
Zookeeper 如何保證分散式系統資料一致性
阿新 • • 發佈:2020-05-19
## 寫在前面
分散式架構出現後,越來越多的分散式系統會面臨資料一致性的問題。目前,ZooKeeper 是在解決分散式資料一致性上最成熟穩定且被大規模應用的工業級解決方案。
ZooKeeper 保證 **分散式系統資料一致性的核心演算法就是 ZAB 協議**(ZooKeeper Atomic Broadcast,原子訊息廣播協議)。
## ZAB 協議
ZooKeeper 能夠保證資料一致性主要依賴於 ZAB 協議的 **訊息廣播,崩潰恢復和資料同步** 三個過程。

### 訊息廣播
1. 一個事務請求(Write)進來之後,Leader 節點會將寫請求包裝成 Proposal 事務,並新增一個全域性唯一的 64 位遞增事務 ID,也就是 Zxid(訊息的先後順序就是通過比較 Zxid);
2. Leader 節點向叢集中其他節點廣播 Proposal 事務,Leader 節點和 Follower 節點是解耦的,通訊都會經過一個 FIFO 的訊息佇列,Leader 會為每一個 Follower 節點分配一個單獨的 FIFO 佇列,然後把 Proposal 傳送到佇列中;
3. Follower 節點收到對應的 Proposal 之後會把它持久到磁碟上,當完全寫入之後,發一個 ACK 給 Leader;
4. 當 Leader 節點收到超過半數 Follower 節點的 ACK 之後(Quorum 機制),會提交本地機器上的事務,同時開始廣播 commit, Follower 節點收到 commit 之後,完成各自的事務提交。
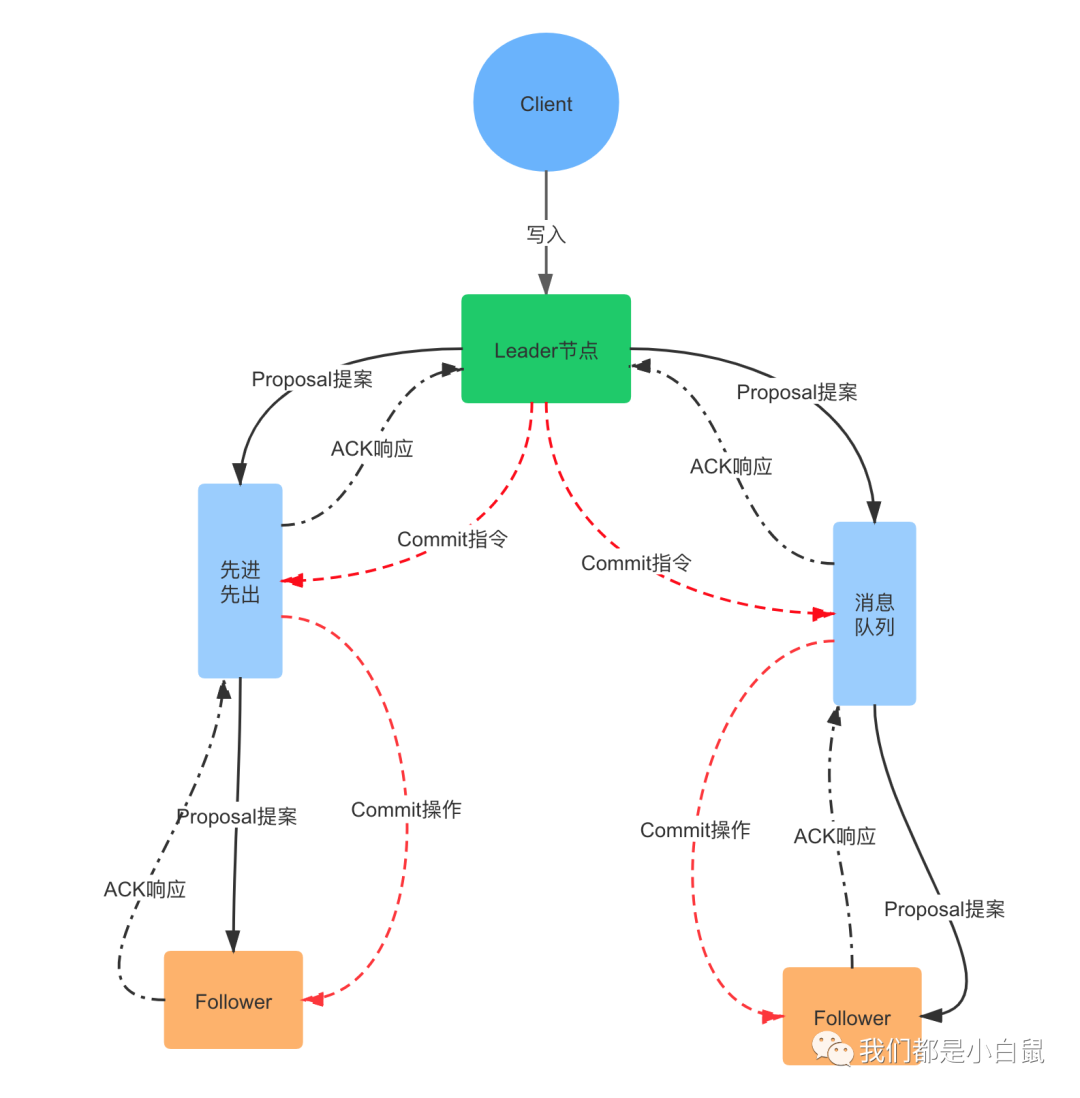
ZAB 協議針對事務請求的處理過程類似於一個兩階段提交過程,第一階段是廣播事務操作,第二階段是廣播提交操作,而在這種兩階段提交模型下,是無法處理因 Leader 節點宕機帶來的資料不一致問題的,比如下面兩種情況:
1. 當 Leader(Server1) 發起一個事務 Proposal1 後就宕機了,導致 Follower 都沒有 Proposal1。
2. 當 Leader 發起 Proposal2 後收到了半數以上的 Follower 的 ACK,但是還沒來得及向 Follower 節點發送 Commit 訊息就宕機了。
**為了解決 Leader 宕機以及宕機後導致的資料不一致問題,ZAB 協議引入了崩潰恢復模式**。
崩潰恢復模式必須解決以下問題:
1. Server1 恢復過來再次加入到叢集中的時候,必須確保丟棄 Proposal1,即保證被丟棄的訊息不能再次出現。
2. 選舉出的新 Leader 必須擁有叢集中所有機器 Zxid 最大的 Proposal,即保證已經被處理的訊息不能丟。
### 崩潰恢復
> Zookeeper 叢集進入崩潰恢復階段的時機:
>
> + 叢集服務剛啟動時進入崩潰恢復階段選取 Leader 節點。
>
> + Leader 節點突然宕機或者由於網路原因導致 Leader 節點與過半的 Follower 失去了聯絡,叢集也會進入崩潰恢復模式。
#### 選舉 Leader 節點
首先使用 Leader 選舉演算法選出一個新的 Leader 節點。選舉過程如下:
1. **各個節點變為 Looking 狀態**
Leader 宕機後,餘下的 Follower 節點都會將自己的狀態變更為 Looking(注意 Observer 不參與選舉),然後開始進入 Leader 選舉過程。
2. **各個 Server 節點都會發出一個投票,參與選舉**
在第一次投票中,所有的 Server 都會投自己,然後各自將投票傳送給叢集中所有機器。
3. **叢集接收來自各個伺服器的投票,開始處理投票和選舉**
處理投票的過程就是對比 Zxid 的過程,假定 Server3 的 Zxid 最大,Server1 判斷 Server3 可以成為 Leader,那麼 Server1 就投票給 Server3,判斷的依據如下:首先選舉 epoch 最大的,如果 epoch 相等,則選 zxid 最大的,若 epoch 和 zxid 都相等,則選擇 server id 最大的。
在選舉過程中,如果有節點獲得超過半數的投票數,則會成為 Leader 節點,反之則重新投票選舉。
4. **選舉成功,各節點的狀態為 Leading 和 Following**。
> Zab 中的節點有三種狀態,folloing(當前節點是 Follower 節點),leading(當前節點是 Leader 節點),looking/election(當前節點處於選舉狀態);伴隨著的 Zab 協議訊息廣播和崩潰恢復兩階段之間的轉換,節點狀態也隨之轉換。
### 資料同步
崩潰恢復完成選舉以後,接下來的工作就是資料同步,在選舉過程中,通過投票已經確認 Leader 節點是最大 Zxid 的節點,同步階段就是利用 Leader 前一階段獲得的最新 Proposal 歷史同步叢集中所有的副本。
## 總結
ZAB 協議是 CAP 理論中 CP 的典型實現,其崩潰恢復階段涉及到的 Leader 節點選舉過程和資料同步選舉完成後的資料同步過程都是對外不提供服務的,就是為了保證資料的強一致性犧牲了可用性。到這裡,關於 ZooKeeper 使用 ZAB 協議保證分散式系統下資料一致性已經分析完了,有關於 Paxos 演算法以及 ZAB 協議與 Paxos 演算法之間的聯絡這裡不做詳細分析,有興趣的小夥伴可以查閱《從 Paxos 到 ZooKeeper 分散式一致性原理與實戰》這本書,裡面有詳細的介紹。
#### 參考
《從 Paxos 到 ZooKeeper 分散式一致性原理與實戰》
《分散式技術原理與實戰 45 講》
## 最後
如果大家想要實時關注我更新的文章以及我分享的乾貨的話,可以關注我的公眾號 **我們都是小白鼠**。
![](https://img2020.cnblogs.com/blog/1326851/202003/1326851-20200307235900287-6131140