
我的Keras使用總結(4)——Application中五款預訓練模型學習及其應用
本節主要學習Keras的應用模組 Application提供的帶有預訓練權重的模型,這些模型可以用來進行預測,特徵提取和 finetune,上一篇文章我們使用了VGG16進行特徵提取和微調,下面嘗試一下其他的模型。
模型的預訓練權重將下載到 ~/.keras/models/ 並在載入模型時自動載入,當然我們也可以下載到自己的目錄下,但是需要去原始碼修改路徑。
模型的官方下載路徑:https://github.com/fchollet/deep-learning-models/releases
TensorFlow VGG-16預訓練模型:https://github.com/ry/tensorflow-vgg16
ImageNet上的預訓練模型參考文獻:https://www.jianshu.com/p/7e13a498bd63
1,預訓練模型的定義
1.1 機器學習為什麼要訓練模型?
在機器學習中大概有如下步驟:確定模型,訓練模型,使用模型。
模型簡單來說可以理解為函式,確定模型時說自己認為這些資料的特徵符合哪個函式。訓練模型就是使用已有的資料,通過一些方法(最優化或者其他方法)確定函式的引數,引數確定後的函式就是訓練的結果,使用模型就是將新的資料代入函式求值。
一個模型中,有很多引數,有些引數,可以通過訓練獲得,比如logistic模型中的權重。但是有些引數,通過訓練無法獲得,被稱為“超引數”,比如學習率等。這需要靠經驗,過著gird search的方法去尋找。
1.2 預訓練模型的由來
預訓練模型是深度學習架構,已經過訓練以執行大量資料上的特定任務(例如,識別圖片上的分類問題)。這種訓練不容易執行,並且需要大量的資源,超出許多可用於深度學習模型的人可用的資源。在談論預訓練模型的時候,通常指的時在ImageNet(http://image-net.org/)上訓練的CNN(用於視覺相關任務的架構)。ImageNet資料包含超過1400萬個影象,其中120萬個影象分為1000個類別(大約100萬個影象含邊界框和註釋)。
1.3 預訓練模型的定義
預訓練模型是在訓練結束時結果比較好的一組權重值,研究人員分享出來供其他人使用。我們可以在GitHub上找到許多具有權重的庫,但是在獲取預訓練模型的最簡單的方法可能是直接來自你選擇的深度學習庫。
上面是預訓練模型的規範定義,你還可以找到預訓練的模型來執行其他任務,例如物體檢測或姿勢估計。
此外,最近研究人員已開始突破預訓練模型的界限。在自然語言處理(使用文字的模型)的上下文中,我們已經有一段時間使用嵌入層。Word嵌入是一組數字的表示,其中的想法是類似的單詞將以某種有用的方式表達。例如,我們可能希望'鷹派','鷹','藍傑伊'的表現形式有一些相似之處,並且在其他方面也有所不同。用矢量表示單詞的開創性論文是word2vec,這篇嵌入層的論文是我最喜歡的論文之一,最早源於80年代,Geoffrey Hinton 的論文。
儘管通過對大型資料集進行訓練獲得的單詞的表示非常有用(並且以與預訓練模型類似的方式共享),但是將單詞嵌入作為預訓練模型會有點拉伸。然而,通過傑里米霍華德和塞巴斯蒂安魯德的工作,真正的預訓練模型已經到達NLP世界。它們往往非常強大,圍繞著首先訓練語言模型(在某種意義上理解某種語言中的文字而不僅僅是單詞之間的相似性)的概念,並將其作為更高階任務的基礎。有一種非常好的方法可以在大量資料上訓練語言模型,而不需要對資料集進行人工註釋。這意味著我們可以在儘可能多的資料上訓練語言模型,比如整個維基百科!然後我們可以為特定任務(例如,情感分析)構建分類器並對模型進行微調,其中獲取資料的成本更高。要了解有關這項非常有趣的工作的更多資訊,請參閱論文雖然我建議先看看隨附的網站,瞭解全域性。
1.4 為什麼要使用預訓練模型呢?
目前在深度學習神經網路中,訓練過程是基於梯度下降法來進行引數調優的。通過一步步的迭代,來求得最小的損失函式和最優的模型權重。進行梯度下降時給每一個引數賦一個初始值。一般我們希望資料和引數的均值都為0,輸入和輸出的方法一致。在實際應用中,引數服從高斯分佈或者均勻分佈都是比較有效的初始化方法。
模型的作者已經給出了基準模型,這樣我們可以使用預訓練模型,而無需從頭開始構建模型來解決類似的問題。
儘管需要進行一些微調,但這為我們節省了大量的時間和計算資源。
一個好的初始化優勢都有哪些呢?
- 1,加速梯度下降的收斂速度
- 2,更有可能獲得一個低模型誤差,或者低泛化誤差的模型
- 3,降低因未初始化或初始化不當導致的梯度消失或者梯度爆炸問題。此情況會導致模型訓練速度變慢,崩潰,直到失敗
- 4,其中隨機初始化,可以打破對稱性,從而保證不同的隱藏單位可以學到不同的東西。
1.5 什麼是finetuning?
finetuning就是使用已用於其他目標,預訓練好的權重或者部分權重,作為初始值開始訓練,那麼為什麼我們不用隨機選取的幾個數作為權重初始值?原因很簡單,第一,自己從頭訓練卷積神經網路容易出現問題,第二,finetuning能很快收斂到一個較理想的狀態,省時又省心。
那麼finetuning的具體做法是什麼?
- 複用相同層的權重,新定義層取隨機權重初始值
- 調大新定一層的學習率,調小服用層學習率
1.6 預訓練模型最好結果
2018年NLP領域取得最重大突破!谷歌AI團隊新發布的BERT模型,在機器閱讀理解頂級水平測試SQuAD1.1中表現出驚人的成績:全部兩個衡量指標上全面超越人類,並且還在11種不同NLP測試中創出最佳成績。毋庸置疑,BERT模型開啟了NLP的新時代!而谷歌提出的BERT就是在OpenAI的GPT的基礎上對預訓練的目標進行了修改,並用更大的模型以及更多的資料去進行預訓練,從而得到了目前為止最好的效果。
旁註:如何從頭開始訓練架構以獲得預訓練的重量?這根本不容易回答,而且相關資訊相當稀少。從紙張到紙張需要大量的跳躍才能將訓練的所有方面(增強,訓練 - 測試分裂,重量衰減,時間表等)拼湊在一起。我試著破解其中一些我過去做過的實驗,你可以在這裡或這裡看看這些嘗試。更有趣的是DAWNBench比賽網站。在這裡,各個團隊已經嘗試將他們的神經網路訓練到某種程度的準確性,同時提高資源使用效率和優化速度。這通常不是架構最初如何訓練,而是一個非常有用的資訊源(因為程式碼也可用)。
1.7 TensorFlow VGG-16預訓練模型
參考博文:https://blog.csdn.net/daydayup_668819/article/details/70225244
在我們的實際專案中,一般不會直接從第一層直接開始訓練,而是通過在大的資料集上(如ImageNet)訓練好的模型,把前面那些層的引數固定,在運用到我們新的問題上,修改最後一到兩層,用自己的資料去微調(finetuning),一般效果也很好。
所謂finetuning,就是說我們針對某相似任務已經訓練好的模型,比如CaffeNet,VGG-16,ResNet等,再通過自己的資料集進行權重更新,如果資料量比較小,可以只更新最後一層,其他層的權重不變,如果資料量中等,可以訓練後面幾層,如果資料量很大,那OK,直接從頭訓練,只不過花在訓練的時間比較多。
在網路訓練好之後,只需要forward過程就能做預測,當然,我們也可以直接把這個網路當成一個feature extractor 來用,可以直接用任何一層的輸出作為特徵,根據R-CNN對AlexNet的實驗結果,如果不做 fine-tuning,pool5和fc6和fc7的特徵效果並沒有很強的提升,所以如果直接用作feature extractor,直接用pool的最後一層輸出就OK。
VGG-16是一種深度卷積神經網路模型,16表示其深度。模型可以達到92.7%的測試準確度,它的資料集包括1400萬張影象,1000個類別。
2,模型文件
Keras的應用模組(keras.applications)提供了帶有預訓練權重的深度學習模型,這些模型可以用來進行預測,特徵提取和微調(fine-tuning)。
2.1 模型概覽
在ImageNet上預訓練過的用於影象分類的模型:
- Xception
- VGG16
- VGG19
- ResNet, ResNetV2, ResNeXt
- InceptionV3
- InceptionResNetV2
- MobileNet
- MobileNetV2
- DenseNet
- NASNet
模型的top-1準確率和 top-5準確率分別如下(均是在ImageNet驗證集上的結果)
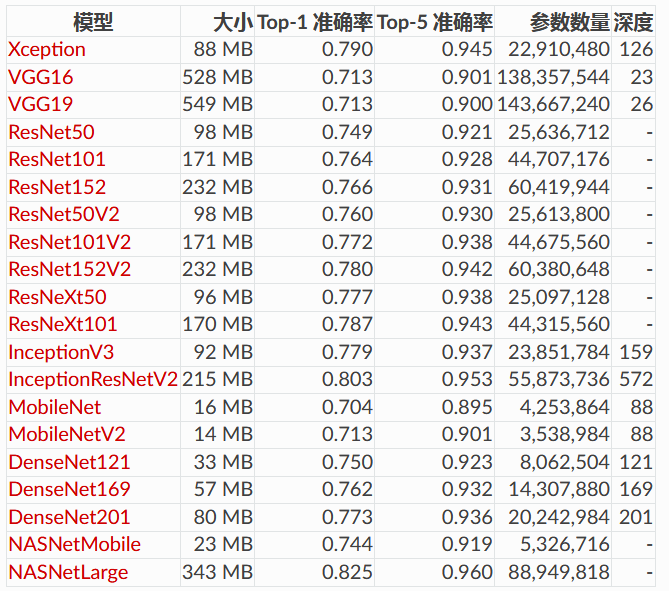
(其中Depth 表示網路拓撲深度。這包括啟用層等)
下面對Keras中幾個模型進行詳細說明(官網地址:https://keras-cn.readthedocs.io/en/latest/legacy/other/application/ https://keras.io/zh/applications/)
2.2 Xception模型
keras.applications.xception.Xception(include_top=True,
weights='imagenet', input_tensor=None,
input_shape=None, classes=1000)
Xception V1模型,權重由 ImageNet 訓練而言,在ImageNet上,該模型取得了驗證集 top1 0.790 和 top 5 0.945 的正確率。
注意,該模型目前僅能以 TensorFlow 為後端使用,由於它依賴於 “Separable Convolution”層,目前該模型只支援 tf 的維度順序(width,height,channels)。
預設輸入圖片大小為 299*299
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“Imagenet”表示載入預訓練權重
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 71,如(150, 150, 3)
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1610.02357
2.3 VGG16模型
keras.applications.vgg16.VGG16(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
classes=1000)
vgg16模型,權重由 ImageNet 訓練
該模型在 Theano和TensorFlow後端均可使用,並接受th和tf兩種輸入維度順序
模型的預設輸入尺寸為 224*224
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“Imagenet”表示載入預訓練權重
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 48,如(200, 200, 3)
- pooling:當 include_top=False時,該引數指定了池化方式。None代表不池化,最後一個卷積層的輸出為 4D張量,‘avg’代表全域性平均池化,‘max’代表全域性最大值池化
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1409.1556
2.4 VGG19模型
keras.applications.vgg19.VGG19(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
classes=1000)
vgg19模型,權重由 ImageNet 訓練
該模型在 Theano和TensorFlow後端均可使用,並接受th和tf兩種輸入維度順序
模型的預設輸入尺寸為 224*224
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“Imagenet”表示載入預訓練權重
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 48,如(200, 200, 3)
- pooling:當 include_top=False時,該引數指定了池化方式。None代表不池化,最後一個卷積層的輸出為 4D張量,‘avg’代表全域性平均池化,‘max’代表全域性最大值池化
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1409.1556
預訓練權重由牛津VGG組釋出的預訓練權重移植而來
2.5 ResNet50模型
keras.applications.resnet50.ResNet50(include_top=True,
weights='imagenet', input_tensor=None,
input_shape=None, classes=1000)
50層殘差網路模型,權重由 ImageNet 訓練
該模型在Theano和TensorFlow後端均可使用,並接受 th 和 tf兩種輸入維度順序
預設輸入圖片大小為 299*299
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“Imagenet”表示載入預訓練權重
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 71,如(150, 150, 3)
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1512.03385
2.6 Inception V3模型
keras.applications.inception_v3.InceptionV3(include_top=True,
weights='imagenet', input_tensor=None,
input_shape=None, classes=1000)
Inception V3模型,權重由 ImageNet 訓練
該模型在 Theano和TensorFlow後端均可使用,並接受th 和 tf兩種輸入維度順序
預設輸入圖片大小為 299*299
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“Imagenet”表示載入預訓練權重
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 71,如(150, 150, 3)
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1512.00567
2.7 InceptionResNetV2模型
keras.applications.inception_resnet_v2.InceptionResNetV2(include_top=True,
weights='imagenet', input_tensor=None,
input_shape=None, pooling=None, classes=1000)
Inception-ResNet V2 模型,權重由 ImageNet 訓練
該模型在 Theano和TensorFlow後端均可使用,並接受th 和 tf兩種輸入維度順序
預設輸入圖片大小為 299*299
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“Imagenet”表示載入預訓練權重
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 71,如(150, 150, 3)
- pooling:可選,當 include_top為False時,該引數指定了特徵提取時的池化方式。
- None代表不池化,直接輸出最後一層卷積層的輸出,該輸出是一個四維張量
- avg 代表全域性平均池化(GlobalAveragePooling2D),相當於在最後一層卷積層後面再加上一層全域性平均池化層,輸出是一個二維張量。
- max 代表全域性最大池化
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1602.07261
2.8 MobileNet 模型
keras.applications.mobilenet.MobileNet(input_shape=None, alpha=1.0,
depth_multiplier=1, dropout=1e-3, include_top=True,
weights='imagenet', input_tensor=None, pooling=None,
classes=1000)
Mobilenet 模型,權重由 ImageNet 訓練
該模型只支援 channels_last 的維度順序(高度,寬度,通道)
預設輸入圖片大小為 224*224
引數:
- input_shape: 可選,輸入尺寸元組,僅當
include_top=False時有效,否則輸入形狀必須是(224, 224, 3)(channels_last格式)或(3, 224, 224)(channels_first格式)。它必須為 3 個輸入通道,且寬高必須不小於 32,比如(200, 200, 3)是一個合法的輸入尺寸。 - alpha: 控制網路的寬度:
- 如果
alpha< 1.0,則同比例減少每層的濾波器個數。 - 如果
alpha> 1.0,則同比例增加每層的濾波器個數。 - 如果
alpha= 1,使用論文預設的濾波器個數
- 如果
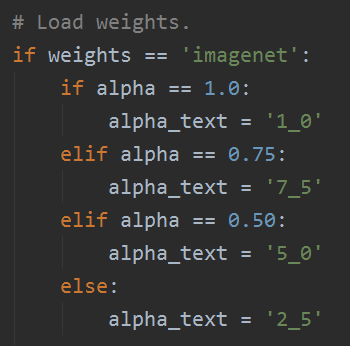
- depth_multiplier: depthwise卷積的深度乘子,也稱為(解析度乘子)
- dropout: dropout 概率
- include_top: 是否包括頂層的全連線層。
- weights:
None代表隨機初始化,'imagenet'代表載入在 ImageNet 上預訓練的權值。 - input_tensor: 可選,Keras tensor 作為模型的輸入(比如
layers.Input()輸出的 tensor)。 - pooling: 可選,當
include_top為False時,該引數指定了特徵提取時的池化方式。None代表不池化,直接輸出最後一層卷積層的輸出,該輸出是一個四維張量。'avg'代表全域性平均池化(GlobalAveragePooling2D),相當於在最後一層卷積層後面再加一層全域性平均池化層,輸出是一個二維張量。'max'代表全域性最大池化
- classes: 可選,圖片分類的類別數,僅當
include_top為True並且不載入預訓練權值時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/pdf/1704.04861.pdf
2.9 MusicTaggerCRNN模型
keras.applications.music_tagger_crnn.MusicTaggerCRNN(weights='msd',
input_tensor=None, include_top=True, classes=50)
該模型是一個卷積迴圈模型,以向量化的 MelSpectrogram 音樂資料為輸入,能夠輸出音樂的風格。你可以用 keras.applications.musiic_tagger_crnn.preprocess_input 來將一個音樂檔案向量化為 spectrogram,注意,使用該功能需要安裝 Librosa,請參考以下使用範例。
引數:
- include_top:是否保留頂層的3個全連線網路
- weights:None代表隨機初始化,即不載入預訓練權重,“msd" 代表載入預訓練權重(訓練自Millon Song DataSet:http://labrosa.ee.columbia.edu/millionsong/)
- input_tensor:可填入Keras tensor 作為模型的影象輸出 tensor
- input_shape:可選,僅當 include_top=False 有效,應為長為3的 tuple,指明輸入圖片的 shape,圖片的寬高必須大於 71,如(150, 150, 3)
- classes:可選,圖片分類的類別數,僅當 include_top=True 並且不載入預訓練權重時可用。
返回值:
Keras模型物件
參考文獻:
https://arxiv.org/abs/1609.04243
使用範例:音樂特徵抽取與風格標定
from keras.applications.music_tagger_crnn import MusicTaggerCRNN
from keras.applications.music_tagger_crnn import preprocess_input, decode_predictions
import numpy as np
# 1. Tagging
model = MusicTaggerCRNN(weights='msd')
audio_path = 'audio_file.mp3'
melgram = preprocess_input(audio_path)
melgrams = np.expand_dims(melgram, axis=0)
preds = model.predict(melgrams)
print('Predicted:')
print(decode_predictions(preds))
# print: ('Predicted:', [[('rock', 0.097071797), ('pop', 0.042456303), ('alternative', 0.032439161), ('indie', 0.024491295), ('female vocalists', 0.016455274)]])
#. 2. Feature extraction
model = MusicTaggerCRNN(weights='msd', include_top=False)
audio_path = 'audio_file.mp3'
melgram = preprocess_input(audio_path)
melgrams = np.expand_dims(melgram, axis=0)
feats = model.predict(melgrams)
print('Features:')
print(feats[0, :10])
# print: ('Features:', [-0.19160545 0.94259131 -0.9991011 0.47644514 -0.19089699 0.99033844 0.1103896 -0.00340496 0.14823607 0.59856361])
3,圖片分類模型的示例
應用於影象分類的模型,權重訓練自 ImageNet:Xception VGG16 VGG19 ResNet50 InceptionV3
所有的這些模型(除了Xception)都相容 Theano 和 TensorFlow,並會自動基於 ~/.keras/keras.json 的Keras 的影象維度進行自動設定。例如,如果你設定 data_format = 'channel_last',則載入的模型將按照 TensorFlow的維度順序來構造,即“Width-Height-Depth”的順序。
3.1 利用ResNet50 網路進行 ImageNet分類
程式碼如下:
# 利用ResNet50網路進行 ImageNet 分類
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
model = ResNet50(weights='imagenet')
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
# decode the results into a list of tuples(class description, probability)
# one such list for each sample in the batch
print('Predicted:', decode_predictions(preds, top=3)[0])
'''
Predicted: [('n01871265', 'tusker', 0.40863296),
('n02504458', 'African_elephant', 0.36055887),
('n02504013', 'Indian_elephant', 0.22416794)]
'''
3.2 利用 VGG16 提取特徵
程式碼如下:
# 利用VGG16提取特徵 from keras.applications.vgg16 import VGG16 from keras.preprocessing import image from keras.applications.vgg16 import preprocess_input import numpy as np model = VGG16(weights='imagenet', include_top=False) img_path = 'elephant.jpg' img = image.load_img(img_path, target_size=(224, 224)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) features = model.predict(x) print(features.shape, type(features)) # (1, 7, 7, 512) <class 'numpy.ndarray'>
3.3 從 VGG19的任意中間層中抽取特徵
程式碼如下:
# 利用VGG16提取特徵
from keras.applications.vgg19 import VGG19
from keras.preprocessing import image
from keras.applications.vgg19 import preprocess_input
from keras.models import Model
import numpy as np
base_model = VGG19(weights='imagenet')
model = Model(inputs=base_model.input,
outputs=base_model.get_layer('block4_pool').output)
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
block4_pool_features = model.predict(x)
print(block4_pool_features.shape, type(block4_pool_features))
注意,這裡將模型下載到本地,就不用了先載入網上的模型了,這樣比較快,下載到本地,然後修改原始碼路徑即可

3.4 在新類上 finetune inceptionV3
程式碼如下:
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing import image
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras import backend as K
# create the base pre-trained model
base_model = InceptionV3(weights='imagenet', include_top=False)
# add a global spatial average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
# let's add a fully-connected layer
x = Dense(1024, activation='relu')(x)
# and a logistic layer -- let's say we have 200 classes
predictions = Dense(200, activation='softmax')(x)
# this is the model we will train
model = Model(input=base_model.input, output=predictions)
# first: train only the top layers (which were randomly initialized)
# i.e. freeze all convolutional InceptionV3 layers
for layer in base_model.layers:
layer.trainable = False
# compile the model (should be done *after* setting layers to non-trainable)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# train the model on the new data for a few epochs
model.fit_generator(...)
# at this point, the top layers are well trained and we can start fine-tuning
# convolutional layers from inception V3. We will freeze the bottom N layers
# and train the remaining top layers.
# let's visualize layer names and layer indices to see how many layers
# we should freeze:
for i, layer in enumerate(base_model.layers):
print(i, layer.name)
# we chose to train the top 2 inception blocks, i.e. we will freeze
# the first 172 layers and unfreeze the rest:
for layer in model.layers[:172]:
layer.trainable = False
for layer in model.layers[172:]:
layer.trainable = True
# we need to recompile the model for these modifications to take effect
# we use SGD with a low learning rate
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy')
# we train our model again (this time fine-tuning the top 2 inception blocks
# alongside the top Dense layers
model.fit_generator(...)
3.5 在定製的輸入 tensor 上構建 Inception V3
程式碼如下:
from keras.applications.inception_v3 import InceptionV3
from keras.layers import Input
# this could alse be the output a different Keras model or layer
input_tensor = Input(shape=(224, 224, 3))
model = InceptionV3(input_tensor=input_tensor,
weights='imagenet',
include_top=True)
'''
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.5/inception_v3_weights_tf_dim_ordering_tf_kernels.h5
'''
4,模型說明
4.1 th與tf 的區別
Keras提供了兩套後端,Theano 和 TensorFlow,tf和th 的大部分功能都被 backend 統一包裝起來了,但是二者還是存在不少的衝突,有時候需要特別注意Keras是執行在哪種後端上,他們的主要衝突是維度順序,也就是資料格式的區別,channels_last 對應的是 tf,channels_first 對應的是 th。
比如:
vgg16_weights_th_dim_ordering_th_kernels_notop.h5 vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
4.2 notop模型是指什麼?
notop 表示是否包含最後三個全連線層(whether to include the 3 fully-connected layers at the top of the network),用來做 fine-tuning 專用,專門開源了這類模型。
就比如上面模型中出現的 include_top=False/True,一般來說為TRUE,表示保留頂層的全連線網路。
4.3 H5py簡述
Keras中已訓練模型為H5PY 格式的,不是 caffe 的 .caffemodel
htpy.File 類似於Python的詞典物件,因此我們可以檢視所有的鍵值。
讀入如下:
# 讀入模型
file=h5py.File('.../notop.h5','r')
# 代表file的屬性,其中有一個屬性為 'nb_layers'
file.attrs['nb_layers']
f.keys()
[u'block1_conv1', u'block1_conv2', u'block1_pool', u'block2_conv1', u'block2_conv2',
u'block2_pool', u'block3_conv1', u'block3_conv2', u'block3_conv3', u'block3_pool',
u'block4_conv1', u'block4_conv2', u'block4_conv3', u'block4_pool', u'block5_conv1',
u'block5_conv2', u'block5_conv3', u'block5_pool']
可以使用下面程式碼看file中各個層內有什麼
for name in file:
print(name)
# 類似f.keys()
結果如下:
block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_pool
5,Keras-application-VGG16解讀
注意:在計算機視覺CV任務中,對於遠大於可用記憶體的大型圖片資料集,應用深度學習模型 VGG16 提取 bottleneck特徵,用 HDF5儲存特徵 array,是目前我感覺的最佳方案。
5.1 函式式
此py檔案來源於:https://github.com/fchollet/deep-learning-models/blob/master/vgg16.py
此解讀檔案來源於:https://blog.csdn.net/sinat_26917383/article/details/72859145
VGG16預設的輸入資料格式應該是:channels_last
程式碼如下:
# -*- coding: utf-8 -*-
'''VGG16 model for Keras.
# Reference:
- [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
'''
from __future__ import print_function
import numpy as np
import warnings
from keras.models import Model
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Input
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import GlobalMaxPooling2D
from keras.layers import GlobalAveragePooling2D
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras import backend as K
from keras.applications.imagenet_utils import decode_predictions
# decode_predictions 輸出5個最高概率:(類名, 語義概念, 預測概率) decode_predictions(y_pred)
from keras.applications.imagenet_utils import preprocess_input
# 預處理 影象編碼服從規定,譬如,RGB,GBR這一類的,preprocess_input(x)
from keras.applications.imagenet_utils import _obtain_input_shape
# 確定適當的輸入形狀,相當於opencv中的read.img,將影象變為陣列
from keras.engine.topology import get_source_inputs
WEIGHTS_PATH = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5'
WEIGHTS_PATH_NO_TOP = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5'
def VGG16(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None,
classes=1000):
# 檢查weight與分類設定是否正確
if weights not in {'imagenet', None}:
raise ValueError('The `weights` argument should be either '
'`None` (random initialization) or `imagenet` '
'(pre-training on ImageNet).')
if weights == 'imagenet' and include_top and classes != 1000:
raise ValueError('If using `weights` as imagenet with `include_top`'
' as true, `classes` should be 1000')
# 設定影象尺寸,類似caffe中的transform
# Determine proper input shape
input_shape = _obtain_input_shape(input_shape,
default_size=224,
min_size=48,
# 模型所能接受的最小長寬
data_format=K.image_data_format(),
# 資料的使用格式
include_top=include_top)
#是否通過一個Flatten層再連線到分類器
# 資料簡單處理,resize
if input_tensor is None:
img_input = Input(shape=input_shape)
# 這裡的Input是keras的格式,可以用於轉換
else:
if not K.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
# 如果是tensor的資料格式,需要兩步走:
# 先判斷是否是keras指定的資料型別,is_keras_tensor
# 然後get_source_inputs(input_tensor)
# 編寫網路結構,prototxt
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
if include_top:
# Classification block
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
x = Dense(classes, activation='softmax', name='predictions')(x)
else:
if pooling == 'avg':
x = GlobalAveragePooling2D()(x)
elif pooling == 'max':
x = GlobalMaxPooling2D()(x)
# 調整資料
# Ensure that the model takes into account
# any potential predecessors of `input_tensor`.
if input_tensor is not None:
inputs = get_source_inputs(input_tensor)
# get_source_inputs 返回計算需要的資料列表,List of input tensors.
# 如果是tensor的資料格式,需要兩步走:
# 先判斷是否是keras指定的資料型別,is_keras_tensor
# 然後get_source_inputs(input_tensor)
else:
inputs = img_input
# 建立模型
# Create model.
model = Model(inputs, x, name='vgg16')
# 載入權重
# load weights
if weights == 'imagenet':
if include_top:
weights_path = get_file('vgg16_weights_tf_dim_ordering_tf_kernels.h5',
WEIGHTS_PATH,
cache_subdir='models')
else:
weights_path = get_file('vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5',
WEIGHTS_PATH_NO_TOP,
cache_subdir='models')
model.load_weights(weights_path)
if K.backend() == 'theano':
layer_utils.convert_all_kernels_in_model(model)
if K.image_data_format() == 'channels_first':
if include_top:
maxpool = model.get_layer(name='block5_pool')
shape = maxpool.output_shape[1:]
dense = model.get_layer(name='fc1')
layer_utils.convert_dense_weights_data_format(dense, shape, 'channels_first')
if K.backend() == 'tensorflow':
warnings.warn('You are using the TensorFlow backend, yet you '
'are using the Theano '
'image data format convention '
'(`image_data_format="channels_first"`). '
'For best performance, set '
'`image_data_format="channels_last"` in '
'your Keras config '
'at ~/.keras/keras.json.')
return model
if __name__ == '__main__':
model = VGG16(include_top=True, weights='imagenet')
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print('Input image shape:', x.shape)
preds = model.predict(x)
print('Predicted:', decode_predictions(preds))
# decode_predictions 輸出5個最高概率:(類名, 語義概念, 預測概率)
1,將模型下載到本地,不必每次從網站進行載入
當模型下載好了,就可以修改以下內容:
WEIGHTS_PATH = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.1/'
'vgg19_weights_tf_dim_ordering_tf_kernels.h5')
WEIGHTS_PATH_NO_TOP = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.1/'
'vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5')
# Load weights.
if weights == 'imagenet':
if include_top:
weights_path = keras_utils.get_file(
'vgg19_weights_tf_dim_ordering_tf_kernels.h5',
WEIGHTS_PATH,
cache_subdir='models',
file_hash='cbe5617147190e668d6c5d5026f83318')
else:
weights_path = keras_utils.get_file(
'vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5',
WEIGHTS_PATH_NO_TOP,
cache_subdir='models',
file_hash='253f8cb515780f3b799900260a226db6')
model.load_weights(weights_path)
if backend.backend() == 'theano':
keras_utils.convert_all_kernels_in_model(model)
elif weights is not None:
model.load_weights(weights)
2,幾個layer中的新用法
from keras.applications.imagenet_utils import decode_predictions decode_predictions 輸出5個最高概率:(類名, 語義概念, 預測概率) decode_predictions(y_pred) from keras.applications.imagenet_utils import preprocess_input 預處理 影象編碼服從規定,譬如,RGB,GBR這一類的,preprocess_input(x) from keras.applications.imagenet_utils import _obtain_input_shape 確定適當的輸入形狀,相當於opencv中的read.img,將影象變為陣列
- (1)decode_predictions用在最後輸出結果上,比較好用【print(‘Predicted:’, decode_predictions(preds))】;
- (2)preprocess_input,改變編碼,【preprocess_input(x)】;
- (3)_obtain_input_shape
3,當inclide_top=True 時
fc_model = VGG16(include_top=True) notop_model = VGG16(include_top=False)
當使用VGG16做 fine-tuning 的時候,得到的 notop_model 就是沒有全連線層的模型,然後再去新增自己的層。
當是健全的網路結構的時候,fc_model需要新增以下的內容以補全網路結構:
x = Flatten(name='flatten')(x) x = Dense(4096, activation='relu', name='fc1')(x) x = Dense(4096, activation='relu', name='fc2')(x) x = Dense(classes, activation='softmax', name='predictions')(x)
pool層之後接一個 flatten層,修改資料格式,然後接兩個 dense層,最後有softmax的dense層。
4,如果輸入的資料格式是 channels_first
其實我都預設是使用TensorFlow後端,所以資料格式一般是 channels_last,但是如果input格式是“channels_first”,fc_model 還需要修改一下格式,因為VGG16原始碼是以 “channels_last”定義的,所以需要轉換一下輸出格式,
maxpool = model.get_layer(name='block5_pool') # model.get_layer()依據層名或下標獲得層物件 shape = maxpool.output_shape[1:] # 獲取block5_pool層輸出的資料格式 dense = model.get_layer(name='fc1') layer_utils.convert_dense_weights_data_format(dense, shape, 'channels_first')
其中layer_utils.convert_dense_weights_data_format的作用很特殊,官方文件中沒有說明,本質上用來修改資料格式,因為層中有 Flatten層把資料格式換了,所以需要修改一下。
5.2 序列式
本節節選自Keras中文文件《CNN眼中的世界:利用Keras解釋CNN的濾波器》(https://keras-cn.readthedocs.io/en/latest/blog/cnn_see_world/)
已訓練好VGG16和VGG19模型的權重:
- 國外:https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
- 國內:http://files.heuritech.com/weights/vgg16_weights.h5
前面是VGG16架構的函式式模型的結構,那麼在官方文件這個案例中,也有VGG16架構的序列式,都拿來比對一下比較好。
首先我們在Keras中定義 VGG 網路的結構
from keras.models import Sequential from keras.layers import Convolution2D, ZeroPadding2D, MaxPooling2D img_width, img_height = 128, 128 # build the VGG16 network model = Sequential() model.add(ZeroPadding2D((1, 1), batch_input_shape=(1, 3, img_width, img_height))) first_layer = model.layers[-1] # this is a placeholder tensor that will contain our generated images input_img = first_layer.input # build the rest of the network model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_1')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(64, 3, 3, activation='relu', name='conv1_2')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_1')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(128, 3, 3, activation='relu', name='conv2_2')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_1')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_2')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation='relu', name='conv3_3')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_1')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_2')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu', name='conv4_3')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_1')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_2')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu', name='conv5_3')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) # get the symbolic outputs of each "key" layer (we gave them unique names). layer_dict = dict([(layer.name, layer) for layer in model.layers])
從使用 Convolution2D 來看,是比較早的版本寫的。
Sequential模型如何部分layer載入權重
下面我們將預訓練好的權過載入模型,一般而言我們可以通過 Model.load_weights()載入,但這種辦法是載入全部的權重,並不適用。
之前所看到的 no_top 模型就是用來應付此時的,這裡我們只載入一部分引數,用的時 set_weights() 函式,所以我們需要手工載入:
import h5py
weights_path = '.../vgg16_weights.h5'
f = h5py.File(weights_path)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
但是 ,載入的.h5模型,沒有屬性nb_layers,會報錯,如下:

6,使用預訓練模型Mobilenet網路訓練
6.1 匯入預訓練權重與網路框架
首先下載模型:https://github.com/fchollet/deep-learning-models/releases
當然也可以不下載,直接匯入即可,我下載下來為了方便快捷。下載後則需要修改部分原始碼。
WEIGHTS_PATH = '/data/mobilenet_5_0_224_tf.h5' WEIGHTS_PATH_NO_TOP = '/data/mobilenet_5_0_224_tf_no_top.h5' from keras.applications.mobilenet import MobileNet model = MobileNet(include_top=False, weights='imagenet')
其中 WEIGHTS_PATH_NO_TOP 就是去掉了全連線層,可以用它直接提取 bottleneck的特徵。
6.2 提取圖片的 bottleneck特徵
我們仍然採取上一篇文章中使用的資料,如果需要的話,可以去上一篇文章中的連線去找。
我的Keras使用總結(3)——利用bottleneck features進行微調預訓練模型VGG16
只不過這次嘗試使用mobilenet的預訓練模型提取圖片特徵,而不是VGG模型,我想看看Mobilenet的效果如何,順便看看自己掌握了沒有。

其實程式碼和上一節的大同小異,只不過這次我使用的更加嫻熟了,而且有些引數的意思也更加明確了,而且有些引數還是不要寫死的好,具體可以參考我的程式碼。
完整程式碼如下:
from keras.applications.mobilenet import MobileNet
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import os
import keras
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2'
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config))
def save_bottleneck_features():
model = MobileNet(include_top=False, weights='imagenet', input_shape=(150, 150, 3))
print('load model ok')
datagen = ImageDataGenerator(rescale=1. / 255)
# train set image generator
train_generator = datagen.flow_from_directory(
'/data/lebron/data/mytrain',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None,
shuffle=False
)
# test set image generator
test_generator = datagen.flow_from_directory(
'/data/lebron/data/mytest',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None,
shuffle=False
)
# load weight
model.load_weights(WEIGHTS_PATH_NO_TOP)
print('load weight ok')
# get bottleneck feature
bottleneck_features_train = model.predict_generator(train_generator, 10)
np.save(save_train_path, bottleneck_features_train)
bottleneck_features_validation = model.predict_generator(test_generator, 2)
np.save(save_test_path, bottleneck_features_validation)
def train_fine_tune():
# load bottleneck features
train_data = np.load(save_train_path)
train_labels = np.array(
[0] * 100 + [1] * 100 + [2] * 100 + [3] * 100 + [4] * 100
)
validation_data = np.load(save_test_path)
validation_labels = np.array(
[0] * 20 + [1] * 20 + [2] * 20 + [3] * 20 + [4] * 20
)
# set labels
train_labels = keras.utils.to_categorical(train_labels, 5)
validation_labels = keras.utils.to_categorical(validation_labels, 5)
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(5, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(train_data, train_labels,
nb_epoch=500, batch_size=25,
validation_data=(validation_data, validation_labels))
if __name__ == '__main__':
WEIGHTS_PATH = '/data/model/mobilenet_1_0_224_tf.h5'
WEIGHTS_PATH_NO_TOP = '/data/model/mobilenet_1_0_224_tf_no_top.h5'
save_train_path = '/data/bottleneck_features_train.npy'
save_test_path = '/data/bottleneck_features_validation.npy'
batch_size = 50
save_bottleneck_features()
train_data = np.load(save_train_path)
validation_data = np.load(save_test_path)
print(train_data.shape, validation_data.shape)
train_fine_tune()
print('game over')
訓練的結果就不展示了,這裡說一下準確率是百分之八十,loss有點高,降不下來,我會再學習研究