
Mysql:小主鍵,大問題
今日格言:讓一切迴歸原點,迴歸最初的為什麼。
本篇講解 Mysql 的主鍵問題,從為什麼的角度來了解 Mysql 主鍵相關的知識,並拓展到主鍵的生成方案問題。再也不怕被問到 Mysql 時只知道 CRUD 了。
一、為什麼需要主鍵
- 資料記錄需具有唯一性(第一正規化)
- 資料需要關聯 join
- 資料庫底層索引用於檢索資料所需
以下廢話連篇,可以直接跳過到下一節。
“資訊是用來消除隨機不定性的東西”(夏農)。人通過獲得、識別自然界和社會的不同資訊來區別不同事物,得以認識和改造世界。資料是反映客觀事物屬性的記錄,是資訊的具體表現形式。資料經過加工處理之後,就成為資訊;而資訊需要經過數字化轉變成資料才能儲存和傳輸。資料庫就是用於儲存資料記錄的。既已如此,記錄便是具有確定性(相對)的資訊,其確定性即唯一性。我們得出第一條原因:
1.資料記錄需具有唯一性
世界是由客觀存在及其關係組成的。資料是數字化和模型化的存在關係。資料除了本身的描述價值外,其價值還在於其相互關聯性。為實現關聯的準確性,資料需要有對外相互關聯的標識。所以體現在資料儲存上,主鍵的第二作用,也是存在的第二因素即:
2.資料需要關聯
資料用於描述客觀實在的,本身沒有意義。只有在根據主觀需求組織之後,通過一定方式滿足人認識事物的過程才具有了意義。所以資料需要被檢索,被組織。則主鍵第三個作用:
3.資料庫底層索引用於檢索資料所需
二、為什麼主鍵不宜過長
這個問題的點在長上。那短比長有什麼優勢?(嘿嘿嘿,內涵)—— 短不佔空間。但這麼點磁碟空間相對整個資料量來說微不足道,而且我們一般不怎麼用到主鍵列。那麼原因應該在快上,而且和原始資料關係不大。以此自然得出和索引相關,而且和索引讀取相關。那麼為什麼長主鍵在索引中會影響效能?
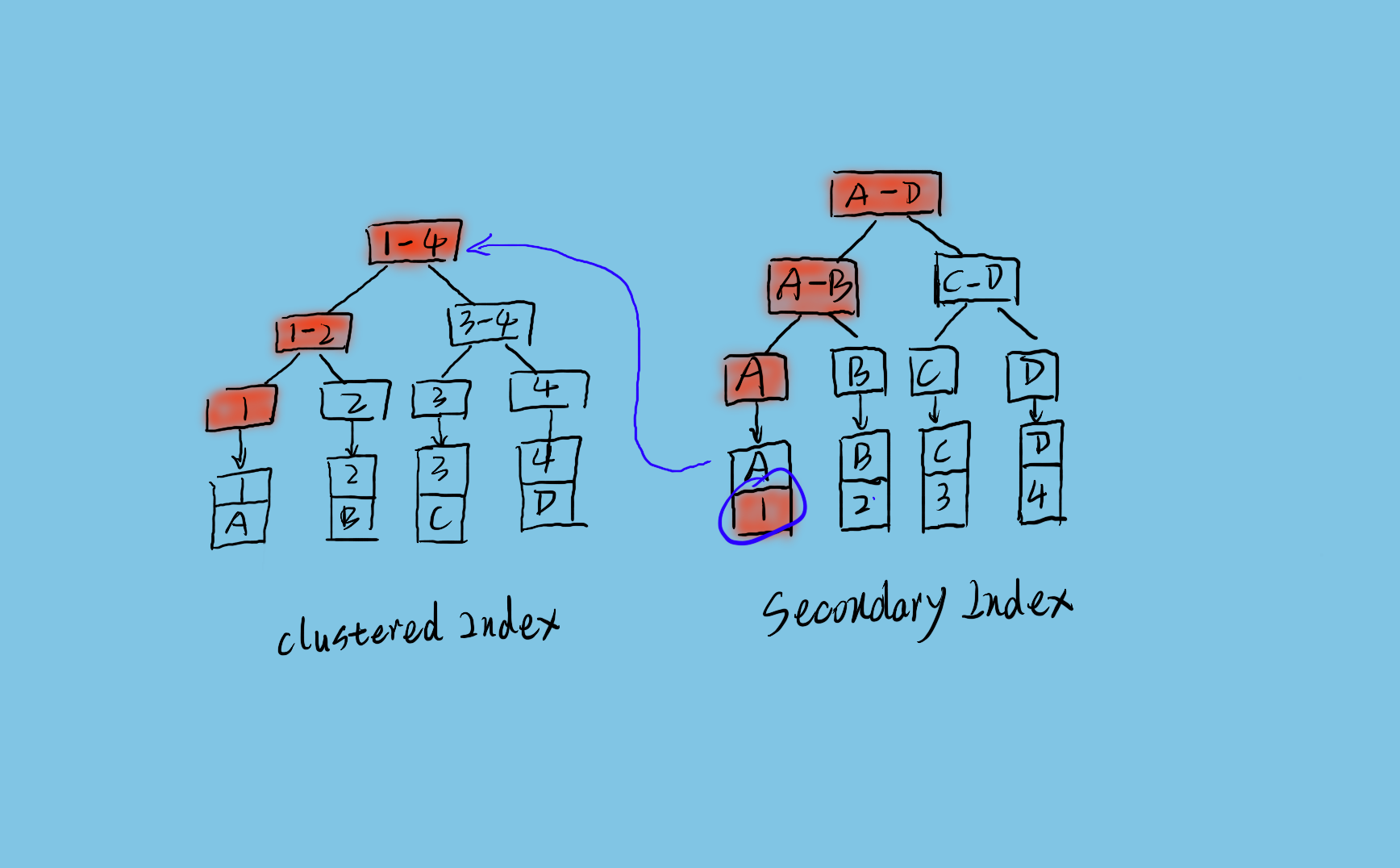
上面是 Innodb 的索引資料結構。左邊是聚簇索引,通過主鍵定位資料記錄。右邊是二級索引,對列資料做索引,通過列資料查詢資料主鍵。如果通過二級索引查詢資料,流程如圖上所示,先從二級索引樹上搜索到主鍵,然後在聚簇索引上通過主鍵搜尋到資料行。其中二級索引的葉子節點是直接儲存的主鍵值,而不是主鍵指標。所以如果主鍵太長,一個二級索引樹所能儲存的索引記錄就會變少,這樣在有限的索引緩衝中,需要讀取磁碟的次數就會變多,所以效能就會下降。
三、為什麼建議使用自增 ID
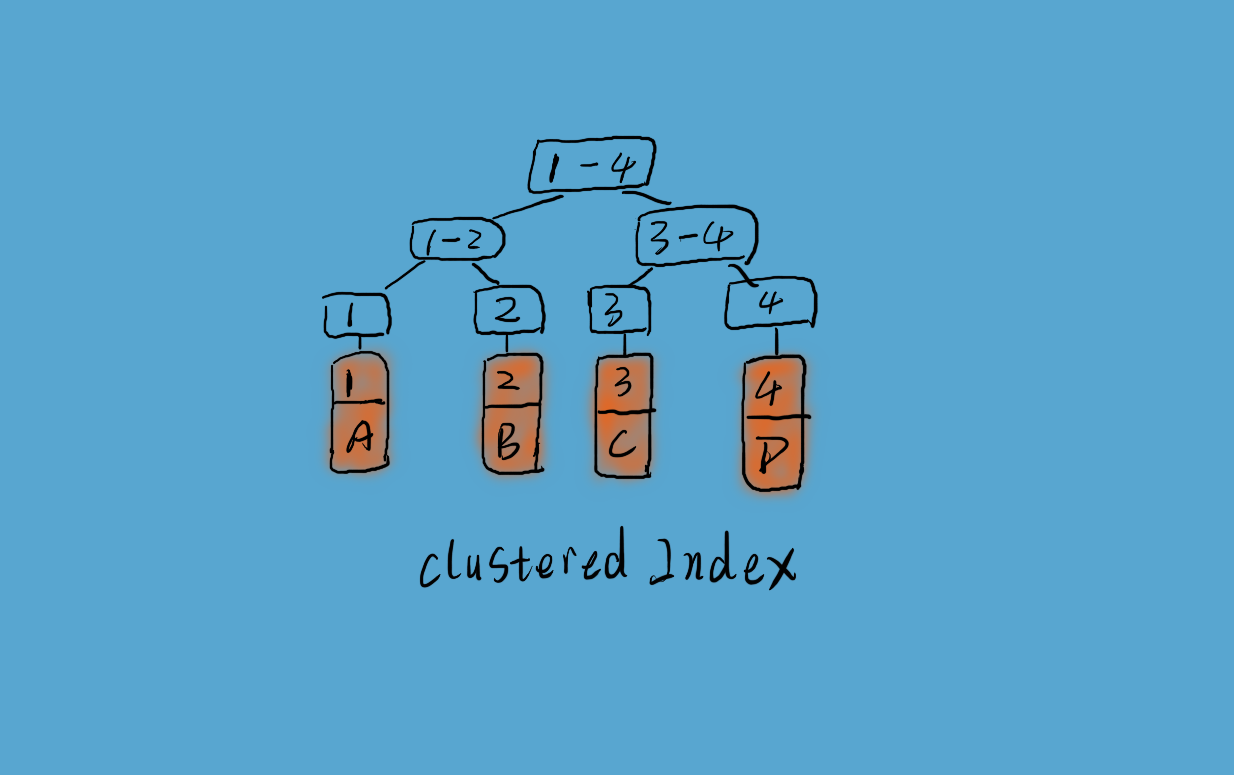
InnoDB 使用聚簇索引,如上圖所示,資料記錄本身被存於主索引(一顆 B+Tree)的葉子節點上。這就要求同一個葉子節點內(大小為一個記憶體頁或磁碟頁)的各條資料記錄按主鍵順序存放,因此每當有一條新的記錄插入時,MySQL 會根據其主鍵將其插入適當的節點和位置,如果頁面達到裝載因子(InnoDB 預設為 15/16),則開闢一個新的頁(節點)。
如果表使用自增主鍵,那麼每次插入新的記錄,記錄就會順序新增到當前索引節點的後續位置,當一頁寫滿,就會自動開闢一個新的頁。這樣就會形成一個緊湊的索引結構,近似順序填滿。由於每次插入時也不需要移動已有資料,因此效率很高,也不會增加很多開銷在維護索引上,如下圖左側所示。否則由於每次插入主鍵的值近似於隨機,因此每次新記錄都要被插到現有索引頁的中間某個位置,MySQL 不得不為了將新記錄插到合適位置而移動資料,如下圖右側所示,這樣就造成了一定的開銷。由於此,Mysql 為維護索引可能需要頻繁的重新整理緩衝,增加了方法磁碟 IO 的次數,而且時常需要對索引結構進行重組織。

四、業務 Key VS 邏輯 Key
業務 Key,即使用具有業務意義的 id 作為 Key,比如使用訂單流水號作為訂單表的主鍵 Key。邏輯 Key,即無關業務的 Key,按某種規則生成 Key,如自增 Key。
業務 Key 的優點
- Key 具有業務意義,在查詢時可以直接作為搜尋關鍵字使用
- 不需要額外的列和索引空間
- 可以減少一些 join 操作。
業務 Key 的缺點
- 當業務發生變化時,有時需要變更主鍵
- 涉及多列 Key 時比較難操作
- 業務 Key 往往比較長,所佔空間更大,導致更大的磁碟 IO
- 在 Key 確定前不能持久化資料,有時我們沒有在確定資料 Key 時,就想先新增一條記錄,之後再更新業務 Key
- 設計一個兼具易用和效能的 Key 生成方案比較難
邏輯 Key 的優點
- 不會因為業務的變動而需要修改 Key 邏輯
- 操作簡單,且易於管理
- 邏輯 Key 往往更小,效能更優
- 邏輯 Key 更容易保證唯一性
- 更易於優化
邏輯 Key 缺點
- 查詢主鍵列和主鍵索引需要額外的磁碟空間
- 在插入資料和更新資料時需要額外的 IO
- 更多的 join 可能
- 如果沒有唯一性策略限制,容易出現重複的 Key
- 測試環境和正式環境 Key 不一致,不利於排查問題
- Key 的值沒有和資料關聯,不符合三正規化
- 不能用於搜尋關鍵字
- 依賴不同資料庫系統的具體實現,不利於底層資料庫的替換
五、主鍵生成
一般情況下,我們都使用 Mysql 的自增 ID,來作為表的主鍵,這樣簡單,而且從上面講到的來看,效能也是最好的。但是在分庫分表的情況情況下,自增 ID 則不能滿足需求。我們可以來看看不同資料庫生成 ID 的方式,也看一些分散式 ID 生成方案。利於我們思考甚至實現自己的分散式 ID 生成服務。
資料庫的實現
Mysql 自增
Mysql 在記憶體中維護一個自增計數器,每次訪問 auto-increment 計數器的時候, InnoDB 都會加上一個名為AUTO-INC 鎖直到該語句結束(注意鎖只持有到語句結束,不是事務結束)。AUTO-INC 鎖是一個特殊的表級別的鎖,用來提升包含 auto_increment 列的併發插入性。
在分散式的情況下,其實可以獨立一個服務和資料庫來做 id 生成,依舊依賴 Mysql 的表 id 自增能力來為第三方服務統一生成 id。為效能考慮可以不同業務使用不同的表。
Mongodb ObjectId
Mongodb 為防止主鍵衝突,設計了一個 ObjectId 作為主鍵 id。它由一個 12 位元組的十六進位制數字組成,其中包含以下幾部分:
-
Time:時間戳。4 位元組。秒級。
-
Machine:機器標識。3 位元組。一般是機器主機名的雜湊值,這樣就確保了不同主機生成不同的機器 hash 值,確保在分散式中不造成衝突,同一臺機器的值相同。
-
PID:程序 ID。2 位元組。上面的 Machine 是為了確保在不同機器產生的 objectId 不衝突,而 pid 就是為了在同一臺機器不同的 mongodb 程序產生的 objectId 不衝突。
-
INC:自增計數器。3 位元組。前面的九個位元組保證了一秒內不同機器不同程序生成的 objectId 不衝突,自增計數器,用來確保在同一秒內產生的 objectId 也不會發現衝突,允許 256 的 3 次方等於 16777216 條記錄的唯一性。
Cassandra TimeUUID
Cassandra 使用下面規則生成一個唯一的 id:time + MAC + sequence
方案
- Zookeeper 自增:通過 zk 的自增機制實現。
- Redis 自增:通過 Redis 的自增機制實現。
- UUID:使用 UUID 字串作為 Key。
- snowflake 演算法:和 Mongodb 的實現類似,
1位符號位 + 41位時間戳(毫秒級)+ 10位資料機器位 + 12位毫秒內的序列。
開源實現
- 百度 UidGenerator:基於snowflake演算法。
- 美團 Leaf:同時實現了基於 Mysql 自增(優化)和 snowflake 演算法的機制。
推薦系列
列式儲存
時間序列資料庫(TSDB)初識與選擇
十分鐘瞭解 Apache Druid
Apache Druid 底層儲存設計
Apache Druid 的叢集設計與工作流程
Mysql 大表問題和解決
想了解更多資料儲存相關知識,請關注我的公眾號。

相關推薦
Mysql:小主鍵,大問題
今日格言:讓一切迴歸原點,迴歸最初的為什麼。 本篇講解 Mysql 的主鍵問題,從為什麼的角度來了解 Mysql 主鍵相關的知識,並拓展到主鍵的生成方案問題。再也不怕被問到 Mysql 時只知道 CRUD 了。 一、為什麼需要主鍵 資料記錄需具有唯一性(第一正規化) 資料需要關聯 join 資料庫底層索
mysql自增長主鍵,刪除數據後,將主鍵順序重新排序
mar drop 排序 ews 字段 name key 博文 csdn 用數據庫的時候,難免會刪除數據,會發現設置的主鍵增長不是按照正常順序排列,中間有斷隔比如這樣。 以我這個情況舉例 處理方法的原理:刪除原有的自增ID,重新建立新的自增ID。 ALTER TABLE `n
MySQL:聯合主鍵、索引
MySQL資料庫用聯合主鍵。用兩張表測試。 # 1分鐘資料表 CREATE TABLE md_1min2( `d_1min` DATETIME(3), `code` CHAR(16), `open` FLOAT, `high` FLOAT, `low` FLOAT, `c
MySQL—概念,使用者的建立,主鍵,外來鍵,資料型別,表格建立
MySQL DBMS,MySQL的概念,資料庫分類,以前MySQL的部署中的一些概念 #DBMS:資料庫管理系統,用於管理資料庫的大型軟體。mysql就是dbms的一種 #Mysql:是用於管理檔案的一個軟體 #服務端軟體
mysql修改表結構 MySQL修改表結構操作命令總結 MySql資料庫在表中新增新欄位,設定主鍵,設定外來鍵,欄位移動位置,以及修改資料庫後如何進行部署和維護的總結 mysql 如何修改、新增、刪除表主鍵
MySQL修改表結構操作命令總結 以下內容轉自:http://www.jb51.net/article/58079.htm 表的結構如下: 複製程式碼程式碼如下:
程式碼自留地:小檔案合併成大檔案,需要配置BytesZip使用,java
public class FileZip implements Serializable { String fileName = null; byte [] zipBytes = null;
【MYSQL筆記2】複製表,在已有表的基礎上設定主鍵,insert和replace
之前我自己建立好了一個數據庫xscj;表xs是已經定義好的 具體的定義資料型別如下: 為了複製表xs,我們新建一個表名為xstext,使用下列語句進行復制xs,或者說是備份都可以; create table xstext as select * from x create ta
【MYSQL筆記2】復制表,在已有表的基礎上設置主鍵,insert和replace
主鍵 insert 我們 key repl 圖片 prim 個數 insert語句 之前我自己建立好了一個數據庫xscj;表xs是已經定義好的 具體的定義數據類型如下: 為了復制表xs,我們新建一個表名為xstext,使用下列語句進行復制xs,或者說是備份都可以; c
MySql資料庫在表中新增新欄位,設定主鍵,設定外來鍵,欄位移動位置,以及修改資料庫後如何進行部署和維護的總結
1,為當前已有的表新增新的欄位 alter table student add studentName varchar(20) not null; 2,為當前已有的表中的欄位設定為主鍵自增 alter table student add constraint PK_studentId primaryKe
mysql 更換主鍵,新增新主鍵欄位及主鍵初始化賦值 sql
順序執行以下sql語句 1.刪除表主鍵約束 ALTER TABLE mobilems_m_weex DROP PRIMARY KEY; 2.新增新主鍵欄位id ALTER TABLE mobilems_m_weex ADD id BIGINT(20) NOT NULL C
MySQL入門——修改資料表4:新增主鍵約束、顯示錶結構、新增唯一約束
這裡的新增主鍵約束、新增唯一約束,指的是列級約束,是在資料表建立以後再新增的。 例如,給user3表中的id欄位新增主鍵約束: ALTER TABLE user3 ADD PRIMARY KE
MySQL聯合主鍵,複合主鍵區別&建立
聯合主鍵: 當兩個資料表形成的是多對多的關係,那麼需要通過兩個資料表的主鍵來組成聯合主鍵,就可以確定每個資料表的其中一條記錄了 例: 學生表:student create table student( id mediumint auto_increment co
資料庫的幾個概念:主鍵,外來鍵,索引,唯一索引
主鍵: 主鍵是資料表的唯一索引,比如學生表裡有學號和姓名,姓名可能有重名的,但學號確是唯一的,你要從學生表中搜索一條紀錄如查詢一個人,就只能根據學號去查詢,這才能找出唯一的一個,這就是主鍵;如:id int(10) not null primary key aut
MySql自增主鍵id插入失敗或刪除後,再插入亂序問題
在對資料庫進行操作的時候,資料庫的表裡的id是自增的,當資料被刪除或者新增或者插入失敗時,id會一直增上去,變得很亂,不會按照順序,下面是兩種解決辦法: alter table tablename drop column id; alter table tablenam
mysql中,索引,主鍵,唯一索引,聯合索引的區別
索引是一種特殊的檔案(InnoDB資料表上的索引是表空間的一個組成部分),它們包含著對資料表裡所有記錄的引用指標。 普通索引(由關鍵字KEY或INDEX定義的索引)的唯一任務是加快對資料的訪問速度。 普通索引允許被索引的資料列包含重複的值。如果能確定某個資料列將只包含彼此各
mysql 外來鍵,主鍵,唯一性約束
為已經新增好的資料表新增外來鍵: 語法:alter table 表名 add constraint FK_ID foreign key(你的外來鍵欄位名) REFERENCES 外表表
JS 點選事件onclick:點選物件小區域顏色,大區域顏色改變
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <
從團隊管理視角看重複建設問題:輪子小造怡情,大造傷身,全域性出發成就更好的你
在一定規模的軟體研發團隊內,經常出現的情況是對同一個問題領域,會有多個人或多個者團隊矇頭再重複做系統或方案來解決相同問題。 甚至,在一些團隊內,技術人員為了職位晉升,會通過重複建設相關的系統來展示其能力,併名其名曰面向晉升程式設計。 對於個人來說,重複造輪子其實是人之本性,特別是對於優秀的研發工程師來說,自己
一張表多個字段是另一張表的主鍵,關聯查詢語句
left join phone where table 查詢語句 tab tin 主鍵 let CREATE TABLE `User`( `Id` BIGINT AUTO_INCREMENT NOT NULL, `Name` VARCHAR(10)
子表,父表;一對多,多對一;主鍵,外鍵梳理。
梳理 一段 引用 cnblogs .com 課程 alt img 分享 這個每次搞明白後,過一段時間又亂了,這次總結下: 子表與父表: 父表:被引用的表。被引用列一定是父表的主鍵。 子表:引用父表的某一列作為外鍵。 一對多,多對一:一的一方一定是父表,多的一