
萬級TPS億級流水-中臺賬戶系統架構設計
阿新 • • 發佈:2020-06-20
# 萬級TPS億級流水-中臺賬戶系統架構設計
標籤:高併發 萬級TPS 億級流水 賬戶系統
- 背景
- 業務模型
- 應用層設計
- 資料層設計
- 日切對賬
# 背景
我們需要給所有前臺業務提供統一的賬戶系統,用來支撐所有前臺產品線的使用者資產管理,統一提供支援大併發萬級TPS、億級流水、資料強一致、風控安全、日切對賬、財務核算、審計等能力,在萬級TPS下保證絕對的資料準確性和資料溯源能力。
>注:資金類系統只有合格和不合格,哪怕資料出現只有0.01分的差錯也是不合格的,區域性資料不準也就意味著全域性資料都不可信。
本文只分享系統的核心模型部分的設計,其他常規類的(如壓測驗收、系統保護策略-限流、降級、熔斷等)設計就不做多介紹,如果對其他方面有興趣歡迎進一步交流。
# 業務模型
__基本賬戶管理:__ 根據交易的不同主體,可以分為`個人賬戶`、`機構賬戶`。
`賬戶餘額`在使用上沒有任何限制,很純粹的賬戶儲存、轉賬管理,可以滿足90%業務場景。
__子賬戶功能:__ 一個使用者可以開通多個子賬戶,根據餘額屬性不同可以分為基本賬戶、過期賬戶,根據幣種不同可以分為人民幣賬戶、虛擬幣賬戶,根據業務形態不同可以自定義。
(不同賬戶的特定功能是通過賬戶上的`賬戶屬性`來區分實現。)
__過期賬戶管理:__ 該賬戶中的餘額是會隨著`進賬流水`到期自動過期。
如:在某平臺充值1000元送300元,其中300元是有過期時間的,但是1000元是沒有時間限制的。這裡的1000元存在你的基本賬戶中,300元存在你的過期賬戶中。
> 注:過期賬戶的每一筆入賬流水都會有一個到期時間。系統根據交易流水的到期時間,自動核銷使用者過期賬戶中的餘額,記為平臺的確認收入。
__賬戶組合使用__:支援多賬戶組合使用,根據配置的優先扣減順序進行扣減餘額。比如:在 `基本賬戶` 和 `過期賬戶` (充值賬戶)中扣錢一般的順序是優先扣減過期賬戶的餘額。
# 應用層設計
根據上述業務模型,賬戶系統是一個典型的 _資料密集型系統_ ,業務層的邏輯不復雜。整個系統的設計關鍵點在於如何平衡大併發TPS和資料一致性。
__熱點賬戶__:前臺直播類業務存在熱點賬戶問題,每到各種活動賽事的時候會存在 _90%DAU_ 給少數幾個頭部主播打賞的場景。
DB就會有熱點行問題,由於 _行鎖_ 關係併發一大肯定大量超時、_RT突增_ 、 _DB活躍執行緒_ 增加等一系列問題,最終DB會被拖掛。
賬戶類系統有一個特點,原賬戶的扣減可以實時處理,目標賬戶可以非同步處理,我們可以將轉賬動作拆解為兩個階段進行非同步化。(可以參考銀行轉賬業務。)
> 比如:A給B轉賬100元,原賬戶A的100元餘額扣減可以同步處理,B賬戶的100增加可以非同步處理。這樣哪怕10w人給主播打賞,這10w人的賬戶都是分散的,而主播的餘額增加則是非同步處理的。
賬戶轉賬扣減A賬戶餘額,記錄A賬戶出賬流水,記錄B賬戶入賬流水,這三個動作可以在一個`DBTransaction`中處理,可以保證源賬戶進出帳一致性。目標賬戶B的入賬可以非同步處理,為了保證萬無一失且滿足一定的實時性,需要兩步結合,程式裡通過`MQ`走非同步入賬,同時增加DB的兜底`JOB`定時掃描 _入賬流水記錄_ 為`未到賬`的流水進行入賬。
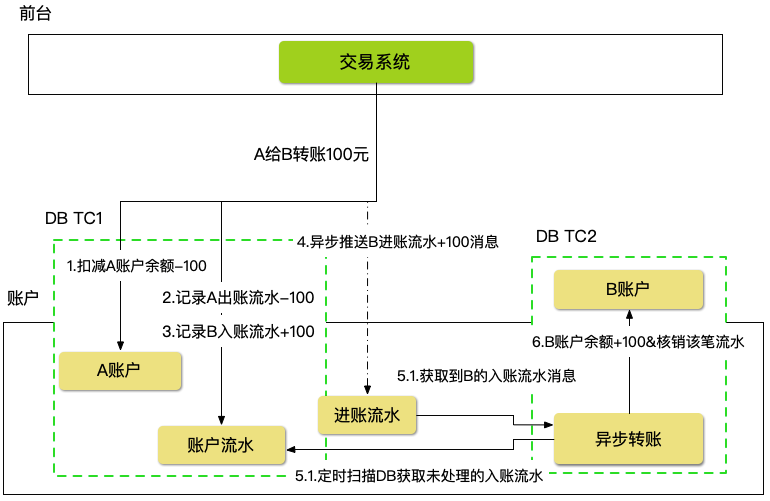
>我們通過非同步化緩解熱點行處理,但是如果 _收款方_ 強烈要求收款必須在一定的時間內完成,我們還是需要進一步處理,後面會講到。
__過期賬戶:__ 通常過期賬戶用來管理贈送類賬戶,這類賬戶有一定的時效性,使用者在使用上也是優先扣減此類賬戶餘額。
這類使用需求其實覆蓋面不大,真正使用者賬戶餘額不使用等著被系統過期的很少,畢竟這是一個很傻的行為。
過期賬戶的兩種核銷情況:第一種是使用者使用過期賬戶時的核銷。第二種是某個過期流水到了過期時間,系統自動核銷記為平臺的確認收入。
過期賬戶核銷邏輯:使用者充值1000元到`基本賬戶`,平臺贈送300元到`贈送賬戶`。此時,`基本賬戶`記錄`進賬流水`+1000元,`贈送賬戶`記錄`進賬流水`+300元並且該筆流水的`過期時間`為 _2020-12-29 23:59:59_ (過期時間由前臺業務方設定) 。
>系統自動核銷:如果使用者不在此時間之前用完就會被系統自動划進平臺的收入,`贈送賬戶`餘額扣減-300元。
>使用者使用核銷:如果使用者在`過期時間`前陸續在使用`贈送賬戶`,比如使用100元,那麼我們需要核銷原本進賬的300元的那筆流水,減少-150元。
也就是說,該筆過期流水已經核銷掉150元,帶過期核銷150元,到期後只要核銷150元即可,而不是300元。
過期賬戶每次使用均產生`待核銷`負向流水,系統自動核銷前必須保證沒有任何負向流水記錄才可以去扣減贈送賬戶餘額。

考慮到極端情況下,剛好過期`JOB`在進行自動過期核銷,使用者又在此時使用過期賬戶,這點需要注意下。可以簡單通過加`DB-X`鎖解決,這個場景其實非常稀少。
# 資料層設計
在應用層設計的時候,我們通過非同步化方式來繞開熱點問題。
同樣我們在設計資料層的時候也要考慮單次操作DB的效能,比如控制事務的大小,事務跨網路的次數等問題。當然還包括金額儲存的精度問題,精度問題處理不好也會影響效能。
__浮點數問題:__ 如果我們用浮點數近似值來儲存金額,那麼就一定會有偏差,隨著金額越大時間越長偏差就會越大。比較好的方式是通過整型來儲存,通過放大`金額比例`來達到不同的業務場景下對`金額比率`的要求。
> 正常的1.12元,儲存比率是1=100元,那麼表裡的儲存值就是112,不同的貨幣比例都可以自由縮放,永遠都可以保持最準確的精度。
__分庫分表+讀寫分離:__ 根據業務特點和未來增量規劃,將DB分為16個邏輯庫,前期使用2個物理庫承載。16個邏輯庫,按照每次2倍擴容,最大擴容上限是16個物理庫。單例項的配置 _8c 32g 2t 8000conn 9000iops_ 。
> 按照單次TPS-rt 1ms計算,TPS 1w 需求,每臺承載5k TPS,單庫的活躍執行緒大概在8-10個(考慮網路延遲)。
最後到達瓶頸的都是iops,因為只要rt足夠短,最終壓力都會在IO上。
分庫按照uid分為16個庫,賬戶表不分表預設16張。每張表按照 _1kw*16=1.6_ 億個賬戶。
>單表能儲存多少要綜合考慮,比如查詢型別,單次查詢的RT,冷熱資料佔比( _innodb_buffer_pool_ 利用率)、是否充分發揮了索引,索引是否達到3星級別,`索引片`中沒有經常變更的欄位等。
賬戶流水錶按照日期分表365張,流水資料會隨著時間推移逐漸變成冷資料,定期歸檔冷資料。(這裡約定了,流水查詢只能按照uid+日期查詢。如果運營類的需求,要橫跨分片key獲取,走OLAP方案 clickhouse、hive等)
分庫分表採用阿里雲分散式資料庫產品DRDS,1個主庫叢集+2個讀庫叢集(讀庫做了讀負載均衡,可以按需擴容)。
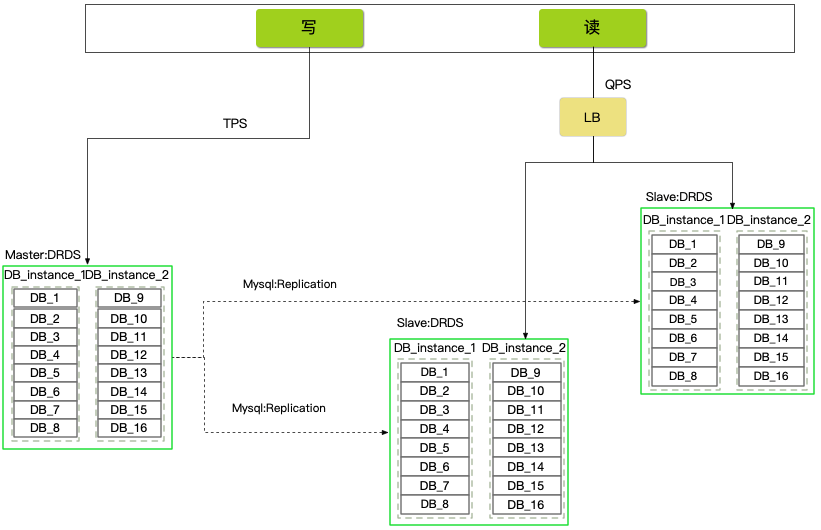
> 讀負載均衡器:https://github.com/Plen-wang/read-loadbalance
既然用了DRDS分散式資料庫產品,那麼在查詢上需要充分考慮`分片鍵`的限制,如果儲存和查詢出現分片鍵衝突問題就需要我們手動計算分片路由,直接訪問物理節點。
訪問物理節點需要藉助DRDS專用`SQL註釋`子句來完成。
先通過 `show node` 檢視物理DB ID、`show topology from logic_table_name` 檢視物理表ID,然後在SQL帶上特定的`註釋子句`。
```
SELECT /*+TDDL:scan('logic_table_name', real_table=("real_table_name"),node='real_db_node_id')*/
count(1) FROM logic_table_name ;
```
__賬戶更新:__ 對賬戶更新都有一個前提就是賬戶已經開通,但是我們為了最大化賬戶系統在使用上的便利性,讓前臺業務方不需要做初始化動作,由賬戶系統`惰性初始化`,比如發現賬戶不存在就自動初始化賬戶資料。
但是我們怎麼知道賬戶不存在,不可能每次都去查詢一次或者根據執行返回錯誤判斷。而且 update 語句是區分不了錯誤的 _賬戶不存在_ 還是 _餘額不足_ 或者其他原因。
那麼如何巧妙的解決這個問題,只要一次DB往返。
我們可以使用 Mysql `INSERT INTO ... ON DUPLICATE KEY UPDATE ...` 子句,但是該子句有一個限制就是不支援 `where` 子句。
```
-- cut_version 樂觀鎖、account_property 賬戶屬性
insert into tb_account(uid,balance,cut_version,account_property) values("%s",%d,%d,%d) ON DUPLICATE KEY UPDATE balance = balance + %d,cut_version = cut_version+1
```
其實不完全推薦使用這個方法,因為這個方法也有弊端就是將來 where 子句無法使用,還有一個辦法就是合併 _賬戶查詢_ 和 _插入_ 為一條 sql 提交。
DB操作本身rt可能很短,但是如果跨網路那麼事務的延遲會帶來DB的序列化增加,降低併發度,整體應用 rt就會增加。所以一個原則就是儘量不要跨網路開事務,合併sql做一次事務提交,最短的事務週期,減少跨網路的事務操作,如果我們將單次事務網路互動減少2-3次,效能的提高可能會增加2-3倍,同樣由於網路的不穩定抖動丟包對 999rt 線的影響也會減少2-3倍。
>平衡好當前系統是`業務密集型`還是`資料密集型`。
判斷當前系統是否有很強的業務層邏輯,是否要運用`DDD`、`RUP`等強模型的工程方法。畢竟`強模型`和`高效能`在落地的時候有些方面是衝突的,需要進一步藉助 `CRQS`、`GRASP`等工程方法來解決。
__單行熱點問題:__ 單行的TPS都是序列的,事務rt越短TPS就越高,按照1ms計算,差不多TPS就是1000。一般只有`機構賬戶`型別才會有這個需求。
我們可以將單行變成多行,增加行的並行度,加大賬戶操作的併發度。(這個方案要評估好寫入和查詢兩端需求)
| id | uid | balance | slot |
|----------|------------|------------|------------|
| 1 | 10101010 |1000 |1 |
| 2 | 10101010 |2000 |2 |
| 3 | 10101010 |3000 |3 |
| 4 | 10101010 |400 |4 |
| 5 | 10101010 |300 |5 |
| 6 | 10101010 |200 |6 |
| 7 | 10101010 |200 |7 |
| 8 | 10101010 |200 |8 |
| 9 | 10101010 |200 |9 |
| 10 | 10101010 |200 |10 |
```
insert into tb_account (uid,balance,slot)
values(10101010, 1000, round(rand()*9)+1)
on duplicate key update balance=balance+values(balance)
```
這裡的 _10slot*單個slot 1000TPS_,理論上可以跑到1w,如果機構賬戶資料量很大,可以擴充套件`slot`個數。
賬戶的總餘額通過`sum()`彙總,如果業務場景中有餘額的頻繁sum()操作,可以通過增加餘額中間表,定期 `insert into tb_account_total select sum(balance) total_balance from tb_account group by uid ` 。
通常機構賬戶的結算是有周期的(T+7、T+30等),而且基本是沒有併發,所以在賬戶餘額扣減方面就可以輕鬆處理。
有兩種實現方案:
第一種,賬戶餘額允許單個slot為負數,但是總的sum()是正數。通過子查詢來對餘額進行檢查。
```
insert into tb_account (uid, balance, slot)
select uid,-1000 as balance,round(rand() *9+ 1)
from(
select uid, sum(balance) as ss
from tb_account
where uid= 10101010
group by uid having ss>= 1000 for update) as tmp
on duplicate key update balance= balance+ values(balance)
```
第二種,如果條件允許可以藉助`使用者自定義`變數來在DB上完成餘額累計掃描,將可以扣減的slot的主鍵id返回給程式,但是隻需要一次DB互動就可以獲取出可以扣減的賬戶solt,然後分別開始對slot賬戶進行扣減。
```
set @f:=0;
select * from tb_account where id in(select id from (select id, @f:=@f+balance from tb_account where @f<1000 order by id) as t);
```
第二種方案在預設的mysql資料庫上都是支援的,但是有些資料庫雲產品不支援,阿里雲rds是不支援的。
# 日切對賬
賬戶系統有一個基本的需求,就是每天餘額映象,簡單講就是餘額在每天的快照,用來做T+1對賬。
不管財務還是每季度的審計都會需要,最重要的是我們自己也需要對賬戶資料做摸底對賬。
由於每天產生上億的流水,這需要在大資料平臺中完成。
>日切對賬:`昨天賬戶餘額` - `前天賬戶餘額` = `昨天的流水` - `前天的流水`。
>比如,昨天的賬戶餘額是5000w,前臺的賬戶餘額是4500w,差值就是500w。同樣道理,昨天的賬戶流水是5000w,前天的賬戶流水是4500w,那麼差值是500w,這就是沒問題的。
>賬戶不僅有增加也有減少,可能昨天賬戶餘額比前天賬戶餘額差值是-500w,但是流水也要是-500w才行。
由於每天會產生億級的流水,用傳統的全量抽取不現實,這類資料抽取的速度都會有延遲,而且對賬最重要的是時間點必須非常精準,才能保證餘額和流水是對得上的。
要不然會出現HDFS的分割槽是2020-06-10號,但是該分割槽裡有2020-06-11的資料,就是因為拉取的時候會延遲到第二天。這個問題也可以通過增加拉取sql的條件限制來解決這個問題,但是無法做到0點瞬間映象全部賬戶。
解決方案: _全量餘額+binlog增量更新_
1.賬戶表,先做一次全量同步。
2.DB的所有變更通過binlog(預設row複製)進到數倉。(因為 binlog 是基於發生時間的,所以無所謂我們是不是在0點去計算映象)
3.T+1跑JOB的時候,獲取前一天的賬戶餘額,然後通過 binlog 來覆蓋前天與昨天的交集部分。
由於數倉的 binlog 資料都是增量的,所以要想取到正確的全量資料需要用到一定的技巧。
```
select app_id,sub_type,sum(amount) records_amount from (
select *,row_number()over(partition by id order by updated_at) as rn
from hive_db_table
where dt='${YESTERDAY}'
) t where t.rn=1
group by t.sub_type,t.app_id
```
使用 hive 開窗函式 `row_number()over()` 對同樣的id進行分組,然後獲取最新的一條資料就是賬戶在T的最後的值。
>作者:王清培(趣頭條 Tech Le