果訓練誤差曲線和測試誤差曲線之間有很大的空隙,說明你的模型可能有過擬合的問題。當然,這個問題與Keras無關。
4.2 在Theano和TensorFlow中如何表示一組彩色圖片的尺寸?
Keras提供了兩套後端,Theano和TensorFlow,這是一件幸福的事,就像手裡拿著麵包,想蘸紅糖蘸紅糖,想蘸白糖蘸白糖。如果你從無到有搭建自己的一套網路,則大可放心。但是如果你想使用一個已有的網路,或把一個用 th/tf 訓練的網路以另一種後端應用,在載入的時候你就應該特別小心了。
Theano和TensorFlow在表示一組彩色圖片的問題上有分歧,“th”模式,也就是Theano模式會把100張 RGB 三通道的16*32(高為16 寬為32)彩色圖表示為下面這張形式(100, 3, 16, 32),Caffe採取的也是這種形式。第0個維度為樣本維,代表樣本的樹木,第一個維度是通道維,代表顏色通道數。後面兩個就是高和寬了。這張Theano 風格的資料組織方式,稱為“channels_first”, 即通道維靠前。
而TensorFlow 的表達形式(100, 16, 32,3),即把通道維放在了最後,這張資料組織形式稱為“channels_last”。
注意:卷積核與所使用的後端不匹配,不會報任何錯誤,因為他們的shape是完全一致的,沒有辦法能夠檢測出這種錯誤。所以在使用預訓練模型的時候,一個建議是首先找一些測試樣本,看看模型的表現是否與預計的一致,如需對卷積核進行轉換,可以使用 utils.convert_call_kernels_in_model 對模型的所有卷積核進行轉換。
4.3,模型的節點資訊提取
# 節點資訊提取 config = model.get_config() # 把model中的資訊,solver.prototxt和train.prototxt資訊提取出來 model = Model.from_config(config) # 還回去 # or, for Sequential: model = Sequential.from_config(config) # 重構一個新的Model模型,用去其他訓練,fine-tuning比較好用
4.4 模型概況查詢(包括權重查詢)
# 1、模型概括列印 model.summary() # 2、返回代表模型的JSON字串,僅包含網路結構,不包含權值。可以從JSON字串中重構原模型: from models import model_from_json json_string = model.to_json() model = model_from_json(json_string) # 3、model.to_yaml:與model.to_json類似,同樣可以從產生的YAML字串中重構模型 from models import model_from_yaml yaml_string = model.to_yaml() model = model_from_yaml(yaml_string) # 4、權重獲取 model.get_layer() #依據層名或下標獲得層物件 model.get_weights() #返回模型權重張量的列表,型別為numpy array model.set_weights() #從numpy array裡將權過載入給模型,要求陣列具有與model.get_weights()相同的形狀。 # 檢視model中Layer的資訊 model.layers 檢視layer資訊
4.5 當驗證集的 loss 不再下降時,如何中斷訓練?
可以定義 EarlyStopping 來提前終止訓練。
from keras.callbacks import EarlyStopping early_stopping = EarlyStopping(monitor='val_loss', patience=2) model.fit(X, y, validation_split=0.2, callbacks=[early_stopping])
可以參考 官網:回撥函式
4.6 如何在每個 epoch後記錄訓練/測試的loss和正確率?
model.fit 在執行結束後返回一個 History 物件,其中含有的 history 屬性包含了訓練過程中損失函式的值以及其他度量指標。
hist = model.fit(X, y, validation_split=0.2) print(hist.history)
4.7 如何在keras中設定GPU使用的大小
如果採用TensorFlow作為後端,當機器上有可用的GPU時,程式碼會自動呼叫GPU進行平行計算,但是在使用keras時候會出現總是佔滿GPU視訊記憶體的情況,可以通過重設backend的GPU佔用情況來進行調節。
import tensorflow as tf from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 set_session(tf.Session(config=config))
需要注意的是,雖然程式碼或配置層面設定了對視訊記憶體佔用百分比閾值,但在實際執行中如果達到了這個閾值,程式有需要的話還是會突破這個閾值。換而言之如果跑在一個大資料集上還是會用到更多的視訊記憶體。以上的視訊記憶體限制僅僅為了在跑小資料集時避免對視訊記憶體的浪費而已。
4.8 如何更科學的模型訓練與模型儲存
filepath = 'model-ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5'
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
# fit model
model.fit(x, y, epochs=20, verbose=2, callbacks=[checkpoint], validation_data=(x, y))
save_best_only開啟之後,會如下:
ETA: 3s - loss: 0.5820Epoch 00017: val_loss did not improve
如果val_loss 提高了就會儲存,沒有提高就不會儲存。
4.9,如何在keras中使用tensorboard
RUN = RUN + 1 if 'RUN' in locals() else 1 # locals() 函式會以字典型別返回當前位置的全部區域性變數。
LOG_DIR = model_save_path + '/training_logs/run{}'.format(RUN)
LOG_FILE_PATH = LOG_DIR + '/checkpoint-{epoch:02d}-{val_loss:.4f}.hdf5' # 模型Log檔案以及.h5模型檔案存放地址
tensorboard = TensorBoard(log_dir=LOG_DIR, write_images=True)
checkpoint = ModelCheckpoint(filepath=LOG_FILE_PATH, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping = EarlyStopping(monitor='val_loss', patience=5, verbose=1)
history = model.fit_generator(generator=gen.generate(True), steps_per_epoch=int(gen.train_batches / 4),
validation_data=gen.generate(False), validation_steps=int(gen.val_batches / 4),
epochs=EPOCHS, verbose=1, callbacks=[tensorboard, checkpoint, early_stopping])
都是在回撥函式中起作用:
-
EarlyStopping patience:當early
(1)stop被啟用(如發現loss相比上一個epoch訓練沒有下降),則經過patience個epoch後停止訓練。
(2)mode:‘auto’,‘min’,‘max’之一,在min模式下,如果檢測值停止下降則中止訓練。在max模式下,當檢測值不再上升則停止訓練。 -
模型檢查點ModelCheckpoint
(1)save_best_only:當設定為True時,將只儲存在驗證集上效能最好的模型
(2) mode:‘auto’,‘min’,‘max’之一,在save_best_only=True時決定效能最佳模型的評判準則,例如,當監測值為val_acc時,模式應為max,當檢測值為val_loss時,模式應為min。在auto模式下,評價準則由被監測值的名字自動推斷。
(3)save_weights_only:若設定為True,則只儲存模型權重,否則將儲存整個模型(包括模型結構,配置資訊等)
(4)period:CheckPoint之間的間隔的epoch數 - 視覺化tensorboard write_images: 是否將模型權重以圖片的形式視覺化
4.10 模型概況查詢(包括權重查詢)
# 1、模型概括列印 model.summary() # 2、返回代表模型的JSON字串,僅包含網路結構,不包含權值。可以從JSON字串中重構原模型: from models import model_from_json json_string = model.to_json() model = model_from_json(json_string) # 3、model.to_yaml:與model.to_json類似,同樣可以從產生的YAML字串中重構模型 from models import model_from_yaml yaml_string = model.to_yaml() model = model_from_yaml(yaml_string) # 4、權重獲取 model.get_layer() #依據層名或下標獲得層物件 model.get_weights() #返回模型權重張量的列表,型別為numpy array model.set_weights() #從numpy array裡將權過載入給模型,要求陣列具有與model.get_weights()相同的形狀。 # 檢視model中Layer的資訊 model.layers
4.11 二分類和多分類編譯模型的引數設定
二分類編譯模型的引數與多分類設定還是有區別的,具體如下:
# 二分類
#model.compile(loss='binary_crossentropy',
# optimizer='rmsprop',
# metrics=['accuracy'])
# 多分類
model.compile(loss='categorical_crossentropy', # matt,多分類,不是binary_crossentropy
optimizer='rmsprop',
metrics=['accuracy'])
# 優化器rmsprop:除學習率可調整外,建議保持優化器的其他預設引數不變
5,Keras中常用資料庫Datasets
5.1 CIFAR10 小圖片分類資料集
該資料庫具有 50000個32*32 的彩色圖片作為訓練集,10000個圖片作為測試集,圖片一共有10個類別。
使用方法:
from keras.datasets import cifar10 (X_train, y_train), (X_test, y_test) = cifar10.load_data()
返回值是兩個Tuple。
X_train和X_test 是形如 (nb_samples, 3, 32, 32)的RGB三通道影象資料,資料型別是無符號8位整形(uint8)
Y_train和Y_test 是形如(nb_samples, )標籤資料,標籤的範圍是0-9
5.2 CIFAR100 小圖片分類資料集
該資料庫具有 50000個32*32 的彩色圖片作為訓練集,10000個圖片作為測試集,圖片一共有100個類別,每個類別有600張圖片。這100個類別又分為20個大類。
使用方法:
from keras.datasets import cifar100 (X_train, y_train), (X_test, y_test) = cifar100.load_data(lebel_mode='fine')
引數 label_model:為 fine 或 coarse,控制標籤的精細度,‘fine’ 獲得的標籤是100個小類的標籤;coarse獲得的標籤是大類的標籤。
返回值是兩個Tuple。
X_train和X_test 是形如 (nb_samples, 3, 32, 32)的RGB三通道影象資料,資料型別是無符號8位整形(uint8)
Y_train和Y_test 是形如(nb_samples, )標籤資料,標籤的範圍是0-9
5.3 MNIST 手寫數字識別
該資料庫具有 60000個28*28 的灰度手寫數字圖片作為訓練集,10000個圖片作為測試集
使用方法:
from keras.datasets import mnist (X_train, y_train), (X_test, y_test) = mnist.load_data()
引數 path:如果你本機上已經有此資料集(位於'~/.keras/datasets/'+path),則載入,否則資料將下載到該目錄下。
返回值是兩個Tuple。
X_train和X_test 是形如 (nb_samples, 28, 28)的RGB三通道影象資料,資料型別是無符號8位整形(uint8)
Y_train和Y_test 是形如(nb_samples, )標籤資料,標籤的範圍是0-9
資料庫會被下載到 ~/.keras/datasets/'+path
5.4 Boston 房屋價格迴歸資料庫
該資料庫由StatLib庫取得,由CMU維護,每個樣本都是 1970s晚期波士頓郊區的不同位置,每條資料含有13個屬性,目標值是該位置房子的房價中位數(千 dollar)。
使用方法:
from keras.datasets import boston_housing (X_train, y_train), (X_test, y_test) = boston_housing.load_data()
引數 path:如果你本機上已經有此資料集(位於'~/.keras/datasets/'+path),則載入,否則資料將下載到該目錄下。
引數 seed:隨機數種子
引數 test_split:分割測試集的比例
返回值是兩個Tuple。
X_train和X_test Y_train和Y_test
資料庫會被下載到 ~/.keras/datasets/'+path
5.5 IMDB 影評傾向分類
本資料庫含有來自 IMDB 的 25000 條影評,被標記為正面/負面兩種評價。影評已被預處理為詞下標構成的序列。方便起見,單詞的下標基於它在資料集中出現的頻率標定,例如整數3所編碼的詞為資料中第三常出現的詞。這樣的組織方式使得使用者可以快速完成諸如“只考慮最常出現的10000個詞,但不考慮最常出現的20個詞”這樣的操作。
按照慣例,0不代表任何特定的詞,而用來編碼任何未知單詞。
使用方法
from keras.datasets import imdb
(X_train, y_train), (X_test, y_test) = imdb.load_data(
path='imdb.npz', num_words=None, skip_top=0,
maxlen=None, seed=113,
start_char=1, oov_char=2, index_from=3, )
引數path:如果你本機上已經有此資料集(位於'~/.keras/datasets/'+path),則載入,否則資料將下載到該目錄下。
引數 nb_words:整數或None,要考慮的最常見的單詞數,序列中任何出現頻率更低的單詞將會被編碼為 oov_char 的值。
引數skip_top:整數,忽略最常出現的若干單詞,這些單詞將會被編碼為 oov_char的值。
引數maxlen:整數,最大序列長度,任何長度大於此值的序列將會被截斷。
引數 seed:整數,用於資料重排的隨機數種子
引數start_char:字元,序列的起始將以該字元標記,預設為1 因為0通常用作padding
引數oov_char:整數,因 nb_words或 skip_top 限制而 cut 掉的單詞將被該字元代替
引數index_form:整數,真實的單詞(而不是類似於 start_char的特殊佔位符)將從這個下標開始
返回值是兩個Tuple。
X_train和X_test 序列的列表,每個序列都是詞下標的列表,如果指定了 nb_words,則序列中可能的最大下標為 nb_word-1.如果指定了 maxlen,則序列的最大可能長度為 maxlen
y_train和y_test 序列的標籤,是一個二值 list
5.6 路透社新聞主題分類
該資料庫包含來自路透社的11228條新聞,分為了46個主題,與IMDB庫一樣,每條新聞被編碼為一個詞下標的序列。
使用方法:
from keras.datasets import reuters
(X_train, y_train), (X_test, y_test) = reuters.load_data(
path='reuters.npz', num_words=None, skip_top=0,
maxlen=None, test_split=0.2, seed=113,
start_char=1, oov_char=2, index_from=3,
)
引數的含義與 IMDB同名引數相同,唯一多的引數是:test_split,用於指定從原資料中分割出作為測試集的比例。該資料庫支援獲取用於編碼序列的詞的下標:
word_index = reuters.get_word_index(path='reuters_word_index.json')
上面的程式碼的返回值是一個以單詞為關鍵字,以其下標為值的字典,例如 word_index['giraffe'] 的值可能是1234.
引數path:如果你在本機上有此資料集(位於 ~/.keras/datasets/'+path),則載入。否則資料將下載到該目錄下
5.7 多分類標籤指定Keras格式
資料集的載入上面都說了,而下面要強調的是Keras對多分類的標籤需要一種固定格式,所以需要按照以下的方式進行轉換,num_classes 為分類數量,假設此時有五類:
y_train = keras.utils.to_categorical(y_train, num_classes)
最終輸出的格式應該是(100, 5)
to_categorical 函式如下:
to_categorical(y, num_classes = None)
將類別向量(從0到 nb_classes的整數向量)對映為二值類別矩陣,用於應用到以 categorical_crossentropy 為目標函式的模型中。 其中y表示類別向量,num_classes表示總共類別數。
6,延伸
6.1 fine-tuning 時如何載入 No_top 的權重
如果你需要載入權重到不同的網路結構(有些層一樣)中,例如 fine-tune或transfer-learning,你可以通過層名字來載入模型:
model.load_weights(‘my_model_weights.h5’, by_name=True)
例如,假設元模型為:
model = Sequential()
model.add(Dense(2, input_dim=3, name="dense_1"))
model.add(Dense(3, name="dense_2"))
...
model.save_weights(fname)
新模型如下:
# new model model = Sequential() model.add(Dense(2, input_dim=3, name="dense_1")) # will be loaded model.add(Dense(10, name="new_dense")) # will not be loaded # load weights from first model; will only affect the first layer, dense_1. model.load_weights(fname, by_name=True)
6.2 應對不均衡樣本的情況
使用 class_weight, sample_weight
兩者的區別為
- class_weight 主要針對的時資料不均衡問題,比如:異常檢測的二項分類問題,異常資料僅佔 1%,正常資料佔 99 %;此時就要設定不同類對 loss 的影響。
- sample_weight 主要解決的時樣本質量不同的問題,比如前 1000 個樣本的可信度,那麼他的權重就要高,後 1000個樣本可能有錯,不可信,那麼權重就要調低。
class-weight 的使用:
cw = {0: 1, 1: 50}
model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,verbose=1,callbacks=cbks,
validation_data=(x_test, y_test), shuffle=True,class_weight=cw)
sample_weight 的使用:
from sklearn.utils import class_weight
list_classes = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]
y = train[list_classes].values
sample_weights = class_weight.compute_sample_weight('balanced', y)
model.fit(X_t, y, batch_size=batch_size, epochs=epochs,validation_split=0.1,sample_weight=sample_weights, callbacks=callbacks_list)
來源:https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/discussion/46673
參考文獻:https://blog.csdn.net/sinat_26917383/article/details/7285