
百萬級別資料Excel匯出優化
阿新 • • 發佈:2020-07-12
## 前提
這篇文章不是標題黨,下文會通過一個模擬例子分析如何優化百萬級別資料`Excel`匯出。
筆者負責維護的一個數據查詢和資料匯出服務是一個相對遠古的單點應用,在上一次雲遷移之後擴充套件為雙節點部署,但是發現了服務經常因為大資料量的資料匯出頻繁`Full GC`,導致應用假死無法響應外部的請求。因為某些原因,該服務只能夠**分配`2GB`的最大堆記憶體**,下面的優化都是以這個堆記憶體極限為前提。通過檢視服務配置、日誌和`APM`定位到兩個問題:
1. 啟動指令碼中添加了`CMS`引數,採用了`CMS`收集器,該收集演算法對記憶體的敏感度比較高,大批量資料匯出容易瞬間打滿老年代導致`Full GC`頻繁發生。
2. 資料匯出的時候採用了一次性把目標資料全部查詢出來再寫到流中的方式,大量被查詢的物件駐留在堆記憶體中,直接打滿整個堆。
對於問題1諮詢過身邊的大牛朋友,直接把所有`CMS`相關的所有引數去掉,由於生產環境使用了`JDK1.8`,相當於直接使用預設的`GC`收集器引數`-XX:+UseParallelGC`,也就是`Parallel Scavenge + Parallel Old`的組合然後重啟服務。觀察`APM`工具發現`Full GC`的頻率是有所下降,但是一旦某個時刻匯出的資料量十分巨大(例如查詢的結果超過一百萬個物件,超越可用的最大堆記憶體),還是會陷入無盡的`Full GC`,也就是修改了`JVM`引數只起到了治標不治本的作用。所以下文會針對這個問題(也就是問題2),通過一個模擬案例來分析一下如何進行優化。
## 一些基本原理
如果使用`Java`(或者說依賴於`JVM`的語言)開發資料匯出的模組,下面的虛擬碼是通用的:
```java
資料匯出方法(引數,輸出流[OutputStream]){
1. 通過引數查詢需要匯出的結果集
2. 把結果集序列化為位元組序列
3. 通過輸出流寫入結果集位元組序列
4. 關閉輸出流
}
```
一個例子如下:
```java
@Data
public static class Parameter{
private OffsetDateTime paymentDateTimeStart;
private OffsetDateTime paymentDateTimeEnd;
}
public void export(Parameter parameter, OutputStream os) throws IOException {
List result =
orderDao.query(parameter.getPaymentDateTimeStart(), parameter.getPaymentDateTimeEnd()).stream()
.map(order -> {
OrderDTO dto = new OrderDTO();
......
return dto;
}).collect(Collectors.toList());
byte[] bytes = toBytes(result);
os.write(bytes);
os.close();
}
```
針對不同的`OutputStream`實現,最終可以把資料匯出到不同型別的目標中,例如對於`FileOutputStream`而言相當於把資料匯出到檔案中,而對於`SocketOutputStream`而言相當於把資料匯出到網路流中(客戶端可以讀取該流實現檔案下載)。目前`B`端應用比較常見的檔案匯出都是使用後一種實現,基本的互動流程如下:
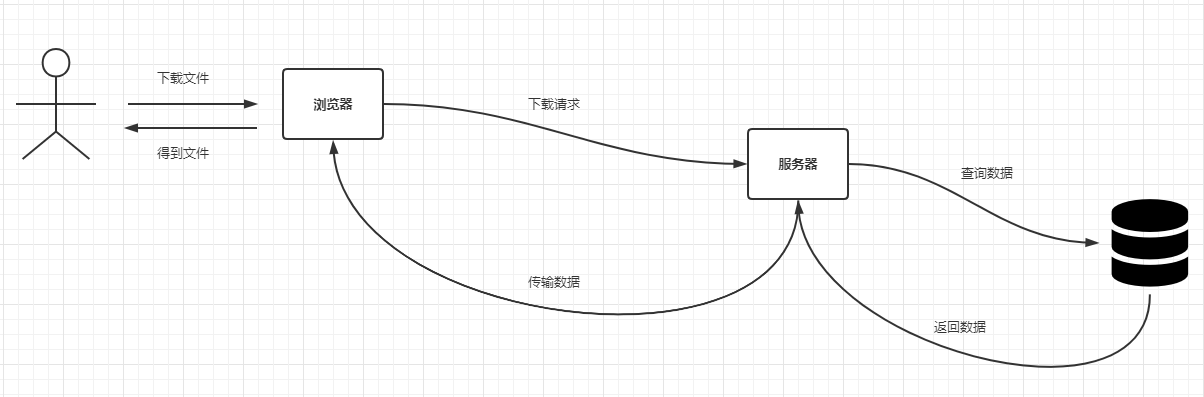
為了節省伺服器的記憶體,這裡的返回資料和資料傳輸部分可以設計為分段處理,也就是查詢的時候考慮把查詢全量的結果這個思路改變為每次只查詢部分資料,直到得到全量的資料,每批次查詢的結果資料都寫進去`OutputStream`中。
這裡以`MySQL`為例,可以使用類似於分頁查詢的思路,但是鑑於`LIMIT offset,size`的效率太低,結合之前的一些實踐,採用了一種**改良的"滾動翻頁"的實現方式**(這個方式是前公司的某個架構小組給出來的思路,後面廣泛應用於各種批量查詢、資料同步、資料匯出以及資料遷移等等場景,這個思路肯定不是首創的,但是實用性十分高),注意這個方案要求表中包含一個有自增趨勢的主鍵,單條查詢`SQL`如下:
```sql
SELECT * FROM tableX WHERE id > #{lastBatchMaxId} [其他條件] ORDER BY id [ASC|DESC](這裡一般選用ASC排序) LIMIT ${size}
```
把上面的`SQL`放進去前一個例子中,並且假設訂單表使用了自增長整型主鍵`id`,那麼上面的程式碼改造如下:
```java
public void export(Parameter parameter, OutputStream os) throws IOException {
long lastBatchMaxId = 0L;
for (;;){
List orders = orderDao.query([SELECT * FROM t_order WHERE id > #{lastBatchMaxId}
AND payment_time >= #{parameter.paymentDateTimeStart} AND payment_time <= #{parameter.paymentDateTimeEnd} ORDER BY id ASC LIMIT ${LIMIT}]);
if (orders.isEmpty()){
break;
}
List result =
orderDao.query([SELECT * FROM t_order]).stream()
.map(order -> {
OrderDTO dto = new OrderDTO();
......
return dto;
}).collect(Collectors.toList());
byte[] bytes = toBytes(result);
os.write(bytes);
os.flush();
lastBatchMaxId = orders.stream().map(Order::getId).max(Long::compareTo).orElse(Long.MAX_VALUE);
}
os.close();
}
```
**上面這個示例就是百萬級別資料`Excel`匯出優化的核心思路**。查詢和寫入輸出流的邏輯編寫在一個死迴圈中,因為查詢結果是使用了自增主鍵排序的,而屬性`lastBatchMaxId`則存放了本次查詢結果集中的最大`id`,同時它也是下一批查詢的起始`id`,這樣相當於基於`id`和查詢條件向前滾動,直到查詢條件不命中任何記錄返回了空列表就會退出死迴圈。而`limit`欄位則用於控制每批查詢的記錄數,可以按照應用實際分配的記憶體和每批次查詢的資料量考量設計一個合理的值,這樣就能讓單個請求下常駐記憶體的物件數量控制在`limit`個從而使應用的記憶體使用更加可控,避免因為併發匯出導致堆記憶體瞬間被打滿。
> 這裡的滾動翻頁方案遠比LIMIT offset,size效率高,因為此方案每次查詢都是最終的結果集,而一般的分頁方案使用的LIMIT offset,size需要先查詢,後截斷。
## 模擬案例
某個應用提供了查詢訂單和匯出記錄的功能,表設計如下:
```sql
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order`
(
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '主鍵',
`creator` VARCHAR(16) NOT NULL DEFAULT 'admin' COMMENT '建立人',
`editor` VARCHAR(16) NOT NULL DEFAULT 'admin' COMMENT '修改人',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '建立時間',
`edit_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改時間',
`version` BIGINT NOT NULL DEFAULT 1 COMMENT '版本號',
`deleted` TINYINT NOT NULL DEFAULT 0 COMMENT '軟刪除標識',
`order_id` VARCHAR(32) NOT NULL COMMENT '訂單ID',
`amount` DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '訂單金額',
`payment_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '支付時間',
`order_status` TINYINT NOT NULL DEFAULT 0 COMMENT '訂單狀態,0:處理中,1:支付成功,2:支付失敗',
UNIQUE uniq_order_id (`order_id`),
INDEX idx_payment_time (`payment_time`)
) COMMENT '訂單表';
```
現在要基於支付時間段匯出一批訂單資料,先基於此需求編寫一個簡單的`SpringBoot`應用,這裡的`Excel`處理工具選用`Alibaba`出品的`EsayExcel`,主要依賴如下:
```xml
org.springframework.boot
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
8.0.18
com.alibaba
easyexcel
2.2.6
```
模擬寫入`200W`條資料,生成資料的測試類如下:
```java
public class OrderServiceTest {
private static final Random OR = new Random();
private static final Random AR = new Random();
private static final Random DR = new Random();
@Test
public void testGenerateTestOrderSql() throws Exception {
HikariConfig config = new HikariConfig();
config.setUsername("root");
config.setPassword("root");
config.setJdbcUrl("jdbc:mysql://localhost:3306/local?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false");
config.setDriverClassName(Driver.class.getName());
HikariDataSource hikariDataSource = new HikariDataSource(config);
JdbcTemplate jdbcTemplate = new JdbcTemplate(hikariDataSource);
for (int d = 0; d < 100; d++) {
String item = "('%s','%d','2020-07-%d 00:00:00','%d')";
StringBuilder sql = new StringBuilder("INSERT INTO t_order(order_id,amount,payment_time,order_status) VALUES ");
for (int i = 0; i < 20_000; i++) {
sql.append(String.format(item, UUID.randomUUID().toString().replace("-", ""),
AR.nextInt(100000) + 1, DR.nextInt(31) + 1, OR.nextInt(3))).append(",");
}
jdbcTemplate.update(sql.substring(0, sql.lastIndexOf(",")));
}
hikariDataSource.close();
}
}
```
基於`JdbcTemplate`編寫`DAO`類`OrderDao`:
```java
@RequiredArgsConstructor
@Repository
public class OrderDao {
private final JdbcTemplate jdbcTemplate;
public List queryByScrollingPagination(long lastBatchMaxId,
int limit,
LocalDateTime paymentDateTimeStart,
LocalDateTime paymentDateTimeEnd) {
return jdbcTemplate.query("SELECT * FROM t_order WHERE id > ? AND payment_time >= ? AND payment_time <= ? " +
"ORDER BY id ASC LIMIT ?",
p -> {
p.setLong(1, lastBatchMaxId);
p.setTimestamp(2, Timestamp.valueOf(paymentDateTimeStart));
p.setTimestamp(3, Timestamp.valueOf(paymentDateTimeEnd));
p.setInt(4, limit);
},
rs -> {
List orders = new ArrayList<>();
while (rs.next()) {
Order order = new Order();
order.setId(rs.getLong("id"));
order.setCreator(rs.getString("creator"));
order.setEditor(rs.getString("editor"));
order.setCreateTime(OffsetDateTime.ofInstant(rs.getTimestamp("create_time").toInstant(), ZoneId.systemDefault()));
order.setEditTime(OffsetDateTime.ofInstant(rs.getTimestamp("edit_time").toInstant(), ZoneId.systemDefault()));
order.setVersion(rs.getLong("version"));
order.setDeleted(rs.getInt("deleted"));
order.setOrderId(rs.getString("order_id"));
order.setAmount(rs.getBigDecimal("amount"));
order.setPaymentTime(OffsetDateTime.ofInstant(rs.getTimestamp("payment_time").toInstant(), ZoneId.systemDefault()));
order.setOrderStatus(rs.getInt("order_status"));
orders.add(order);
}
return orders;
});
}
}
```
編寫服務類`OrderService`:
```java
@Data
public class OrderDTO {
@ExcelIgnore
private Long id;
@ExcelProperty(value = "訂單號", order = 1)
private String orderId;
@ExcelProperty(value = "金額", order = 2)
private BigDecimal amount;
@ExcelProperty(value = "支付時間", order = 3)
private String paymentTime;
@ExcelProperty(value = "訂單狀態", order = 4)
private String orderStatus;
}
@Service
@RequiredArgsConstructor
public class OrderService {
private final OrderDao orderDao;
private static final DateTimeFormatter F = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public List queryByScrollingPagination(String paymentDateTimeStart,
String paymentDateTimeEnd,
long lastBatchMaxId,
int limit) {
LocalDateTime start = LocalDateTime.parse(paymentDateTimeStart, F);
LocalDateTime end = LocalDateTime.parse(paymentDateTimeEnd, F);
return orderDao.queryByScrollingPagination(lastBatchMaxId, limit, start, end).stream().map(order -> {
OrderDTO dto = new OrderDTO();
dto.setId(order.getId());
dto.setAmount(order.getAmount());
dto.setOrderId(order.getOrderId());
dto.setPaymentTime(order.getPaymentTime().format(F));
dto.setOrderStatus(OrderStatus.fromStatus(order.getOrderStatus()).getDescription());
return dto;
}).collect(Collectors.toList());
}
}
```
最後編寫控制器`OrderController`:
```java
@RequiredArgsConstructor
@RestController
@RequestMapping(path = "/order")
public class OrderController {
private final OrderService orderService;
@GetMapping(path = "/export")
public void export(@RequestParam(name = "paymentDateTimeStart") String paymentDateTimeStart,
@RequestParam(name = "paymentDateTimeEnd") String paymentDateTimeEnd,
HttpServletResponse response) throws Exception {
String fileName = URLEncoder.encode(String.format("%s-(%s).xlsx", "訂單支付資料", UUID.randomUUID().toString()),
StandardCharsets.UTF_8.toString());
response.setContentType("application/force-download");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
ExcelWriter writer = new ExcelWriterBuilder()
.autoCloseStream(true)
.file(response.getOutputStream())
.head(OrderDTO.class)
.build();
// xlsx檔案上上限是104W行左右,這裡如果超過104W需要分Sheet
WriteSheet writeSheet = new WriteSheet();
writeSheet.setSheetName("target");
long lastBatchMaxId = 0L;
int limit = 500;
for (; ; ) {
List list = orderService.queryByScrollingPagination(paymentDateTimeStart, paymentDateTimeEnd, lastBatchMaxId, limit);
if (list.isEmpty()) {
writer.finish();
break;
} else {
lastBatchMaxId = list.stream().map(OrderDTO::getId).max(Long::compareTo).orElse(Long.MAX_VALUE);
writer.write(list, writeSheet);
}
}
}
}
```
這裡為了方便,把一部分業務邏輯程式碼放在控制器層編寫,實際上這是不規範的編碼習慣,這一點不要效仿。新增配置和啟動類之後,通過請求`http://localhost:10086/order/export?paymentDateTimeStart=2020-07-01 00:00:00&paymentDateTimeEnd=2020-07-16 00:00:00`測試匯出介面,某次匯出操作後臺輸出日誌如下:
```shell
匯出資料耗時:29733 ms,start:2020-07-01 00:00:00,end:2020-07-16 00:00:00
```
匯出成功後得到一個檔案(連同表頭一共`1031540`行):
## 小結
這篇文章詳細地分析大資料量匯出的效能優化,最要側重於記憶體優化。該方案實現了在儘可能少佔用記憶體的前提下,在效率可以接受的範圍內進行大批量的資料匯出。這是一個可複用的方案,類似的設計思路也可以應用於其他領域或者場景,不侷限於資料匯出。
文中`demo`專案的倉庫地址是:
- `Github`:https://github.com/zjcscut/spring-boot-guide/tree/master/ch10086-excel-export
(本文完 c-2-d e-a-20200711 20:27 PM)
技術公眾號《Throwable文摘》(id:throwable-doge),不定期推送筆者原創技術文章(絕不抄襲或者轉載):
![](https://public-1256189093.cos.ap-guangzhou.myqcloud.com/static/wechat-account-l