
環境篇:嘔心瀝血@CDH線上調優
阿新 • • 發佈:2020-06-12
# 環境篇:嘔心瀝血@CDH線上調優

- 為什麼出這篇文章?
> 近期有很多公司開始引入大資料,由於各方資源有限,並不能合理分配伺服器資源,和伺服器選型,小葉這裡將工作中的總結出來,給新入行的小夥伴帶個方向,不敢說一定對,但是本人親自測試,發現叢集使用率穩定提高了3分之1,最高可達到2分之1,有不對的地方歡迎留言指出。
>
> 注:可能有些服務沒有設計,使用到的小夥伴可以參照這種方式去規劃。
## 0 資源:叢集服務安排
| 服務名稱 | 子服務 | CM-64G | ZK-Kafka(3臺)-12G | DataNode(3臺)-64G | NameNode1-64G | NameNode2-64G | Resourcemanager1-32G | Resourcemanager2-32G | hive-hbase-16G | hive-hbase-16G |
| --------- | ------------------------------------------------------------ | ------------------------------ | ----------------- | ------------------------ | ------------------------ | ------------------------ | ------------------------ | -------------------- | ------------------ | ------------------ |
| MySQL | MySQL | √ | | | | | | | | |
| CM | Activity Monitor
Event Server
Host Monitor
Service Monitor | √
√
√
√
√
| | | | | | | | | | HDFS | NameNode
DataNode
Failover Controller
√
X
X
| √
X
√
√
| √
X
√
√
| X
X
X
√
| | | | | Yarn | NodeManager
Resourcemanager
JobHisoryServer | | | √
X
X
| | | X
√
| X
√
√
| | | | Zookeeper | Zookeeper Server | | √ | | | | | | | | | Kafka | Kafka Broker | | √ | | | | | | | | | Hive | Hive Metastore Server
HiveServer2
Gateway(安裝對應應用伺服器) | | | X
√
√
| | | | | √
X
√
| √
X
√
| | Hbase | HMaster
HRegionServer
Thrift Server | | | X
√
√ | | | | | √
X
| √
X
| | Oozie | Oozie Server | | | | | | √ | | | | | Hue | Hue Server
Load Balancer | | | | | | X
√ | √
X
| | | | Spark | History Server
Gateway(安裝對應應用伺服器) | | | | | | | √
X
| | | | Flume | Flume Agent (安裝對應應用伺服器) | | | | | | | | | | | Sqoop | Sqoop(安裝對應應用伺服器) | | | | | | | | | | ## 1 優化:Cloudera Management ### 1.1 Cloudera Management Service > 這些服務主要是提供監控功能,目前的調整主要集中在記憶體放,以便有足夠的資源 完成叢集管理。 | 服務 | 選項 | 配置值 | | ------------------------- | -------------- | ------ | | Activity Monitor | Java Heap Size | 2G | | Alert Publisher | Java Heap Size | 2G | | Event Server | Java Heap Size | 2G | | Host Monitor | Java Heap Size | 4G | | Service Monitor | Java Heap Size | 4G | | Reports Manager | Java Heap Size | 2G | | Navigator Metadata Server | Java Heap Size | 8G | ## 2 優化:Zookeeper | 服務 | 選項 | 配置值 | | --------- | ------------------------------------- | ------------------------------------ | | Zookeeper | Java Heap Size (堆疊大小) | 4G | | Zookeeper | maxClientCnxns (最大客戶端連線數) | 1024 | | Zookeeper | dataDir (資料檔案目錄+資料持久化路徑) | /hadoop/zookeeper (建議獨立目錄) | | Zookeeper | dataLogDir (事務日誌目錄) | /hadoop/zookeeper_log (建議獨立目錄) | ## 3 優化:HDFS ### 3.1 磁碟測試 #### 3.1.1 讀測試 > **hdparm** 用於檢視硬碟的相關資訊或對硬碟進行測速、優化、修改硬碟相關引數設定 ```java #安裝hdparm yum install hdparm #獲取硬碟符 fdisk -l #讀測試(讀取上一步獲取硬碟符) hdparm -t /dev/vda ``` > 三次測試結果: > > Timing buffered disk reads: 500 MB in 0.84 seconds = 593.64 MB/sec > > Timing buffered disk reads: 500 MB in 0.93 seconds = 538.80 MB/sec > > Timing buffered disk reads: 500 MB in 0.74 seconds = 672.95 MB/sec > > 說明:接近1s秒讀取了500MB磁碟,讀速度約 500 MB/秒 #### 3.1.2 寫測試 > **dd** 這裡使用 time + dd 簡單測試寫速度,不要求很精確 ```java 檢視記憶體快取情況 free -m 清除快取 sync; echo 3 > /proc/sys/vm/drop_caches 查block size blockdev --getbsz /dev/vda 寫測試 echo 3 > /proc/sys/vm/drop_caches; time dd if=/dev/zero of=/testdd bs=4k count=100000 ``` >三次測試結果: > >記錄了100000+0 的讀入 >記錄了100000+0 的寫出 > >409600000 bytes (410 MB) copied, 0.574066 s, 714 MB/s --410MB複製,用時0.57秒,評估714M/s > >409600000 bytes (410 MB) copied, 1.84421 s, 222 MB/s --410MB複製,用時1.84秒,評估222 M/s > >409600000 bytes (410 MB) copied, 1.06969 s, 383 MB/s --410MB複製,用時1.06秒,評估383M/s #### 3.1.3 網路頻寬 > iperf3測量一個網路最大頻寬 ```java #安裝iperf3 yum -y install iperf3 #服務端 iperf3 -s #客戶端 iperf3 -c 上調命令執行的服務機器IP ``` > 測試結果: | [ ID]-->執行緒id | Interva-->傳輸時間 | Transfer-->接收資料大小 | Bandwidth-->頻寬每秒大小 | Retr | 角色 | | -------------- | ------------------ | ----------------------- | ------------------------ | ---- | --------------- | | [ 4] | 0.00-10.00 sec | 17.0 GBytes | 14.6 Gbits/sec | 0 | sender-->傳送 | | [ 4] | 0.00-10.00 sec | 17.0 GBytes | 14.6 Gbits/sec | | receiver-->接收 | ### 3.2 官方壓測 #### 3.2.1 使用者準備 > 由於只能使用yarn配置了允許使用者,故這裡選擇hive使用者,如果su hive不能進入,則需要配置該步驟 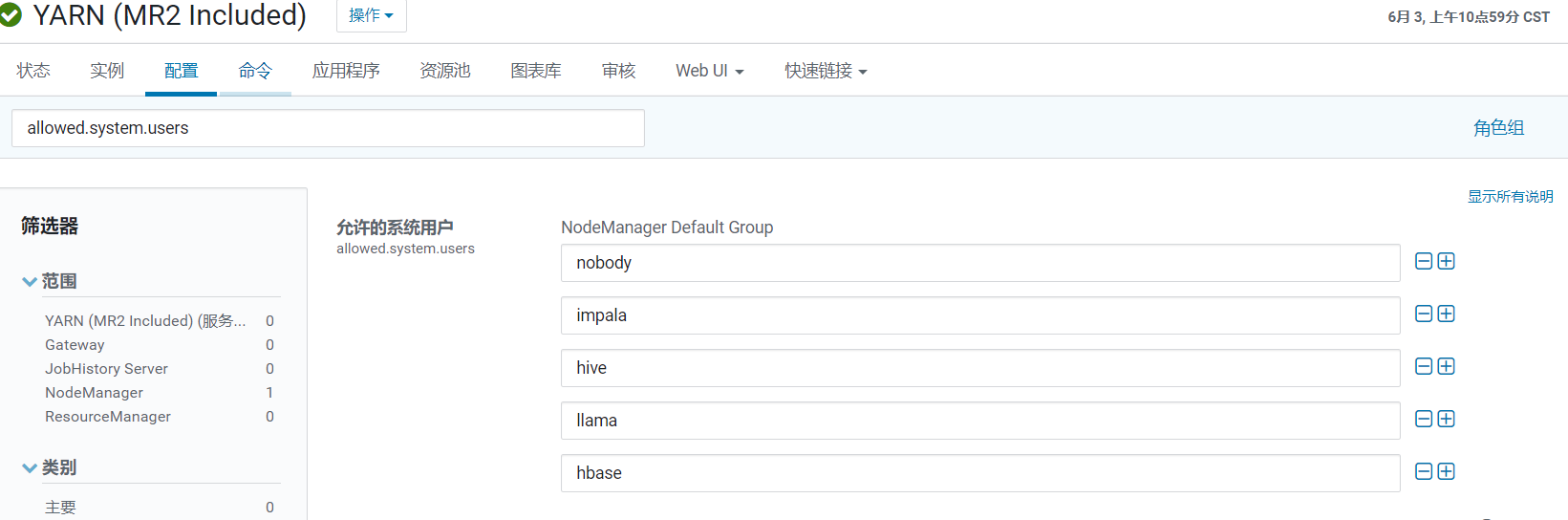 ```java usermod -s /bin/bash hive su hive ``` #### 3.2.2 HDFS 寫效能測試 - 測試內容:HDFS叢集寫入10個128M檔案(-D指定檔案儲存目錄) ```ruby hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -D test.build.data=/test/benchmark -write -nrFiles 10 -fileSize 128 ``` >INFO fs.TestDFSIO: ----- TestDFSIO ----- : write >INFO fs.TestDFSIO: Date & time: Thu Jun 11 10:30:36 CST 2020 >INFO fs.TestDFSIO: Number of files: 10 --十個檔案 >INFO fs.TestDFSIO: Total MBytes processed: 1280 --總大小1280M >INFO fs.TestDFSIO: Throughput mb/sec: 16.96 --吞吐量 每秒16.96M >INFO fs.TestDFSIO: Average IO rate mb/sec: 17.89 --平均IO情況17.89M >INFO fs.TestDFSIO: IO rate std deviation: 4.74 --IO速率標準偏差 >INFO fs.TestDFSIO: Test exec time sec: 46.33 --總執行時間 #### 3.2.3 HDFS 讀效能測試 - 測試內容:HDFS叢集讀取10個128M檔案 ```ruby hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -D test.build.data=/test/benchmark -read -nrFiles 10 -fileSize 128 ``` >INFO fs.TestDFSIO: ----- TestDFSIO ----- : read >INFO fs.TestDFSIO: Date & time: Thu Jun 11 10:41:19 CST 2020 >INFO fs.TestDFSIO: Number of files: 10 --檔案數 >INFO fs.TestDFSIO: Total MBytes processed: 1280 --總大小 >INFO fs.TestDFSIO: Throughput mb/sec: 321.53 --吞吐量 每秒321.53M >INFO fs.TestDFSIO: Average IO rate mb/sec: 385.43 --平均IO情況385.43M >INFO fs.TestDFSIO: IO rate std deviation: 107.67 --IO速率標準偏差 >INFO fs.TestDFSIO: Test exec time sec: 20.81 --總執行時間 #### 3.2.4 刪除測試資料 ```ruby hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -D test.build.data=/test/benchmark -clean ``` ### 3.3 引數調優 | 服務 | 選項 | 配置值 | | ----------- | --------------------------------------------------------- | ------------------ | | NameNode | Java Heap Size (堆疊大小) | 56G | | NameNode | dfs.namenode.handler.count (詳見3.3.2) | 80 | | NameNode | dfs.namenode.service.handler.count (詳見3.3.2) | 80 | | NameNode | fs.permissions.umask-mode (使用預設值022) | 027(使用預設值022) | | DataNode | Java Heap Size (堆疊大小) | 8G | | DataNode | dfs.datanode.failed.volumes.tolerated (詳見3.3.3) | 1 | | DataNode | dfs.datanode.balance.bandwidthPerSec (DataNode 平衡頻寬) | 100M | | DataNode | dfs.datanode.handler.count (伺服器執行緒數) | 64 | | DataNode | dfs.datanode.max.transfer.threads (最大傳輸執行緒數) | 20480 | | JournalNode | Java Heap Size (堆疊大小) | 1G | #### 3.3.1 資料塊優化 > dfs.blocksize = 128M - 檔案以塊為單位進行切分儲存,塊通常設定的比較大(最小6M,預設128M),根據網路頻寬計算最佳值。 - 塊越大,定址越快,讀取效率越高,但同時由於MapReduce任務也是以塊為最小單位來處理,所以太大的塊不利於於對資料的並行處理。 - 一個檔案至少佔用一個塊(如果一個1KB檔案,佔用一個塊,但是佔用空間還是1KB) - 我們在讀取HDFS上檔案的時候,NameNode會去尋找block地址,定址時間為傳輸時間的1%時,則為最佳狀態。 - 目前磁碟的傳輸速度普遍為100MB/S - 如果定址時間約為10ms,則傳輸時間=10ms/0.01=1000ms=1s - 如果傳輸時間為1S,傳輸速度為100MB/S,那麼一秒鐘我們就可以向HDFS傳送100MB檔案,設定塊大小128M比較合適。 - 如果頻寬為200MB/S,那麼可以將block塊大小設定為256M比較合適。 #### 3.3.2 NameNode 的伺服器執行緒的數量 - dfs.namenode.handler.count=20*log2(Cluster Size),比如叢集規模為16 ,8以2為底的對數是4,故此引數設定為80 - dfs.namenode.service.handler.count=20*log2(Cluster Size),比如叢集規模為16 ,8以2為底的對數是4,故此引數設定為80 > NameNode有一個工作執行緒池,用來處理不同DataNode的併發心跳以及客戶端併發的元資料操作。該值需要設定為叢集大小的自然對數乘以20,。 #### 3.3.3 DataNode 停止提供服務前允許失敗的卷的數量 > DN多少塊盤損壞後停止服務,預設為0,即一旦任何磁碟故障DN即關閉。 對盤較多的叢集(例如DN有超過2塊盤),磁碟故障是常態,通常可以將該值設定為1或2,避免頻繁有DN下線。 ## 4 優化:YARN + MapReduce | 服務 | 選項 | 配置值 | 引數說明 | | ----------------- | ------------------------------------------------------------ | ------ | ------------------------------------------------------------ | | ResourceManager | Java Heap Size (堆疊大小) | 4G | | | ResourceManager | yarn.scheduler.minimum-allocation-mb (最小容器記憶體) | 2G | 給應用程式 Container 分配的最小記憶體 | | ResourceManager | yarn.scheduler.increment-allocation-mb (容器記憶體增量) | 512M | 如果使用 Fair Scheduler,容器記憶體允許增量 | | ResourceManager | yarn.scheduler.maximum-allocation-mb (最大容器記憶體) | 32G | 給應用程式 Container 分配的最大記憶體 | | ResourceManager | yarn.scheduler.minimum-allocation-vcores (最小容器虛擬 CPU 核心數量) | 1 | 每個 Container 申請的最小 CPU 核數 | | ResourceManager | yarn.scheduler.increment-allocation-vcores (容器虛擬 CPU 核心增量) | 1 | 如果使用 Fair Scheduler,虛擬 CPU 核心允許增量 | | ResourceManager | yarn.scheduler.maximum-allocation-vcores (最大容器虛擬 CPU 核心數量) | 16 | 每個 Container 申請的最大 CPU 核數 | | ResourceManager | yarn.resourcemanager.recovery.enabled | true | 啟用後,ResourceManager 中止時在群集上執行的任何應用程式將在 ResourceManager 下次啟動時恢復,**備註:**如果啟用 RM-HA,則始終啟用該配置。 | | NodeManager | Java Heap Size (堆疊大小) | 4G | | | NodeManager | yarn.nodemanager.resource.memory-mb | 40G | 可分配給容器的實體記憶體數量,參照資源池記憶體90%左右 | | NodeManager | yarn.nodemanager.resource.cpu-vcores | 32 | 可以為容器分配的虛擬 CPU 核心的數量,參照資源池記憶體90%左右 | | ApplicationMaster | yarn.app.mapreduce.am.command-opts | 右紅 | 傳遞到 MapReduce ApplicationMaster 的 Java 命令列引數 "-Djava.net.preferIPv4Stack=true " | | ApplicationMaster | yarn.app.mapreduce.am.resource.mb (ApplicationMaster 記憶體) | 4G | | | JobHistory | Java Heap Size (堆疊大小) | 2G | | | MapReduce | mapreduce.map.memory.mb (Map 任務記憶體) | 4G | 一個MapTask可使用的資源上限。如果MapTask實際使用的資源量超過該值,則會被強制殺死。 | | MapReduce | mapreduce.reduce.memory.mb (Reduce 任務記憶體) | 8G | 一個 ReduceTask 可使用的資源上限。如果 ReduceTask 實際使用的資源量超過該值,則會被強制殺死 | | MapReduce | mapreduce.map.cpu.vcores | 2 | 每個 MapTask 可使用的最多 cpu core 數目 | | MapReduce | mapreduce.reduce.cpu.vcores | 4 | 每個 ReduceTask 可使用的最多 cpu core 數目 | | MapReduce | mapreduce.reduce.shuffle.parallelcopies | 20 | 每個 Reduce 去 Map 中取資料的並行數。 | | MapReduce | mapreduce.task.io.sort.mb(Shuffle 的環形緩衝區大小) | 512M | 當排序檔案時要使用的記憶體緩衝總量。注意:此記憶體由 JVM 堆疊大小產生(也就是:總使用者 JVM 堆疊 - 這些記憶體 = 總使用者可用堆疊空間) | | MapReduce | mapreduce.map.sort.spill.percent | 80% | 環形緩衝區溢位的閾值 | | MapReduce | mapreduce.task.timeout | 10分鐘 | Task 超時時間,經常需要設定的一個引數,該引數表 達的意思為:如果一個 Task 在一定時間內沒有任何進 入,即不會讀取新的資料,也沒有輸出資料,則認為 該 Task 處於 Block 狀態,可能是卡住了,也許永遠會 卡住,為了防止因為使用者程式永遠 Block 住不退出, 則強制設定了一個該超時時間。如果你的程式對每條輸入資料的處理時間過長(比如會訪問資料庫,通過網路拉取資料等),建議將該引數調大,該引數過小常出現的錯誤提示是 :AttemptID:attempt_12267239451721_123456_m_00 0335_0 Timed out after 600 secsContainer killed by the ApplicationMaster。 | ## 5 優化:Impala | 服務 | 選項 | 配置值 | 引數說明 | | --------------------- | ---------------------- | ------------------------ | ------------------------------------------------------------ | | Impala Daemon | mem_limit (記憶體限制) | 50G | 由守護程式本身強制執行的 Impala Daemon 的記憶體限制。
如果達到該限制,Impalad Daemon 上執行的查詢可能會被停止 | | Impala Daemon | Impala Daemon JVM Heap | 512M | 守護程序堆疊大小 | | Impala Daemon | scratch_dirs | 節點上多塊獨立磁碟(目錄) | Impala Daemon 將溢位資訊等資料寫入磁碟以釋放記憶體所在的目錄。這可能是大量資料 | | Impala Catalog Server | Java Heap Size | 8G | 堆疊大小 | ## 6 優化:Kafka ### 6.1 官方壓測 #### 6.1.1 Kafka Producer 壓力測試 - record-size 是一條資訊有多大,單位是位元組。 - num-records 是總共傳送多少條資訊。 - throughput 是每秒多少條資訊,設成-1,表示不限流,可測出生產者最大吞吐量。 ```ruby bash /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/kafka//bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 ``` >100000 records sent, 225733.634312 records/sec (21.53 MB/sec), > >8.20 ms avg latency, 66.00 ms max latency, > >3 ms 50th, 28 ms 95th, 30 ms 99th, 30 ms 99.9th. > >引數解析:一共寫入 10w 條訊息,吞吐量為 **21.53 MB/sec**,每次寫入的平均延遲 > >為 8.20 毫秒,最大的延遲為 66.00 毫秒。 #### 6.1.2 Kafka Consumer 壓力測試 - zookeeper 指定 zookeeper 的連結資訊 - topic 指定 topic 的名稱 - fetch-size 指定每次 fetch 的資料的大小 - messages 總共要消費的訊息個數 ```ruby bash /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/kafka//bin/kafka-consumer-perf-test.sh --broker-list cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1 ``` >start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec > >2020-06-11 17:53:48:179, 2020-06-11 17:54:04:525, 57.2205, 3.5006, 600000, 36706.2278, 3051, 13295, 4.3039, 45129.7480 > > > >start.time:2020-06-11 17:53:48:179 開始時間 > >end.time:2020-06-11 17:54:04:525 結束時間(用時16秒) > >data.consumed.in.MB:57.2205 消費57M資料 > >MB.sec:3.5006 3.5M/S > >data.consumed.in.nMsg:600000 消費60萬訊息 > >nMsg.sec:36706.2278 36706條訊息/S > >rebalance.time.ms:3051 平衡時間3S > >fetch.time.ms:13295 抓取時間13S > >fetch.MB.sec:4.3039 一秒抓取4.3M > >fetch.nMsg.sec:45129.7480 一秒抓取45129條訊息 > > > >開始測試時間,測試結束資料,共消費資料**57.2205MB**,吞吐量 **3.5M/S**,共消費**600000**條,平均每秒消費**36706.2278**條。 #### 6.1.3 Kafka 機器數量計算 > Kafka 機器數量(經驗公式)= 2 X(峰值生產速度 X 副本數 /100)+ 1 > > 先拿到峰值生產速度,再根據設定的副本數,就能預估出需要部署 Kafka 的數量。 > > 比如我們的峰值生產速度是 50M/s。副本數為 2。 > > Kafka 機器數量 = 2 X( 50 X 2 / 100 )+ 1 = 3 臺 ### 6.2 引數調優 | 服務 | 選項 | 配置值 | 引數說明 | | ------------ | -------------------------- | ------------ | ------------------------------------------------------------ | | Kafka Broker | Java Heap Size of Broker | 2G | Broker堆疊大小 | | Kafka Broker | Data Directories | 多塊獨立磁碟 | | | Kafka 服務 | Maximum Message Size | 10M | 伺服器可以接收的訊息的最大大小。此屬性必須與使用者使用的最大提取大小同步。否則,不守規矩的生產者可能會發布太大而無法消費的訊息 | | Kafka 服務 | Replica Maximum Fetch Size | 20M | 副本傳送給leader的獲取請求中每個分割槽要獲取的最大位元組數。此值應大於message.max.bytes。 | | Kafka 服務 | Number of Replica Fetchers | 6 | 用於複製來自領導者的訊息的執行緒數。增大此值將增加跟隨者代理中I / O並行度。 | ## 7 優化:HBase | 服務 | 選項 | 配置值 | 引數說明 | | ------------------ | ------------------------------------ | -------- | ------------------------------------------------------------ | | HBase | Java Heap Size | 18G | 客戶端 Java 堆大小(位元組)主要作用來快取Table資料,但是flush時會GC,不要太大,根據叢集資源,一般分配整個Hbase叢集記憶體的70%,16->48G就可以了 | | HBase | hbase.client.write.buffer | 512M | 寫入緩衝區大小,調高該值,可以減少RPC呼叫次數,單數會消耗更多記憶體,較大緩衝區需要客戶端和伺服器中有較大記憶體,因為伺服器將例項化已通過的寫入緩衝區並進行處理,這會降低遠端過程呼叫 (RPC) 的數量。 | | HBase Master | Java Heap Size | 8G | HBase Master 的 Java 堆疊大小 | | HBase Master | hbase.master.handler.count | 300 | HBase Master 中啟動的 RPC 伺服器例項數量。 | | HBase RegionServer | Java Heap Size | 31G | HBase RegionServer 的 Java 堆疊大小 | | HBase RegionServer | hbase.regionserver.handler.count | 100 | RegionServer 中啟動的 RPC 伺服器例項數量,根據叢集情況,可以適當增加該值,主要決定是客戶端的請求數 | | HBase RegionServer | hbase.regionserver.metahandler.count | 60 | 用於處理 RegionServer 中的優先順序請求的處理程式的數量 | | HBase RegionServer | zookeeper.session.timeout | 180000ms | ZooKeeper 會話延遲(以毫秒為單位)。HBase 將此作為建議的最長會話時間傳遞給 ZooKeeper 仲裁 | | HBase RegionServer | hbase.hregion.memstore.flush.size | 1G | 如 memstore 大小超過此值,Memstore 將重新整理到磁碟。通過執行由 hbase.server.thread.wakefrequency 指定的頻率的執行緒檢查此值。 | | HBase RegionServer | hbase.hregion.majorcompaction | 0 | 合併週期,在合格節點下,Region下所有的HFile會進行合併,非常消耗資源,在空閒時手動觸發 | | HBase RegionServer | hbase.hregion.majorcompaction.jitter | 0 | 抖動比率,根據上面的合併週期,有一個抖動比率,也不靠譜,還是手動好 | | HBase RegionServer | hbase.hstore.compactionThreshold | 6 | 如在任意一個 HStore 中有超過此數量的 HStoreFiles,則將執行壓縮以將所有 HStoreFiles 檔案作為一個 HStoreFile 重新寫入。(每次 memstore 重新整理寫入一個 HStoreFile)您可通過指定更大數量延長壓縮,但壓縮將執行更長時間。在壓縮期間,更新無法重新整理到磁碟。長時間壓縮需要足夠的記憶體,以在壓縮的持續時間內記錄所有更新。如太大,壓縮期間客戶端會超時。 | | HBase RegionServer | hbase.client.scanner.caching | 1000 | 記憶體未提供資料的情況下掃描器下次呼叫時所提取的行數。較高快取值需啟用較快速度的掃描器,但這需要更多的記憶體且當快取為空時某些下一次呼叫會執行較長時間 | | HBase RegionServer | hbase.hregion.max.filesize | 50G | HStoreFile 最大大小。如果列組的任意一個 HStoreFile 超過此值,則託管 HRegion 將分割成兩個 | ## 8 優化:Hive | 服務 | 選項 | 配置值 | 引數說明 | | -------------- | ------------------------------------------------------------ | -------- | ------------------------------------------------------------ | | HiveServer2 | Java Heap Size | 4G | | | Hive MetaStore | Java Heap Size | 8G | | | Hive Gateway | Java Heap Size | 2G | | | Hive | hive.execution.engine | Spark | 執行引擎切換 | | Hive | hive.fetch.task.conversion | more | Fetch抓取修改為more,可以使全域性查詢,欄位查詢,limit查詢等都不走計算引擎,而是直接讀取表對應儲存目錄下的檔案,大大普通查詢速度 | | Hive | hive.exec.mode.local.auto(hive-site.xml 服務高階配置,客戶端高階配置) | true | 開啟本地模式,在單臺機器上處理所有的任務,對於小的資料集,執行時間可以明顯被縮短 | | Hive | hive.exec.mode.local.auto.inputbytes.max(hive-site.xml 服務高階配置,客戶端高階配置) | 50000000 | 檔案不超過50M | | Hive | hive.exec.mode.local.auto.input.files.max(hive-site.xml 服務高階配置,客戶端高階配置) | 10 | 個數不超過10個 | | Hive | hive.auto.convert.join | 開啟 | 在join問題上,讓小表放在左邊 去左連結(left join)大表,這樣可以有效的減少記憶體溢位錯誤發生的機率 | | Hive | hive.mapjoin.smalltable.filesize(hive-site.xml 服務高階配置,客戶端高階配置) | 50000000 | 50M以下認為是小表 | | Hive | hive.map.aggr | 開啟 | 預設情況下map階段同一個key傳送給一個reduce,當一個key資料過大時就發生資料傾斜。 | | Hive | hive.groupby.mapaggr.checkinterval(hive-site.xml 服務高階配置,客戶端高階配置) | 200000 | 在map端進行聚合操作的條目數目 | | Hive | hive.groupby.skewindata(hive-site.xml 服務高階配置,客戶端高階配置) | true | 有資料傾斜時進行負載均衡,生成的查詢計劃會有兩個MR Job,第一個MR Job會將key加隨機數均勻的分佈到Reduce中,做部分聚合操作(預處理),第二個MR Job在根據預處理結果還原原始key,按照Group By Key分佈到Reduce中進行聚合運算,完成最終操作 | | Hive | hive.exec.parallel(hive-site.xml 服務高階配置,客戶端高階配置) | true | 開啟平行計算 | | Hive | hive.exec.parallel.thread.number(hive-site.xml 服務高階配置,客戶端高階配置) | 16G | 同一個sql允許的最大並行度,針對叢集資源適當增加 | ## 9 優化:Oozie、Hue | 服務 | 選項 | 配置值 | 引數說明 | | ----- | -------------- | ------ | -------- | | Oozie | Java Heap Size | 1G | 堆疊大小 | | Hue | Java Heap Size | 4G | 堆疊
Event Server
Host Monitor
Service Monitor | √
√
√
√
√
| | | | | | | | | | HDFS | NameNode
DataNode
Failover Controller
√
X
X
| √
X
√
√
| √
X
√
√
| X
X
X
√
| | | | | Yarn | NodeManager
Resourcemanager
JobHisoryServer | | | √
X
X
| | | X
√
| X
√
√
| | | | Zookeeper | Zookeeper Server | | √ | | | | | | | | | Kafka | Kafka Broker | | √ | | | | | | | | | Hive | Hive Metastore Server
HiveServer2
Gateway(安裝對應應用伺服器) | | | X
√
√
| | | | | √
X
√
| √
X
√
| | Hbase | HMaster
HRegionServer
Thrift Server | | | X
√
√ | | | | | √
X
| √
X
| | Oozie | Oozie Server | | | | | | √ | | | | | Hue | Hue Server
Load Balancer | | | | | | X
√ | √
X
| | | | Spark | History Server
Gateway(安裝對應應用伺服器) | | | | | | | √
X
| | | | Flume | Flume Agent (安裝對應應用伺服器) | | | | | | | | | | | Sqoop | Sqoop(安裝對應應用伺服器) | | | | | | | | | | ## 1 優化:Cloudera Management ### 1.1 Cloudera Management Service > 這些服務主要是提供監控功能,目前的調整主要集中在記憶體放,以便有足夠的資源 完成叢集管理。 | 服務 | 選項 | 配置值 | | ------------------------- | -------------- | ------ | | Activity Monitor | Java Heap Size | 2G | | Alert Publisher | Java Heap Size | 2G | | Event Server | Java Heap Size | 2G | | Host Monitor | Java Heap Size | 4G | | Service Monitor | Java Heap Size | 4G | | Reports Manager | Java Heap Size | 2G | | Navigator Metadata Server | Java Heap Size | 8G | ## 2 優化:Zookeeper | 服務 | 選項 | 配置值 | | --------- | ------------------------------------- | ------------------------------------ | | Zookeeper | Java Heap Size (堆疊大小) | 4G | | Zookeeper | maxClientCnxns (最大客戶端連線數) | 1024 | | Zookeeper | dataDir (資料檔案目錄+資料持久化路徑) | /hadoop/zookeeper (建議獨立目錄) | | Zookeeper | dataLogDir (事務日誌目錄) | /hadoop/zookeeper_log (建議獨立目錄) | ## 3 優化:HDFS ### 3.1 磁碟測試 #### 3.1.1 讀測試 > **hdparm** 用於檢視硬碟的相關資訊或對硬碟進行測速、優化、修改硬碟相關引數設定 ```java #安裝hdparm yum install hdparm #獲取硬碟符 fdisk -l #讀測試(讀取上一步獲取硬碟符) hdparm -t /dev/vda ``` > 三次測試結果: > > Timing buffered disk reads: 500 MB in 0.84 seconds = 593.64 MB/sec > > Timing buffered disk reads: 500 MB in 0.93 seconds = 538.80 MB/sec > > Timing buffered disk reads: 500 MB in 0.74 seconds = 672.95 MB/sec > > 說明:接近1s秒讀取了500MB磁碟,讀速度約 500 MB/秒 #### 3.1.2 寫測試 > **dd** 這裡使用 time + dd 簡單測試寫速度,不要求很精確 ```java 檢視記憶體快取情況 free -m 清除快取 sync; echo 3 > /proc/sys/vm/drop_caches 查block size blockdev --getbsz /dev/vda 寫測試 echo 3 > /proc/sys/vm/drop_caches; time dd if=/dev/zero of=/testdd bs=4k count=100000 ``` >三次測試結果: > >記錄了100000+0 的讀入 >記錄了100000+0 的寫出 > >409600000 bytes (410 MB) copied, 0.574066 s, 714 MB/s --410MB複製,用時0.57秒,評估714M/s > >409600000 bytes (410 MB) copied, 1.84421 s, 222 MB/s --410MB複製,用時1.84秒,評估222 M/s > >409600000 bytes (410 MB) copied, 1.06969 s, 383 MB/s --410MB複製,用時1.06秒,評估383M/s #### 3.1.3 網路頻寬 > iperf3測量一個網路最大頻寬 ```java #安裝iperf3 yum -y install iperf3 #服務端 iperf3 -s #客戶端 iperf3 -c 上調命令執行的服務機器IP ``` > 測試結果: | [ ID]-->執行緒id | Interva-->傳輸時間 | Transfer-->接收資料大小 | Bandwidth-->頻寬每秒大小 | Retr | 角色 | | -------------- | ------------------ | ----------------------- | ------------------------ | ---- | --------------- | | [ 4] | 0.00-10.00 sec | 17.0 GBytes | 14.6 Gbits/sec | 0 | sender-->傳送 | | [ 4] | 0.00-10.00 sec | 17.0 GBytes | 14.6 Gbits/sec | | receiver-->接收 | ### 3.2 官方壓測 #### 3.2.1 使用者準備 > 由於只能使用yarn配置了允許使用者,故這裡選擇hive使用者,如果su hive不能進入,則需要配置該步驟  ```java usermod -s /bin/bash hive su hive ``` #### 3.2.2 HDFS 寫效能測試 - 測試內容:HDFS叢集寫入10個128M檔案(-D指定檔案儲存目錄) ```ruby hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -D test.build.data=/test/benchmark -write -nrFiles 10 -fileSize 128 ``` >INFO fs.TestDFSIO: ----- TestDFSIO ----- : write >INFO fs.TestDFSIO: Date & time: Thu Jun 11 10:30:36 CST 2020 >INFO fs.TestDFSIO: Number of files: 10 --十個檔案 >INFO fs.TestDFSIO: Total MBytes processed: 1280 --總大小1280M >INFO fs.TestDFSIO: Throughput mb/sec: 16.96 --吞吐量 每秒16.96M >INFO fs.TestDFSIO: Average IO rate mb/sec: 17.89 --平均IO情況17.89M >INFO fs.TestDFSIO: IO rate std deviation: 4.74 --IO速率標準偏差 >INFO fs.TestDFSIO: Test exec time sec: 46.33 --總執行時間 #### 3.2.3 HDFS 讀效能測試 - 測試內容:HDFS叢集讀取10個128M檔案 ```ruby hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -D test.build.data=/test/benchmark -read -nrFiles 10 -fileSize 128 ``` >INFO fs.TestDFSIO: ----- TestDFSIO ----- : read >INFO fs.TestDFSIO: Date & time: Thu Jun 11 10:41:19 CST 2020 >INFO fs.TestDFSIO: Number of files: 10 --檔案數 >INFO fs.TestDFSIO: Total MBytes processed: 1280 --總大小 >INFO fs.TestDFSIO: Throughput mb/sec: 321.53 --吞吐量 每秒321.53M >INFO fs.TestDFSIO: Average IO rate mb/sec: 385.43 --平均IO情況385.43M >INFO fs.TestDFSIO: IO rate std deviation: 107.67 --IO速率標準偏差 >INFO fs.TestDFSIO: Test exec time sec: 20.81 --總執行時間 #### 3.2.4 刪除測試資料 ```ruby hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.2.0-tests.jar TestDFSIO -D test.build.data=/test/benchmark -clean ``` ### 3.3 引數調優 | 服務 | 選項 | 配置值 | | ----------- | --------------------------------------------------------- | ------------------ | | NameNode | Java Heap Size (堆疊大小) | 56G | | NameNode | dfs.namenode.handler.count (詳見3.3.2) | 80 | | NameNode | dfs.namenode.service.handler.count (詳見3.3.2) | 80 | | NameNode | fs.permissions.umask-mode (使用預設值022) | 027(使用預設值022) | | DataNode | Java Heap Size (堆疊大小) | 8G | | DataNode | dfs.datanode.failed.volumes.tolerated (詳見3.3.3) | 1 | | DataNode | dfs.datanode.balance.bandwidthPerSec (DataNode 平衡頻寬) | 100M | | DataNode | dfs.datanode.handler.count (伺服器執行緒數) | 64 | | DataNode | dfs.datanode.max.transfer.threads (最大傳輸執行緒數) | 20480 | | JournalNode | Java Heap Size (堆疊大小) | 1G | #### 3.3.1 資料塊優化 > dfs.blocksize = 128M - 檔案以塊為單位進行切分儲存,塊通常設定的比較大(最小6M,預設128M),根據網路頻寬計算最佳值。 - 塊越大,定址越快,讀取效率越高,但同時由於MapReduce任務也是以塊為最小單位來處理,所以太大的塊不利於於對資料的並行處理。 - 一個檔案至少佔用一個塊(如果一個1KB檔案,佔用一個塊,但是佔用空間還是1KB) - 我們在讀取HDFS上檔案的時候,NameNode會去尋找block地址,定址時間為傳輸時間的1%時,則為最佳狀態。 - 目前磁碟的傳輸速度普遍為100MB/S - 如果定址時間約為10ms,則傳輸時間=10ms/0.01=1000ms=1s - 如果傳輸時間為1S,傳輸速度為100MB/S,那麼一秒鐘我們就可以向HDFS傳送100MB檔案,設定塊大小128M比較合適。 - 如果頻寬為200MB/S,那麼可以將block塊大小設定為256M比較合適。 #### 3.3.2 NameNode 的伺服器執行緒的數量 - dfs.namenode.handler.count=20*log2(Cluster Size),比如叢集規模為16 ,8以2為底的對數是4,故此引數設定為80 - dfs.namenode.service.handler.count=20*log2(Cluster Size),比如叢集規模為16 ,8以2為底的對數是4,故此引數設定為80 > NameNode有一個工作執行緒池,用來處理不同DataNode的併發心跳以及客戶端併發的元資料操作。該值需要設定為叢集大小的自然對數乘以20,。 #### 3.3.3 DataNode 停止提供服務前允許失敗的卷的數量 > DN多少塊盤損壞後停止服務,預設為0,即一旦任何磁碟故障DN即關閉。 對盤較多的叢集(例如DN有超過2塊盤),磁碟故障是常態,通常可以將該值設定為1或2,避免頻繁有DN下線。 ## 4 優化:YARN + MapReduce | 服務 | 選項 | 配置值 | 引數說明 | | ----------------- | ------------------------------------------------------------ | ------ | ------------------------------------------------------------ | | ResourceManager | Java Heap Size (堆疊大小) | 4G | | | ResourceManager | yarn.scheduler.minimum-allocation-mb (最小容器記憶體) | 2G | 給應用程式 Container 分配的最小記憶體 | | ResourceManager | yarn.scheduler.increment-allocation-mb (容器記憶體增量) | 512M | 如果使用 Fair Scheduler,容器記憶體允許增量 | | ResourceManager | yarn.scheduler.maximum-allocation-mb (最大容器記憶體) | 32G | 給應用程式 Container 分配的最大記憶體 | | ResourceManager | yarn.scheduler.minimum-allocation-vcores (最小容器虛擬 CPU 核心數量) | 1 | 每個 Container 申請的最小 CPU 核數 | | ResourceManager | yarn.scheduler.increment-allocation-vcores (容器虛擬 CPU 核心增量) | 1 | 如果使用 Fair Scheduler,虛擬 CPU 核心允許增量 | | ResourceManager | yarn.scheduler.maximum-allocation-vcores (最大容器虛擬 CPU 核心數量) | 16 | 每個 Container 申請的最大 CPU 核數 | | ResourceManager | yarn.resourcemanager.recovery.enabled | true | 啟用後,ResourceManager 中止時在群集上執行的任何應用程式將在 ResourceManager 下次啟動時恢復,**備註:**如果啟用 RM-HA,則始終啟用該配置。 | | NodeManager | Java Heap Size (堆疊大小) | 4G | | | NodeManager | yarn.nodemanager.resource.memory-mb | 40G | 可分配給容器的實體記憶體數量,參照資源池記憶體90%左右 | | NodeManager | yarn.nodemanager.resource.cpu-vcores | 32 | 可以為容器分配的虛擬 CPU 核心的數量,參照資源池記憶體90%左右 | | ApplicationMaster | yarn.app.mapreduce.am.command-opts | 右紅 | 傳遞到 MapReduce ApplicationMaster 的 Java 命令列引數 "-Djava.net.preferIPv4Stack=true " | | ApplicationMaster | yarn.app.mapreduce.am.resource.mb (ApplicationMaster 記憶體) | 4G | | | JobHistory | Java Heap Size (堆疊大小) | 2G | | | MapReduce | mapreduce.map.memory.mb (Map 任務記憶體) | 4G | 一個MapTask可使用的資源上限。如果MapTask實際使用的資源量超過該值,則會被強制殺死。 | | MapReduce | mapreduce.reduce.memory.mb (Reduce 任務記憶體) | 8G | 一個 ReduceTask 可使用的資源上限。如果 ReduceTask 實際使用的資源量超過該值,則會被強制殺死 | | MapReduce | mapreduce.map.cpu.vcores | 2 | 每個 MapTask 可使用的最多 cpu core 數目 | | MapReduce | mapreduce.reduce.cpu.vcores | 4 | 每個 ReduceTask 可使用的最多 cpu core 數目 | | MapReduce | mapreduce.reduce.shuffle.parallelcopies | 20 | 每個 Reduce 去 Map 中取資料的並行數。 | | MapReduce | mapreduce.task.io.sort.mb(Shuffle 的環形緩衝區大小) | 512M | 當排序檔案時要使用的記憶體緩衝總量。注意:此記憶體由 JVM 堆疊大小產生(也就是:總使用者 JVM 堆疊 - 這些記憶體 = 總使用者可用堆疊空間) | | MapReduce | mapreduce.map.sort.spill.percent | 80% | 環形緩衝區溢位的閾值 | | MapReduce | mapreduce.task.timeout | 10分鐘 | Task 超時時間,經常需要設定的一個引數,該引數表 達的意思為:如果一個 Task 在一定時間內沒有任何進 入,即不會讀取新的資料,也沒有輸出資料,則認為 該 Task 處於 Block 狀態,可能是卡住了,也許永遠會 卡住,為了防止因為使用者程式永遠 Block 住不退出, 則強制設定了一個該超時時間。如果你的程式對每條輸入資料的處理時間過長(比如會訪問資料庫,通過網路拉取資料等),建議將該引數調大,該引數過小常出現的錯誤提示是 :AttemptID:attempt_12267239451721_123456_m_00 0335_0 Timed out after 600 secsContainer killed by the ApplicationMaster。 | ## 5 優化:Impala | 服務 | 選項 | 配置值 | 引數說明 | | --------------------- | ---------------------- | ------------------------ | ------------------------------------------------------------ | | Impala Daemon | mem_limit (記憶體限制) | 50G | 由守護程式本身強制執行的 Impala Daemon 的記憶體限制。
如果達到該限制,Impalad Daemon 上執行的查詢可能會被停止 | | Impala Daemon | Impala Daemon JVM Heap | 512M | 守護程序堆疊大小 | | Impala Daemon | scratch_dirs | 節點上多塊獨立磁碟(目錄) | Impala Daemon 將溢位資訊等資料寫入磁碟以釋放記憶體所在的目錄。這可能是大量資料 | | Impala Catalog Server | Java Heap Size | 8G | 堆疊大小 | ## 6 優化:Kafka ### 6.1 官方壓測 #### 6.1.1 Kafka Producer 壓力測試 - record-size 是一條資訊有多大,單位是位元組。 - num-records 是總共傳送多少條資訊。 - throughput 是每秒多少條資訊,設成-1,表示不限流,可測出生產者最大吞吐量。 ```ruby bash /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/kafka//bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 ``` >100000 records sent, 225733.634312 records/sec (21.53 MB/sec), > >8.20 ms avg latency, 66.00 ms max latency, > >3 ms 50th, 28 ms 95th, 30 ms 99th, 30 ms 99.9th. > >引數解析:一共寫入 10w 條訊息,吞吐量為 **21.53 MB/sec**,每次寫入的平均延遲 > >為 8.20 毫秒,最大的延遲為 66.00 毫秒。 #### 6.1.2 Kafka Consumer 壓力測試 - zookeeper 指定 zookeeper 的連結資訊 - topic 指定 topic 的名稱 - fetch-size 指定每次 fetch 的資料的大小 - messages 總共要消費的訊息個數 ```ruby bash /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/kafka//bin/kafka-consumer-perf-test.sh --broker-list cdh01.cm:9092,cdh02.cm:9092,cdh03.cm:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1 ``` >start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec > >2020-06-11 17:53:48:179, 2020-06-11 17:54:04:525, 57.2205, 3.5006, 600000, 36706.2278, 3051, 13295, 4.3039, 45129.7480 > > > >start.time:2020-06-11 17:53:48:179 開始時間 > >end.time:2020-06-11 17:54:04:525 結束時間(用時16秒) > >data.consumed.in.MB:57.2205 消費57M資料 > >MB.sec:3.5006 3.5M/S > >data.consumed.in.nMsg:600000 消費60萬訊息 > >nMsg.sec:36706.2278 36706條訊息/S > >rebalance.time.ms:3051 平衡時間3S > >fetch.time.ms:13295 抓取時間13S > >fetch.MB.sec:4.3039 一秒抓取4.3M > >fetch.nMsg.sec:45129.7480 一秒抓取45129條訊息 > > > >開始測試時間,測試結束資料,共消費資料**57.2205MB**,吞吐量 **3.5M/S**,共消費**600000**條,平均每秒消費**36706.2278**條。 #### 6.1.3 Kafka 機器數量計算 > Kafka 機器數量(經驗公式)= 2 X(峰值生產速度 X 副本數 /100)+ 1 > > 先拿到峰值生產速度,再根據設定的副本數,就能預估出需要部署 Kafka 的數量。 > > 比如我們的峰值生產速度是 50M/s。副本數為 2。 > > Kafka 機器數量 = 2 X( 50 X 2 / 100 )+ 1 = 3 臺 ### 6.2 引數調優 | 服務 | 選項 | 配置值 | 引數說明 | | ------------ | -------------------------- | ------------ | ------------------------------------------------------------ | | Kafka Broker | Java Heap Size of Broker | 2G | Broker堆疊大小 | | Kafka Broker | Data Directories | 多塊獨立磁碟 | | | Kafka 服務 | Maximum Message Size | 10M | 伺服器可以接收的訊息的最大大小。此屬性必須與使用者使用的最大提取大小同步。否則,不守規矩的生產者可能會發布太大而無法消費的訊息 | | Kafka 服務 | Replica Maximum Fetch Size | 20M | 副本傳送給leader的獲取請求中每個分割槽要獲取的最大位元組數。此值應大於message.max.bytes。 | | Kafka 服務 | Number of Replica Fetchers | 6 | 用於複製來自領導者的訊息的執行緒數。增大此值將增加跟隨者代理中I / O並行度。 | ## 7 優化:HBase | 服務 | 選項 | 配置值 | 引數說明 | | ------------------ | ------------------------------------ | -------- | ------------------------------------------------------------ | | HBase | Java Heap Size | 18G | 客戶端 Java 堆大小(位元組)主要作用來快取Table資料,但是flush時會GC,不要太大,根據叢集資源,一般分配整個Hbase叢集記憶體的70%,16->48G就可以了 | | HBase | hbase.client.write.buffer | 512M | 寫入緩衝區大小,調高該值,可以減少RPC呼叫次數,單數會消耗更多記憶體,較大緩衝區需要客戶端和伺服器中有較大記憶體,因為伺服器將例項化已通過的寫入緩衝區並進行處理,這會降低遠端過程呼叫 (RPC) 的數量。 | | HBase Master | Java Heap Size | 8G | HBase Master 的 Java 堆疊大小 | | HBase Master | hbase.master.handler.count | 300 | HBase Master 中啟動的 RPC 伺服器例項數量。 | | HBase RegionServer | Java Heap Size | 31G | HBase RegionServer 的 Java 堆疊大小 | | HBase RegionServer | hbase.regionserver.handler.count | 100 | RegionServer 中啟動的 RPC 伺服器例項數量,根據叢集情況,可以適當增加該值,主要決定是客戶端的請求數 | | HBase RegionServer | hbase.regionserver.metahandler.count | 60 | 用於處理 RegionServer 中的優先順序請求的處理程式的數量 | | HBase RegionServer | zookeeper.session.timeout | 180000ms | ZooKeeper 會話延遲(以毫秒為單位)。HBase 將此作為建議的最長會話時間傳遞給 ZooKeeper 仲裁 | | HBase RegionServer | hbase.hregion.memstore.flush.size | 1G | 如 memstore 大小超過此值,Memstore 將重新整理到磁碟。通過執行由 hbase.server.thread.wakefrequency 指定的頻率的執行緒檢查此值。 | | HBase RegionServer | hbase.hregion.majorcompaction | 0 | 合併週期,在合格節點下,Region下所有的HFile會進行合併,非常消耗資源,在空閒時手動觸發 | | HBase RegionServer | hbase.hregion.majorcompaction.jitter | 0 | 抖動比率,根據上面的合併週期,有一個抖動比率,也不靠譜,還是手動好 | | HBase RegionServer | hbase.hstore.compactionThreshold | 6 | 如在任意一個 HStore 中有超過此數量的 HStoreFiles,則將執行壓縮以將所有 HStoreFiles 檔案作為一個 HStoreFile 重新寫入。(每次 memstore 重新整理寫入一個 HStoreFile)您可通過指定更大數量延長壓縮,但壓縮將執行更長時間。在壓縮期間,更新無法重新整理到磁碟。長時間壓縮需要足夠的記憶體,以在壓縮的持續時間內記錄所有更新。如太大,壓縮期間客戶端會超時。 | | HBase RegionServer | hbase.client.scanner.caching | 1000 | 記憶體未提供資料的情況下掃描器下次呼叫時所提取的行數。較高快取值需啟用較快速度的掃描器,但這需要更多的記憶體且當快取為空時某些下一次呼叫會執行較長時間 | | HBase RegionServer | hbase.hregion.max.filesize | 50G | HStoreFile 最大大小。如果列組的任意一個 HStoreFile 超過此值,則託管 HRegion 將分割成兩個 | ## 8 優化:Hive | 服務 | 選項 | 配置值 | 引數說明 | | -------------- | ------------------------------------------------------------ | -------- | ------------------------------------------------------------ | | HiveServer2 | Java Heap Size | 4G | | | Hive MetaStore | Java Heap Size | 8G | | | Hive Gateway | Java Heap Size | 2G | | | Hive | hive.execution.engine | Spark | 執行引擎切換 | | Hive | hive.fetch.task.conversion | more | Fetch抓取修改為more,可以使全域性查詢,欄位查詢,limit查詢等都不走計算引擎,而是直接讀取表對應儲存目錄下的檔案,大大普通查詢速度 | | Hive | hive.exec.mode.local.auto(hive-site.xml 服務高階配置,客戶端高階配置) | true | 開啟本地模式,在單臺機器上處理所有的任務,對於小的資料集,執行時間可以明顯被縮短 | | Hive | hive.exec.mode.local.auto.inputbytes.max(hive-site.xml 服務高階配置,客戶端高階配置) | 50000000 | 檔案不超過50M | | Hive | hive.exec.mode.local.auto.input.files.max(hive-site.xml 服務高階配置,客戶端高階配置) | 10 | 個數不超過10個 | | Hive | hive.auto.convert.join | 開啟 | 在join問題上,讓小表放在左邊 去左連結(left join)大表,這樣可以有效的減少記憶體溢位錯誤發生的機率 | | Hive | hive.mapjoin.smalltable.filesize(hive-site.xml 服務高階配置,客戶端高階配置) | 50000000 | 50M以下認為是小表 | | Hive | hive.map.aggr | 開啟 | 預設情況下map階段同一個key傳送給一個reduce,當一個key資料過大時就發生資料傾斜。 | | Hive | hive.groupby.mapaggr.checkinterval(hive-site.xml 服務高階配置,客戶端高階配置) | 200000 | 在map端進行聚合操作的條目數目 | | Hive | hive.groupby.skewindata(hive-site.xml 服務高階配置,客戶端高階配置) | true | 有資料傾斜時進行負載均衡,生成的查詢計劃會有兩個MR Job,第一個MR Job會將key加隨機數均勻的分佈到Reduce中,做部分聚合操作(預處理),第二個MR Job在根據預處理結果還原原始key,按照Group By Key分佈到Reduce中進行聚合運算,完成最終操作 | | Hive | hive.exec.parallel(hive-site.xml 服務高階配置,客戶端高階配置) | true | 開啟平行計算 | | Hive | hive.exec.parallel.thread.number(hive-site.xml 服務高階配置,客戶端高階配置) | 16G | 同一個sql允許的最大並行度,針對叢集資源適當增加 | ## 9 優化:Oozie、Hue | 服務 | 選項 | 配置值 | 引數說明 | | ----- | -------------- | ------ | -------- | | Oozie | Java Heap Size | 1G | 堆疊大小 | | Hue | Java Heap Size | 4G | 堆疊