
01_爬蟲基礎知識回顧
阿新 • • 發佈:2020-05-09
## 技術選型,爬蟲能做什麼?
### 1、Scrapy VS requests+beautifulsoup
- requests和beautifulsoup都是庫,Scrapy是框架。
- scrapy框架可以加入requests和beautifulsoup。
- scrapy是基於twisted,效能是最大的優勢。
- scrapy方便擴充套件,提供了很多內建的功能。
- scrapy內建的css和xpath selector非常方便,beautifulsoup最大的缺點就是慢。
### 2、爬蟲能做什麼?
- 搜尋引擎(百度、google、垂直領域搜尋引擎)。
- 推薦引擎(今日頭條、一點資訊)。
- 機器學習的資料樣本。
- 資料分析(如金融資料分析)、輿情分析。
## 正則表示式
- 貪婪模式:正則表示式一把趨向於最大長度的匹配,也就是所謂的貪婪匹配。
- 非貪婪匹配:就是匹配到結果就好,較少的匹配字元。
- 預設是貪婪模式,在兩次後面直接加上一個問號` ?`就是非貪婪模式。
### 1、特殊字元(原始字串'booby123')
- `^` : `^b` 以b開頭的字串
- `.` : 匹配任意字串
- `*` : 任意長度(次數),≥0
- `()` : 要取出的資訊就用括號括起來
- `?` : 非貪婪模式(從左邊開始匹配),儘可能少的匹配所搜尋的字串 `'.*?(b.*?b).*'`----從左至右第一個b和的二個b之間的內容(包含b)
- `+`:+ 前面的字元至少出現一次
- `{}` : 前面字元出現的次數
- `+`: 出現至少一次
- `{2}` :限定字元出現次數,2次
- `{2,5}`: 出現2-5次之間,後者需大於前者
- `|` :或”的關係,例如:“z|food”能匹配“z”或“food”(此處請謹慎)。“[z|f]ood”則匹配“zood”或“food”或"zood"。
- `()`:提取字串裡的值,(1)“第一個字串值”
- `[]`:滿足中括號內任意字元就行,進入後皆無特殊含義[.*]、區間[0-9]、具體數值[123]、不等於1[^1]
- `\s`:為空格 \S非空格
- `\w`:大小寫字、數字以及下劃線,等於:[A-Za-z0-9_]
- `\W`:匹配下劃線在內的任何單詞字元,[^A-Za-z0-9_]
- `\w`:和上一個相反
- `[\u4E00-\u9FA5]`:匹配所有中文
- `\d` :匹配數字
- `\D`:匹配所有非數字
### 2、正則表示式的運用
①貪婪模式
```python
line = "boooobaaaooobbbbby123"
regex_str = ".*?(b.*b).*" #貪婪模式,從右邊選擇b,.*(一個或者沒有),再到左邊最前面一個b。
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#group(1)表示匹配括號裡面的第一組,所以輸出:boooobaaaooobbbbb
```
②非貪婪模式
```python
line = "boooobaaaooobbbbby123"
regex_str = ".*?(b.*?b).*" #非貪婪模式,從左邊選擇b,.*(一個或者沒有),再到後面第一個b
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#group(1)表示匹配括號裡面的第一組,所以輸出:boooob
```
③年月日正則案例
```python
line = "XXX出生於2001年6/1"
line = "XXX出生於2001-6-1"
line = "XXX出生於2001-06-01"
line = "XXX出生於2001年6月1日"
line = "XXX出生於2001-6-1"
line = "XXX出生於2001-06-01"
line = "XXX出生於2001-06"
regex_str = ".*(\d{4}[年-]\d{1,2}([月 / -]\d{1,2}|[月 / - ]$|$))" #[月日時],滿足於具體數字月、日、時就可以
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
```
## 深度優先和廣度優先原理
### 1、深度優先和廣度優先
- **深度優先**:遞迴演算法,預設模式(A、B、D、E、I、C、F、G、H)
- **廣度優先**:層次演算法,佇列實現(A、B、C、D、E、F、G、H、I)
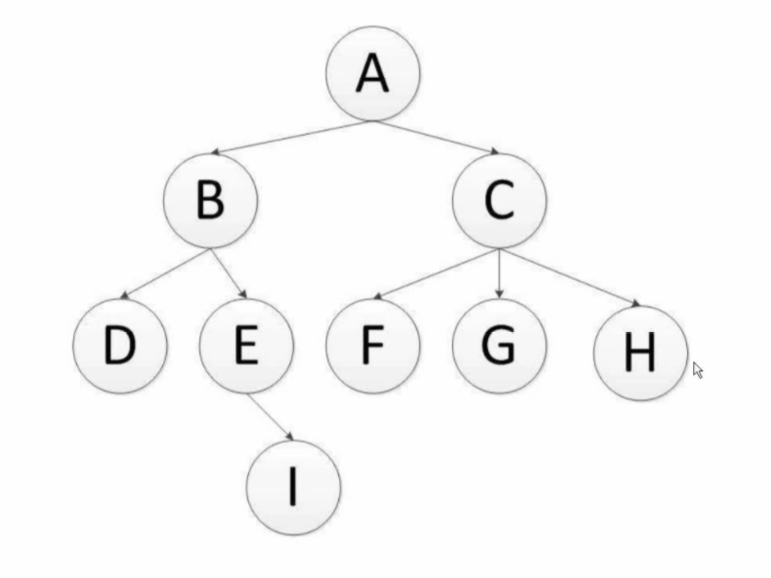
### 2、深度優先過程
**深度優先遍歷**:對每一個可能的分支路徑深入到不能再深入為止,而且每個結點只能訪問一次。二叉樹的深度優先遍歷的非遞迴的通用做法是採用棧,要特別注意的是,二叉樹的深度優先遍歷比較特殊,可以細分為先序遍歷、中序遍歷、後序遍歷。具體說明如下:
- 先序(根)遍歷:對任一子樹,先訪問根,然後遍歷其左子樹,最後遍歷其右子樹。
- 中序(根)遍歷:對任一子樹,先遍歷其左子樹,然後訪問根,最後遍歷其右子樹。
- 後序(根)遍歷:對任一子樹,先遍歷其左子樹,然後遍歷其右子樹,最後訪問根。
DFS的Python演算法描述:
```python
def depth_tree(tree_node):
"""
# 深度優先過程
:param tree_node:
:return:
"""
if tree_node is not None:
print(tree_node._data)
if tree_node._left is not None:
return depth_tree(tree_node._left)
if tree_node._right is not None:
return depth_tree(tree_node._right)
```
注:scrapy預設是通過深度優先來實現的。
### 3、廣度優先過程
**廣度優先遍歷**:又叫層次遍歷,從上往下對每一層依次訪問,在每一層中,從左往右(也可以從右往左)訪問結點,訪問完一層就進入下一層,直到沒有結點可以訪問為止。廣度優先遍歷的非遞迴的通用做法是採用佇列。
BFS的演算法描述:
```python
def level_queue(root):
"""
# 廣度優先過程
:param root:
:return:
"""
if root is None:
return
my_queue = []
node = root
my_queue.append(node)
while my_queue:
node = my_queue.pop(0)
print(node.elem)
if node.lchild is not None:
my_queue.append(node.lchild)
if node.rchild is not None:
my_queue.append(node.rchild)
```
**區別**:
通常深度優先搜尋法遍歷時不全部保留結點,遍歷完後的結點從棧中彈出刪去,這樣,一般在棧中儲存的結點數就是二叉樹的深度值,因此它佔用空間較少。所以,當搜尋樹的結點較多,用其它方法易產生記憶體溢位時,深度優先搜尋不失為一種有效的求解方法。 但深度優先搜素演算法有回溯操作(即有入棧、出棧操作),執行速度慢。
廣度優先搜尋演算法,一般需儲存產生的所有結點,佔用的儲存空間要比深度優先搜尋大得多,因此,程式設計中,必須考慮溢位和節省記憶體空間的問題。但廣度優先搜尋法一般無回溯操作,即入棧和出棧的操作,所以執行速度比深度優先搜尋要快些。
## url去重方法
### 1、爬蟲去重的策略
- 將訪問過的url儲存到資料庫中。
- 將訪問過的url儲存到set中,只要O(1)的代價就可以查詢url。(但是如果有1億個url,那麼很容易爆記憶體
)邏輯如下:
- 100000000 * 2byte * 50個字元 / 1024 / 1024 / 1024 ≈ 9G
- 使用`bitmap`方法,將訪問過的URL通過hash函式對映到某一位。(但是容易發生雜湊衝突,,即不同url雜湊值相同。)1億bit = 12.5MB記憶體
- bloomfilter方法對bitmap進一步優化,對bitmap進行了改進.,通過多個雜湊函式,,減少衝突的可能性。
## 徹底搞清楚unicode和utf8編碼
### 1、字串編碼
- 計算機本身只能處理數字,文字轉換為數字才能處理。計算機中8個bit作為一個位元組,所以一個位元組能表示最大的數字就是255。
- 計算機是美國人發明的,所以一個位元組可以表示所以字元了,所以ASCII(一個位元組)編碼就成為美國人的標準編碼。
- 但是ASCII處理中文明顯是不夠的,中文不止255個漢字,所以中國製定了GB2312編碼,用兩個位元組表示一個漢字。GB2312還把ASCII包含進去了,同理日文韓文等等上百個國家為了解決這個問題都發展了一套位元組的編碼,標準就越來越多,如果出現多種語言混合顯示就一定會出現亂碼。
- 於是unicode出現了,將所有語言統一到一套編碼裡。
- ASCII和unicode編碼:
- 字母A用ASCII編碼十進位制65,二進位制01000001
- 漢字"中"已超出了ASCII編碼的範圍,用unicode編碼是20013,二進位制01001110 00101101
- A用unicode編碼中只需要前面補0,二進位制是 00000000 01000001
- 亂碼問題解決了,但是如果內容全是英文,unicode編碼比ASCII需要多一倍的儲存空間,同時如果傳輸需要多一倍的傳輸。
- 所以出現了可變長的編碼“utf-8”,把英文變長一個位元組,漢字3個位元組。特別生僻的變成4-6位元組。如果傳輸大量的英文,utf-8作用就很明顯。
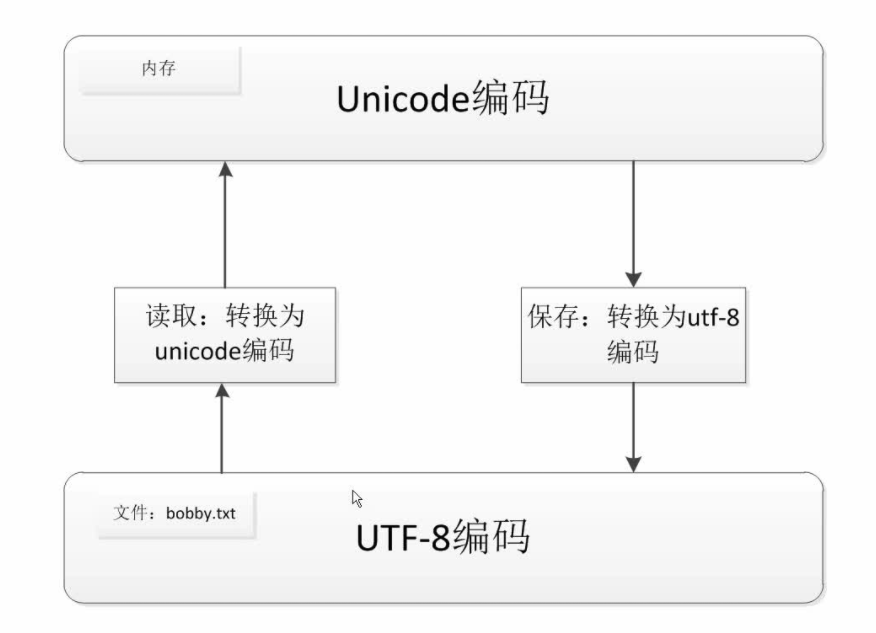
### 2、Python3的預設採用Unicode編碼
- `decode` 的方法是將bytes型別轉換為str型別(解碼)
- `encode`的方法是將str型別轉換為bytes型別(編碼)
```python
stingc = "我愛python"
print(stingc.encode('utf-8'))#encode的方法是將str型別轉換為bytes型別
string = stingc.encode('utf-8')
print(string.decode('utf-8'))#encode的方法是將str型別轉換為bytes型別(編