
如何選出適合自己的管理Helm Chart的最佳方式?
阿新 • • 發佈:2020-06-03
>作者:Merlin Carter,專注於早期創業公司的風險投資家,擅長撰寫開發人員創新和新技術的文章
>
>原文連結:
>https://insights.project-a.com/whats-the-best-way-to-manage-helm-charts-1cbf2614ec40
本文轉載自[Rancher Labs](https://mp.weixin.qq.com/s/ChPCoTyesGgpK77LN4EDOA "Rancher Labs")
無論你喜歡與否,你都不得不承認Helm是管理Kubernetes應用程式獨一無二的工具,你甚至可以通過不同的方式使用它。
在Helm的使用過程中,我們注意到有幾個問題不斷出現:
- 你將你的Helm chart放在哪裡?
你是使用app檔案儲存它們還是使用chart倉庫?
- 你如何劃分Helm chart?
你是使用一個共享的chart或是為每個服務維護一個chart?
我正在通過我以往在各種創業公司的經驗來嘗試解決這些問題,但是我也借鑑了大型公司的做法。
以下是我要概述的幾個方法:
1. 使用一個chart倉庫來儲存一個大型共享chart
2. 使用一個chart倉庫來儲存許多特定於服務的chart
3. 使用特定於服務的chart,這些chart與服務本身儲存在同一倉庫中
然後,我將介紹在決定這些選項時應該考慮的因素,例如依賴項差異和團隊結構等。

## Option1:在一個chart倉庫中維護一個大型共享chart
在我們一個專案中,我們從一個用於部署多個服務的大型chart開始。它儲存在ChartMuseum中,並由負責部署基礎架構的人員進行維護。
如果你的各個服務在本質上十分類似,那麼共享chart可以為你省去很多麻煩。這裡我們採用Helm維護者Josh Dolitsky在KubeCon 2019上描述的情況:
我最近在負責一個專案,這個專案包含9個微服務……我意識到它們幾乎都是相同的HTTP監聽服務。所以我決定僅僅構建一個helm chart來部署9個不同的服務,為每個服務做不同的配置——僅為特定的服務設定一個新的docker標籤。
在這種情況下,將Helm chart儲存在ChartMuseum等chart倉庫中是有意義的,因為只有值需要儲存在這些特定服務的倉庫中。
## Option2:在一個chart倉庫中維護幾個特定於服務的chart
特定於服務的chart優勢在於,你可以更改一項服務,而無需擔心會破壞另一項服務。但是它們可能會導致重複的工作——如果你要更新通用配置,則必須在每個chart中進行相同的更改。
是否需要在一個chart倉庫中儲存它們則是另一個問題了。如果這些chart是特定於服務的,那麼將它們儲存在一起尚沒有強有力的架構論證。當然,如果你有專門的人員或團隊來維護所有的chart,一起儲存多個特定於服務的chart通常會比較容易。
例如,與我一起工作的一位DevOps工程師,他在一箇中心chart倉庫中維護15種不同的微服務chart。對於他而言,在同一個位置更新所有chart比向15個不同的倉庫提交拉取請求要容易得多。開發人員當然清楚如何更新chart,但是處理資源相關的設定顯然更吸引他們。
## Option3:在與服務本身相同的倉庫種維護特定於服務的chart
對於基於微服務的應用程式來說,特定於服務的chart是一個很好的選擇。而當你將每個chart與服務程式碼儲存在同一倉庫中時,使用特定於服務的chart則會更好。
如果你在服務倉庫中儲存Helm chart,那麼可以更輕鬆地獨立於其他專案持續部署服務。並且你可以將chart更新(例如新增新變數)與應用程式邏輯的更改一起提交,使其更易於識別和還原重大更改。
然而,本選項的優勢取決於你所維護的微服務的數量。如果你的微服務數量正邁入兩位數,那麼這一選項的優勢則沒有那麼明顯,更多的是阻礙。如果你要處理非常同質的服務(如Josh Dolisky),則尤其如此。
## 決定選項時需要考慮的因素
一般情況下,有兩個方面需要考慮:
- **依賴項和可重現**:每個服務的依賴項有多少區別?對一個服務的更改有多大風險會中斷另一個服務?你如何再現特定的開發條件?
- **團隊結構**:你負責每個服務的小型自治團隊嗎?你有了解DevOps的開發人員嗎?你的團隊中DevOps文化流行程度如何?
## 依賴項和可重現
如果你將你的chart和應用程式分開維護,它們的版本將彼此不同。如果你在部署時遇到問題,並且需要重現導致該問題的條件,則需要確定:a)服務版本;b)用於部署它的chart版本。你可能想要走捷徑,使用“latest” chart來測試服務x.x.x,但這並不是一個好想法,因為這樣你將永遠無法重現造成問題的確切條件。
那麼,如果你經常需要更改的chart版本怎麼辦?是不是應該一起測試這些改動呢?
考慮到許多開發人員需要建立同一共享chart中的分支版本這一場景:
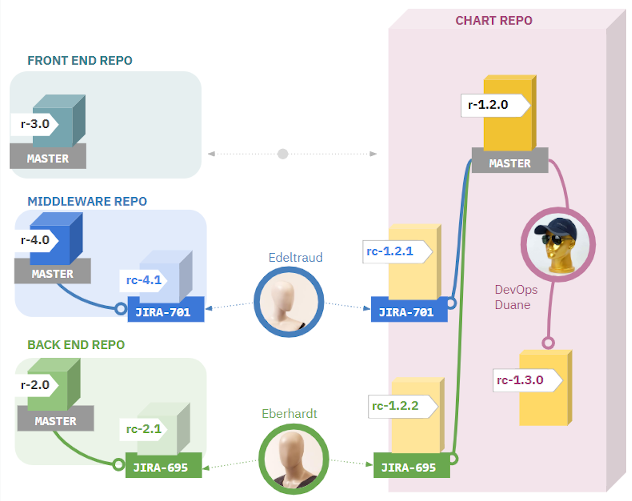
開發人員(圖中的Edeltraud和Eberhardt)分別在不同的分支中工作,並且想要在開發環境中測試他們的更改以及圖表更改——所以他們還需要分支chart。同時,DevOps工程師在他的共享chart的分支中更新一些常用元件。
如果沒有人將他們的chart更改更新到各個分支,那麼就有可能破壞另一個服務部署。
不久前,我們正好遇到了這個問題。Chart維護者用一個新的條件塊更新了共享chart。該語句檢查了一個新的變數“foo”是否被設定為“啟用”。然而,變數“foo”還沒有在所有服務的值檔案中定義。對於缺少該變數的服務,部署中斷了。不幸的是,當時chart中沒有定義預設的回滾行為。
如果chart和程式碼位於同一個倉庫中,並且可以在同一個分支中進行測試,則針對這些問題的測試將更加容易。
即使一開始似乎是矯枉過正,我們也會這樣做。我們的工作物件是很少有依賴項的服務。對於每個服務,Helm chart只部署一個帶有特定Docker標籤的主容器。chart的名稱和docker標籤是通過變數傳遞進來的。儘管如此,我們仍然避免了使用共享chart,而是選擇在每個服務倉庫中放置單獨的chart。
這主要是因為我們只處理了四個服務。但我們的開發人員也更喜歡掌控所有能夠影響CI/CD的配置。然而情況並非總是如此,所以現在是研究另一個維度的好時機。
## 團隊結構
Chart維護的問題同時也取決於誰管理部署流程。
這裡推薦另一篇文章,由Helm維護者Matt Farina撰寫的,在文章中他闡述了關於Helm正在嘗試解決複雜性的話題。文章連結:
https://codeengineered.com/blog/2018/helm-kustomize-complexity/
他闡明瞭必須處理Kubernetes複雜性的三個主要角色。為了清楚起見,我將對其內容進行一些解釋,並將角色描述如下:
1. App開發人員——這個角色主要構建服務、新增特性以及修復bug
2. Deployer——這個角色負責將應用程式推向世界。理想情況下,有一個不錯的自動化程式可以為他們部署應用程式,但是他們知道它的工作方式,可以根據需要進行修改。
3. 系統工程師——這一角色負責維護deployer部署的Kubernetes環境。他們是管理計算機資源的專家,並且可以儘量減少任何服務的停機時間。
第一個和第三個角色你都能在公司裡找到與其負責內容相符的職位,而Deployer這個角色則有些模糊,這個角色所負責的內容常常會被其他兩個角色的人接管——這會影響你如何管理你的Helm chart。
## 尚在早期階段的初創公司的DevOps
如前所述,我們的業務是為初創企業提供運維支援,這些企業往往需要快速擴大規模。我們見過很多“非常規”的設定和分工。在早期階段,App開發者可能會負責各種事情,有些人甚至會幫忙完成系統管理員的任務,比如設定印表機或配置辦公室網路等。他們會盡力去了解其他兩個角色所需要負責的內容,因為沒有人可以幫助他們(直到我們參與進來)。
一旦他們想了解Helm,大多數應用開發者會把他們的chart放在最容易處理的地方——也就是他們維護的同一個repo。
## 在大型企業中的DevOps
你可能在一個更大的、架構更分明的團隊中工作,
在這種情況下,你可能有自己的DevOps工程師甚至是整個DevOps部門。而這個人或團隊經常會覺得自己也要負責 “Deployer”的角色。很有可能,他們會傾向於採用更集中的方法,比如將所有的chart儲存在ChartMuseum這樣的chart倉庫中。更不願意讓應用開發者過多地參與到Helm chart中來(往往是有合理緣由的)。
例如,我最近看了一個經典的技術講座,叫《從頭開始構建Helm chart》,由VMWare系統工程師Amy Chen主講。在她的開場白中,她說:
> 在基礎設施方面,你的主要目標是時刻準備著應對故障,沒有信任——在這個意義上說,就像我不太願意信任我的APP開發者,並且我也不太需要信任我的APP開發者。
這是可以理解的。你不想讓應用開發者去搞亂設定,比如CPU和記憶體限制,或者是pod中斷預算。但整個 “DevOps文化”的概念是專門為了改善基礎設施維護者和開發者之間有時會出現的疏離關係而演化出來的。
## 實踐DveOps文化
Atlassian(JIRA和Trello的所有者)出版了一本“團隊手冊”,其中定義了DevOps文化:
> DevOps文化是關於開發者和運維之間的共同理解,併為他們所構建的軟體分擔責任。這意味著增加透明度、溝通和協作,並在開發、IT/運維和 “業務”之間進行合作。
如果將其實際應用到Helm chart維護和一般的基礎架構配置中,就會把大部分的責任放在應用開發者的手中。他們也會承擔起“Deployer”的角色,並改變他們擁有的倉庫中的配置。
系統工程師仍然可以把他們專門維護的設定集中起來。例如,一些團隊也會維護一箇中央基礎架構repo,該repo中儲存著Terraform配置或Helm檔案等常用資源,這些資源是啟動新專案所需要的(例如,用於設定ingress controller和cert manager)。Helm 3還支援所謂的 “library chart”,它只能作為另一個chart的一部分進行部署。這讓我們更容易區分常見的和服務特定的變更責任。
即使當chart儲存在服務倉庫中,系統工程師仍然可以作為重要更改的把關人。例如,你可以使用GitHub CODEOWNERS檔案來確保系統工程師在你的repo中的chart目錄中的任何更改都會被新增為稽核者。
如果系統工程師需要主動做一些與應用開發無關的改動,可以指導開發人員為他們做更改,並解釋為什麼這些改動是必須的。以下圖片也許能反映這種情況:
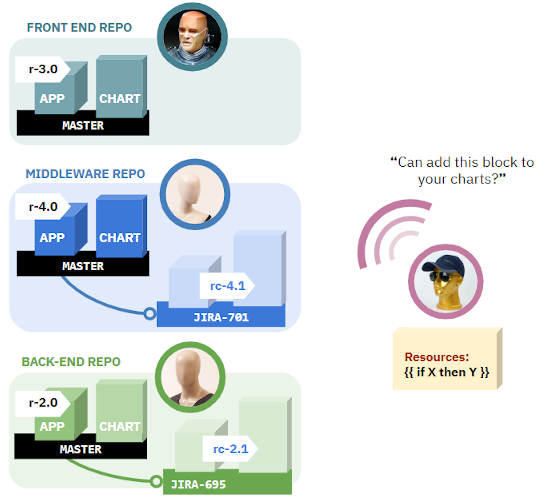
開發者可以瞭解更多關於基礎設施的內容以及這些更改如何影響他們的服務。
## 經驗法則
如果有簡單的經驗法則,那就是:先了解選項3。嘗試為服務倉庫中的每個服務維護一個Helm chart。或者至少考慮一下我之前描述的混合方法。
如果你有幾十個服務都非常相似,那麼共享chart是更好的選擇。只是要記住,你必須把它維護在一箇中心repo中。但是這增加了意外耦合的風險,可能會破壞一個服務部署。風險增加意味著你在部署的時候需要更加謹慎,這反過來又意味著你會減少部署的頻率。
即使你有特定服務的chart,你可能也需要集中儲存,因為你沒有足夠的人員或專業知識以分散式的方式來管理這些chart。或者,也許你的團隊需要在“Deployer”和“應用開發者”之間明確劃分責任。
無論你決定做什麼,我希望我已經說明清楚了你在做最後決定時需要考慮的問題。做一個“Deployer”並不容易,尤其是當它不是你的日常工