
Java中的資料結構-HashMap
Java資料結構-HashMap
目錄
- Java資料結構-HashMap
- 1. HashMap
- 1.1 HashMap介紹
- 1.1.1 HashMap介紹
- 1.1.2 HashMap繼承圖
- 1.2 HashMap 組成結構
- 1.2.1 Hashmap底層資料結構
- 1.1 HashMap介紹
- 2.HashMap原始碼解析
- 2.1 HashMap屬性原始碼解析
- 2.1.1 HashMap中的靜態常量
- 2.1.2 HashMap中的屬性
- 2.1.3 HashMap中的儲存結點
- 2.1.4 Hash表
- 2.2 HashMap資料的改變
- 2.2.1 構造方法分析
- 2.2.2 鍵值對的新增 put方法分析
- 2.2.3 hash表table擴容 resize方法分析
- 2.2.4 刪除鍵值對 remove方法分析
- 2.2.5 替換結點值 replace方法分析
- 2.2.6 K 對映 compute方法
- 2.2.7 K-V 對映 merge方法
- 2.2.8 遍歷消費 forEach方法
- 2.2.9 清空 clear方法
- 2.3 獲取HashMap中的資訊
- 2.3.1 獲取值 get方法分析
- 2.3.2 檢查是否包含key,value containsXX方法
- 2.3.3 檢查大小
- 2.4 其它方法
- 2.4.1 序列化與反序列化
- 2.1 HashMap屬性原始碼解析
- 3. 總結
- 3.1.1 HashMap中的其他類與方法
- 1. HashMap
1. HashMap
1.1 HashMap介紹
1.1.1 HashMap介紹
- HashMap是一個用於儲存Key-Value鍵值對的集合,每一個鍵值對也叫做Entry,有著key與value兩個基本屬性以及有其他的包含其他結點位置資訊的屬性
- 通過HashMap我們可以儲存鍵值對,並且可以在較短的時間複雜度內,
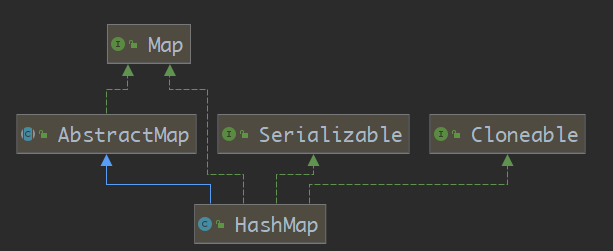
1.1.2 HashMap繼承圖
-
HashMap通過繼承
AbstractMap實現了Map介面,且本身也實現了Map介面-
在介面實現關係上來看為多餘操作
-
但有一點要注意,在使用反射獲取實現介面時,如果不是顯示實現某介面而是通過繼承來實現該介面,則不會獲取該介面型別,這一點在使用動態代理時要注意
HashMap.class.getInterfaces()//[interface java.util.Map, interface java.lang.Cloneable, interface java.io.Serializable]- HashMap 通過顯示實現Map介面,從而在通過反射時能夠獲取到Map介面
-
-
HashMap實現了
Serializable介面,可以通過java.io.ObjectStream進行序列化 -
HashMap實現了
Cloneable介面,實現了淺拷貝,通過以下程式碼可以證實:-
HashMap map = new HashMap(); map.put(1, "first"); HashMap copiedMap = (HashMap) map.clone(); System.out.println(copiedMap.get(1)==map.get(1));//true copiedMap.put(2, "second"); System.out.println(map);//{1=first}
-
1.2 HashMap 組成結構
1.2.1 Hashmap底層資料結構
- HashMap底層採用陣列+連結串列/紅黑樹的資料結構
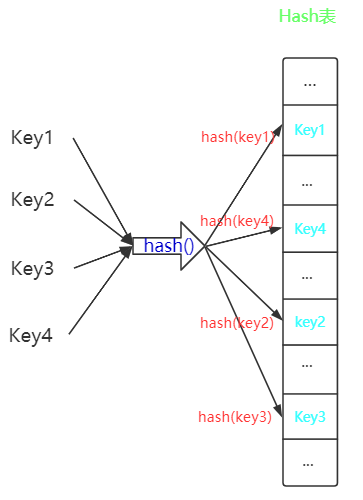
(1)雜湊表
-
雜湊表也成為散列表,它是根據關鍵字經過
hash()函式處理,將值對映到雜湊表上的某一個位置,以該位置作為關鍵字的儲存位置,無論存在哪,只需要進行一次hash計算,便可以找到該位置,整個查詢過程時間複雜度為\(O(1)\) -
HashMap 使用陣列作為雜湊表,來儲存Key的hash()資訊
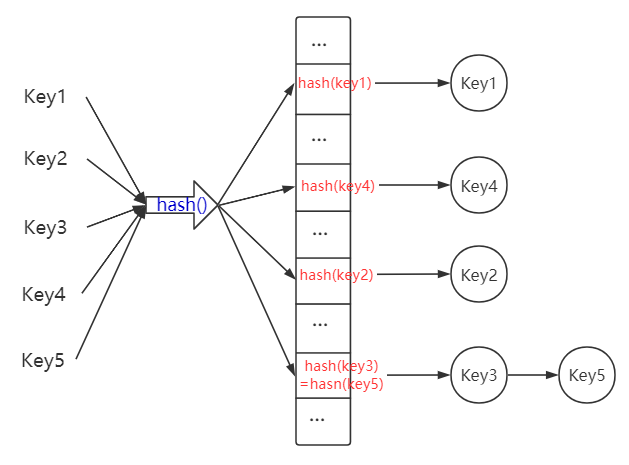
(2)連結串列
-
因為
hash()函式是將key值對映到有限的空間中,如果hash()函式碰撞性設計的不完善,或者雜湊表儲存的元素過多,必然會導致不同元素的hash值相同,即位置衝突,此時我們採用的方式一般有:- 使用連結串列,儲存不同元素但hash()函式處理值相同的元素,雜湊表對應位置儲存該連結串列的頭結點
- 擴大雜湊表陣列的大小,重新設計
hash()函式對映關係使元素分佈地更加均勻,降低碰撞機率
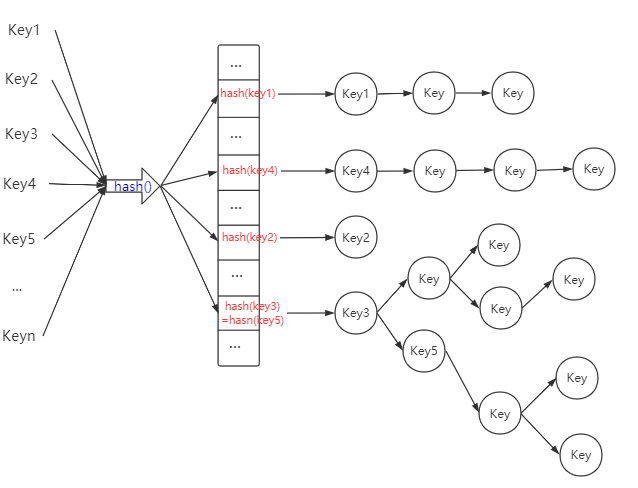
(3)紅黑樹
-
紅黑樹為一顆平衡二叉樹
-
當元素越來越多時,hash碰撞也會越來越嚴重,連結串列的長度會變得很大,此時如果我們想要查詢該連結串列的的某一個元素,其時間複雜度為\(O(n)\),必須採用一個閾值,當連結串列的長度達到該閾值時,便應該將連結串列轉化為一顆紅黑樹,從而將時間複雜度從\(O(n)\)降低為\(O(logn)\),從而改善Hash表的查詢效能
2.HashMap原始碼解析
2.1 HashMap屬性原始碼解析
2.1.1 HashMap中的靜態常量
(1)預設table長度
-
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//為16
(2)table長度的最大值
-
static final int MAXIMUM_CAPACITY = 1 << 30;
(3)預設負載因子
-
static final float DEFAULT_LOAD_FACTOR = 0.75f;- 負載因子 = 含有元素的桶個數/ 桶的總個數
- 實際上在HashMap中是傳入負載因子,來確定含有元素的桶個數,而這個數值為擴容閾值
- 可以這樣理解,負載因子的作用就是為了讓空桶保持不少於一個比例,降低hash碰撞機率
(4)樹化閾值-連結串列長度
-
static final int TREEIFY_THRESHOLD = 8;- 連結串列轉換為紅黑樹的條件之一為桶的連結串列長度達到8及以上
(5)樹化閾值-HashMap元素個數
-
static final int MIN_TREEIFY_CAPACITY = 64;- 連結串列轉換為紅黑樹的條件之二為HashMap中的元素達到64及以上
(6)樹降為連結串列的閾值
-
static final int UNTREEIFY_THRESHOLD = 6;- 當該桶的連結串列樹的結點數目低於該值時便會轉化為連結串列,以便避免不必要的平衡修復運算
2.1.2 HashMap中的屬性
(1)HashMap元素個數
-
transient int size;
(2)Hash表結構修改次數
-
transient int modCount;- 結構修改:插入或刪除元素等操作,改變了HashMap的結構(插入相同元素替換掉原來元素因為並沒有改變結構,所以不算修改)
(3)擴容閾值
-
int threshold;- 擴容閾值,當table中的元素達到閾值時,觸發擴容
threshold = loadFactor * capacity
(4)負載因子
-
final float loadFactor;
2.1.3 HashMap中的儲存結點
(1)靜態結點類原始碼
-
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; . . . 構造方法 . . . getter&&setter //重寫的hash()方法 public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } //重寫的equals方法 public final boolean equals(Object o) { //如果為該物件 if (o == this) return true; //如果是Map.Entry型別 if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; //如鍵,值equals方法都為真 if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } ...toString(){...} } -
結點Node類為實現了
Map.Entry介面的一個靜態內部類,主要包含:hash計算值:後面構造時用以儲存hashcode,避免每次重新計算key:鍵value:值next:指向下一個結點的引用:如果發生雜湊碰撞,使用鏈式結構儲存hash值相同的鍵值對
-
重寫的
hash()方法將key和value經Objects.hashCode(Object o)處理後進行與操作,使得hash()函式對映更加隨機均勻 -
重寫的
equals方法中只有傳入結點為自身結點或者key與value呼叫equals方法比較都為真時,結果才為真(主要用於後面查詢元素時的比較)
2.1.4 Hash表
(1)Hash表原始碼
-
Hash表定義原始碼:
transient Node<K,V>[] table; -
為了能夠通過確定計算的hashcod找到桶的位置,HashMap中底層採用Node<K,V>結點型別陣列作為桶
-
transient修飾在序列化時會被跳過
(2)確定桶的位置
- 當
put一個結點時,通過以下演算法來確定結點應該位於哪個桶index = (table.length - 1) & node.hash,也就是說位置完全取決於node.hash的後幾位(table.length-1的二進位制位數)
(3)長度的確定
-
hash表長度計算方法原始碼:
static final int tableSizeFor(int cap) { int n = cap; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }-
該方法的作用是,當初始化時,通過傳入capacity返回一個大於等於當前值cap的一個數字,並且這個數字一定是2的次方數
-
該方法不斷通過右移然後進行‘或’操作,可以將傳入的cap中的首非0位之後的0位填滿,變為
0..11...1的形式,即\(2^{n的二進位制位數+1}-1\)-
例:
cap = 10 n = 10 - 1 => 9 0b1001 | 0b0100 => 0b1101 0b1101 | 0b0011 => 0b1111 0b1111 | 0b0000 => 0b1111 = 15 return 15 + 1 = 16cap = 16 n = 16; 0b10000 | 0b01000 =>0b11000 0b11000 | 0b00110 =>0b11110 0b11110 | 0b00001 =>0b11111 return 31 + 1 = 32;
-
-
-
Hash表的長度必須為2的整數次冪
- 因為當陣列的長度為2的整數次冪時,table.length-1的二進位制位(11...1)(例如15:1111,7:111)
- 假設當前長度為16,其table.length-1 = 1111b,如果進來兩個元素的hash分別是(。。。0111 b)與(。。。0001 b)分別進行與操作,其位置結果不同;
- 如果當前長度為10,其table.length-1 = 1001b,上面兩個元素分別進行與操作結果相同(即該長度只需要傳入元素的hashcode的最低位元組的最高位與最低位相同即可(只比較了兩位))必然導致分配不均勻,而使用2的整數次冪-1可以保證進行與操作時,只有hashcode的位比較全部相同才會相同,提高了分散程度
(4)hash值的計算:hash(K key)
-
hash擾動函式原始碼:(實際上產生的就是
Node.hash,用於後面Node物件的構造)static final int hash(Object key) { int h;//h=0 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }-
如果key為null則hash值為0,位置計算結果也為0(從putVal方法的第一種情況可以看出),會替換掉
table[0]桶位的key為null的元素- 注意:table[0]可能儲存著其他計算出的hash值為0的元素,並不是只有一個(null:value)結點
-
當table長度比較小時,從前面位置演算法
index = (table.length-1)|node.hash()可以看出,如果不經處理,計算的index只取決於結點的hash的後幾位(table.length-1的二進位制長度),這樣會使不同元素的位置結果相同概率大大增加 -
h>>16的結果的高16位全為0,
(h = key.hashCode()) ^ (h >>> 16)就可以讓結果hash的高16位為key.hashCode()的高16位,使得高16位也參與hash值的計算,增加低16位的隨機性-
例:
h = key.hashCode() = 0b 0010 0101 1010 1100 0011 1111 0010 1110 0b 0010 0101 1010 1100 _ 0011 1111 0010 1110 ^ 0b 0000 0000 0000 0000 _ 0010 0101 1010 1100 (h>>>16) => 0010 0101 1010 1100 _ 0001 1010 1000 0010
-
hash擾動原理參考
-
2.2 HashMap資料的改變
2.2.1 構造方法分析
(1)HashMap(int initialCapacity, float loadFactor)
-
public HashMap(int initialCapacity, float loadFactor) { //前面都是校驗傳入引數是否合法,不合法丟擲 IllegalArgumentException //initialCapacity必須是大於0 ,最大值為 MAX_CAPACITY if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //loadFactor必須大於0且不是NaN if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " +loadFactor); this.loadFactor = loadFactor; //HashMap的擴容閾值通過以下方法取得 this.threshold = tableSizeFor(initialCapacity); }
(2)其它構造方法
-
其它構造方法原始碼
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // 0.75 //現在的擴容閾值thershold = 0 } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; //現在的擴容閾值thershold = 0 //呼叫putMapEntries,新增鍵值對s putMapEntries(m, false); }- 其它構造方法的屬性處了傳入引數屬性其它皆為預設屬性
-
putMapEntries方法原始碼:final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) { //獲取鍵值對map長度 int s = m.size(); if (s > 0) { //如果table沒有初始化,先計算一系列屬性再初始化 if (table == null) { // pre-size //計算初始的table長度 float ft = ((float)s / loadFactor) + 1.0F; //選取table長度與最大長度的最小值 int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY); if (t > threshold) threshold = tableSizeFor(t); } //如果map的長度大於擴容閾值,擴容table else if (s > threshold) resize(); //遍歷呼叫put方法新增鍵值對 for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) { K key = e.getKey(); V value = e.getValue(); putVal(hash(key), key, value, false, evict); } } }- 該方法實際上包含了HashMap屬性值的初始化操作與可能的擴容操作,當操作完成後,遍歷傳入的
m.entrySet(),依次插入鍵值對
- 該方法實際上包含了HashMap屬性值的初始化操作與可能的擴容操作,當操作完成後,遍歷傳入的
2.2.2 鍵值對的新增 put方法分析
(1)put(K key, V value)
-
原始碼:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }套娃方法,該方法首先計算呼叫
hash()方法計算hash值(並不是key.hashCode()),呼叫putVal以替換的方式進行結點插入操作,返回之前結點的value
(2)putIfAbsent
-
原始碼:
@Override public V putIfAbsent(K key, V value) { return putVal(hash(key), key, value, true, true); }套娃方法,計算hash值,呼叫
putVal以非替換的方式進行結點插入操作,返回之前結點的value
(3)putAll
-
原始碼:
public void putAll(Map<? extends K, ? extends V> m) { putMapEntries(m, true); }套娃方法,呼叫
putMapEntries(m, true)實現新增傳入的map的所有的鍵值對
(3)putVal
-
putVal原始碼
/** * Implements Map.put and related methods. * * @param hash hash for key -key的hash值 * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value -true:如果該元素已經存在與HashMap中就不操作了 * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { //tab:引用當前hashMap的散列表 //p:表示當前散列表的元素 //n:表示散列表陣列的長度 //i:表示路由定址結果 Node<K,V>[] tab; Node<K,V> p; int n, i; //延遲初始化邏輯,第一次呼叫putVal時會初始化hashMap物件中的最耗費記憶體的散列表 //這樣會防止new出來HashMap物件之後卻不存資料,導致空間浪費的情況 if ((tab = table) == null || (n = tab.length) == 0)//此處進行tab與n的賦值 n = (tab = resize()).length; //情形1:定址找到的桶位,賦值給p,如果p剛好是 null,這個時候,直接將當前k-v=>node 扔進去就可以了 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //e:臨時的Node元素,不為null的話,找到了一個與當前要插入的key-value一致的key的元素 //k:表示臨時的一個key Node<K,V> e; K k; //情形2:表示桶位中的該元素,與你當前插入的元素的key完全一致,表示後續需要進行替換操作 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //情形3:如果改桶為儲存的結點與插入結點的hash不同或者key不一致嗎,且為紅黑樹的樹根結點,在需要插入結點到紅黑樹中 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //情形4:連結串列的情況,而且連結串列的頭元素與我們要插入的key不一致。 else { for (int binCount = 0; ; ++binCount) { //條件成立的話,說明迭代到最後一個元素了,也沒找到一個與你要插入的key一致的node,說明需要加入到當前連結串列的末尾 if ((e = p.next) == null) { //連結串列末尾新增新的結點 p.next = newNode(hash, key, value, null); //條件成立的話,說明當前連結串列的長度,達到樹化標準了,需要進行樹化 //TREEIFY_THRESHOLD - 1 = 7 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //樹化操作 treeifyBin(tab, hash); break; } //條件成立的話,說明找到了相同key的node元素,需要進行替換操作 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //e不等於null,條件成立說明,找到了一個與你插入元素key完全一致的資料,需要進行替換 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); //返回舊元素 return oldValue; } } //modCount:表示散列表結構被修改的次數,替換Node元素的value不計數 ++modCount; //插入新元素,size自增,如果自增後的值大於擴容閾值,則觸發擴容。 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } -
整個方法的流程:
-
傳入的引數
int hash:上層呼叫者經過hash擾動後的hash值K key,V vey:鍵,值boolean onlyIfAbsent:如果為true,則對相同的元素不進行替換處理boolean evict:沒用,後面並沒有做什麼工作
-
方法執行邏輯:
- 如果table為null或者table長度為0,則進行擴容方法,並取得表長
- 如果經過位置計算的到的table相應位置的元素
p為null- new新的結點並賦值到table對應位置
- 否則:先建立臨時
Node e,K k- 如果經過位置計算得到的元素
p.hash值與傳入的hash值相同,並且p.key==key或者說key通過equals方法比較為true- 儲存p的引用(
e=p),下一步進行結點的值的替換
- 儲存p的引用(
- 否則,如果:
p為紅黑樹結點- 呼叫紅黑樹的結點插入操作
- 否則:該情形為連結串列,從頭結點
p開始遍歷,binCount=0,之後每次迴圈+1- 如果:已經到連結串列末尾(
(e=p.next)==null,e為當前結點p的下一個結點),說明並沒有找到該元素,new 新的結點插入到連結串列尾部(p.next = new Node(...))- 遍歷的長度(該連結串列長度與樹化閾值比較(
binCount >= TREEIFY_THRESHOLD - 1)),即當binCount到達7時,即插入操作後連結串列長度為8時(binCount從0開始計數,而p開始就對應第一個結點),呼叫樹化方法 - break
- 遍歷的長度(該連結串列長度與樹化閾值比較(
- 否則:找到連結串列中的元素
e.hash值與傳入的hash值相同,並且e.key==key或者說equals方法比較為true- break
- 儲存結點p = e
- 如果:已經到連結串列末尾(
- 如果經過位置計算得到的元素
- 如果:e不為null,說明找到了一個key一致的元素,需要將該結點e的value進行替換
- 儲存舊的
oldvalue = e.value - 如果
!onlyIfAbsent || oldValue == null- 將e.value = value進行替換
- afterNodeAccess(e);
return oldvalue;(原始碼中並沒有方法體{沒有內容},在這裡沒用)
- 儲存舊的
- HashMap this.modCount++ 修改次數(執行到這一步說明沒有找到對應key的元素,從而進行了插入操作)
- 如果
++size>thershold,超過擴容閾值,則執行擴容方法 - afterNodeInsertion(evict);(原始碼中並沒有方法體{沒有內容},在這裡沒用)
return null
2.2.3 hash表table擴容 resize方法分析
(1)擴容原因
- 由於在hash表位置的計算中index = (table.length-1)&node.hash,位置的計算永遠不會超過hash表的長度,大量的元素會發生雜湊碰撞,降低查詢效率,所以當達到飽和條件,即到達含有元素的桶達到thorshold時,需要進行擴容操作
(2)核心resize方法
-
resize方法原始碼:
/** * @return the table */ final Node<K,V>[] resize() { //oldTab:引用擴容前的雜湊表 Node<K,V>[] oldTab = table; //oldCap:表示擴容之前table陣列的長度 int oldCap = (oldTab == null) ? 0 : oldTab.length; //oldThr:表示擴容之前的擴容閾值,觸發本次擴容的閾值 int oldThr = threshold; //newCap:擴容之後table陣列的大小 //newThr:擴容之後,下次再次觸發擴容的條件 int newCap, newThr = 0; //條件如果成立說明 hashMap中的散列表已經初始化過了,這是一次正常擴容 if (oldCap > 0) { //擴容之前的table陣列大小已經達到 最大閾值後,則不擴容,且設定擴容條件為 int 最大值,返回原hashtable if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } //oldCap左移一位實現數值翻倍,並且賦值給newCap, newCap 小於陣列最大值限制 且 擴容之前的閾值 >= 16 //這種情況下,則 下一次擴容的閾值 等於當前閾值翻倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) \\ newThr = oldThr << 1; // double threshold } //oldCap == 0,說明hashMap中的散列表是null //1.new HashMap(initCap, loadFactor); //2.new HashMap(initCap); //3.new HashMap(map); 並且這個map有資料 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; //oldCap == 0,oldThr == 0 //new HashMap(); else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY;//16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//12 } //newThr為零時,通過newCap和loadFactor計算出一個newThr if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; //創建出一個更長 更大的陣列 @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; //說明,hashMap本次擴容之前,table不為null if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { //當前node節點 Node<K,V> e; //說明當前桶位中有資料,但是資料具體是 單個數據,還是連結串列 還是 紅黑樹 並不知道 if ((e = oldTab[j]) != null) { //方便JVM GC時回收記憶體 oldTab[j] = null; //第一種情況:當前桶位只有一個元素,從未發生過碰撞,這情況 直接計算出當前元素應存放在 新陣列中的位置,然後 //扔進去就可以了 if (e.next == null) newTab[e.hash & (newCap - 1)] = e; //第二種情況:當前節點已經樹化,本期先不講,下一期講,紅黑樹。QQ群:865-373-238 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order //第三種情況:桶位已經形成連結串列 //低位連結串列:存放在擴容之後的陣列的下標位置,與當前陣列的下標位置一致。 Node<K,V> loHead = null, loTail = null; //高位連結串列:存放在擴容之後的陣列的下表位置為 當前陣列下標位置 + 擴容之前陣列的長度 Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; //hash-> .... 1 1111 //hash-> .... 0 1111 // 0b 10000 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } -
確定新的表容量以及新的擴容閾值邏輯:
- 建立引用變數
- oldTab = this.table進行引用賦值
- 舊的表容量oldCap = 表的長度,如果表為null的話,oldCap = 0
- 舊的擴容閾值oldThr = this.thershold
- 建立儲存新的表容量與擴容閾值的變數newCap,newThr
- 如果:oldCap>0,說明HashMap之前已經初始化過了,這是正常擴容
- 如果:舊的表容量已經達到
MAXIMUN_CAPCITY=1<<30,則將擴容閾值設為整數最大值,返回原table(已經無法擴容了) - 否則,如果:讓
newCap = oldCap<<1,如果newCap小於MAXIMUN_CAPCITY並且舊的負載oldCap大於預設表容量16,則新的擴容閾值等於舊的擴容閾值翻倍
- 如果:舊的表容量已經達到
- 否則,說明oldCp=0如果:舊的擴容閾值
oldThr>0(構造HashMap時除了無參預設方法其他都直接或間接設定了thorshold),讓新的表容量等於舊的擴容閾值newCap=oldThr - 否則,此時情況為
oldCap == 0,oldThr == 0(使用無參構造方法),讓newCap = 預設表容量16,newThr = 預設負載因子*預設表容量 - 如果:newThr = 0,ft = newCap負載因子
- 如果newCap<小於整數最大值 並且 ft<最大表容量?ft取整:整數的最大值
- 以上程式碼已經計算出來本次陣列應該改為多大,下次擴容閾值應設為多大,接下來就開始建立新的陣列,並把舊元素賦給新陣列
- 建立引用變數
-
開始將舊錶元素分配到新的表上
-
使用
newCap建立新的陣列newTab -
如果:oldTab!=null,說明擴容之前陣列就已經被建立了,此時開始遍歷
oldTab.for(j = 0;j<oldCap;++j):-
如果:
(Node e = oldTab[j]) != null,即當前節點不為空: -
令
oldTab[j] = null方便GC回收舊的陣列 -
如果:e.next == null(即當前桶位只有一個元素),則讓
newTab[e.hash & (newCap - 1)] = e;(利用新的表容量的位置演算法,讓e賦值到新表的相應位置) -
如果:e為樹的根結點,呼叫
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);去進行樹中結點在新表的分配 -
如果:e為連結串列的頭結點,建立4個連結串列結點
loHead,loTail,hiHead,hiTail- loxxx:低位連結串列:存放在擴容之後的陣列的下標位置與當前陣列的下標位置一致
- hixxx:高位連結串列:存放在擴容之後的陣列的下表位置為 (當前陣列下標位置 + 擴容之前陣列的長度)
- 這裡以原先表容量為16,擴容後容量為32為例
- 由於16 = (10000)b ,32 = (100000)b
- 有依據原先的路由演算法:
index = e.hash & (15=1111b),也就是說是因為該連結串列的hash後4位相同,所以才分配到該連結串列上 - 然後當新的表容量為32時,index = hash&(31 = 11111b),也就是說現在在新表上的位置取決於e.hash的後5位
- 此時需要計算每個連結串列的與oldCap的與操作結果,其結果取決於e.hash的倒數第5位(與newCap-1進行&操作時,newCap-1前面都為0,又因為該連結串列的後四位都相同,所以就分配而言只取決於第5位):
- e.hash = ...1 xxxx ->分配到新的陣列位置為:15+原先位置
- e.hash = ...0 xxxx ->分配到新的陣列位置為:原先位置
- 該方法將原本的一條連結串列可以分配到兩個桶中,以減小連結串列長度
-
開始迴圈:建立結點
next = e.next- 如果:
(e.hash & oldCap) == 0- 將e新增到lo連結串列中
- 否則:
- 將e新增到hi連結串列中
- 如果:
-
最後將兩條連結串列的尾結點置null
將
newTab[j] = loHead,newTab[j+oldCap] = hiHead元素的分配,擴容完成!!!
-
-
2.2.4 刪除鍵值對 remove方法分析
(1)remove(K)方法
-
原始碼
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; }套娃方法,呼叫removeNode方法,獲取其返回的被刪除結點,返回該結點的value
(2)remove(K,V)方法
-
原始碼
public boolean remove(Object key, Object value) { return removeNode(hash(key), key, value, true, true) != null; }套娃方法,呼叫removeNode方法,返回是否刪除成功
(3)核心removeNode方法
-
原始碼
/** * Implements Map.remove and related methods. * * @param hash hash for key * @param key the key * @param value the value to match if matchValue, else ignored * @param matchValue if true only remove if value is equal * @param movable if false do not move other nodes while removing * @return the node, or null if none */ final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { //tab:引用當前hashMap中的散列表 //p:當前node元素 //n:表示散列表陣列長度 //index:表示定址結果 Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { //說明路由的桶位是有資料的,需要進行查詢操作,並且刪除 //node:查詢到的結果 //e:當前Node的下一個元素 Node<K,V> node = null, e; K k; V v; //第一種情況:當前桶位中的元素 即為 你要刪除的元素 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { //說明,當前桶位 要麼是 連結串列 要麼 是紅黑樹 if (p instanceof TreeNode)//判斷當前桶位是否升級為 紅黑樹了 //第二種情況 //紅黑樹查詢操作,下一期再說 node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { //第三種情況 //連結串列的情況 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } //判斷node不為空的話,說明按照key查詢到需要刪除的資料了 if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { //第一種情況:node是樹節點,說明需要進行樹節點移除操作 if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); //第二種情況:桶位元素即為查詢結果,則將該元素的下一個元素放至桶位中 else if (node == p) tab[index] = node.next; else //第三種情況:將當前元素p的下一個元素 設定成 要刪除元素的 下一個元素。 p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; } -
方法邏輯:
- 前面部分與getNode方法相似,目的是查詢要刪除的Node結點是否存在,如果不存在或者HashTable未被初始化,則直接返回null
- 如果:查詢到的node不為空,說明查詢到了
- 如果:該結點為樹節點,呼叫
removeTreeNode(this, tab, movable)方法,刪除並儲存樹的結點 - 否則,如果:該結點在桶中,直接讓下一個結點放入桶中,儲存之前結點
- 否則:將連結串列的結點刪除,即將前一結點的next指向node.next
- 如果:該結點為樹節點,呼叫
- 修改次數+1 ,size-1,返回刪除結點
- 返回儲存的結點
2.2.5 替換結點值 replace方法分析
(1)replace(K,V)
-
原始碼:
@Override public V replace(K key, V value) { Node<K,V> e; if ((e = getNode(hash(key), key)) != null) { V oldValue = e.value; e.value = value; afterNodeAccess(e); return oldValue; } return null; }呼叫
getNode方法通過比較key來找到需要替換的結點,將value賦給該結點,返回舊value;如果沒找到返回null
(2)replace(K key, V oldValue, V newValue)
-
原始碼:
@Override public boolean replace(K key, V oldValue, V newValue) { Node<K,V> e; V v; if ((e = getNode(hash(key), key)) != null && ((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) { e.value = newValue; afterNodeAccess(e); return true; } return false; }呼叫
getNode方法通過比較key與value來找到需要替換的結點,將newValue賦給該結點,返回true,如果沒找到返回false
2.2.6 K 對映 compute方法
(1)compute方法
-
該方法實現了通過傳入函式式介面,來對傳入的key值對應的結點進行操作,如果找不到key對應的結點,會進行插入一個新的結點
Node(key,mappingFunction.apply(key,value)),並可能會重新排列部分資料結構;如果對映value結果為null,則會刪除該結點 -
原始碼:
@Override public V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) { if (remappingFunction == null) throw new NullPointerException(); int hash = hash(key); Node<K,V>[] tab; Node<K,V> first; int n, i; int binCount = 0; TreeNode<K,V> t = null; Node<K,V> old = null; if (size > threshold || (tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((first = tab[i = (n - 1) & hash]) != null) { if (first instanceof TreeNode) old = (t = (TreeNode<K,V>)first).getTreeNode(hash, key); else { Node<K,V> e = first; K k; do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { old = e; break; } ++binCount; } while ((e = e.next) != null); } } V oldValue = (old == null) ? null : old.value; V v = remappingFunction.apply(key, oldValue); if (old != null) { if (v != null) { old.value = v; afterNodeAccess(old); } else removeNode(hash, key, null, false, true); } else if (v != null) { if (t != null) t.putTreeVal(this, tab, hash, key, v); else { tab[i] = newNode(hash, key, v, first); if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); } ++modCount; ++size; afterNodeInsertion(true); } return v; } -
方法邏輯
- 前面部分與getNode方法相似,只不過在最前面加入了對傳入的BiFunction例項的控制判斷,如果為空,則丟擲異常
- 之後去尋找key值對應的結點
old,如果找到了且value不為空,利用remappingFunction.apply(key, oldValue)進行對映操作,獲得新的value v - 如果:old不為空且old結點的value值不為空,將新的v賦給old.value,實現value的對映操作
- 如果:v不為null
- 將old.value 替換為 v
否則:v為null,呼叫removeNode(hash, key, null, false, true)方法刪除key,value對應結點
- 如果:v不為null
- 否則:old為null,證明沒找到該結點,呼叫相關方法新增新的結點
- 如果:該結點是一個樹的根結點,則呼叫
t.putTreeVal(this, tab, hash, key, v)實現作為新結點的插入 - 否則:將該桶位元素tab[i]設為新結點,插入完成之後在進行樹化判斷,並決定是否樹化
- 修改資料屬性
- 如果:該結點是一個樹的根結點,則呼叫
- 返回對映後的結果 v
-
使用方法
HashMap<Integer,String> hp = new HashMap<Integer,String>(); hp.put(1,"A"); hp.put(2,"B"); hp.put(3,"C") hp.compute(2,(k,v)->v+"A")//將key為2的元素的value修改為value+"A" hp ==> {1=A, 2=BA, 3=C} hp.put(10,"A") hp ==> {1=A, 2=BA, 3=C, 10=A} hp.compute(10,(k,v)->null)//null hp ==> {1=A, 2=BA, 3=C}
(2)computeIfAbsent方法
-
public V computeIfAbsent(K key,Function<? super K, ? extends V> mappingFunction) {...} -
該方法如果沒有檢測到該key所對應結點,會新增一個新的結點
Node(key,mappingFunction.apply(key,value))到HashMap中,如果存在則不進行此操作,並返回null;如果對映value結果為null,則會刪除該結點 -
使用方法
承接上處 hp.computeIfAbsent(2,(v)->"new value")//返回BA hp ==> {1=A, 2=BA, 3=C} jshell> hp.computeIfAbsent(4,(v)->"new value")//返回new value hp ==> {1=A, 2=BA, 3=C, 4=new value}
(3)computeIfPresent方法
-
public V computeIfPresent(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {...} -
該方法如果檢測到該key所對應結點,會新增一個新的結點
Node(key,mappingFunction.apply(key,value))到HashMap中,如果不存在則不進行此操作,並返回null;如果對映value結果為null,則會刪除該結點 -
使用方法
承接上處 hp.computeIfPresent(5,(k,v)->"new value :5")//返回null hp.computeIfPresent(4,(k,v)->"new value :4")//返回"new value :4" hp ==> {1=A, 2=BA, 3=C, 4=new value :4}
2.2.7 K-V 對映 merge方法
(1)merge方法
-
該方法與compute類似,只不過以
key與value來尋找相應結點,找到則覆蓋,找不到則插入新的結點Node(key,value) -
如果oldValue為null或者節點不存在,則直接取value引數(不是對映後的value)作為節點的value值
-
同樣的,作為特殊情況,如果計算出來的value值為null,刪除節點
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) {...與compute類似...} -
使用方法
HashMap<Integer,String> hp = new HashMap(); hp.put(1,"A"); hp.merge(1,"A",(k,v)->"new value");//new value hp ==> {1=new value} hp.merge(1,"B",(k,v)->"new value:1")//new value:1 hp ==> {1=new value:1} hp.merge(2,"B",(k,v)->"new value:B")//B hp ==> {1=new value:C, 2=B} hp.put(null,"我是null")//對映後的預設值 hp ==> {null=對映後的預設值, 1=new value:C, 2=B} hp.merge(100,"100的預設值",(k,v)->"對映後的100的預設值") //100的預設值 hp ==> {null=對映後的預設值, 1=new value:C, 2=B, 100=100的預設值}
2.2.8 遍歷消費 forEach方法
(1)forEach方法
-
原始碼
public void forEach(BiConsumer<? super K, ? super V> action) { Node<K,V>[] tab; if (action == null) throw new NullPointerException(); 。。。之後就是遍歷table,對結點進行消費action.accpet(e.key,e.value) }
2.2.9 清空 clear方法
(1)clear方法
-
原始碼
public void clear() { Node<K,V>[] tab; modCount++; if ((tab = table) != null && size > 0) { size = 0; for (int i = 0; i < tab.length; ++i) tab[i] = null; } }判斷table是否初始化,如果不為空,每個位置置為null,等待JVM回收各個結點即可
2.3 獲取HashMap中的資訊
2.3.1 獲取值 get方法分析
(1)get方法
-
原始碼:
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }套娃方法,先用hash函式獲取key的hash值,getNode去尋找Node結點,如果找到則返回value值,沒找到則返回null
(2)getOrDefault方法
-
原始碼:
public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? defaultValue : e.value; }套娃方法,和get方法類似,只不過如果找不到結點則返回傳入的預設值
(2)核心getNode方法
-
原始碼:
/** * Implements Map.get and related methods. * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key) { //tab:引用當前hashMap的散列表 //first:桶位中的頭元素 //e:臨時node元素 //n:table陣列長度 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //第一種情況:定位出來的桶位元素 即為咱們要get的資料 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; //說明當前桶位不止一個元素,可能 是連結串列 也可能是 紅黑樹 if ((e = first.next) != null) { //第二種情況:桶位升級成了 紅黑樹 if (first instanceof TreeNode)//下一期說 return ((TreeNode<K,V>)first).getTreeNode(hash, key); //第三種情況:桶位形成連結串列 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; } -
方法邏輯
- 建立幾個引用
tab表,頭結點first,臨時結點e,表長度n - 如果:tab不為空 並且 表長大於0 並且 通過路由演算法得出的結點
first = tab[(n - 1) & hash]不為空,則:- 如果得到的first即為自己所尋找的元素的key,返回first
- 如果:frist不是所尋找的元素的key,first.next不為空,說明可能存在與之後的鏈式結構中
- 如果:first是紅黑樹根結點,呼叫
getTreeNode(hash, key)尋找樹種符合條件的結點,並返回結果 - 否則:frist為連結串列頭結點,遍歷連結串列,去比較,獲得對應結點,並返回結果
- 如果:first是紅黑樹根結點,呼叫
- 如果:以上都沒找到,返回null
- 建立幾個引用
2.3.2 檢查是否包含key,value containsXX方法
(1)containsKey(K)
-
原始碼:
public boolean containsKey(Object key) { return getNode(hash(key), key) != null; }套娃方法,呼叫
getNode方法查詢,返回是否查詢到結點
(2)containsValue(V)
-
原始碼:
public boolean containsValue(Object value) { Node<K,V>[] tab; V v; if ((tab = table) != null && size > 0) { for (int i = 0; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null; e = e.next) { if ((v = e.value) == value || (value != null && value.equals(v))) return true; } } } return false; } -
方法邏輯
- 遍歷table,對於每個桶:
- 遍歷每個桶的鏈式結構,比較Node.value與傳入value
- 如果:找到對應value,返回true
- 遍歷每個桶的鏈式結構,比較Node.value與傳入value
- 沒找到對應value,返回false
- 遍歷table,對於每個桶:
2.3.3 檢查大小
(1)isEmpty方法
return size == 0,判斷是否為空
(2)size方法
return this.size,返回元素個數
2.4 其它方法
2.4.1 序列化與反序列化
(1)HashMap中的序列化方法介紹
-
為了確保JVM的跨平臺,防止因機器的不同序列化與反序列化的結果可能並不是正常構建的結果,HashMap中的資料屬性很多都用
transient修飾,序列化時會被跳過,所以需要重寫方法來自定義序列化的資料的寫入與讀取transient Node<K,V>[] table; transient Set<Map.Entry<K,V>> entrySet; transient int size; transient int modCount; -
HashMap中還為了方便,提供了序列化與反序列化方法(這裡就不貼原始碼了,可以去jdk中看):
final private wirteObject(ObjectOutputStream)- HashMap序列化的時候不會將儲存資料的陣列序列化,而是將元素個數以及每個元素的Key和Value都進行序列化
final private readObject(ObjectOutputStream)- 在反序列化的時候,重新計算Key和Value的位置,重新填充一個數組,重新構建HashMap
(2)方法作用
- 上述方法作用為當進行序列化與反序列化時,會判斷被序列化的物件是否自己重寫了writeObject方法,如果重寫了,就會呼叫被序列化物件自己的writeObject方法,如果沒有重寫,才會呼叫預設的序列化方法
- final型別也保證瞭如果有類繼承HashMap時,
HashMap序列化與反序列化參考
3. 總結
3.1.1 HashMap中的其他類與方法
- HashMap中為了功能的增強與擴充套件還定義了許多類,比如紅黑樹結點
TreeNode,對於值的遍歷Values類與key的遍歷Keys,EntrySet等以及各種迭代器的設計,它們各自都有自己的資料操作方法,篇幅原因,就不一一贅述了 - 如果有錯誤,還請指出
b站HashMap原始碼講解參