
正則表達選擇分組向後引用及捕獲和非捕獲分組(五)(1000則)
前言
直接用例子作為演示。
四沒有,因為我看了一下,第四節當時理解錯了,還在改。
正文
選擇操作
部分割槽分大小寫
我們在做匹配的時候希望,不區分大小寫。
當然我們在python使用庫中,可以選擇顯示不區分大小寫。
但是python庫在我們寫入中,有個有一個需求一部分是不區分大小寫的。
比如說我們希望the 中,t區分大小寫,而he不區分大小寫,怎麼寫呢?
我們用(?i)表示不區分大小寫,那麼我們可以這樣寫:t(?i)he,這樣就可以了。
其他選擇操作
在此說明一下,其實每一種語言的正則都有一定的區別。
我這裡介紹幾種通用的選擇操作:
(?m) 表示多行匹配,如果不清楚請看我的第三章。
(?s) 單行匹配
(?x) 忽略註釋
還有很多,在此提一下,然後呢,每一種語言都存在差異,最好是使用同類型的庫。
子模式
什麼是子模式?
指的是分組中的一個或多個分組,子模式就是模式中的模式。
可能這樣理解有點難理解,舉個栗子:
THE RIME OF THE ANCYENT MARINERE
我要匹配這樣一段話,怎麼匹配呢?
正則我這樣寫肯定可以匹配的。
THE RIME OF THE ANCYENT MARINERE
那麼我現在這樣寫:
(THE) (RIME) (OF) (THE) (ANCYENT) (MARINERE)
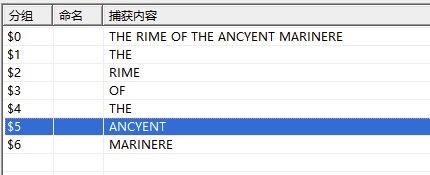
它不僅把我們要匹配的匹配出來了,而且每個括號中的進行了分組,這就是子模式。
捕獲和向後引用
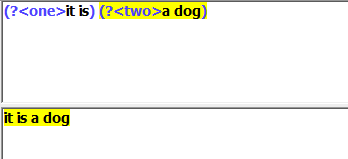
it is a dog
正則
(it is) (a dog)
這個時候就將他們分組了。
$2 $1 的結果是 a dog it is.
除了這個我們還可以這樣 \U$1 $2 得到的結果是 A DOG it is
\U 是將匹配項轉換為大寫。
那麼還有其他的:\u 是首字母大寫,\l 首字母小寫 \L 全部小寫
這些java或其他高階語言本身不支援,你需要使用一些庫,但這些屬於正則規範。
命名分組
得到的結果是:
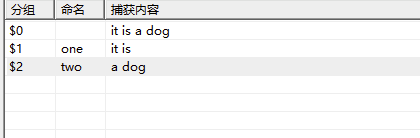
也就是說我們可以進行命名分組,如何引用分組:
$+{one}
通過$+{xx}的方式。
每一種命名分組在不同語言中是不同的,python中是(?p
非捕獲分組
非捕獲分組是相對捕獲分組而言的。
因為捕獲分組會將分組資訊儲存在記憶體中而非捕獲不會,所以效能高。
我再網上找了一個例子:
var str = "a1***ab1cd2***c2";
var reg1 = /((ab)+\d+)((cd)+\d+)/i;
var reg2 = /((?:ab)+\d+)((?:cd)+\d+)/i;
alert(str.match(reg1));//ab1cd2,ab1,ab,cd2,cd
alert(str.match(reg2));//ab1cd2,ab1,cd2
(?:xx) 使用?:就是非捕獲分組。
也就是說(?:xx) 是為了方便我們寫正則更加清晰,有括號輔助。
c#例子來一個:
using System;
using System.Text.RegularExpressions;
public class Example
{
public static void Main()
{
string pattern = @"(?:\b(?:\w+)\W*)+\.";
string input = "This is a short sentence.";
Match match = Regex.Match(input, pattern);
Console.WriteLine("Match: {0}", match.Value);
for (int ctr = 1; ctr < match.Groups.Count; ctr++)
Console.WriteLine(" Group {0}: {1}", ctr, match.Groups[ctr].Value);
}
}
// The example displays the following output:
// Match: This is a short sentence.
原子分組
原子分組應該是關閉回溯。
很多人不理解回溯哈,在此特意解釋一下:
通常,如果正則表示式包含一個可選或可替代匹配模式並且備選不成功的話,正則表示式引擎可以在多個方向上分支以將輸入的字串與某種模式進行匹配。
如果未找到使用第一個分支的匹配項,則正則表示式引擎可以備份或回溯到使用第一個匹配項的點並嘗試使用第二個分支的匹配項。
此過程可繼續進行,直到嘗試所有分支。
我找到了一個例子:
using System;
using System.Text.RegularExpressions;
public class Example
{
public static void Main()
{
string[] inputs = { "cccd.", "aaad", "aaaa" };
string back = @"(\w)\1+.\b";
string noback = @"(?>(\w)\1+).\b";
foreach (string input in inputs)
{
Match match1 = Regex.Match(input, back);
Match match2 = Regex.Match(input, noback);
Console.WriteLine("{0}: ", input);
Console.Write(" Backtracking : ");
if (match1.Success)
Console.WriteLine(match1.Value);
else
Console.WriteLine("No match");
Console.Write(" Nonbacktracking: ");
if (match2.Success)
Console.WriteLine(match2.Value);
else
Console.WriteLine("No match");
}
}
}
// The example displays the following output:
// cccd.:
// Backtracking : cccd
// Nonbacktracking: cccd
// aaad:
// Backtracking : aaad
// Nonbacktracking: aaad
// aaaa:
// Backtracking : aaaa
// Nonbacktracking: No match
為什麼最後一個aaaa,不會被匹配呢?
分析一下:
@"(?>(\w)\1+).\b"
(\w) 捕獲分組,也就是說被捉住的是a。
那麼\1+ 就是是說匹配0或者多個a,然後呢由於原子性,那麼是貪婪的,他就會匹配aaaa,也就是匹配完了,那麼你剩下一個.(任意字元),就不能匹配了。
總結
以上僅僅是個人理解,如有不對,望請指出