
這個教程,真的讓我學會了正則表示式
這個教程,真的讓我學會了正則表示式
這是一篇翻譯文章。我學過很多次正則表示式,總是學了忘,忘了學,一到用的時候還是隻能靠搜尋引擎。
這回看到這個正則教程,感覺非常驚喜。嘗試翻譯了一遍,譯得不好,大家可以看原文,很容易理解。
原文地址:https://refrf.shreyasminocha.me/
1 介紹
正則表示式允許定義一種模式,並通過這種模式針對字串執行對應的操作。與模式匹配的子字串稱為“匹配”。
正則表示式是定義搜尋模式的一串字元。
正則表示式主要用在如下場景:
- 輸入驗證
- 查詢替換操作
- 高階字串操作
- 檔案搜尋或重新命名
- 白名單和黑名單
正則表示式不太適合用在這些場景:
- XML 或 HTML 解析
- 完全匹配的日期
有許多實現正則匹配的引擎,每種都有自己的特性。這本書將避免討論(不同引擎之間的)特性差異,而是隻討論在大多數情況下不同引擎都共有的特徵。
整本書中的示例使用JavaScript。因此,這本書可能會稍微偏向 JavaScript 的正則引擎。
2 基礎
正則表示式通常格式化為 /<rules>/<flags>,通常為了簡潔而省略後面的 /<flags>。關於 flag 我們將在下一章詳細討論。
讓我們從/p/g 這個正則表示式開始。現在,請將 /g flag 視為固定不變的。
/p/g

如我們所見,/p/g 匹配所有小寫的 p 字元。
注意
預設情況下,正則表示式區分大小寫。
在輸入字串中找到的正則表示式模式的例項稱為“匹配”。
/pp/g

3 字元組
可以從一組字元中匹配一個字元。
/[aeiou]/g

[aeiou]/g 匹配輸入字串中的所有母音。
下面是另一個例子:
/p[aeiou]t/g

我們匹配一個 p,後跟一個母音,然後是一個 t。
有一個更直觀的快捷方式,可以在一個連續的範圍內匹配一個字元。
/[a-z]/g

警告
表示式
/[a-z]/g只匹配一個字元。在上面的示例中,每個字元都有一個單獨的匹配項。不是整個字串匹配。
我們也可以在正則表示式中組合範圍和單個字元。
/[A-Za-z0-9_-]/g

我們的正則表示式 /[A-Za-z0-9_-]/g
A-Za-z0-9_或者-
我們也可以“否定”這些規則:
/[^aeiou]/g

/[aeiou]/g與 /[^aeiou]/g 之間的唯一區別是 ^ 緊跟在左括號之後。其目的是"否定"括號中定義的規則。它表示的意思是:
匹配任何不屬於a、e、i、o和 u 的字元
3.1 例子
非法的使用者名稱字元
/[^a-zA-Z_0-9-]/g

指定字元
/[A-HJ-NP-Za-kmnp-z2-9]/g

4 字元轉義
字元轉義是對某些通用字元類的簡略表達方式。
4.1 數字字元 \d
轉義符 \d 表示匹配數字字元 0-9。等同於 [0-9]。
/\d/g(這裡請仔細看)
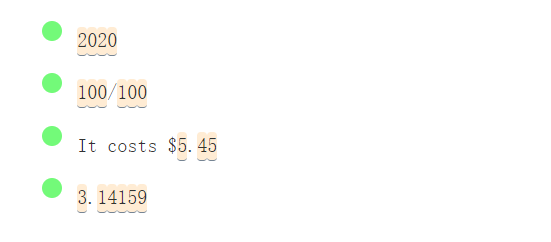 regular_expression_10-fs8.png
regular_expression_10-fs8.png
/\d\d/g
 regular_expression_11-fs8.png
regular_expression_11-fs8.png
\D是\d 的反面,相當於[^0-9]。
/\D/g
 regular_expression_12-fs8.png
regular_expression_12-fs8.png
4.2 單詞字元 \w
轉義符 \w 匹配單詞字元。包括:
- 小寫字母 a-z
- 大寫字母 A-Z
- 數字 0-9
- 下劃線 _
等價於 [a-zA-Z0-9_]
/\w/g
 regular_expression_13-fs8.png
regular_expression_13-fs8.png
/\W/g
 regular_expression_14-fs8.png
regular_expression_14-fs8.png
4.3 空白字元 \s
轉義符 \s匹配空白字元。具體匹配的字符集取決於正則表示式引擎,但大多數至少包括:
- 空格
- tab 製表符
\t - 回車
\r - 換行符
\n - 換頁
\f
其他還可能包括垂直製表符(\v)。Unicode自識別引擎通常匹配分隔符類別中的所有字元。然而,技術細節通常並不重要。
/\s/g
 regular_expression_15-fs8.png
regular_expression_15-fs8.png
/\S/g(大寫 s)
 regular_expression_16-fs8.png
regular_expression_16-fs8.png
4.4 任意字元 .
雖然不是典型的字元轉義。. 可以匹配任意1個字元。(除換行符 \n 以外,通過 dotall 修飾符,也可以匹配換行符 \n)
/./g
 regular_expression_17-fs8.png
regular_expression_17-fs8.png
5 轉義
在正則表示式中,有些字元有特殊的含義,我們將在這一章中進行探討:
|{,}(,)[,]^,$+,*,?\.只在字元類中的字面量。-: 有時是字元類中的特殊字元。
當我們想通過字面意思匹配這些字元時,我們可以再這些字元前面加
\“轉義”它們。
/\(paren\)/g
 regular_expression_18-fs8.png
regular_expression_18-fs8.png
/(paren)/g
 regular_expression_19-fs8.png
regular_expression_19-fs8.png
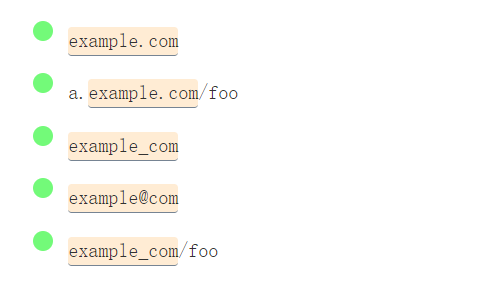
/example\.com/g
 regular_expression_20.png
regular_expression_20.png
/example.com/g
 regular_expression_21.png
regular_expression_21.png
/A\+/g
 regular_expression_22-fs8.png
regular_expression_22-fs8.png
/A+/g
 regular_expression_23-fs8.png
regular_expression_23-fs8.png
/worth \$5/g
 regular_expression_24-fs8.png
regular_expression_24-fs8.png
/worth $5/g
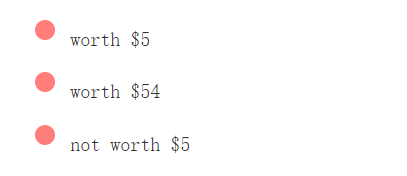 regular_expression_25-fs8.png
regular_expression_25-fs8.png
5.1 例子
JavaScript 內聯註釋
/\/\/.*
 regular_expression_26-fs8.png
regular_expression_26-fs8.png
星號包圍的子串
/*[^\*]*\*
 regular_expression_27-fs8.png
regular_expression_27-fs8.png
第一個和最後一個星號是字面上的,所有他們要用 \* 轉義。字符集裡面的星號不需要被轉義,但為了清楚起見,我還是轉義了它。緊跟在字符集後面的星號表示字符集的重複,我們將在後面的章節中對此進行探討。
6 組
顧名思義,組是用來“組合”正則表示式的元件的。這些組可用於:
- 提取匹配的子集
- 重複分組任意次數
- 參考先前匹配的子字串
- 增強可讀性
- 允許複雜的替換
這一章我們先學組如何工作,之後的章節還會有更多例子。
6.1 捕獲組
捕獲組用(…)表示。下面是一個解釋性的例子:
/a(bcd)e/g
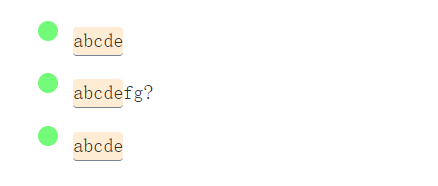 regular_expression_28-fs8.png
regular_expression_28-fs8.png
捕獲組允許提取部分匹配項。
/\{([^{}]*)\}/g
 regular_expression_29-fs8.png
regular_expression_29-fs8.png
通過語言的正則函式,您將能夠提取括號之間匹配的文字。
捕獲組還可以用於對正則表示式進行部分分組,以便於重複。雖然我們將在接下來的章節中詳細介紹重複,但這裡有一個示例演示了組的實用性。
/a(bcd)+e/g
 regular_expression_30-fs8.png
regular_expression_30-fs8.png
其他時候,它們用於對正則表示式的邏輯相似部分進行分組,以提高可讀性。
/(\d\d\d\d)-W(\d\d)/g
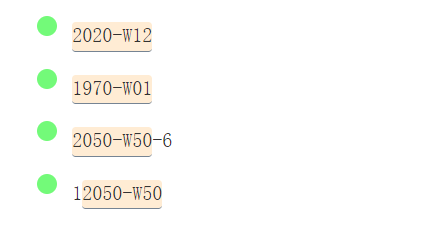 regular_expression_31-fs8.png
regular_expression_31-fs8.png
6.2 回溯
回溯允許引用之前捕獲的子字串。
匹配第一組可以使用 \1,匹配第二組可以使用 \2,依此類推…
/([abc])×\1×\1/g
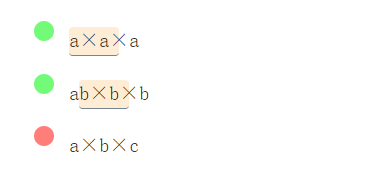 regular_expression_32-fs8.png
regular_expression_32-fs8.png
不能使用回溯來減少正則表示式中的重複。它們指的是組的匹配,而不是模式。
/[abc][abc][abc]/g
 regular_expression_33-fs8.png
regular_expression_33-fs8.png
/[abc]\1\1/g
 regular_expression_34-fs8.png
regular_expression_34-fs8.png
下面是一個演示常見用例的示例:
/\w+([,|])\w+\1\w+/g
 regular_expression_35-fs8.png
regular_expression_35-fs8.png
這不能通過重複的字元類來實現。
/\w+[,|]\w+[,|]\w+/g
 regular_expression_36-fs8.png
regular_expression_36-fs8.png
6.3 非捕獲組
非捕獲組與捕獲組非常相似,只是它們不建立“捕獲”。而是採取形式 (?: ...)
非捕獲組通常與捕獲組一起使用。也許您正在嘗試使用捕獲組提取匹配的某些部分。而你可能希望使用一個組而不擾亂捕獲順序,這時候你應該使用非捕獲組。
6.4 例子
查詢字串引數
/^\?(\w+)=(\w+)(?:&(\w+)=(\w+))*$/g
 regular_expression_37-fs8.png
regular_expression_37-fs8.png
我們單獨匹配第一組鍵值對,因為這可以讓我麼使用 & 分隔符, 作為重複組的一部分。
(基礎的) HTML 標籤
根據經驗,不要使用正則表示式來匹配 XML/HTML。不過,我還是提供相關的一個例子:
/<([a-z]+)+>(.*)<\/\1>/gi
 regular_expression_38-fs8.png
regular_expression_38-fs8.png
姓名
查詢:\b(\w+) (\w+)\b
替換: 1
在替換操作,經常使用 2;捕獲使用
\1,\2
替換之前
John Doe
Jane Doe
Sven Svensson
Janez Novak
Janez Kranjski
Tim Joe
替換之後
Doe, John
Doe, Jane
Svensson, Sven
Novak, Janez
Kranjski, Janez
Joe, Tim
回溯和複數
查詢: \bword(s?)\b
替換: phrase$1
替換之前
This is a paragraph with some words.
Some instances of the word "word" are in their plural form: "words".
Yet, some are in their singular form: "word".
替換之後
This is a paragraph with some phrases.
Some instances of the phrase "phrase" are in their plural form: "phrases".
Yet, some are in their singular form: "phrase".
7 重複
重複是一個強大而普遍的正則表示式特性。在正則表示式中有幾種表示重複的方法。
7.1 可選項
我們可以使用 ?將某一部分設定成可選的(0或者1次)。
/a?/g
 regular_expression_39-fs8.png
regular_expression_39-fs8.png
另一個例子:
/https?/g
 regular_expression_40-fs8.png
regular_expression_40-fs8.png
我們還可以讓捕獲組和非捕獲組程式設計可選的。
/url: (www\.)?example\.com/g
 regular_expression_41-fs8.png
regular_expression_41-fs8.png
7.2 零次或者多次
如果我們希望匹配零個或多個標記,可以用 * 作為字尾。
/a*/g
 regular_expression_42-fs8.png
regular_expression_42-fs8.png
我們的正則表示式甚至匹配一個空字串。
7.3 一次或者多次
如果我們希望匹配 1 個或多個標記,可以用 + 作為字尾。
/a+/g
 regular_expression_43-fs8.png
regular_expression_43-fs8.png
7.4 精確的 x 次
如果我們希望匹配特定的標記正好x次,我們可以新增{x}字尾。這在功能上等同於複製貼上該標記 x 次。
/a{3}/g
 regular_expression_44-fs8.png
regular_expression_44-fs8.png
下面是匹配大寫的六個字元的十六進位制顏色程式碼的例子。
/#[0-9A-F]{6}/g
 regular_expression_45-fs8.png
regular_expression_45-fs8.png
這裡,標記 {6} 應用於字符集 [0-9A-F]。
7.5 最小次和最大次之間
如果我們希望在最小次和最大次之間匹配一個特定標記,可以在這個標記後新增 {min,max}。
/a{2,4}/g
 regular_expression_46-fs8.png
regular_expression_46-fs8.png
警告
{min,max}中逗號後面不要有空格。
7.6 最少 x 次
如果我們希望匹配一個特定的標記最少 x 次,可以在標記後新增 {x,}。 和 {min, max} 類似,只是沒有上限了。
/a{2,}/g
 regular_expression_47-fs8.png
regular_expression_47-fs8.png
7.7 貪婪模式的注意事項
正則表示式預設使用貪婪模式。在貪婪模式下,會盡可能多的匹配符合要求的字元。
/a*/g
 regular_expression_48-fs8.png
regular_expression_48-fs8.png
/".*"/g
 regular_expression_49-fs8.png
regular_expression_49-fs8.png
在**重複操作符(?,*,+,...)**後面新增 ?,可以讓匹配變“懶”。
/".*?"/g
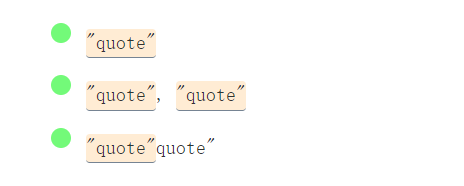 regular_expression_50-fs8.png
regular_expression_50-fs8.png
在這裡,這也可以通過使用[^"]代替。(這是最好的做法)。
/"[^"]*"/g
 regular_expression_51-fs8.png
regular_expression_51-fs8.png
懶惰,意味著只要條件滿足,就立即停止;但貪婪意味著只有條件不再滿足才停止。
-Andrew S on StackOverflow
/<.+>/g
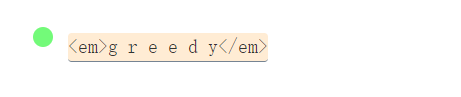 regular_expression_52-fs8.png
regular_expression_52-fs8.png
/<.+?>/g
 regular_expression_53-fs8.png
regular_expression_53-fs8.png
7.8 例子
比特幣地址
/([13][a-km-zA-HJ-NP-Z0-9]{26,33})/g(思考: {26,33}?呢)
 regular_expression_54-fs8.png
regular_expression_54-fs8.png
Youtube 視訊
/(?:https?: