
多模態融合註記
阿新 • • 發佈:2020-07-03
多模態機器學習MultiModal Machine Learning (MMML),旨在通過機器學習並處理理解多種模態資訊。包括多模態表示學習Multimodal Representation,模態轉化Translation,對齊Alignment,多模態融合Multimodal Fusion,協同學習Co-learning等。
多模態融合Multimodal Fusion也稱多源資訊融合(Multi-source Information Fusion),多感測器融合(Multi-sensor Fusion)。多模態融合是指綜合來自兩個或多個模態的資訊以進行預測的過程。在預測的過程中,單個模態通常不能包含產生精確預測結果所需的全部有效資訊,多模態融合過程結合了來自兩個或多個模態的資訊,實現資訊補充,拓寬輸入資料所包含資訊的覆蓋範圍,提升預測結果的精度,提高預測模型的魯棒性。
**一、融合方法**

####1.1早期融合
為緩解各模態中原始資料間的不一致性問題,可以先從每種模態中分別提取特徵的表示,然後在特徵級別進行融合,即特徵融合。由於深度學習中會涉及從原始資料中學習特徵的具體表示,從而導致有時需在未抽取特徵之前就進行資料融合,因此資料層面和特徵層面的融合均稱為早期融合。
特徵融合實現過程中,首先提取各輸入模態的特徵,然後將提取的特徵合併到融合特徵中,融合特徵作為輸入資料輸入到一個模型中,輸出預測結果。早期融合中,各模態特徵經轉換和縮放處理後產生的融合特徵通常具有較高的維度,可以使用主成分分析( PCA) 和線性判別分析( LDA) 對融合特徵進行降維處理。
早期融合中模態表示的融合有多種方式,常用的方式有對各模態表示進行相同位置元素的相乘或相加、構建編碼器—解碼器結構和用 LSTM 神經網路進行資訊整合等。
####1.2 晚期融合
晚期融合方法也稱決策級融合方法,先用不同模型對不同模態進行訓練,再融合多個模型輸出的結果。晚期融合方法主要採用規則來確定不同模型輸出結果的結合策略,例如最大值結合、平均值結合、貝葉斯規則結合以及整合學習等結合方法。
與早期融合相比,晚期融合可較簡單地處理資料的非同步性,整個系統可以隨模態個數的增加進行擴充套件,每個模態的專屬預測模型能更好地針對該模態進行建模,當模型輸入缺少某些模態時也可以進行預測。然而晚期融合也存在一些缺點,如未考慮特徵層面的模態相關性、實現難度更高等。
####1.3 混合融合
混合融合方法結合早期和晚期融合,在綜合兩者優點同時也增加了模型結構複雜度和訓練難度。研究表明:各融合方式並無確定的優劣關係,在不同的實驗條件下,可以嘗試不同的融合方式以獲得較好的融合結果。
**二、應用例項**
####2.1基於多模態特徵和多分類器融合的前列腺癌放療中直腸併發症預測
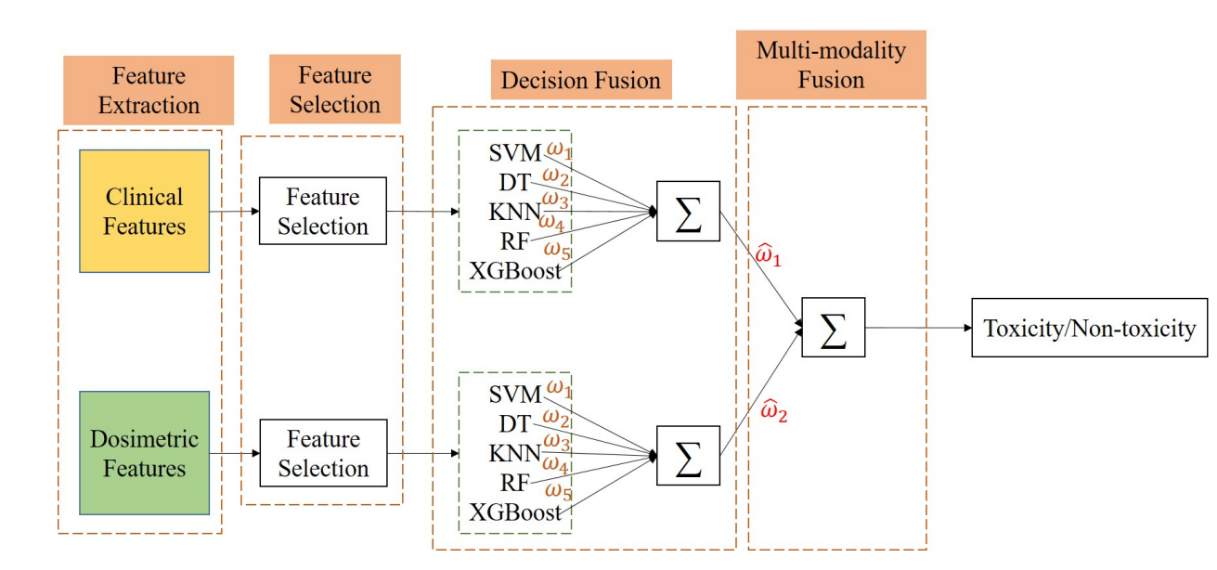
上述模型首先在分類器層面上進行第一輪融合,然後在模態層面上進行第二輪融合。因此需要為每個分類器以及每個模態(臨床引數特徵和劑量學特徵)分配權重。權重分配後,依次實現分類器決策融合與模態資訊融合。
1.分類器決策融合,是對每個分類器的預測概率進行加權求和:
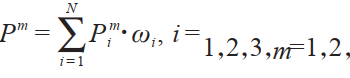
其中, 表示單模態下各個分類器對待預測樣本的預測概率值, 表示每個分類器的權重, 為當前模態下融合多分類器資訊後的預測概率。
2.多模態資訊融合,是對單模態決策的結果進行加權求和:

其中, 為每個單模態下多分類器融合的預測概率, 為分配給該模態的權重。經過以上兩次融合,最終得到患者發生併發症的概率P和不發生併發症的概率(1-P)。
####2.2基於多模態特徵融合的骨質疏鬆評估
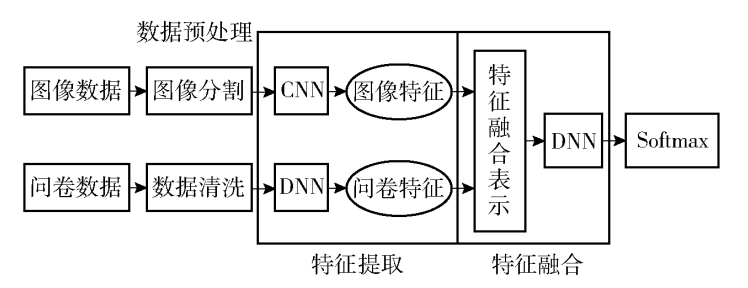
影象特徵包含骨骼結構資訊,問卷特徵包含骨質疏鬆影響因素的個體資訊,兩方面的模態資訊存在一定的互補關係,有必要進行適當的特徵融合。
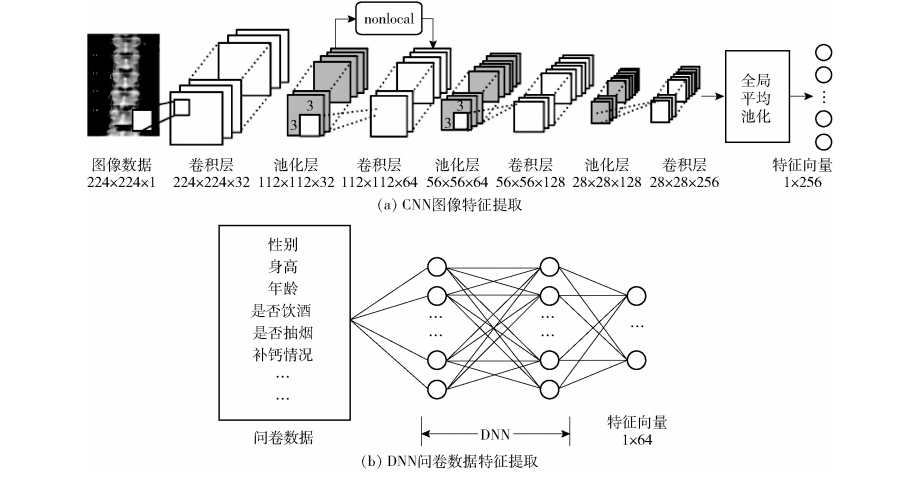
目前特徵融合方法有以下幾種: 特徵向量按照人工規則線性融合;計算多個向量相似度矩陣,按照相似度進行融合;直接拼接特徵向量。

實驗中交叉驗證結果表明,多模態特徵融合方法與僅單獨使用影象資料或問卷資料的機器學習方法相比,分類準確率有了明顯提升。
####2.3多模態融合下長時程肺部病灶良惡性預測
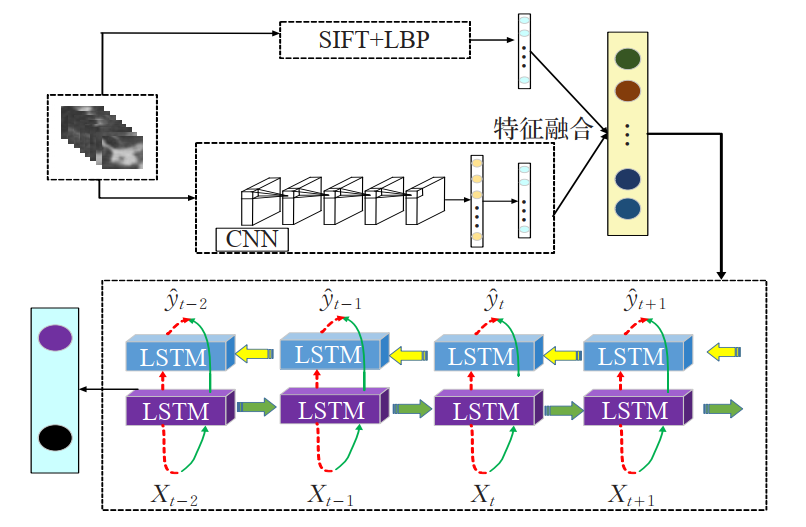
針對同一病人從早期到確診的 CT 影像,分別提取肺結節影象的傳統特徵與深度特徵(雙模態),利用一個兩層神經網路進行相關性融合;然後選取不同時期的肺結節多模態特徵融合向量,利用長短期記憶網路研究各時期特徵向量的變化趨勢及關係,利用雙向長短期記憶模型預測長時程下肺部病灶的演化趨勢並確定其良惡性。
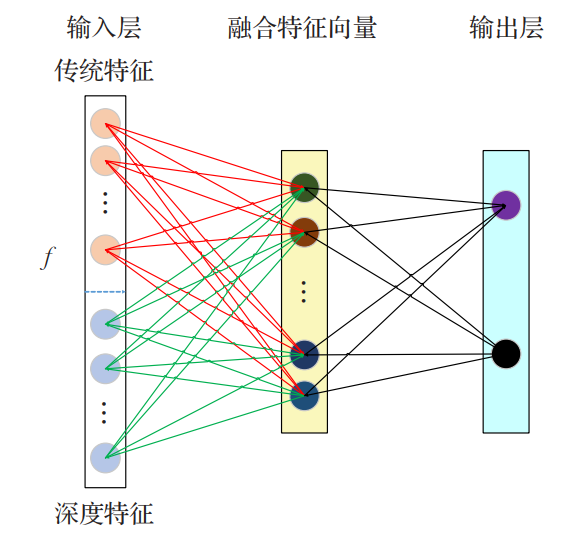
通過構建一個雙層神經網路實現特徵融合:輸入層為傳統特徵與深度特徵的串接,通過學習隱藏層的權值得到融合後的特徵。隱藏層的節點數為融合特徵的維數。
####2.4 基於隨機化融合和CNN的多模態肺部腫瘤影象識別
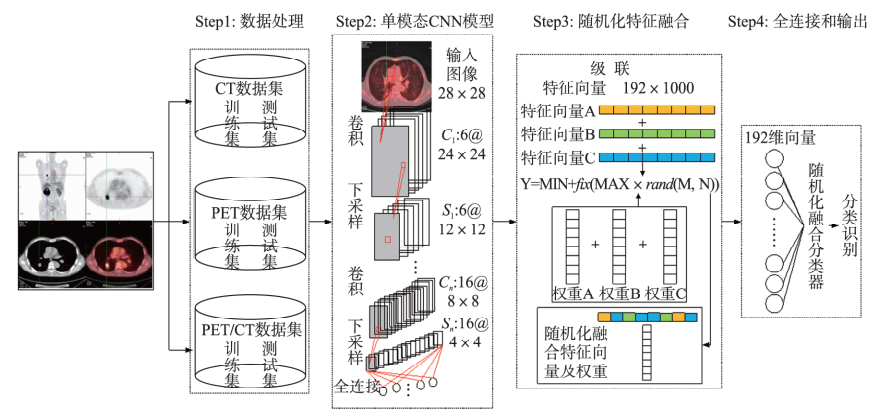
使用三個不同的醫學影像資料集,視為三個不同的模態資訊,共同執行肺部腫瘤影象識別:
(1)利用改進的Lenet-5網路模型實現對多模態肺部腫瘤影象並行地特徵提取;(2)利用隨機化函式對並聯的多模態特徵進行融合,重建同一維度的目標特徵;(3)新增全連線層和分類層對網路進行迴歸訓練,從而得到分類結果。
在step3中,採用隨機化融合方法實現特徵融合:
通過對CNN模型的微調,將構造好的三個單模態CNN全連線層的192維特徵向量、相對應的權值和偏置分別提取出來,利用隨機函式
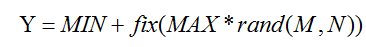
將特徵向量、對應的權重及偏置分別進行隨機化融合,同時遵循對應位置不變的融合規則。
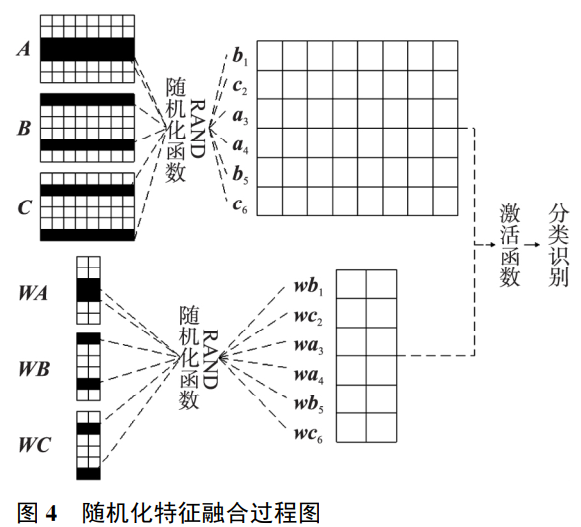
隨機化特徵融合過程: 分別代表不同模態的特徵矩陣, 分別表示 某一行的特徵向量, 分別代表對應於 的權值, 分別表示 某一行對應的權值.在隨機化融合過程中,根據同一隨機化原則,將 和 進行對應位置融合,隨機化融合後得到與之前同樣大小的融合矩陣,再將融合後的矩陣與權值輸入啟用函式中,得到分類