
G1垃圾回收器
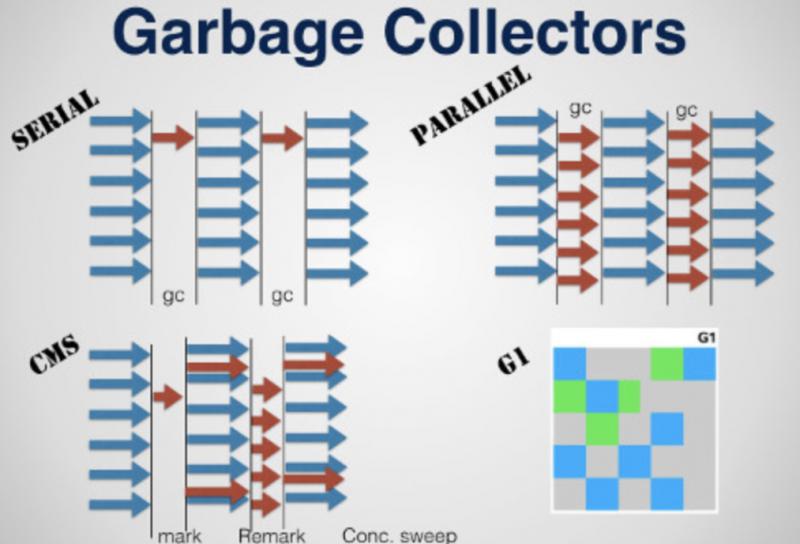
垃圾回收器的發展歷程
背景
01、G1解決的問題
G1垃圾回收器是04年正式提出,12開始正式支援,在17年作為JDK9預設的垃圾處理器。
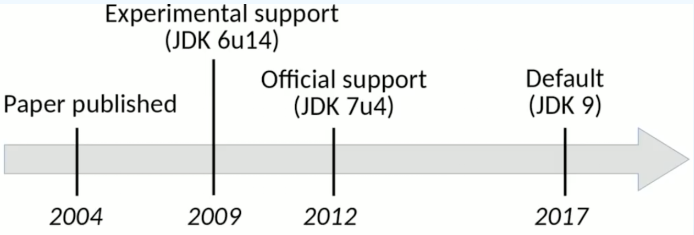
在04年的時候,java程式堆的記憶體越來越大,從而導致程式中可存活的活物件越來越多,因此GC的STW時間越來越長。這是G1要解決的主要問題:STW帶來的停頓時間太長了。
CMS在此之前效率也很高,但活物件數量一多,STW時間也很長。而且CMS無法解決記憶體碎片化的問題。
G1還解決的問題是:CMS在GC後,無法compact記憶體。
02、G1達成的目標
(1)減少由於STW而帶來的程式延遲時間,做到偽實時、低延時、可設定目標;
可設定目標是指能夠設定GC
STW停頓的時間,G1會盡量達成目的,但不一定達成。
-XX:MaxGCPauseMillis=N
預設情況下是250毫秒
(2)解決CMS在GC後,無法壓縮程式記憶體的問題;
(3)在JDK9之後,預設的垃圾處理器就是G1;它適用於堆記憶體較大的情況下(>4~6G);
G1垃圾回收器
一、G1記憶體佈局
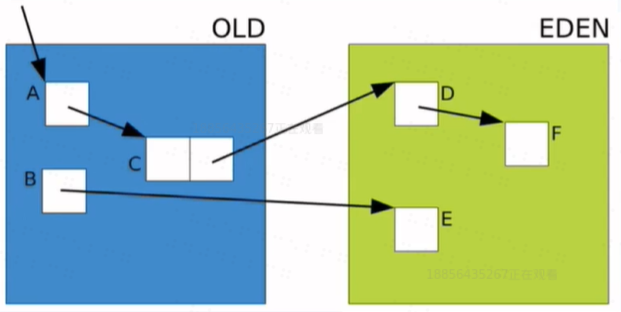
G1不再遵循之前的堆中物件的分代排列,而是將堆分成若干個等大的區域。
而是變成:
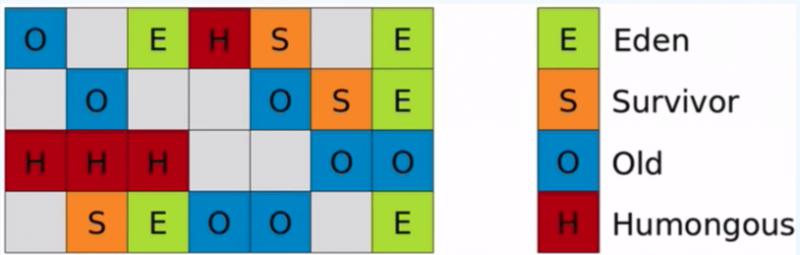
預設是分成
2048個區域,-XX:G1HeapRegionSize=N 2048
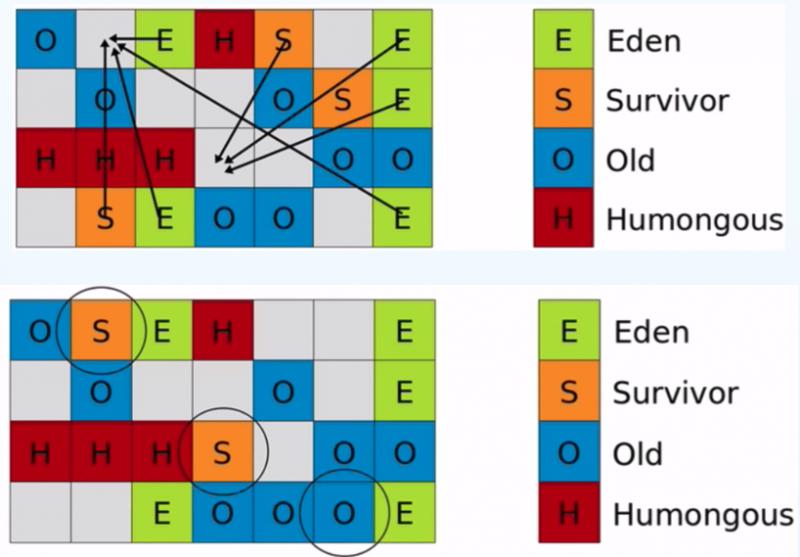
Humongous:當你分配的一個物件超過一半區域的大小時,這個物件就會被放入這個區域。這個區域屬於老年代區域。
二、G1的介紹
G1垃圾回收器不再回收整個堆,而是選擇一個Collection Set(CS)。而且每次GC時,會估計每個Region中的垃圾比例,優先回收垃圾多的Region。這就為什麼被叫做Garbage First演算法。這也是為什麼G1可以控制STW停頓時間的原因。
G1含有三種GC演算法:
Full young GC:年輕代GC演算法:STW、Parallel、Copying- 老年代
GC演算法:Mostly-concurrent marking、Incremental compaction Mixed GC:混合GC
三、G1引來的問題
問題描述
G1將年輕代、老年代區域劃分為許多個小區域,增加在GC
- 老年代物件可能持有年代代的引用(跨代引用)
- 不同的
Region間的互相引用
假設在Full young GC時,某個年輕代Region物件可能被老年代的某個物件引用,那麼我在回收這個年輕代Region時,怎麼知道這裡面的物件是否被其他Region、老年代引用呢?
問題解決
Remembered Set、Card Table
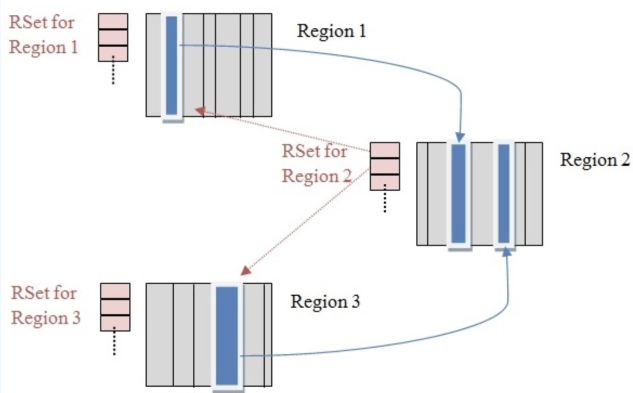
1、CardTable
每個Region中分為很多區域,每個區域我們成為CardTable,對應的就是上述藍色區域;每個CardTable有多個entry組成。當對應的記憶體空間發生改變時,就會標記為dirty。
2、RememberedSet
當Region1的CardTable引用Region2的CardTable時,Region2的RememberedSet就會記錄對應CardTable中的entry,可以根據其找到對應的記憶體區域。
3、解析
當某個記憶體對應進行賦值是,就是物件的set方法,我們可以在這種方法上新增dirty的描述。
這其實就是典型的時間換空間的做法:用額外的空間維護引用資訊,這就是佔用5~10%的過多記憶體佔用。
解決方法的實現
1、Write Barrier介紹
Write barrier是一種向JVM注入的一小段程式碼,用於記錄指標變化。比如說object.field = <reference>。
在JVM開始更新指標時,就經過以下幾步:
- 標記
Card為Dirty - 將
Card存入Dirty Card Queue佇列中
這裡有一個問題:為什麼要放在佇列裡,而不是直接去更新RememberedSet呢?
這是因為JVM執行可能會有多個執行緒並行的修改RememberedSet,這樣就需要花費額外的時間來解決多執行緒同步問題。而這種更新引用是頻繁的,所以這種額外時間是無法忍受的。
2、Dirty Card Queue
這個佇列有白、綠、黃、紅四個顏色,表示應用執行緒往這個佇列放任務的狀態。
-
White
表示沒有應用執行緒往佇列裡放任務,什麼事都不用幹。 -
Green
此時Refinement執行緒開始被啟用,開始更新RS。-XX:G1ConcRefinementGreenZone=N -
Yellow
此時全部的Refinement執行緒都被啟用,來更新RS。-XX:G1ConcRefinementYellowZone=N -
Red
這個時候,應用執行緒也開始參與排空佇列的工作。-XX:G1ConcRefinementRedZone=N
四、GC演算法的過程
1、Fully young GC
GC的過程
(1)STW
此時會暫停所有堆中的物件,將部分Region拷貝到指定區域。
(2)構建Collection Set
fully young GC就是選取所有的Eden和Survivor。
(3)掃描GC Roots
(4)更新RememberedSet
排空Dirty Card Queue
(5)Process RS
根據RS找到要GC的物件被哪些物件引用了。
(6)物件拷貝
survivor區域物件的調整。
(7)Reference Processing
額外會做的事
G1記錄每個階段的時間,用於後期自動調優。比如說會記錄Eden、Survivor的數量和GC時間,後期會根據我們之前設定的暫停目標來自動調整Region數量。
但是我們設定暫停目標越短,年輕代的Region數量就越少。但這可能會導致Fully young GC頻繁發生。
2、Old GC
當堆用量達到一定程度時,就會觸發old GC。可以通過以下引數進行設定:
-XX:InitatingHeapOccpancyPercent=45
old GC有一個很大特點就是併發進行的。但它是如何在堆中不斷變化的情況下,確定哪些是要清理的垃圾物件呢?
三色標記演算法
這種演算法實現了在不暫停應用執行緒的情況下進行併發標記,標記過程過如下:
(1)將GC Root物件記錄為黑色,其直接引用物件記錄為灰色,並將這些灰色物件放入一個佇列中
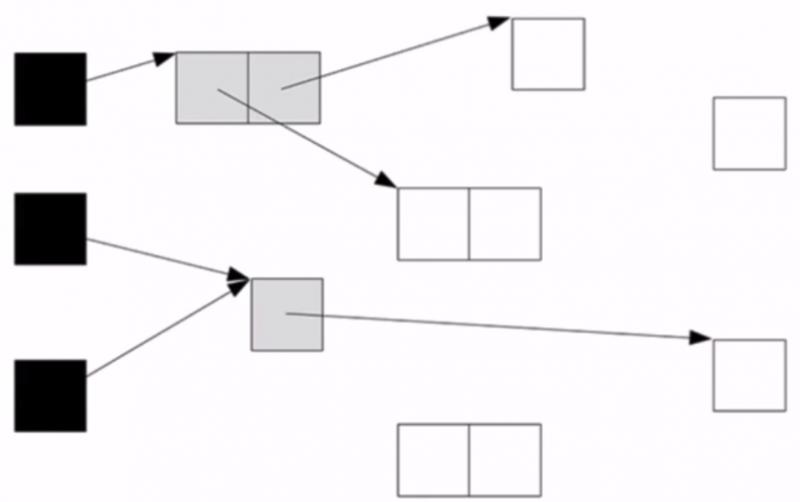
(2)從佇列取出物件,將其標為黑色,將其引用物件記錄為灰色,再放入佇列中
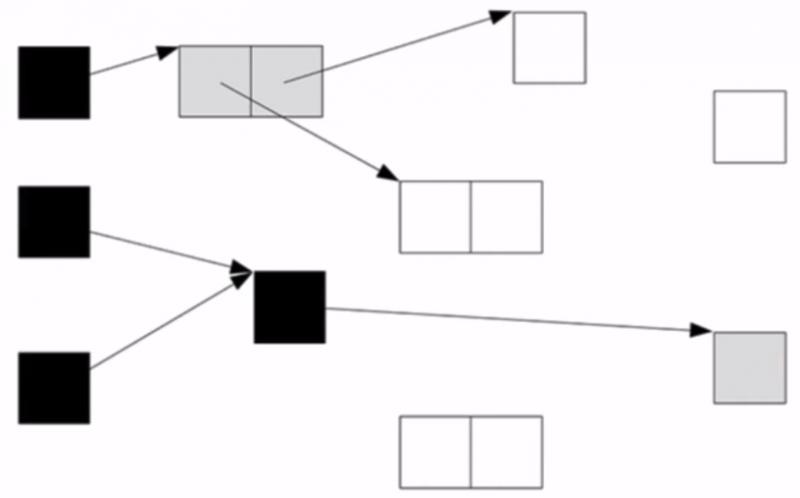
(3)直到佇列中無物件為止
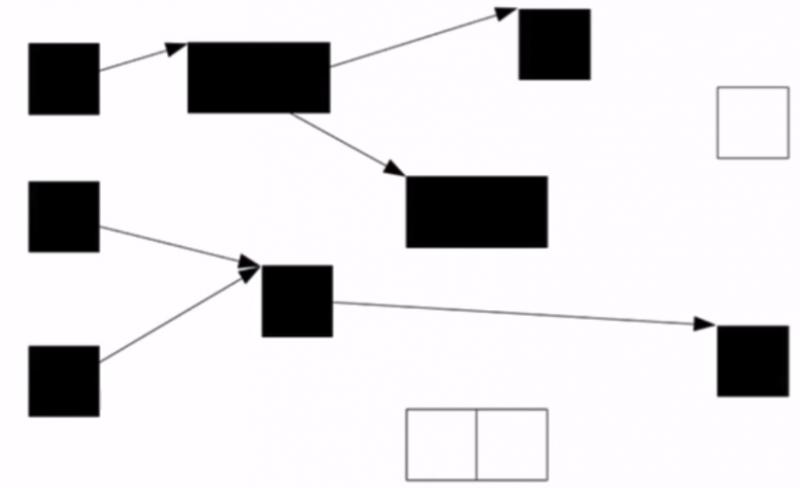
三色標記演算法的缺點:Lost Object Problem
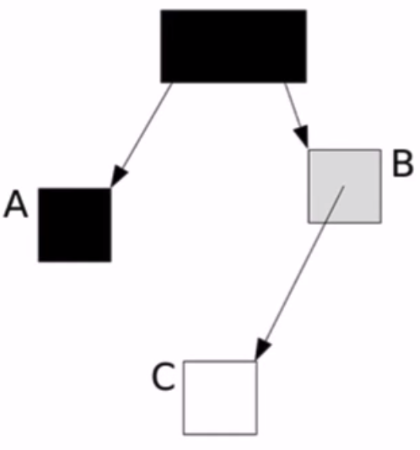
三色標記演算法並沒有完全將所有的活物件都標記出來,這就是Lost Object Problem問題。比如說:
(1)剛開始時
(2)在即將描述將C標為灰色的一剎那
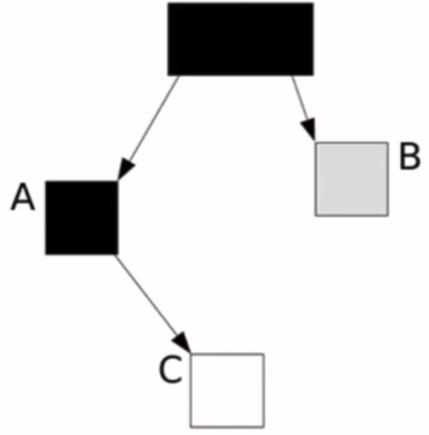
此時,C依然是活物件,但是已經無法將其標記了。
(3)結果
Lost Object Problem的解決
這種解決辦法還是通過Write barrier技術來解決。當B.c=null,也就是C指標被刪除時,G1還是被認為活物件。
那如果
C是新生物件呢?這是老年代GC
Old GC過程
(1)STW
老年代GC會在這個時候,進行一次Fully young GC
(2)恢復應用執行緒
(3)使用三色標記演算法併發標記(init marking)
(4)STW
這時候會有一個Remark階段,主要是解決SATB、Reference processing
還會有一個Cleanup階段,用於回收全為空的區
(5)恢復應用執行緒
3、Mixed GC
我們直到CMS最大的缺點就是無法進行壓縮操作,而G1就通過Mixed GC解決了這個問題。
Mixed GC沒有固定觸發條件,他是根據Fully young GC收集的資訊和我們配置的時間來決定,是否觸發Mixed GC。它會根據暫停目標,來優先選擇垃圾最多的Old Region來執行。
Mixed GC會選擇若干個Region進行,預設是選擇1/8的Old Region、Eden Region、Survivor Region。
Mixed GC的過程跟Fully young GC的過程相同,都是:STW、Parallel、Copying。
原部落格地址