
小師妹學JVM之:cache line對程式碼效能的影響
阿新 • • 發佈:2020-07-07
[toc]
# 簡介
讀萬卷書不如行萬里路,講了這麼多assembly和JVM的原理與優化,今天我們來點不一樣的實戰。探索一下怎麼使用assembly來理解我們之前不能理解的問題。
# 一個奇怪的現象
小師妹:F師兄,之前你講了那麼多JVM中JIT在編譯中的效能優化,講真的,在工作中我們真的需要知道這些東西嗎?知道這些東西對我們的工作有什麼好處嗎?
um...這個問題問得好,知道了JIT的編譯原理和優化方向,我們的確可以在寫程式碼的時候稍微注意一下,寫出效能更加優秀的程式碼,但是這只是微觀上了。
如果將程式碼上升到企業級應用,一個硬體的提升,一個快取的加入或者一種架構的改變都可能比小小的程式碼優化要有用得多。
就像是,如果我們的專案遇到了效能問題,我們第一反應是去找架構上面有沒有什麼缺陷,有沒有什麼優化點,很少或者說基本上不會去深入到程式碼層面,看你的這個程式碼到底有沒有可優化空間。
第一,只要程式碼的業務邏輯不差,執行起來速度也不會太慢。
第二,程式碼的優化帶來的收益實在太小了,而工作量又非常龐大。
所以說,對於這種類似於雞肋的優化,真的有必要存在嗎?
其實這和我學習物理化學數學知識是一樣的,你學了那麼多知識,其實在日常生活中真的用不到。但是為什麼要學習呢?
我覺得有兩個原因,第一是讓你對這個世界有更加本質的認識,知道這個世界是怎麼執行的。第二是鍛鍊自己的思維習慣,學會解決問題的方法。
就想演算法,現在寫個程式真的需要用到演算法嗎?不見得,但是演算法真的很重要,因為它可以影響你的思維習慣。
所以,瞭解JVM的原理,甚至是Assembly的使用,並不是要你用他們來讓你的程式碼優化的如何好,而是讓你知道,哦,原來程式碼是這樣工作的。在未來的某一個,或許我就可能用到。
好了,言歸正傳。今天給小師妹介紹一個很奇怪的例子:
~~~java
private static int[] array = new int[64 * 1024 * 1024];
@Benchmark
public void test1() {
int length = array.length;
for (int i = 0; i < length; i=i+1)
array[i] ++;
}
@Benchmark
public void test2() {
int length = array.length;
for (int i = 0; i < length; i=i+2)
array[i] ++;
}
~~~
小師妹,上面的例子,你覺得哪一個執行的更快呢?
小師妹:當然是第二個啦,第二個每次加2,遍歷的次數更少,肯定執行得更快。
好,我們先持保留意見。
第二個例子,上面我們是分別+1和+2,如果後面再繼續+3,+4,一直加到128,你覺得執行時間是怎麼樣的呢?
小師妹:肯定是線性減少的。
好,兩個問題問完了,接下來讓我們來揭曉答案吧。
# 兩個問題的答案
我們再次使用JMH來測試我們的程式碼。程式碼很長,這裡就不列出來了,有興趣的朋友可以到本文下面的程式碼連結下載執行程式碼。
我們直接上執行結果:
~~~java
Benchmark Mode Cnt Score Error Units
CachelineUsage.test1 avgt 5 27.499 ± 4.538 ms/op
CachelineUsage.test2 avgt 5 31.062 ± 1.697 ms/op
CachelineUsage.test3 avgt 5 27.187 ± 1.530 ms/op
CachelineUsage.test4 avgt 5 25.719 ± 1.051 ms/op
CachelineUsage.test8 avgt 5 25.945 ± 1.053 ms/op
CachelineUsage.test16 avgt 5 28.804 ± 0.772 ms/op
CachelineUsage.test32 avgt 5 21.191 ± 6.582 ms/op
CachelineUsage.test64 avgt 5 13.554 ± 1.981 ms/op
CachelineUsage.test128 avgt 5 7.813 ± 0.302 ms/op
~~~
好吧,不夠直觀,我們用一個圖表來表示:
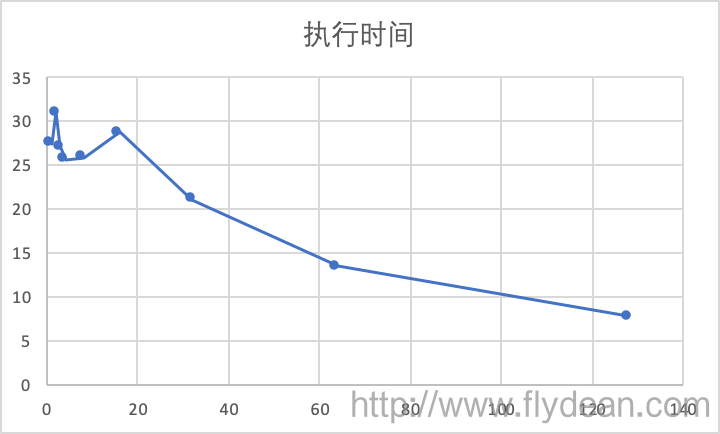
從圖表可以看出,步長在1到16之間的時候,執行速度都還相對比較平穩,在25左右,然後就隨著步長的增長而下降。
## CPU cache line
那麼我們先回答第二個問題的答案,執行時間是先平穩再下降的。
為什麼會在16步長之內很平穩呢?
CPU的處理速度是有限的,為了提升CPU的處理速度,現代CPU都有一個叫做CPU快取的東西。
而這個CPU快取又可以分為L1快取,L2快取甚至L3快取。
其中L1快取是每個CPU核單獨享有的。在L1快取中,又有一個叫做Cache line的東西。為了提升處理速度,CPU每次處理都是讀取一個Cache line大小的資料。
怎麼檢視這個Cache line的大小呢?
在mac上,我們可以執行:sysctl machdep.cpu
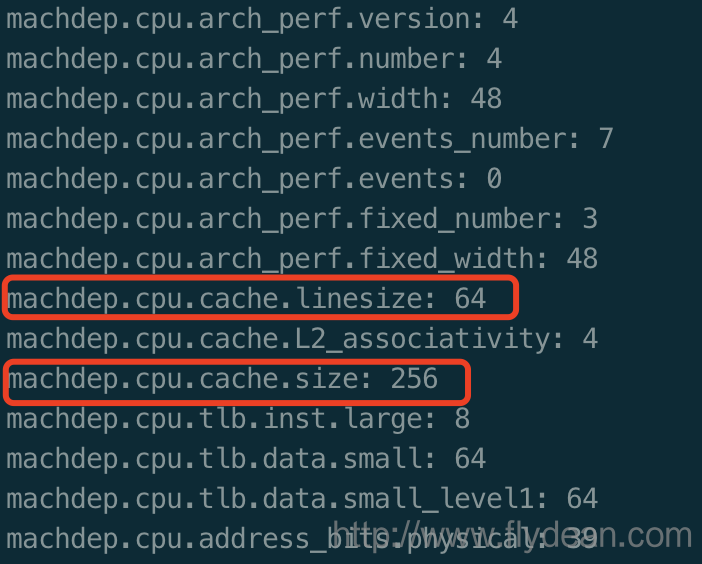
從圖中我們可以得到,機子的CPU cache line是64byte,而cpu的一級快取大小是256byte。
好了,現在回到為什麼1-16步長執行速度差不多的問題。
我們知道一個int佔用4bytes,那麼16個int剛好佔用64bytes。所以我們可以粗略的認為,1-16步長,每次CPU取出來的資料是一樣的,都是一個cache line。所以,他們的執行速度其實是差不多的。
## inc 和 add
小師妹:F師兄,上面的解釋雖然有點完美了,但是好像還有一個漏洞。既然1-16使用的是同一個cache line,那麼他們的執行時間,應該是逐步下降才對,為什麼2比1執行時間還要長呢?
這真的是一個好問題,光看程式碼和cache line好像都解釋不了,那麼我們就從Assembly的角度再來看看。
還是使用JMH,開啟PrintAssembly選項,我們看看輸出結果。
先看下test1方法的輸出:

再看下test2方法的輸出:

兩個有什麼區別呢?
基本上的結構都是一樣的,只不過test1使用的是inc,而test2方法使用的add。
本人對組合語言不太熟,不過我猜兩者執行時間的差異在於inc和add的差異,add可能會執行慢一點,因為它多了一個額外的引數。
# 總結
Assembly雖然沒太大用處,但是在解釋某些神祕現象的時候,還是挺好用的。
本文的例子[https://github.com/ddean2009/learn-java-base-9-to-20](https://github.com/ddean2009/learn-java-base-9-to-20)
> 本文作者:flydean程式那些事
>
> 本文連結:[http://www.flydean.com/jvm-jit-cacheline/](http://www.flydean.com/jvm-jit-cacheline/)
>
> 本文來源:flydean的部落格
>
> 歡迎關注我的公眾號:程式那些事,更多精彩等著您!