
資料倉庫知識點梳理(1)
阿新 • • 發佈:2020-03-30
近幾年隨著「大資料」、「資料驅動」、「資料中臺」等概念在網際網路界的熱炒,懂資料的獲取、處理到演算法推薦、模型預測等人才也得到熱捧。觀感上,這些技能領域是隨著大資料時代而來的。而實際上,早在上世紀80年到90年代初資料倉庫和資料決策支援系統概念已經提出,本質上都是將多源頭的資料集中起來,採用統計學的方法來進行資料分析以支援企業的各種決策。
既然換湯不換藥,我們可以通過資料倉庫知識來指導在大資料工程的實踐。本文將對資料倉庫的發展歷史和背景進行介紹,作為「資料倉庫知識梳理」系列的第一篇文章。
## 01 資料儲存的發展歷程
從狹義上講,資料倉庫也是一種資料的儲存形式。從電子計算機出現以來,資料的數字化儲存大致經歷了下面的幾個階段。
* 1950s
打孔卡(Punch cards),首個儲存資料的介質
* 1960s
磁性儲存(磁帶、磁碟)
* 1970s
首個數據庫管理軟體(IMS), 層次型資料庫
DBTG,網狀資料庫
* 1980s早期
關係資料模型,RDBMS的實現
* 1980s末-1990s
資料探勘,資料倉庫(W. H. Inmon)
95年資料倉庫流行:IBM的dw方案,Oracle/SQL Server繫結OLAP服務
* 2000s
隨著線上資料增長,成為BI解決方案的一部分
與大資料,NoSQL系統的結合
## 02 企業的決策層級
企業中部署資料倉庫,其目的還是要用資料來說明現在的情況,並對下一步的動作計劃提供支援。企業的決策可以分成三個層級,如下圖所示。
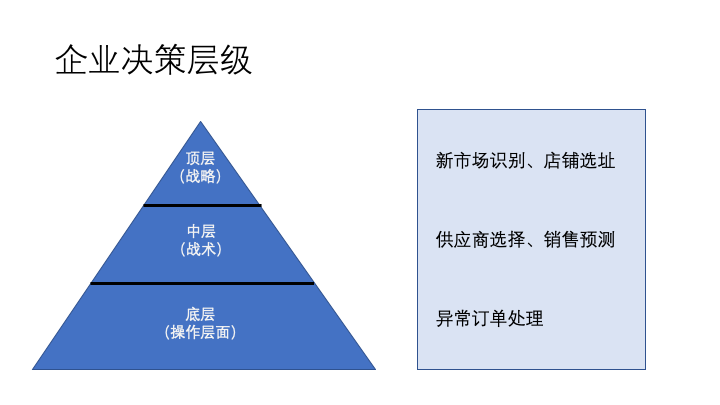
底層可能有操作員就可以執行,比如一個電商訂單物流長期處於「發出」狀態,可能是出現丟件異常,就需要聯絡物流進行處理。中層的銷售預測,需要根據歷史的銷售記錄為主對未來一段時間的銷售進行預測,這一層級可能在特定部門內使用。頂層的新市場識別或者店鋪選址等動作,需要考慮整個公司的資料甚至是外部的資料,如地理、人口、經濟資料等結合起來而作出決策。
因此,在建立資料倉庫或者資料中臺的時候,不是說越複雜的系統就越好,關鍵是看需要支援怎麼樣的決策層級。其次還要考慮實施難度和建設週期等多個方面的因素。
## 03 資料庫技術的限制
上一小節中的「異常訂單處理」,如果單純考慮超時提醒功能,可以直接在關係型資料庫中實現。但是上層的決策,在關係型資料庫上開發可能會遇到以下的3個問題。
1.效能限制:
1.不能同時保證事物處理和BI決策型別的統計查詢;
2.整合度不夠:
1.C/S,B/S架構,資料庫獨立服務特定應用,資料是分散的
2.還有外部資料來源的資料
3.各系統間的名稱、單位口徑的統一
3.方法工具的缺失
1.統計查詢的優化
2.資料建模的方法論
3.配套的統計查詢和統計分析工具
基於以上原因,資料倉庫與業務資料庫有不同的底層設計。
## 04 資料倉庫的定義
> 資料倉庫是一個面向主題的、整合的、非易失的,隨時間變化的用來支援管理人員決策的資料集合。
>
> ——《資料倉庫(第4版)》
* 面向主題,是指對應企業中某一巨集觀分析領域所涉及的分析物件
* 例如:"銷售分析"就是一個分析領域
* 這個"銷售分析"所涉及到的分析物件為商品、供應商、顧客、倉庫等,那麼數倉主題可以確定為商品主題、供應商主題、顧客主題、倉庫主題
* 資料層面來說,主題之間可能存在資料重疊關係
* 整合
* 資料來自於多個異構資料來源
* 標準化的資料整合方法
* 非易失
* 與資料來源的資料分離儲存
* 一旦資料寫入資料倉庫,不進行更新
* 資料倉庫的資料只支援資料的初次載入和訪問
* 隨時間變化
* 保留歷史資料(資料的快照)
* 資料倉庫的資料包含時間元素(記錄時間戳)
* 資料追加方式通過不同時間上資料的變化實現
## 05 資料建模方式
既然資料倉庫最基本的功能是儲存資料,資料如何儲存就是下一個問題了。資料建模方式即對資料的儲存方式進行設計,目前的主流的方式為維度建模,相對而言業務資料庫通常採用關心建模的方式。
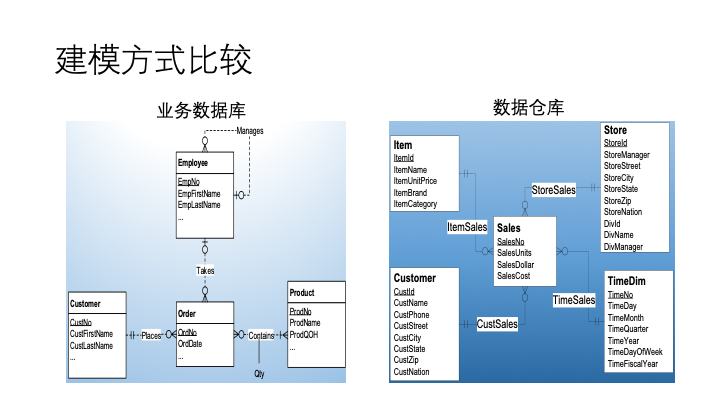
上圖中,左邊是業務資料庫模型,訂單、顧客、產品表等都對於與業務中的實體,方面業務系統的資料查詢和新增,減少sql的查詢。其通常符合「正規化」建模要求。
右邊是數倉的星型模型,以一個銷售主題,通過一個fact表,對接其他維度表資訊。其特點是資料冗餘小,大量的屬性都存放在維度表中,結構清晰,便於使用相關的工具做資料分析。這裡先提一下,資料倉庫查詢語言的工業標準其實不是sql,而是mdx,後面會單獨出一篇講下mdx的工具和簡單語法。

## 06 架構設計
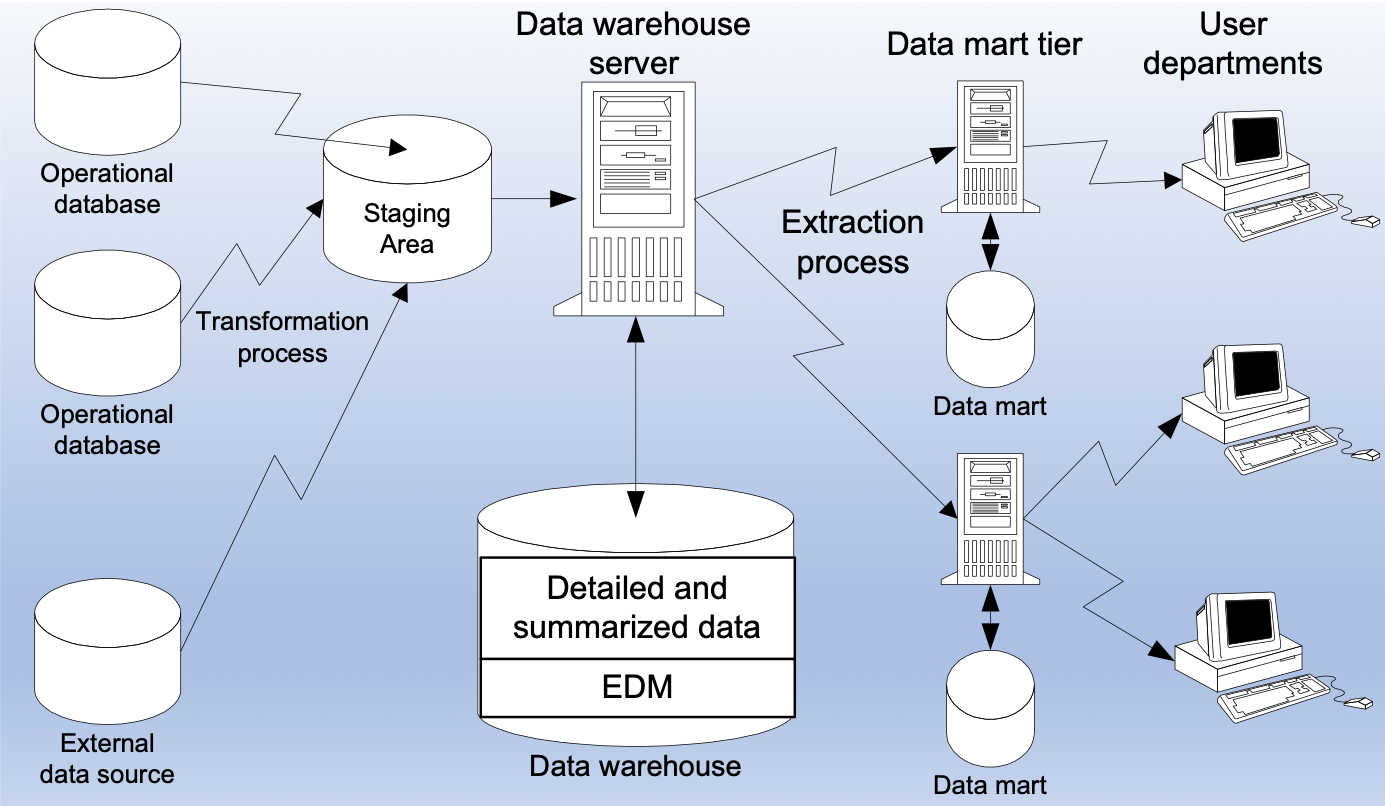
資料倉庫架構設計有自頂向下構建和自底向上構建兩種方式。
其中自頂向下構建方式需要從企業總體需求開始設計出整體的資料模型,然後將所有需要的資料彙集起來ETL到相應的模型物件之中,這是一種大一統的方式。最後再通過特定的許可權設定,將資料的訪問提供給企業下面的部門。
自底向上的方式,可以在子部門中獲得特定主題的小型資料模型,建立服務於特定部門的資料倉庫,它們也被稱為資料集市。
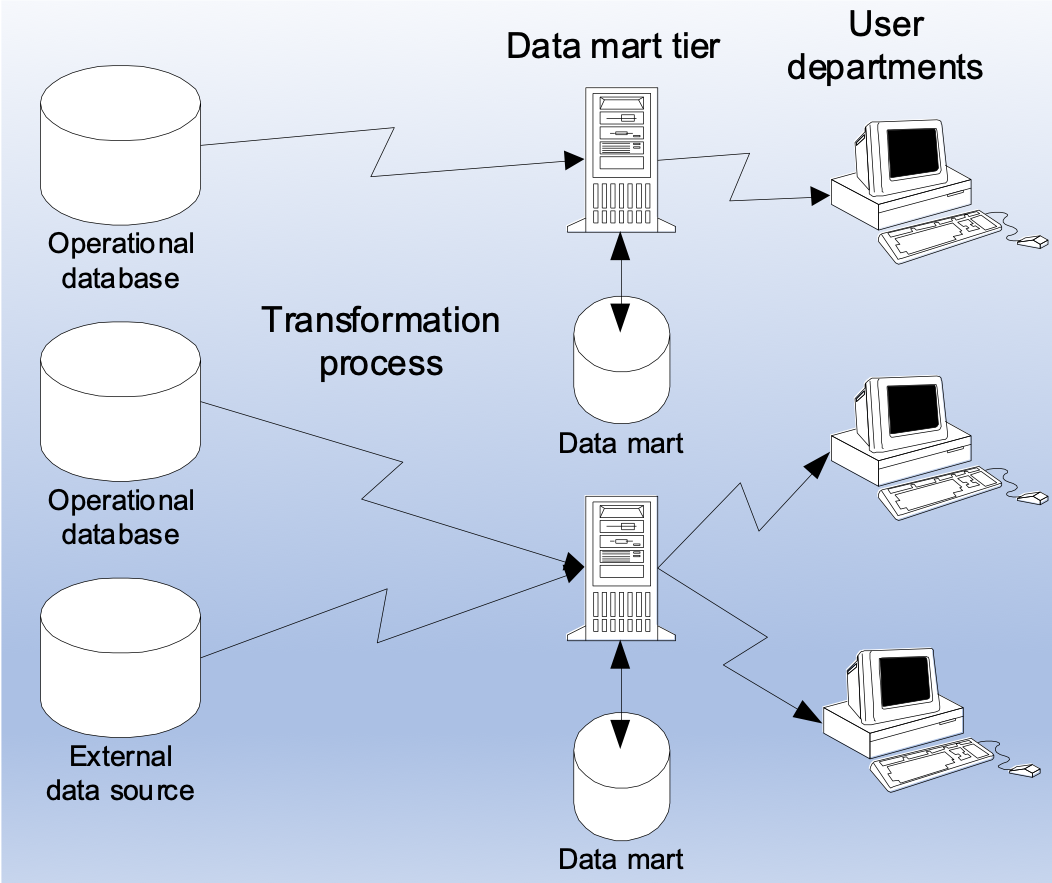
至於如何選擇自己的架構,可以從以下兩個方面進行考慮。
* ROI
* 專案風險:自頂向下方式可能週期較長,部門間資料的流轉必然成為制肘
* 商業價值:資料更集中更有可能發現其中蘊含的關係
* IT部分角度
* 資金政策的來源:明確專案的出資方和收益方
* 資料資訊的來源:明確誰能夠提供出資料
## 07 總結
本文簡要介紹了資料儲存的發展歷史,資料倉庫產生的原因,資料倉庫的定義、資料建模方式和數倉的架構設計。
**歡迎掃描二維碼關注公眾號**
![](https://img2018.cnblogs.com/blog/670593/201912/670593-20191201214002980-3085