
4L-線性表之陣列
關注公眾號 MageByte,設定星標點「在看」是我們創造好文的動力。後臺回覆 “加群” 進入技術交流群獲更多技術成長。
陣列對於每一門程式語言來說都是重要的資料結構之一,當然不同語言對陣列的實現及處理也不盡相同。Java 語言中提供的陣列是用來儲存固定大小的同類型元素。
你一定會說陣列這麼簡單,有啥說的。嘿嘿嘿,裡面包含的玄機可不一定每個人都知道。

今天的疑惑來了…..
陣列幾乎都是從 0 開始編號的,有沒有想過 為啥陣列從 0 開始編號,而不是從 1 開始呢? 使用 1 不是更符合人類的思維麼?
陣列簡介
陣列是一種線性表資料結構,用一組連續的記憶體空間來儲存一組具有相同型別的資料。
裡面出現了幾個重要關鍵字,線性表、連續記憶體空間和相同型別資料,這裡解釋下每個關鍵詞的含義。
線性表
就是資料排成像線一樣的結構,就像我們的高鐵 G1024 號,每節車廂首尾相連,資料最多隻有「前」和「後」兩個方向。除了陣列,連結串列,佇列,棧都是線性結構。
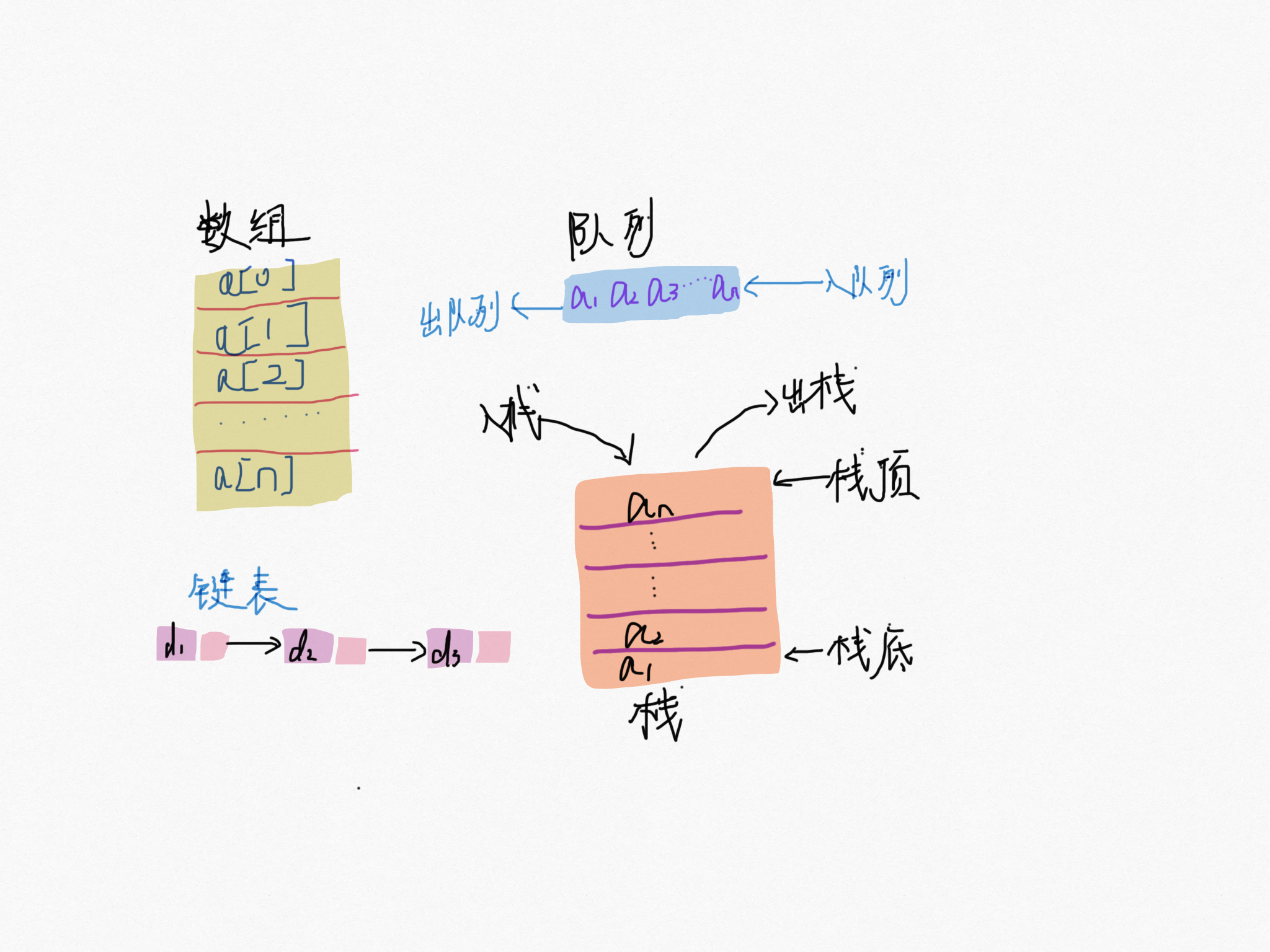
非線性表
比如二叉樹、堆、圖等。之所以叫非線性,是因為,在非線性表中,資料之間並不是簡單的前後關係。
連續的記憶體空間
正式由於它具有連續的記憶體空間和相同的資料型別的資料。就有一個牛逼特性:「隨機訪問」。很多人面試的時候一定被問陣列與連結串列有什麼區別?多數會回答 “連結串列適合插入、刪除,時間複雜度 O(1);陣列適合查詢,查詢時間複雜度為 O(1)”。
這個回答並不嚴謹。適合查詢,但是查詢的時間複雜度並不是 O(1),即便是已經排序好的資料,你用二分法查詢時間複雜度也是 O(logn)。正確的應該是,陣列支援隨機訪問,根據下表隨機訪問的時間複雜度為 O(1)。
隨機訪問
我們都知道陣列是根據下表訪問資料的,它是如何實現隨機訪問呢?
用一個長度 4 的 int 型別的陣列 int[] a = new int[4] 舉例,首先計算機給陣列 a 分配了一塊連續記憶體空間 1000~1015。int 型別佔 4 個位元組,所以一共佔有 4*4位元組。記憶體塊的首地址 base_address = 1000。當程式隨機訪問陣列中的第 i 個元素,計算機通過以下定址公式計算出記憶體地址。
targetAddress = base_address + i * data_type_size- targetAddress:訪問目標的記憶體地址。
- base_address:陣列記憶體塊的首地址。
- i 表示要訪問的下標, data_type_size:資料型別的位元組大小,比如 int 型別佔 4 個位元組。
首地址就像高鐵 G1024 編號,每節車廂就是陣列的的下標位置,每節車廂的座位就像一個個位元組長度。
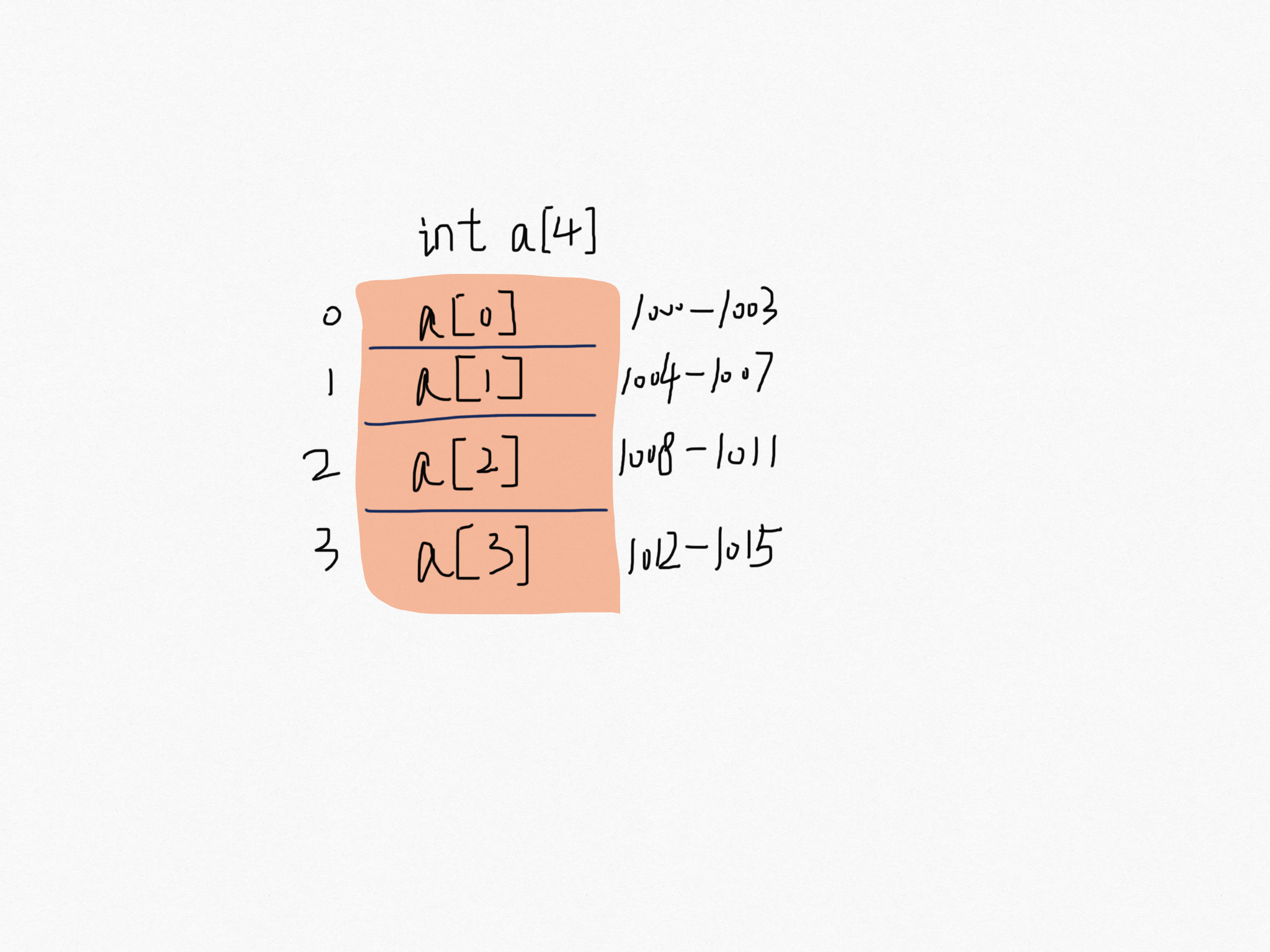
敲黑板了:同學們,陣列定址公式就是這兒回事。這個公式也是最後解釋為何 下標從 0 開始的鋪墊。
為何下標從 0 開始?
“下標”最確切的定義應該是“偏移(offset)”。前面也講到,如果用 base_address 來表示陣列的首地址,a[0] 就是偏移為 0 的位置,也就是首地址,a[i] 就表示偏移 i 個 data_type_size 的位置,所以計算 a[i] 的記憶體地址只需要用這個公式:
targetAddress[i] = base_address + i * data_type_size現在問題來了,假如陣列下標從 1 開始,計算 a[i] 的記憶體地址公式就需要改成:
targetAddress[i] = base_address + (i - 1) * data_type_size重點來了,對比兩個公式,從 1 開始每次隨機訪問陣列元素都多了一次減法運算,相當於多執行了一次減法指令。
陣列作為非常基礎的資料結構,通過下標隨機訪問陣列元素又是其非常基礎的程式設計操作,效率的優化就要儘可能做到極致。所以為了減少一次減法操作,陣列選擇了從 0 開始編號,而不是從 1 開始。
當然這不能說是絕對,也可能是歷史原因,C 語言設計是從 0 開始,後面的高階語言都效仿,也方便程式猿很快的適應,減少學習成本。
低效的插入和刪除
有利有弊,這個限制也導致陣列的刪除、插入這種操作變得低效,為了保證記憶體連續性,就需要做資料移動工作。
那有沒有什麼改進方式呢?
插入操作
陣列長度為 n,將一個元素插入到陣列的第 k 個位置。為了滿足連續性我們需要把 k 這個位置騰出來,給新插入的資料佔坑,然後把 k 到 n 這部分的資料都往後移動一位。這個插入的時間複雜度是多少呢?我們來分析下,順便學習下時間與空間複雜度分析。
當在陣列的末尾插入元素,那就不需要移動資料,所以「最好時間複雜度」為 O(1)。當插入的位置在陣列的開頭,那所有的資料都需要依次往後移動一位,所有最壞時間複雜度 O(n)。而我們在每個位置插入元素概率是一樣的,所以平均時間複雜度 就是 $$\frac {(1+2+3+…+n)} {n} = O(n)$$。
優化思路-鳩佔鵲巢
如果陣列中的順序是有序,我們就需要移動 k 之後的資料,假如陣列中存放的資料無序,只是作為一個存放資料的集合,要將某個元素插入到陣列 k 位置,我們可以把原來在 k 位置的元素放到陣列的最後,把新插入的元素放入 k 這個位置,時間複雜度就降低到了 O(1)。
刪除操作
同理,假設我們要刪除 第 k 個位置的資料,如果 k = n-1,那麼最好時間複雜度就是 O(1)。若果 k = 0,最壞時間複雜度 O(n)。平均時間複雜度也是 O(n)。
優化思路-標記-批量執行
實際上,在某些場合並不需要非要追求資料的連續性。可以將多次的刪除操作批量執行。
比如陣列 number[6]中儲存了 6 個 int 型別的元素:1、2、3、4、5、6。依次刪除 1、2、3。三個元素。防止每次刪除都需要移動資料,我們只要標記資料已經被刪除,當達到刪除閾值,比如是 3,才執行移動資料的操作,這個時候才執行移動操作,大大減少了資料搬移。
你會發現,這不就是 JVM 標記清除垃圾回收演算法的核心思想嗎?沒錯,資料結構和演算法的魅力就在於此,很多時候我們並不是要去死記硬背某個資料結構或者演算法,而是要學習它背後的思想和處理技巧,這些東西才是最有價值的。如果你細心留意,不管是在軟體開發還是架構設計中,總能找到某些演算法和資料結構的影子。
知識拓展&總結
陣列用一塊連續的記憶體空間,來儲存相同型別的一組資料,最大的特點就是支援隨機訪問,但插入、刪除操作也因此變得比較低效,平均情況時間複雜度為 O(n)。在平時的業務開發中,我們可以直接使用程式語言提供的容器類,但是,如果是特別底層的開發,直接使用陣列可能會更合適。
問題來了
基於陣列刪除操作我們提出一個優化思路:標記-批量清除思想,在 Java 的 JVM 中,垃圾回收的標記清除演算法是什麼麼?歡迎加群分享你的想法或者後臺回覆 「標記清除」獲取答案。
歡迎加群與我們討論分享,我們第一時間反饋。
推薦閱讀
1.資料結構演算法的重要性
2.時間複雜度與空間複雜度
3.最好、最壞、平均、均攤時間複雜度

相關推薦
4L-線性表之陣列
關注公眾號 MageByte,設定星標點「在看」是我們創造好文的動力。後臺回覆 “加群” 進入技術交流群獲更多技術成長。 陣列對於每一門程式語言來說都是重要的資料結構之一,當然不同語言對陣列的實現及處理也不盡相同。Java 語言中提供的陣列是用來儲存固定大小的同類型元素。 你一定會說陣列這麼簡單,有啥說的
JavaScript 資料結構與演算法之美 - 線性表(陣列、棧、佇列、連結串列)
前言 基礎知識就像是一座大樓的地基,它決定了我們的技術高度。 我們應該多掌握一些可移值的技術或者再過十幾年應該都不會過時的技術,資料結構與演算法就是其中之一。 棧、佇列、連結串列、堆 是資料結構與演算法中的基礎知識,是程式設計師的地基。 筆者寫的 JavaScript 資料結構與演算法之美 系列用
【Java】 大話數據結構(2) 線性表之單鏈表
out 返回 opened time 頭結點 tel color strong 基本數據類型 本文根據《大話數據結構》一書,實現了Java版的單鏈表。 書中的線性表抽象數據類型定義如下(第45頁): 實現程序: package LinkList; /** * 說
算法習題---線性表之單鏈表逆序打印
思路 sta ini info 若是 簡單 數組 for () 一:題目 逆序打印單鏈表中的數據,假設指針指向單鏈表的開始結點 二:思路 1.可以使用遞歸方法,來進行數據打印 2.可以借助數組空間,獲取長度,逆序打印數組 3.若是可以,
算法習題---線性表之控制變量個數獲取數據最小值
.com dex style find oid 常量 一個 std 一位 一:問題 有N個個位正整數存放在int整型數組A中,N定義為已經定義的常量N<=9,數組長度為N,另給一個int型變量i,要求只用上述變量,寫一個算法,找出N個整數中的最小者,並且要求不能
算法習題---線性表之單鏈表的查找
erro 返回 col 問題 null stat printf .com link 一:問題 已知一個帶頭結點的單鏈表,結點結構為(data,link)假設該鏈表只給出了頭指針list,在不改變鏈表的前提下,設計一個盡可能高效的算法,查找鏈表中倒數第k個位置上的結點(
算法習題---線性表之數組實現循環移動
oid 復雜 http pan 復雜度 ack temp img 空間 一:問題 設將n(n>1)個整數存放到一維數組R中,試設計一個在時間和空間兩方面都盡可能高效的算法,將R中保存的序列循環左移p(0<p<n)個位置,即把R中的數據序列由(x0,x
算法習題---線性表之數組主元素查找
info def 進行 元素查找 變化 lib .com 否則 fin 一:題目 主元素是指:一個數在數組中出現的次數超過數組長度的一半,那麽這個數就是數組元素的主元素。例如:{0,5,5,3,4,5,5,5,5,9}這裏面元素5有6個超過了一半,所以就是主元素
數據結構與算法(四)-線性表之循環鏈表
log ddc 兩個 方向 http return close 單向 throw 前言:前面幾篇介紹了線性表的順序和鏈式存儲結構,其中鏈式存儲結構為單向鏈表(即一個方向的有限長度、不循環的鏈表),對於單鏈表,由於每個節點只存儲了向後的指針,到了尾部標識就停止了向後鏈的操作。
線性表之順序儲存
順序表的儲存結構 # define MAXSIZE 10 typedef int ElemType; typedef struct LNode{ ElemType data[MAXSIZE]; int length; }Node; 順序表的基本運算 順序表的初始化
線性表之鏈式儲存
連結串列的儲存結構 typedef int ElementType; typedef struct Node { ElementType data; struct Node* next; }LNode; 連結串列的基本運算 連結串列的初始化 沒有頭結點的連結串列
資料結構線性表之鏈式儲存結構單鏈表(C++)
一. 標頭檔案—linkedlist.h 1 #ifndef _LIKEDLIST_H_ 2 #define _LIKEDLIST_H_ 3 4 #include <iostream> 5 6 template <class T> 7 struc
資料結構與演算法——線性表之順序表(JAVA語言實現 )
資料結構與演算法——線性表之順序表(JAVA語言實現 ) 線性表是由n個數據元素組成的優先序列。 線性表中每個元素都必須有相同的結構,線性表是線性結構中最常用而又最簡單的一種資料結構。線性表由儲存結構是否連續可分為順序表和連結串列。順序表指線性表中每個元素按順序依次儲存,線性表中邏
【Java】 大話資料結構(1) 線性表之順序儲存結構
本文根據《大話資料結構》一書,實現了Java版的順序儲存結構。 順序儲存結構指的是用一段地址連續的儲存單元一次儲存線性表的資料元素,一般用一維陣列來實現。 書中的線性表抽象資料型別定義如下(第45頁): 實現程式:
資料結構:線性表之順序表
順序表之缺點: 每當插入一個元素,可能會有相當多個元素挨著盤兒的往後挪. 每當刪除一個元素,可能會有相當多個
c語言——線性表之順序結構
#include <stdio.h> #include <stdlib.h> #include <conio.h> //線性表——順序儲存 #define LIST_INIT_SIZE 10 #define LISTINCREMENT 10 #define ERR
線性表之順序表與單鏈表的區別及優缺點
這裡比較的是基於C語言實現的順序表與單鏈表,與其他語言的實現可能會有差異,但我相信語言是相通的,它們的實現機制應該也差不多。 1、What 什麼是順序表和單鏈表 ①順序表: 順序表是在計算機記憶體中以陣列的形式儲存的線性表,是指用一組地址連續的儲存單元依
資料結構與演算法(二)-線性表之單鏈表順序儲存和鏈式儲存
前言:前面已經介紹過資料結構和演算法的基本概念,下面就開始總結一下資料結構中邏輯結構下的分支——線性結構線性表 一、簡介 1、線性表定義 線性表(List):由零個或多個數據元素組成的有限序列; 這裡有需要注意的幾個關鍵地方: 1.首先他是一個序列,也就是說元素之間是有個先來後到的。
資料結構與演算法(三)-線性表之靜態連結串列
前言:前面介紹的線性表的順序儲存結構和鏈式儲存結構中,都有對物件地引用或指向,也就是程式語言中有引用或者指標,那麼在沒有引用或指標的語言中,該怎麼實現這個的資料結構呢? 一、簡介 定義:用陣列代替指標或引用來描述單鏈表,即用陣列描述的連結串列叫做靜態連結串列,這種描述方法叫做遊標實現法;
初識線性表之------------靜態順序表
靜態順序表是藉助陣列實現的,但與陣列不同的是,在順序表中資料是連續儲存的,這是順序表與陣列的區別。 下面是關於靜態順序表的實現: 首先,先定義順序表的結構體: 順序表的定義 //因為是藉助陣列實現的,因此