
深入理解程序,執行緒,協程
阿新 • • 發佈:2020-06-23
> 程序,執行緒,協程,以及golang協程和python協程的區別。
## 1. 程序
程序是系統進行資源分配和排程的一個獨立單位,程式段、資料段、PCB三部分組成了程序實體(程序映像),**PCB是程序存在的唯一標準**
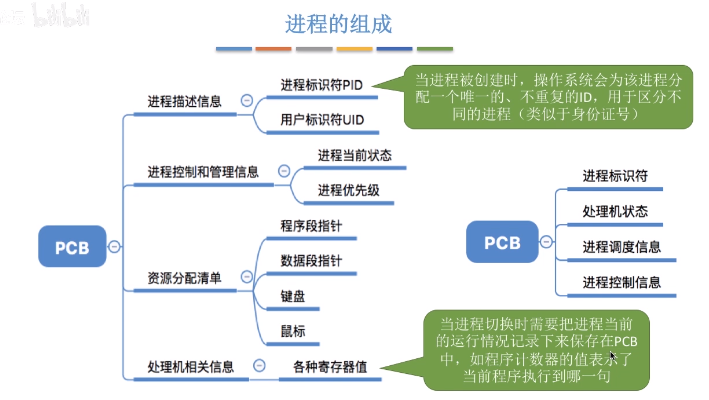
### 1.1 程序的組織方式:
- 連結方式
- 按照程序狀態將PCB分為多個佇列,就緒佇列,阻塞佇列等
- 作業系統持有指向各個佇列的指標
- 索引方式
- 根據程序狀態的不同,建立幾張索引表
- 作業系統持有指向各個索引表的指標
### 1.2 程序的狀態
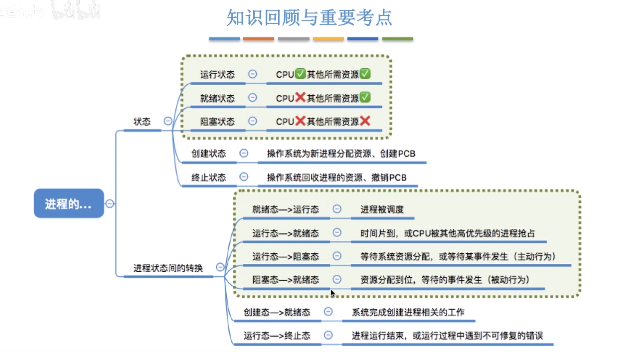
- 建立態: 作業系統為程序分配資源,初始化PCB
- 就緒態:執行資源等條件都滿足,儲存在就緒佇列中,等待CPU排程
- 執行態:CPU正在執行程序
- 阻塞態:等待某些條件滿足,等待訊息回覆,等待同步鎖,sleep等,阻塞佇列
- 終止態 :回收程序擁有的資源,撤銷PCB
### 1.3 程序的切換和排程
*程序在**作業系統核心程式臨界區**中不能進行排程與切換*
臨界資源:一個時間段內只允許一個程序使用資源,各程序需要互斥地訪問臨界資源
臨界區:訪問臨界資源的程式碼
核心程式臨界區:訪問某種核心資料結構,如程序的就緒佇列(儲存各程序的PCB)
**程序排程的方式:**
- 非剝奪排程方式(非搶佔方式),只允許程序主動放棄處理機,在執行過程中即便有更緊迫的任務到達,當前程序依然會繼續使用處理機,直到該程序終止或者主動要求進入阻塞態
- 剝奪排程方式(又稱搶佔方式)當一個程序正在處理機上執行時,如果有一個優先順序更高的程序需要處理機,則立即開中斷暫停正在執行的程序,將處理機飯呢陪給優先順序高的那個程序
**程序的切換與過程**:程序的排程、切換是有代價的
1. 對原來執行程序各種資料的儲存
2. 對新的程序各種資料恢復(程式計數器,程式狀態字,各種資料暫存器等處理機的現場)
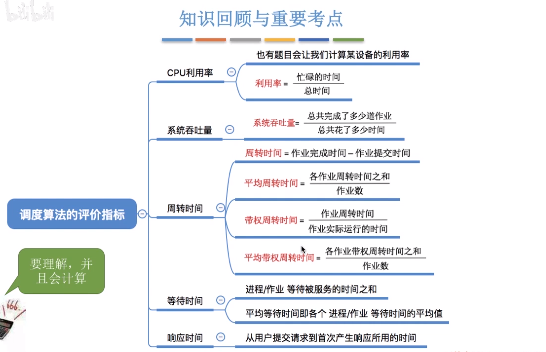
程序排程演算法的相關引數:
- CPU利用率:CPU忙碌時間/作業完成的總時間
- 系統吞吐量:單位時間內完成作業的數量
- 週轉時間:從作業被提交給系統開始,到作業完成為止的時間間隔 = 作業完成時間-作業提交時間
- 帶權週轉時間:(由於週轉時間相同的情況下,可能實際作業的執行時間不一樣,這樣就會給使用者帶來不一樣的感覺) 作業週轉時間/作業實際執行時間, 帶權週轉時間>=1, 越小越好
- 平均帶權週轉時間:各作業帶權週轉時間之和/作業數
- 等待時間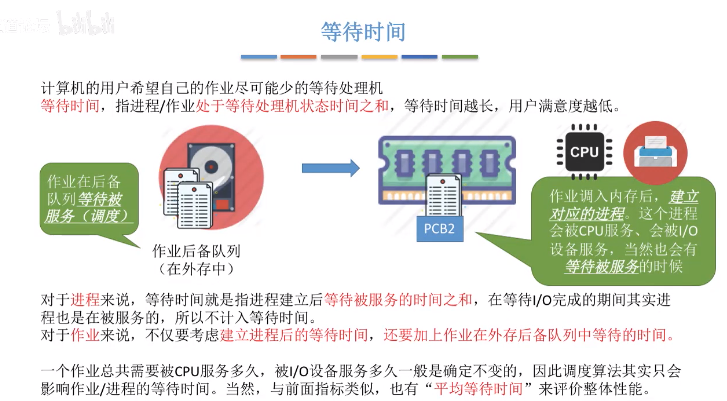
- 響應時間
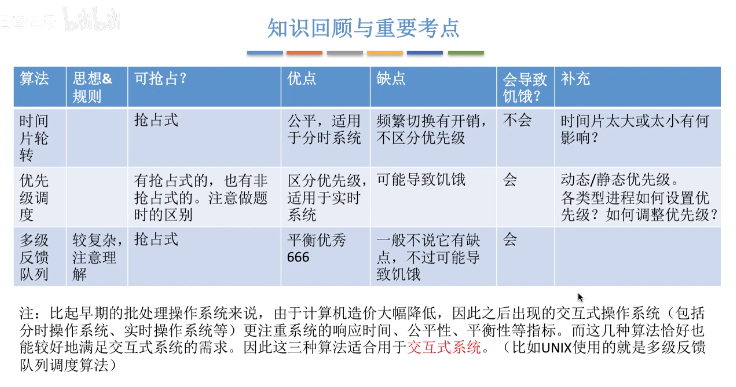
**排程演算法:**
演算法思想,用於解決什麼問題?
演算法規則,用於作業(PCB作業)排程還是程序排程?
搶佔式還是非搶佔式的?
優缺點?是否會導致飢餓?
**以下排程演算法是適用於當前互動式作業系統**
- **時間片輪轉(Round-Robin)**
- 演算法思想:公平地、輪流地為各個程序服務,讓每個程序在一定時間間隔內可以得到相應
- 演算法規則:按照各程序到達就緒佇列的順序,輪流讓各個程序執行一個時間片(如100ms)。若程序未在一個時間片內執行完,則剝奪處理機,將程序重新放到就緒佇列隊尾重新排隊。
- 用於作業/程序排程:用於程序的排程(只有作業放入記憶體建立相應的程序後,才會被分配處理機時間片)
- 是否可搶佔?若程序未能在規定時間片內完成,將被強行剝奪處理機使用權,由時鐘裝置發出時鐘中斷訊號來通知CPU時間片到達
- 優缺點:適用於分時作業系統,由於高頻率的程序切換,因此有一定開銷;不區分任務的緊急程度
- 是否會導致飢餓? 不會
- **優先順序排程演算法**
- 演算法思想:隨著計算機的發展,特別是實時作業系統的出現,越來越多的應用場景需要根據任務的程序成都決定處理順序
- 演算法規則:每個作業/程序有各自的優先順序,排程時選擇優先順序最高的作業/程序
- 用於作業/程序排程:即可用於作業排程(處於外存後備佇列中的作業排程進記憶體),也可用於程序排程(選擇就緒佇列中的程序,為其分配處理機),甚至I/O排程
- 是否可搶佔? 具有可搶佔版本,也有非搶佔式的
- 優缺點:適用於實時作業系統,用優先順序區分緊急程度,可靈活地調整對各種作業/及程序的偏好程度。缺點:若源源不斷地提供高優先順序程序,則可能導致飢餓
- 是否會導致飢餓: 會
- **多級反饋佇列排程演算法**
- 演算法思想:綜合FCFS、SJF(SPF)、時間片輪轉、優先順序排程
- 演算法規則:
- 1.設定多級就緒佇列,各級別佇列優先順序從高到底,時間片從小到大
- 2.新程序到達時先進入第1級佇列,按照FCFS原則排隊等待被分配時間片,若用完時間片程序還未結束,則程序進入下一級佇列隊尾
- 3.只有第k級別佇列為空時,才會為k+1級對頭的程序分配時間片
- 用於作業/程序排程:用於程序排程
- 是否可搶佔? 搶佔式演算法。在k級佇列的程序執行過程中,若更上級別的佇列(1-k-1級)中進入一個新程序,則由於新程序處於優先順序高的佇列中,因此新程序會搶佔處理機,原理執行的程序放回k級佇列隊尾。
- 優缺點:對各型別程序相對公平(FCFS的有點);每個新到達的程序都可以很快就得到相應(RR優點);短程序只用較少的時間就可完成(SPF)的有點;不必實現估計程序的執行時間;可靈活地調整對各類程序的偏好程度,比如CPU密集型程序、I/O密集型程序(拓展:可以將因I/O而阻塞的程序重新放回原佇列,這樣I/O型程序就可以保持較高優先順序)
- 是否會導致飢餓: 會
- 
## 2. 執行緒
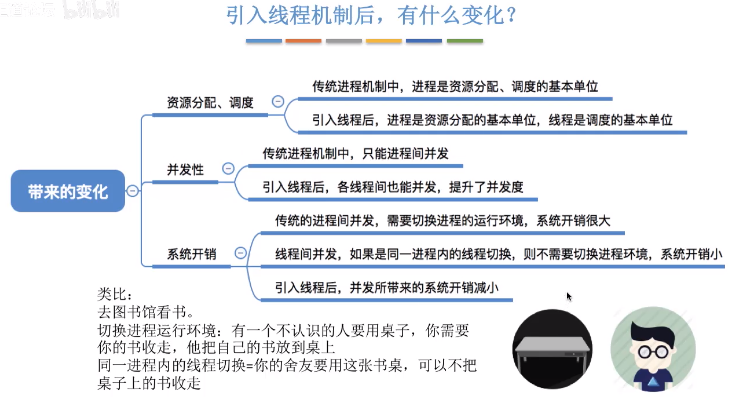
引入執行緒之後,程序只作為除CPU之外的系統資源的分配單元(如:印表機,記憶體地址空間等都是分配給程序的)
執行緒的是實現方式:
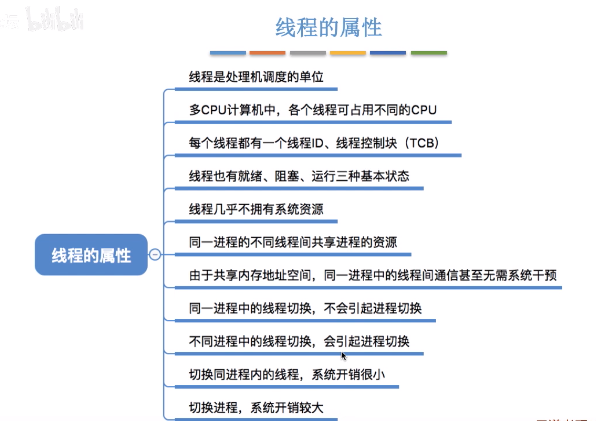
- 使用者級執行緒(User-Level Thread),使用者級執行緒由應用程式通過執行緒庫是實現如python (import thread), 執行緒的管理工作由應用程式負責。
- 核心級執行緒(kernel-Level Thread),核心級執行緒的管理工作由作業系統核心完成,執行緒排程,切換等工作都由核心負責,因此核心級執行緒的切換必然需要在核心態下才能完成
程序和執行緒的關係:一條執行緒指的是程序中一個單一順序的控制流,一個程序中可以併發多個執行緒,每條執行緒並行執行不同的任務。CPU的最小排程單元是執行緒,所以單程序多執行緒是可以利用多核CPU的。
### 2.1 執行緒模型:
- 使用者級執行緒模型(一對多模型)
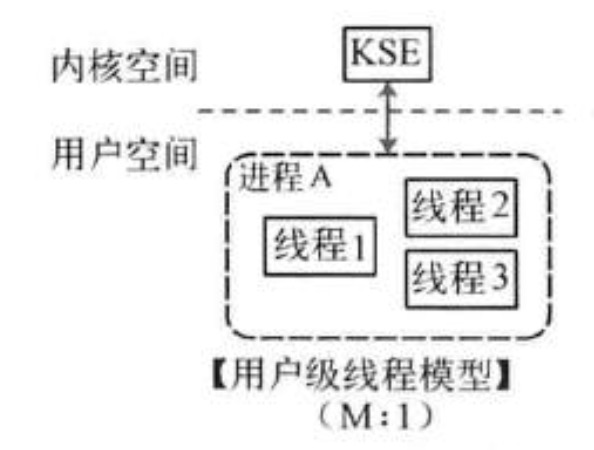
多個使用者態的執行緒對應著一個核心執行緒,程式執行緒的建立、終止、切換或者同步等執行緒工作必須自身來完成。python就是這種。雖然可以實現非同步,但是不能有效利用多核(GIL)
- 核心級執行緒模型 (一對一)
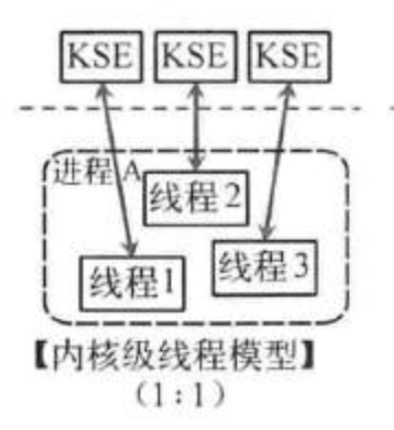
這種模型直接呼叫作業系統的核心執行緒,所有執行緒的建立、終止、切換、同步等操作,都由核心來完成。C++就是這種
- 兩級執行緒模型(M:N)
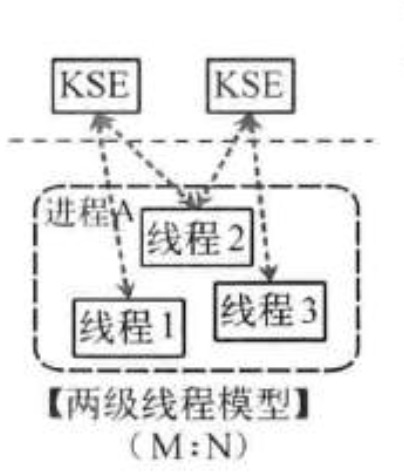
這種執行緒模型會先建立多個核心級執行緒,然後用自身的使用者級執行緒去對應建立的多個核心級執行緒,自身的使用者級執行緒需要本身程式去排程,核心級的執行緒交給作業系統核心去排程。GO語言就是這種。
python中的多執行緒因為GIL的存在,並不能利用多核CPU優勢,但是在阻塞的系統呼叫中,如sock.connect(), sock.recv()等耗時的I/O操作,當前的執行緒會釋放GIL,讓出處理器。但是單個執行緒內,阻塞呼叫上還是阻塞的。除了GIL之外,所有的多執行緒還有通病,他們都是被OS呼叫的,排程策略是搶佔式的,以保證同等有限級的執行緒都有機執行,帶來的問題就是:並不知道下一刻執行那個執行緒,也不知道正在執行什麼程式碼,會存在**競態條件**
## 3. 協程
協程通過線上程中實現排程,避免了陷入核心級別的上下文切換造成的效能損失,進而突破了執行緒在IO上的效能瓶頸。
python的協程源於yield指令
- yield item 用於產出一個值,反饋給next()的呼叫方法
- 讓出處理機,暫停執行生成器,讓呼叫方繼續工作,直到需要使用另一個值時再呼叫next()
協程式對執行緒的排程,yield類似惰性求職方式可以視為一種流程控制工具,實現協作式多工,python3.5引入了async/await表示式,使得協程證實在語言層面得到支援和優化,大大簡化之前的yield寫法。執行緒正式在語言層面得到支援和優化。執行緒是核心進行搶佔式排程的,這樣就確保每個執行緒都有執行的機會。而coroutine執行在同一個執行緒中,有語言層面執行時中的EventLoop(事件迴圈)來進行排程。在**python中協程的排程是非搶佔式的**,也就是說一個協程必須主動讓出執行機會,其他協程才有機會執行。讓出執行的關鍵字 await, 如果一個協程阻塞了,持續不讓出CPU處理機,那麼整個執行緒就卡住了,沒有任何併發。
PS: 作為服務端,event loop最核心的就是I/O多路複用技術,所有來自客戶端的請求都由I/O多路複用函式來處理;作為客戶端,event loop的核心在於Future物件延遲執行,並使用send函式激發協程,掛起,等待服務端處理完成返回後再呼叫Callback函式繼續執行。[[python 協程與go協程的區別](https://www.cnblogs.com/lgjbky/p/10838035.html)]
### 3.1 Golang 協程
Go 天生在語言層面支援,和python類似都是用關鍵字,而GO語言使用了go關鍵字,go協程之間的通訊,採用了channel關鍵字。
go實現了兩種併發形式:
- 多執行緒共享記憶體:如Java 或者C++在多執行緒中共享資料的時候,通過鎖來訪問
- Go語言特有的,也是Go語言推薦的 CSP(communicating sequential processes)併發模型。
```go
package main
import ("fmt")
func main() {
jobs := make(chan int)
done := make(chan bool) // end flag
go func() {
for {
j, ok := <- jobs
fmt.Println("---->:", j, ok)
if ok {
fmt.Println("received job")
} else {
fmt.Println("end received jobs")
done <- true
return
}
}
}()
go func() {
for j:= 1; j <= 3; j++ {
jobs <-j
fmt.Println("sent job", j)
}
close(jobs)
fmt.Println("close(jobs)")
}()
fmt.Println("sent all jobs")
<-done // 阻塞 讓main等待協程完成
}
```
Go的CSP併發模型是通過goroutine 和 channel來實現的。
- goroutine是go語言中併發的執行單位。
- channel是Go語言中各個併發結構體之間的通訊機制。
- channel -< data 寫資料
- <- channel 讀資料
協程本質上來說是一種使用者態的執行緒,不需要系統來執行搶佔式排程,而是在語言測個面實現執行緒的排程。
## 4. 併發
**併發:Do not communicate by sharing memory; instead, share memory by communicate.**
### 4.1 Actor模型

Actor模型和CSP模型的區別:
- CSP並不Focus傳送訊息的實體/Task, 而是關注傳送訊息時訊息所使用的載體,即channel。
- 在Actor的設計中,Actor與信箱是耦合的,而在CSP中channel是作為first-class獨立存在的
- Actor中有明確的send/receive關係,而channel中並不區分這樣的關係,執行快可以任意選擇傳送或者取訊息
>