
052.Kubernetes叢集管理-故障排錯指南
阿新 • • 發佈:2020-04-12
一 故障指南
1.1 常見問題排障
為了跟蹤和發現在Kubernetes叢集中執行的容器應用出現的問題,常用如下查錯方法:- 檢視Kubernetes物件的當前執行時資訊,特別是與物件關聯的Event事件。這些事件記錄了相關主題、發生時間、最近發生時間、發生次數及事件原因等,對排查故障非常有價值。此外,通過檢視物件的執行時資料,還可以發現引數錯誤、關聯錯誤、狀態異常等明顯問題。由於在Kubernetes中多種物件相互關聯,因此這一步可能會涉及多個相關物件的排查問題。
- 對於服務、容器方面的問題,可能需要深入容器內部進行故障診斷,此時可以通過檢視容器的執行日誌來定位具體問題。
- 對於某些複雜問題,例如Pod排程這種全域性性的問題,可能需要結合叢集中每個節點上的Kubernetes服務日誌來排查。比如蒐集Master上的kube-apiserver、kube-schedule、kube-controler-manager服務日誌,以及各個Node上的kubelet、kube-proxy服務日誌,通過綜合判斷各種資訊,就能找到問題的成因並解決問題。
二 常見措施
2.1 檢視Event
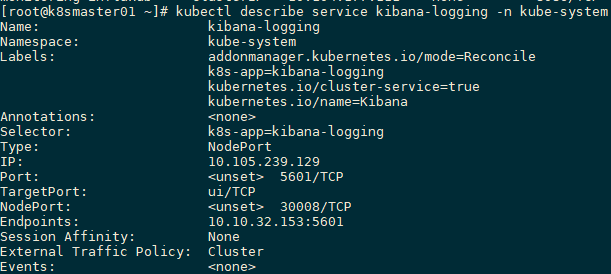
[root@k8smaster01 ~]# kubectl describe pod kibana-logging-7dcbbd96d6-tsr82 -n kube-system 解讀:通過kubectl describe pod命令,可以顯示Pod建立時的配置定義、狀態等資訊,還可以顯示與該Pod相關的最近的Event事件,事件資訊對於查錯非常有用。如果某個Pod一直處於Pending狀態,可以通過kubectl describe命令瞭解具體原因。
通常,從Event事件中獲知Pod失敗的原因可能有以下幾種:
解讀:通過kubectl describe pod命令,可以顯示Pod建立時的配置定義、狀態等資訊,還可以顯示與該Pod相關的最近的Event事件,事件資訊對於查錯非常有用。如果某個Pod一直處於Pending狀態,可以通過kubectl describe命令瞭解具體原因。
通常,從Event事件中獲知Pod失敗的原因可能有以下幾種:
- 沒有可用的Node以供排程。
- 開啟了資源配額管理, 但在當前排程的目標節點上資源不足。
- 映象下載失敗。
2.2 檢視日誌
[root@k8smaster01 ~]# kubectl logs elasticsearch-logging-0 -n kube-system [root@k8smaster01 ~]# kubectl logs elasticsearch-logging-0 -c elasticsearch-logging -n kube-system 解讀:如上檢視日誌等同於在Pod的宿主機上執行docker logs <container_id>。容器中應用程式生成的日誌與容器的生命週期是一致的,所以在容 器被銷燬之後,容器內部的檔案也會被丟棄,包括日誌等。如果需要保留容器內應用程式生成的日誌,則可以使用掛載的Volume將容器內應用程式生成的日誌儲存到宿主機,還可以通過一些工具如Fluentd、Elasticsearch等對日誌進行採集。2.3 檢視Kubernetes服務日誌
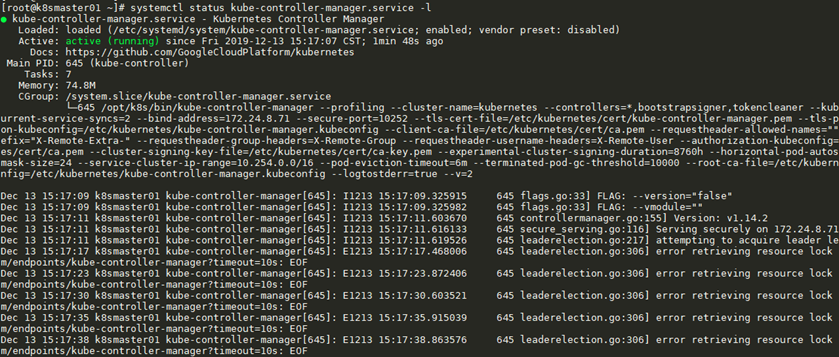 [root@k8smaster01 ~]# journalctl -u kube-controller-manager.service
[root@k8smaster01 ~]# journalctl -u kube-controller-manager.service
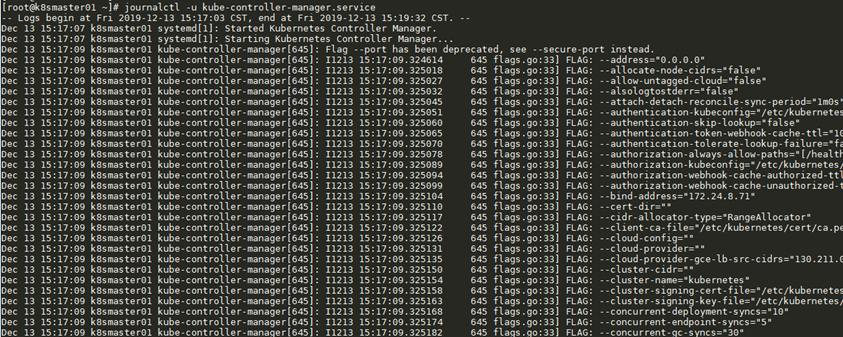 如果不使用systemd系統接管Kubernetes服務的標準輸出(如使用kubeadm部署的Kubernetes),則也可以通過日誌相關的啟動引數來指定日誌的存放目錄。
如果不使用systemd系統接管Kubernetes服務的標準輸出(如使用kubeadm部署的Kubernetes),則也可以通過日誌相關的啟動引數來指定日誌的存放目錄。
- --logtostderr=false:不輸出到stderr。
- --log-dir=/var/log/kubernetes:日誌的存放目錄。
- --alsologtostderr=false:將其設定為true時,表示將日誌同時輸出到檔案和stderr。
- --v=0:glog的日誌級別。
- --vmodule=gfs*=2,test*=4:glog基於模組的詳細日誌級別。
- kube-controller-manager.ERROR;
- kube-controller-manager.INFO;
- kube-controller-manager.WARNING;
- kube-controller-manager.kubernetesmaster.unknownuser.log.ERROR.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.INFO.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.WARNING.20150930-173939.9847。
2.4 Kubernetes異常排查思路
通常可以從WARNING和ERROR級別的日誌中就能找到問題的成因,但有時還需要排查INFO級別的日誌甚至DEBUG級別的詳細日誌。 此外,etcd服務也屬於Kubernetes叢集的重要組成部分,etcd的日誌同樣重要。如果某個Kubernetes物件存在問題,則可以用這個物件的名字作為關鍵字搜尋Kubernetes的日誌來發現和解決問題。 通常Kubernetes主要是與Pod物件相關的問題,比如無法建立Pod、Pod啟動後就停止或者Pod副本無法增加,等等。此時,可以先確定Pod在哪個節點上,然後登入這個節點,從kubelet的日誌中查詢該Pod的完整日誌,然後進行問題排查。 對於與Pod擴容相關或者與RC相關的問題,則很可能在kube-controller-manager及kube-scheduler的日誌中找出問題的關鍵點。 另外,若kube-proxy意外停止,Pod的狀態也是正常的,但會導致某些服務訪問異常。這些錯誤通常與每個節點上的kube-proxy服務有著密切的關係。遇到這些問題時,首先要排查kube-proxy服務的日誌,同時排查防火牆服務,要特別留意在防火牆中是否有人為新增的可疑規則。三 常見Kubernetes問題
3.1 無法pull映象
由於無法下載pause映象導致Pod一直處於Pending狀態,可通過kubectl get pods命令檢視。 解決方法如下。- 如果伺服器可以訪問Internet,並且不希望使用HTTPS的安全機制來訪問gcr.io,則可以在Docker Daemon的啟動引數中加上--insecure-registry gcr.io,來表示可以匿名下載。
- 如果Kubernetes叢集在內網環境中無法訪問gcr.io網站,則可以先通過一臺能夠訪問gcr.io的機器下載pause映象,將pause映象匯出後,再匯入內網的Docker私有映象庫,並在kubelet的啟動引數中加上--pod_infra_container_image,配置為:--pod_infra_container_image=<docker_registry_ip>:<port>/pause:3.1,之後重新建立redis-master即可正確啟動Pod。
3.2 一直RESTARTS
建立一個RC之後,通過kubectl get pods命令檢視Pod,發現Pod一會兒是Running狀態,一會兒是ExitCode:0狀態,在READY列中始終無法變成1/1,而且RESTARTS(重啟的數量)的數量不斷增加。這通常是因為容器的啟動命令不能保持在前臺執行。 在Kubernetes中根據RC定義建立Pod,之後啟動容器。在容器的啟動命令執行完成時,認為該容器的執行已經結束,並且是成功結束(ExitCode=0)的。根據Pod的預設重啟策略定義(RestartPolicy=Always),RC將啟動這個容器。新的容器在執行啟動命令後仍然會成功結束,之後RC會再次重啟該容器,如此往復。其解決方法為將Docker映象的啟動命令設定為一個前臺執行的命令。3.3 通過服務名無法訪問
在Kubernetes叢集中應儘量使用服務名訪問正在執行的微服務,但有時會訪問失敗。由於服務涉及服務名的DNS域名解析、kube-proxy元件的負載分發、後端Pod列表的狀態等,所以可通過以下幾方面排查問題。- 檢視Service的後端Endpoint是否正常
- Service的LabelSelector與Pod的Label不匹配;
- 後端Pod一直沒有達到Ready狀態(通過kubectlgetpods進一步檢視Pod的狀態);
- Service的targetPort埠號與Pod的containerPort不一致等。
- 檢視Service的名稱能否被正確解析為ClusterIP地址
- 檢視kube-proxy的轉發規則是否正確