
手寫一個簡單的HashMap
HashMap簡介
HashMap是Java中一中非常常用的資料結構,也基本是面試中的“必考題”。它實現了基於“K-V”形式的鍵值對的高效存取。JDK1.7之前,HashMap是基於陣列+連結串列實現的,1.8以後,HashMap的底層實現中加入了紅黑樹用於提升查詢效率。
HashMap根據存入的鍵值對中的key計算對應的index,也就是它在陣列中的儲存位置。當發生雜湊衝突時,即不同的key計算出了相同的index,HashMap就會在對應位置生成連結串列。當連結串列的長度超過8時,連結串列就會轉化為紅黑樹。
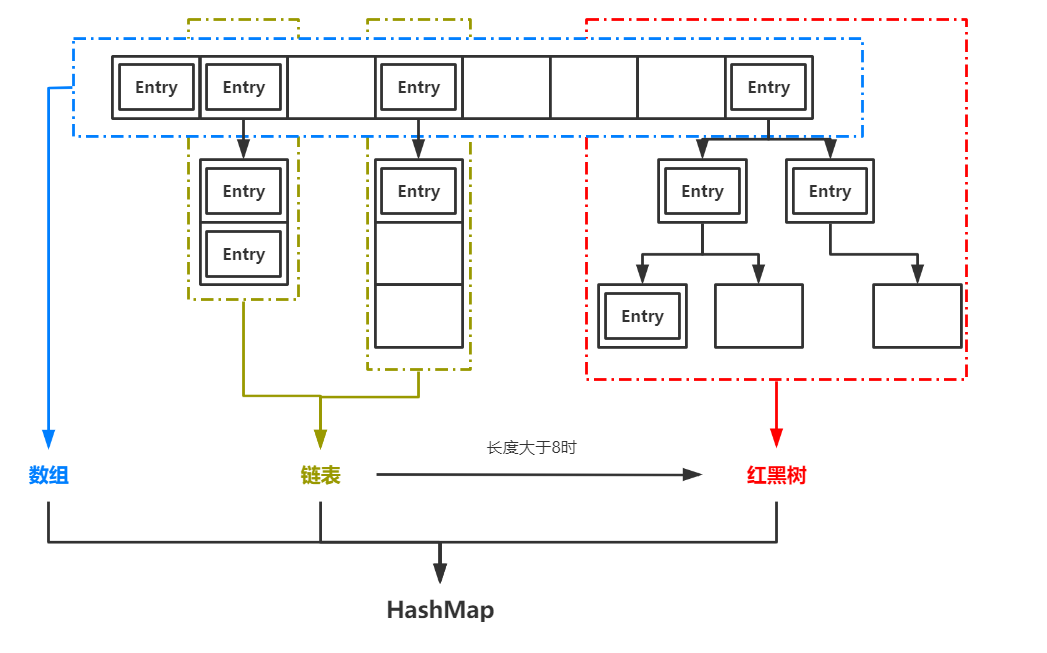
手寫HashMap之前,我們討論一個小問題:當我們在HashMap中根據key查詢value時,在陣列、連結串列、紅黑樹三種情況下,平均要做多少次比較?
在陣列中查詢時,我們可以通過key的hashcode直接計算它在陣列中的位置,比較次數為1
在連結串列中查詢時,根據next引用依次比較各個節點的key,長度為n的連結串列節點平均比較次數為n/2
在紅黑樹中查詢時,由於紅黑樹的特性,節點數為n的紅黑樹平均比較次數為log(n)
前面我們提到,連結串列長度超過8時樹化(TREEIFY),正是因為n=8,就是log(n) < n/2的閾值。而n<6時,log(n) > n/2,紅黑樹解除樹化(UNTREEIFY)。另外我們可以看到,想要提高HashMap的效率,最重要的就是儘量避免生成連結串列,或者說盡量減少連結串列的長度,避免雜湊衝突,降低key的比較次數。
手寫HashMap
定義一個Map介面
也可以使用Java中的java.util.Map
public interface MyMap<K,V> {
V put(K k, V v);
V get(K k);
int size();
V remove(K k);
boolean isEmpty();
void clear();
}
然後編寫一個MyHashMap類,實現這個介面,並實現裡面的方法。
成員變數
final static int DEFAULT_CAPACITY = 16; final static float DEFAULT_LOAD_FACTOR = 0.75f; int capacity; float loadFactor; int size = 0; Entry<K,V>[] table;
class Entry<K, V>{
K k;
V v;
Entry<K,V> next;
public Entry(K k, V v, Entry<K, V> next){
this.k = k;
this.v = v;
this.next = next;
}
}
我們參照HashMap設定一個預設的容量capacity和預設的載入因子loadFactor,table就是底層陣列,Entry類儲存了"K-V"資料,next欄位表明它可能會是一個連結串列節點。
構造方法
public MyHashMap(){
this(DEFAULT_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public MyHashMap(int capacity, float loadFactor){
this.capacity = upperMinPowerOf2(capacity);
this.loadFactor = loadFactor;
this.table = new Entry[capacity];
}
這裡的upperMinPowerOf2的作用是獲取大於capacity的最小的2次冪。在HashMap中,開發者採用了更精妙的位運算的方式完成了這個功能,效率比這種方式要更高。
private static int upperMinPowerOf2(int n){
int power = 1;
while(power <= n){
power *= 2;
}
return power;
}
為什麼HashMap的capacity一定要是2次冪呢?這是為了方便HashMap中的陣列擴容時已存在元素的重新雜湊(rehash)考慮的。
put方法
@Override
public V put(K k, V v) {
// 通過hashcode雜湊
int index = k.hashCode() % table.length;
Entry<K, V> current = table[index];
// 判斷table[index]是否已存在元素
// 是
if(current != null){
// 遍歷連結串列是否有相等key, 有則替換且返回舊值
while(current != null){
if(current.k == k){
V oldValue = current.v;
current.v = v;
return oldValue;
}
current = current.next;
}
// 沒有則使用頭插法
table[index] = new Entry<K, V>(k, v, table[index]);
size++;
return null;
}
// table[index]為空 直接賦值
table[index] = new Entry<K, V>(k, v, null);
size++;
return null;
}
put方法中,我們通過傳入的K-V值構建一個Entry物件,然後判斷它應該被放在陣列的那個位置。回想我們之前的論斷:
想要提高HashMap的效率,最重要的就是儘量避免生成連結串列,或者說盡量減少連結串列的長度
想要達到這一點,我們需要Entry物件儘可能均勻地散佈在陣列table中,且index不能超過table的長度,很明顯,取模運算很符合我們的需求int index = k.hashCode() % table.length。關於這一點,HashMap中也使用了一種效率更高的方法——通過&運算完成key的雜湊,有興趣的同學可以檢視HashMap的原始碼。
如果table[index]處已存在元素,說明將要形成連結串列。我們首先遍歷這個連結串列(長度為1也視作連結串列),如果存在key與我們存入的key相等,則替換並返回舊值;如果不存在,則將新節點插入連結串列。插入連結串列又有兩種做法:頭插法和尾插法。如果使用尾插法,我們需要遍歷這個連結串列,將新節點插入末尾;如果使用頭插法,我們只需要將table[index]的引用指向新節點,然後將新節點的next引用指向原來table[index]位置的節點即可,這也是HashMap中的做法。

如果table[index]處為空,將新的Entry物件直接插入即可。
get方法
@Override
public V get(K k) {
int index = k.hashCode() % table.length;
Entry<K, V> current = table[index];
// 遍歷連結串列
while(current != null){
if(current.k == k){
return current.v;
}
current = current.next;
}
return null;
}
呼叫get方法時,我們根據key的hashcode計算它對應的index,然後直接去table中的對應位置查詢即可,如果有連結串列就遍歷。
remove方法
@Override
public V remove(K k) {
int index = k.hashCode() % table.length;
Entry<K, V> current = table[index];
// 如果直接匹配第一個節點
if(current.k == k){
table[index] = null;
size--;
return current.v;
}
// 在連結串列中刪除節點
while(current.next != null){
if(current.next.k == k){
V oldValue = current.next.v;
current.next = current.next.next;
size--;
return oldValue;
}
current = current.next;
}
return null;
}
移除某個節點時,如果該key對應的index處沒有形成連結串列,那麼直接置為null。如果存在連結串列,我們需要將目標節點的前驅節點的next引用指向目標節點的後繼節點。由於我們的Entry節點沒有previous引用,因此我們要基於目標節點的前驅節點進行操作,即:
current.next = current.next.next;
current代表我們要刪除的節點的前驅節點。
還有一些簡單的size()、isEmpty()等方法都很簡單,這裡就不再贅述。現在,我們自定義的MyHashMap基本可以使用了。
最後
關於HashMap的實現,還有幾點我們沒有解決:
- 擴容問題。在HashMap中,當儲存的元素數量超過閾值(threshold = capacity * loadFactor)時,HashMap就會發生擴容(resize),然後將內部的所有元素進行rehash,使hash衝突儘可能減少。在我們的MyHashMap中,雖然定義了載入因子,但是並沒有使用它,capacity是固定的,雖然由於連結串列的存在,仍然可以一直存入資料,但是資料量增大時,查詢效率將急劇下降。
- 樹化問題(treeify)。我們之前講過,連結串列節點數量超過8時,為了更高的查詢效率,連結串列將轉化為紅黑樹。但是我們的程式碼中並沒有實現這個功能。
- null值的判斷。HashMap中是允許存null值的key的,key為null時,HashMap中的hash()方法會固定返回0,即key為null的值固定存在table[0]處。這個實現起來很簡單,不實現的情況下MyHashMap中如果存入null值會直接報
NullPointerException異常。 - 一些其他問題。
相信大家自己完成了對HashMap的實現之後,對它的原理一定會有更深刻的認識,本文如果有錯誤或是不嚴謹的地方也歡迎大家指出。上述的問題我們接下來再逐步解決,至於紅黑樹,我也不會(攤手)