
5萬字、97 張圖總結作業系統核心知識點
阿新 • • 發佈:2020-07-14
文末領取大圖。
這不是一篇教你如何建立一個作業系統的文章,相反,這是一篇指導性文章,教你從幾個方面來理解作業系統。首先你需要知道你為什麼要看這篇文章以及為什麼要學習作業系統。
## 搞清楚幾個問題
首先你要搞明白你學習作業系統的目的是什麼?作業系統的重要性如何?學習作業系統會給我帶來什麼?下面我會從這幾個方面為你回答下。
作業系統也是一種軟體,但是作業系統是一種非常複雜的軟體。作業系統提供了幾種抽象模型
* 檔案:對 I/O 裝置的抽象
* 虛擬記憶體:對程式儲存器的抽象
* 程序:對一個正在執行程式的抽象
* 虛擬機器:對整個作業系統的抽象
這些抽象和我們的日常開發息息相關。搞清楚了作業系統是如何抽象的,才能培養我們的抽象性思維和開發思路。
很多問題都和作業系統相關,作業系統是解決這些問題的基礎。如果你不學習作業系統,可能會想著從框架層面來解決,那是你瞭解的還不夠深入,當你學習了作業系統後,能夠培養你的全域性性思維。
學習作業系統我們能夠有效的解決`併發`問題,併發幾乎是網際網路的重中之重了,這也從側面說明了學習作業系統的重要性。
學習作業系統的重點不是讓你從頭製造一個作業系統,而是告訴你**作業系統是如何工作的**,能夠讓你對計算機底層有所瞭解,打實你的基礎。
相信你一定清楚什麼是程式設計
**Data structures + Algorithms = Programming**
作業系統內部會涉及到眾多的資料結構和演算法描述,能夠讓你瞭解演算法的基礎上,讓你編寫更優秀的程式。
我認為可以把計算機比作一棟樓
計算機的底層相當於就是樓的根基,計算機應用相當於就是樓的外形,而作業系統就相當於是告訴你大樓的構造原理,編寫高質量的軟體就相當於是告訴你構建一個穩定的房子。
## 認識作業系統
在瞭解作業系統前,你需要先知道一下什麼是計算機系統:現代計算機系統由**一個或多個處理器、主存、印表機、鍵盤、滑鼠、顯示器、網路介面以及各種輸入/輸出裝置構成的系統**。這些都屬於`硬體`的範疇。我們程式設計師不會直接和這些硬體打交道,並且每位程式設計師不可能會掌握所有計算機系統的細節。
所以電腦科學家在硬體的基礎之上,安裝了一層軟體,這層軟體能夠根據使用者輸入的指令達到控制硬體的效果,從而滿足使用者的需求,這樣的軟體稱為 `作業系統`,它的任務就是為使用者程式提供一個更好、更簡單、更清晰的計算機模型。也就是說,作業系統相當於是一箇中間層,為使用者層和硬體提供各自的藉口,遮蔽了不同應用和硬體之間的差異,達到統一標準的作用。
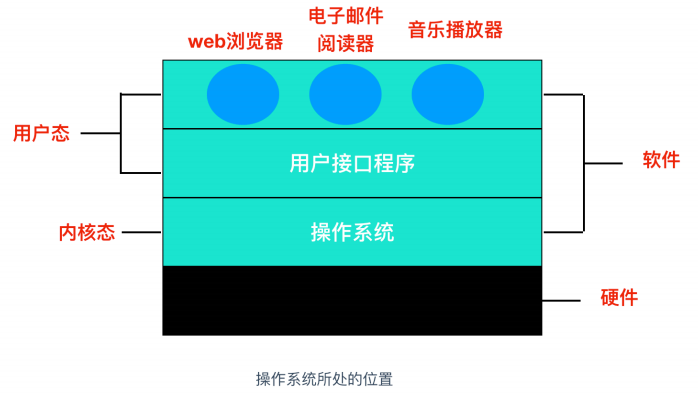
上面一個作業系統的簡化圖,最底層是硬體,硬體包括**晶片、電路板、磁碟、鍵盤、顯示器**等我們上面提到的裝置,在硬體之上是軟體。大部分計算機有兩種執行模式:`核心態` 和 `使用者態`,軟體中最基礎的部分是`作業系統`,它執行在 `核心態` 中。作業系統具有硬體的訪問權,可以執行機器能夠執行的任何指令。軟體的其餘部分執行在 `使用者態` 下。
在大概瞭解到作業系統之後,我們先來認識一下硬體都有哪些
## 計算機硬體
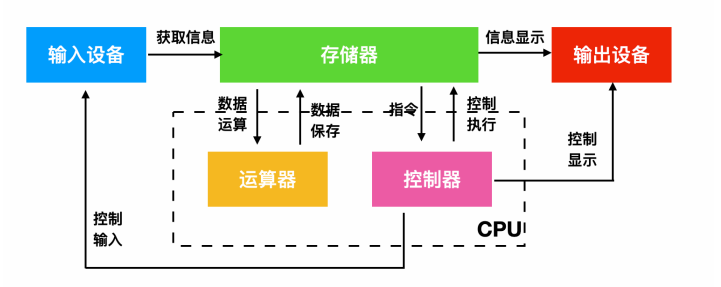
計算機硬體是計算機的重要組成部分,其中包含了 5 個重要的組成部分:**運算器、控制器、儲存器、輸入裝置、輸出裝置**。
* `運算器`:運算器最主要的功能是對資料和資訊進行加工和運算。它是計算機中執行算數和各種邏輯運算的部件。運算器的基本運算包括加、減、乘、除、移位等操作,這些是由 `算術邏輯單元(Arithmetic&logical Unit)` 實現的。而運算器主要由算數邏輯單元和暫存器構成。
* `控制器`:指按照指定順序改變主電路或控制電路的部件,它主要起到了控制命令執行的作用,完成協調和指揮整個計算機系統的操作。控制器是由程式計數器、指令暫存器、解碼譯碼器等構成。
>運算器和控制器共同組成了 CPU
* `儲存器`:儲存器就是計算機的`記憶裝置`,顧名思義,儲存器可以儲存資訊。儲存器分為兩種,一種是主存,也就是記憶體,它是 CPU 主要互動物件,還有一種是外存,比如硬碟軟盤等。下面是現代計算機系統的儲存架構
* `輸入裝置`:輸入裝置是給計算機獲取外部資訊的裝置,它主要包括鍵盤和滑鼠。
* `輸出裝置`:輸出裝置是給使用者呈現根據輸入裝置獲取的資訊經過一系列的計算後得到顯示的裝置,它主要包括顯示器、印表機等。
這五部分也是馮諾伊曼的體系結構,它認為計算機必須具有如下功能:
把需要的程式和資料送至計算機中。必須具有長期記憶程式、資料、中間結果及最終運算結果的能力。能夠完成各種算術、邏輯運算和資料傳送等資料加工處理的能力。能夠根據需要控制程式走向,並能根據指令控制機器的各部件協調操作。能夠按照要求將處理結果輸出給使用者。
下面是一張 intel 家族產品圖,是一個詳細的計算機硬體分類,我們在根據圖中涉及到硬體進行介紹
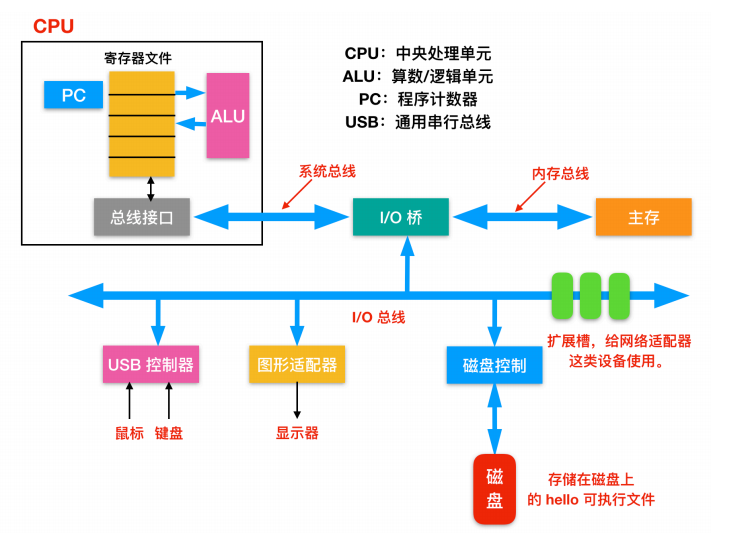
* `匯流排(Buses)`:在整個系統中執行的是稱為匯流排的電氣管道的集合,這些匯流排在元件之間來回傳輸位元組資訊。通常匯流排被設計成傳送定長的位元組塊,也就是 `字(word)`。字中的位元組數(字長)是一個基本的系統引數,各個系統中都不盡相同。現在大部分的字都是 4 個位元組(32 位)或者 8 個位元組(64 位)。
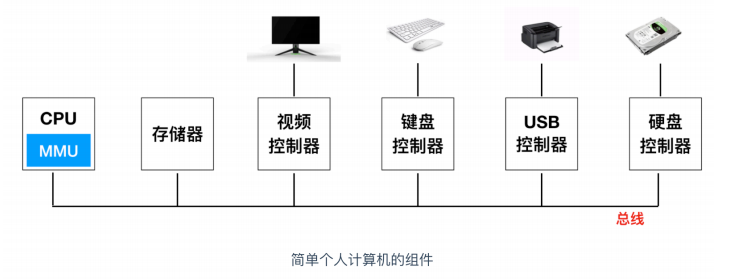
* `I/O 裝置(I/O Devices)`:Input/Output 裝置是系統和外部世界的連線。上圖中有四類 I/O 裝置:用於使用者輸入的鍵盤和滑鼠,用於使用者輸出的顯示器,一個磁碟驅動用來長時間的儲存資料和程式。剛開始的時候,可執行程式就儲存在磁碟上。
每個I/O 裝置連線 I/O 匯流排都被稱為`控制器(controller)` 或者是 `介面卡(Adapter)`。控制器和介面卡之間的主要區別在於封裝方式。控制器是 I/O 裝置本身或者系統的主印製板電路(通常稱作主機板)上的晶片組。而介面卡則是一塊插在主機板插槽上的卡。無論組織形式如何,它們的最終目的都是彼此交換資訊。
* `主存(Main Memory)`,主存是一個`臨時儲存裝置`,而不是永久性儲存,磁碟是 `永久性儲存` 的裝置。主存既儲存程式,又儲存處理器執行流程所處理的資料。從物理組成上說,主存是由一系列 `DRAM(dynamic random access memory)` 動態隨機儲存構成的集合。邏輯上說,記憶體就是一個線性的位元組陣列,有它唯一的地址編號,從 0 開始。一般來說,組成程式的每條機器指令都由不同數量的位元組構成,C 程式變數相對應的資料項的大小根據型別進行變化。比如,在 Linux 的 x86-64 機器上,short 型別的資料需要 2 個位元組,int 和 float 需要 4 個位元組,而 long 和 double 需要 8 個位元組。
* `處理器(Processor)`,`CPU(central processing unit)` 或者簡單的處理器,是解釋(並執行)儲存在主儲存器中的指令的引擎。處理器的核心大小為一個字的儲存裝置(或暫存器),稱為`程式計數器(PC)`。在任何時刻,PC 都指向主存中的某條機器語言指令(即含有該條指令的地址)。
從系統通電開始,直到系統斷電,處理器一直在不斷地執行程式計數器指向的指令,再更新程式計數器,使其指向下一條指令。處理器根據其指令集體系結構定義的指令模型進行操作。在這個模型中,指令按照嚴格的順序執行,執行一條指令涉及執行一系列的步驟。處理器從程式計數器指向的記憶體中讀取指令,解釋指令中的位,執行該指令指示的一些簡單操作,然後更新程式計數器以指向下一條指令。指令與指令之間可能連續,可能不連續(比如 jmp 指令就不會順序讀取)
下面是 CPU 可能執行簡單操作的幾個步驟
* `載入(Load)`:從主存中拷貝一個位元組或者一個字到記憶體中,覆蓋暫存器先前的內容
* `儲存(Store)`:將暫存器中的位元組或字複製到主儲存器中的某個位置,從而覆蓋該位置的先前內容
* `操作(Operate)`:把兩個暫存器的內容複製到 `ALU(Arithmetic logic unit) `。把兩個字進行算術運算,並把結果儲存在暫存器中,重寫暫存器先前的內容。
>算術邏輯單元(ALU)是對數字二進位制數執行算術和按位運算的組合數位電子電路。
* `跳轉(jump)`:從指令中抽取一個字,把這個字複製到`程式計數器(PC)` 中,覆蓋原來的值
## 程序和執行緒
關於程序和執行緒,你需要理解下面這張腦圖中的重點
## 程序
作業系統中最核心的概念就是 `程序`,程序是對正在執行中的程式的一個抽象。作業系統的其他所有內容都是圍繞著程序展開的。
在多道程式處理的系統中,CPU 會在`程序`間快速切換,使每個程式執行幾十或者幾百毫秒。然而,嚴格意義來說,在某一個瞬間,CPU 只能執行一個程序,然而我們如果把時間定位為 1 秒內的話,它可能執行多個程序。這樣就會讓我們產生`並行`的錯覺。因為 CPU 執行速度很快,程序間的換進換出也非常迅速,因此我們很難對多個並行程序進行跟蹤。所以,作業系統的設計者開發了用於描述並行的一種概念模型(順序程序),使得並行更加容易理解和分析。
### 程序模型
一個程序就是一個正在執行的程式的例項,程序也包括程式計數器、暫存器和變數的當前值。從概念上來說,每個程序都有各自的虛擬 CPU,但是實際情況是 CPU 會在各個程序之間進行來回切換。
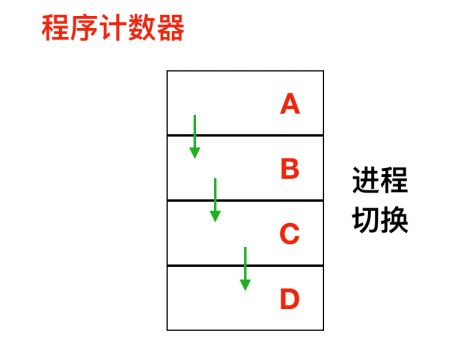
如上圖所示,這是一個具有 4 個程式的多道處理程式,在程序不斷切換的過程中,程式計數器也在不同的變化。
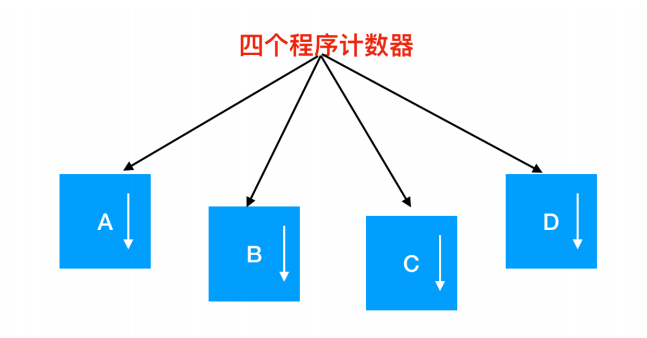
在上圖中,這 4 道程式被抽象為 4 個擁有各自控制流程(即每個自己的程式計數器)的程序,並且每個程式都獨立的執行。當然,實際上只有一個物理程式計數器,每個程式要執行時,其邏輯程式計數器會裝載到物理程式計數器中。當程式執行結束後,其物理程式計數器就會是真正的程式計數器,然後再把它放回程序的邏輯計數器中。
從下圖我們可以看到,在觀察足夠長的一段時間後,所有的程序都運行了,**但在任何一個給定的瞬間僅有一個程序真正執行**。
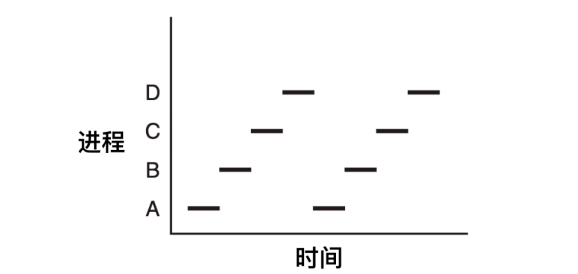
因此,當我們說一個 CPU 只能真正一次執行一個程序的時候,即使有 2 個核(或 CPU),**每一個核也只能一次執行一個執行緒**。
由於 CPU 會在各個程序之間來回快速切換,所以每個程序在 CPU 中的執行時間是無法確定的。並且當同一個程序再次在 CPU 中執行時,其在 CPU 內部的執行時間往往也是不固定的。
這裡的關鍵思想是`認識到一個程序所需的條件`,程序是某一類特定活動的總和,它有程式、輸入輸出以及狀態。
### 程序的建立
作業系統需要一些方式來建立程序。下面是一些建立程序的方式
* 系統初始化(init):啟動作業系統時,通常會建立若干個程序。
* 正在執行的程式執行了建立程序的系統呼叫(比如 fork)
* 使用者請求建立一個新程序:在許多互動式系統中,輸入一個命令或者雙擊圖示就可以啟動程式,以上任意一種操作都可以選擇開啟一個新的程序,在基本的 UNIX 系統中執行 X,新程序將接管啟動它的視窗。
* 初始化一個批處理工作
從技術上講,在所有這些情況下,讓現有流程執行流程是通過建立系統呼叫來建立新流程的。該程序可能是正在執行的使用者程序,是從鍵盤或滑鼠呼叫的系統程序或批處理程式。這些就是系統呼叫建立新程序的過程。該系統呼叫告訴作業系統建立一個新程序,並直接或間接指示在其中執行哪個程式。
在 UNIX 中,僅有一個系統呼叫來建立一個新的程序,這個系統呼叫就是 `fork`。這個呼叫會建立一個與呼叫程序相關的副本。在 fork 後,一個父程序和子程序會有相同的`記憶體映像`,相同的環境字串和相同的開啟檔案。
在 Windows 中,情況正相反,一個簡單的 Win32 功能呼叫 `CreateProcess`,會處理流程建立並將正確的程式載入到新的程序中。這個呼叫會有 10 個引數,包括了需要執行的程式、輸入給程式的命令列引數、各種安全屬性、有關開啟的檔案是否繼承控制位、優先順序資訊、程序所需要建立的視窗規格以及指向一個結構的指標,在該結構中新建立程序的資訊被返回給呼叫者。**在 Windows 中,從一開始父程序的地址空間和子程序的地址空間就是不同的**。
### 程序的終止
程序在建立之後,它就開始執行並做完成任務。然而,沒有什麼事兒是永不停歇的,包括程序也一樣。程序早晚會發生終止,但是通常是由於以下情況觸發的
* `正常退出(自願的)` : 多數程序是由於完成了工作而終止。當編譯器完成了所給定程式的編譯之後,編譯器會執行一個系統呼叫告訴作業系統它完成了工作。這個呼叫在 UNIX 中是 `exit` ,在 Windows 中是 `ExitProcess`。
* `錯誤退出(自願的)`:比如執行一條不存在的命令,於是編譯器就會提醒並退出。
* `嚴重錯誤(非自願的)`
* `被其他程序殺死(非自願的)` : 某個程序執行系統呼叫告訴作業系統殺死某個程序。在 UNIX 中,這個系統呼叫是 kill。在 Win32 中對應的函式是 `TerminateProcess`(注意不是系統呼叫)。
### 程序的層次結構
在一些系統中,當一個程序建立了其他程序後,父程序和子程序就會以某種方式進行關聯。子程序它自己就會建立更多程序,從而形成一個程序層次結構。
#### UNIX 程序體系
在 UNIX 中,程序和它的所有子程序以及子程序的子程序共同組成一個程序組。當用戶從鍵盤中發出一個訊號後,該訊號被髮送給當前與鍵盤相關的程序組中的所有成員(它們通常是在當前視窗建立的所有活動程序)。每個程序可以分別捕獲該訊號、忽略該訊號或採取預設的動作,即被訊號 kill 掉。整個作業系統中所有的程序都隸屬於一個單個以 init 為根的程序樹。

#### Windows 程序體系
相反,Windows 中沒有程序層次的概念,Windows 中所有程序都是平等的,唯一類似於層次結構的是在建立程序的時候,父程序得到一個特別的令牌(稱為控制代碼),該控制代碼可以用來控制子程序。然而,這個令牌可能也會移交給別的作業系統,這樣就不存在層次結構了。而在 UNIX 中,程序不能剝奪其子程序的 `程序權`。(這樣看來,還是 Windows 比較`渣`)。
### 程序狀態
儘管每個程序是一個獨立的實體,有其自己的程式計數器和內部狀態,但是,程序之間仍然需要相互幫助。當一個程序開始執行時,它可能會經歷下面這幾種狀態
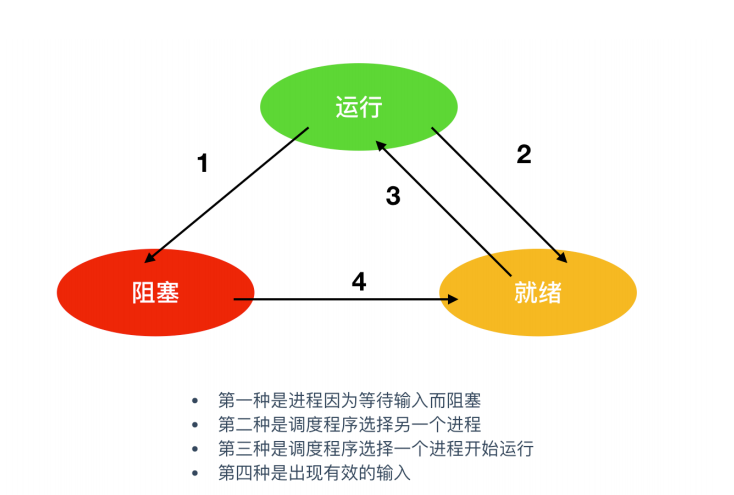
圖中會涉及三種狀態
1. `執行態`,執行態指的就是程序實際佔用 CPU 時間片執行時
2. `就緒態`,就緒態指的是可執行,但因為其他程序正在執行而處於就緒狀態
3. `阻塞態`,除非某種外部事件發生,否則程序不能執行
### 程序的實現
作業系統為了執行程序間的切換,會維護著一張表,這張表就是 `程序表(process table)`。每個程序佔用一個程序表項。該表項包含了程序狀態的重要資訊,包括程式計數器、堆疊指標、記憶體分配狀況、所開啟檔案的狀態、賬號和排程資訊,以及其他在程序由執行態轉換到就緒態或阻塞態時所必須儲存的資訊。
下面展示了一個典型系統中的關鍵欄位

第一列內容與`程序管理`有關,第二列內容與 `儲存管理`有關,第三列內容與`檔案管理`有關。
現在我們應該對程序表有個大致的瞭解了,就可以在對單個 CPU 上如何執行多個順序程序的錯覺做更多的解釋。與每一 I/O 類相關聯的是一個稱作 `中斷向量(interrupt vector)` 的位置(靠近記憶體底部的固定區域)。它包含中斷服務程式的入口地址。假設當一個磁碟中斷髮生時,使用者程序 3 正在執行,則中斷硬體將程式計數器、程式狀態字、有時還有一個或多個暫存器壓入堆疊,計算機隨即跳轉到中斷向量所指示的地址。這就是硬體所做的事情。然後軟體就隨即接管一切剩餘的工作。
當中斷結束後,作業系統會呼叫一個 C 程式來處理中斷剩下的工作。在完成剩下的工作後,會使某些程序就緒,接著呼叫排程程式,決定隨後執行哪個程序。然後將控制權轉移給一段組合語言程式碼,為當前的程序裝入暫存器值以及記憶體對映並啟動該程序執行,下面顯示了中斷處理和排程的過程。
1. 硬體壓入堆疊程式計數器等
2. 硬體從中斷向量裝入新的程式計數器
3. 組合語言過程儲存暫存器的值
4. 組合語言過程設定新的堆疊
5. C 中斷伺服器執行(典型的讀和快取寫入)
6. 排程器決定下面哪個程式先執行
7. C 過程返回至彙編程式碼
8. 組合語言過程開始執行新的當前程序
一個程序在執行過程中可能被中斷數千次,但關鍵每次中斷後,被中斷的程序都返回到與中斷髮生前完全相同的狀態。
## 執行緒
在傳統的作業系統中,每個程序都有一個地址空間和一個控制執行緒。事實上,這是大部分程序的定義。不過,在許多情況下,經常存在同一地址空間中執行多個控制執行緒的情形,這些執行緒就像是分離的程序。下面我們就著重探討一下什麼是執行緒
### 執行緒的使用
或許這個疑問也是你的疑問,為什麼要在程序的基礎上再建立一個執行緒的概念,準確的說,這其實是程序模型和執行緒模型的討論,回答這個問題,可能需要分三步來回答
* 多執行緒之間會共享同一塊地址空間和所有可用資料的能力,這是程序所不具備的
* 執行緒要比程序`更輕量級`,由於執行緒更輕,所以它比程序更容易建立,也更容易撤銷。在許多系統中,建立一個執行緒要比建立一個程序快 10 - 100 倍。
* 第三個原因可能是效能方面的探討,如果多個執行緒都是 CPU 密集型的,那麼並不能獲得性能上的增強,但是如果存在著大量的計算和大量的 I/O 處理,擁有多個執行緒能在這些活動中彼此重疊進行,從而會加快應用程式的執行速度
### 經典的執行緒模型
程序中擁有一個執行的執行緒,通常簡寫為 `執行緒(thread)`。執行緒會有程式計數器,用來記錄接著要執行哪一條指令;執行緒實際上 CPU 上排程執行的實體。
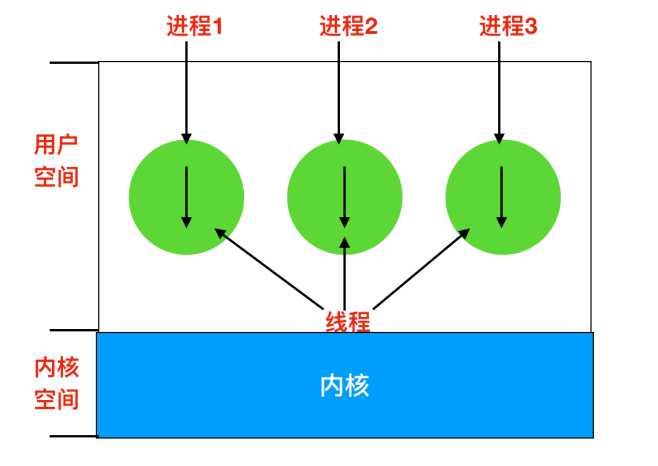
下圖我們可以看到三個傳統的程序,每個程序有自己的地址空間和單個控制執行緒。每個執行緒都在不同的地址空間中執行
下圖中,我們可以看到有一個程序三個執行緒的情況。每個執行緒都在相同的地址空間中執行。
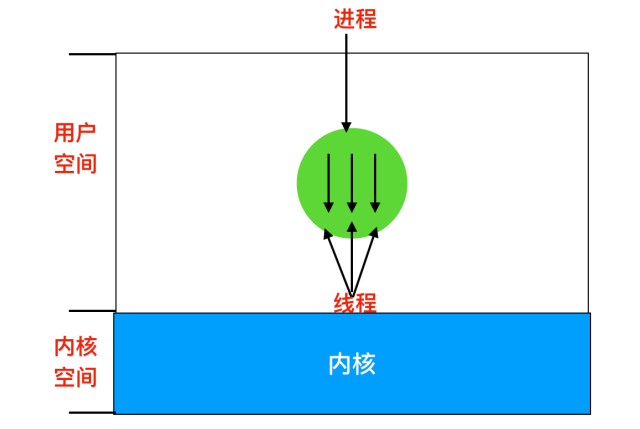
執行緒不像是程序那樣具備較強的獨立性。同一個程序中的所有執行緒都會有完全一樣的地址空間,這意味著它們也共享同樣的全域性變數。由於每個執行緒都可以訪問程序地址空間內每個記憶體地址,**因此一個執行緒可以讀取、寫入甚至擦除另一個執行緒的堆疊**。執行緒之間除了共享同一記憶體空間外,還具有如下不同的內容

上圖左邊的是同一個程序中`每個執行緒共享`的內容,上圖右邊是`每個執行緒`中的內容。也就是說左邊的列表是程序的屬性,右邊的列表是執行緒的屬性。
**執行緒之間的狀態轉換和程序之間的狀態轉換是一樣的**。
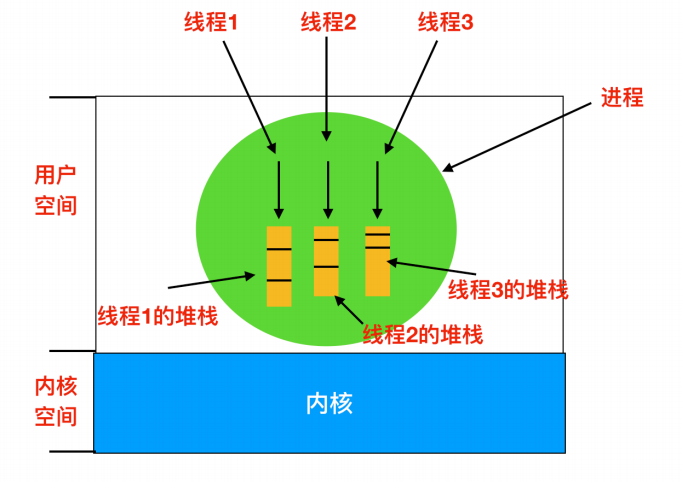
每個執行緒都會有自己的堆疊,如下圖所示
#### 執行緒系統呼叫
程序通常會從當前的某個單執行緒開始,然後這個執行緒通過呼叫一個庫函式(比如 `thread_create `)建立新的執行緒。執行緒建立的函式會要求指定新建立執行緒的名稱。建立的執行緒通常都返回一個執行緒識別符號,該識別符號就是新執行緒的名字。
當一個執行緒完成工作後,可以通過呼叫一個函式(比如 `thread_exit`)來退出。緊接著執行緒消失,狀態變為終止,不能再進行排程。在某些執行緒的執行過程中,可以通過呼叫函式例如 `thread_join` ,表示一個執行緒可以等待另一個執行緒退出。這個過程阻塞呼叫執行緒直到等待特定的執行緒退出。在這種情況下,執行緒的建立和終止非常類似於程序的建立和終止。
另一個常見的執行緒是呼叫 `thread_yield`,它允許執行緒自動放棄 CPU 從而讓另一個執行緒執行。這樣一個呼叫還是很重要的,因為不同於程序,執行緒是無法利用時鐘中斷強制讓執行緒讓出 CPU 的。
### POSIX 執行緒
`POSIX 執行緒 通常稱為 pthreads`是一種獨立於語言而存在的執行模型,以及並行執行模型。

它允許程式控制時間上重疊的多個不同的工作流程。每個工作流程都稱為一個執行緒,可以通過呼叫 POSIX Threads API 來實現對這些流程的建立和控制。可以把它理解為執行緒的標準。
>POSIX Threads 的實現在許多類似且符合POSIX的作業系統上可用,例如 **FreeBSD、NetBSD、OpenBSD、Linux、macOS、Android、Solaris**,它在現有 Windows API 之上實現了**pthread**。
>
>IEEE 是世界上最大的技術專業組織,致力於為人類的利益而發展技術。
| 執行緒呼叫 | 描述 |
| -------------------- | ------------------------------ |
| pthread_create | 建立一個新執行緒 |
| pthread_exit | 結束呼叫的執行緒 |
| pthread_join | 等待一個特定的執行緒退出 |
| pthread_yield | 釋放 CPU 來執行另外一個執行緒 |
| pthread_attr_init | 建立並初始化一個執行緒的屬性結構 |
| pthread_attr_destory | 刪除一個執行緒的屬性結構 |
所有的 Pthreads 都有特定的屬性,每一個都含有識別符號、一組暫存器(包括程式計數器)和一組儲存在結構中的屬性。這個屬性包括堆疊大小、排程引數以及其他執行緒需要的專案。
### 執行緒實現
主要有三種實現方式
* 在使用者空間中實現執行緒;
* 在核心空間中實現執行緒;
* 在使用者和核心空間中混合實現執行緒。
下面我們分開討論一下
#### 在使用者空間中實現執行緒
第一種方法是把整個執行緒包放在使用者空間中,核心對執行緒一無所知,它不知道執行緒的存在。所有的這類實現都有同樣的通用結構
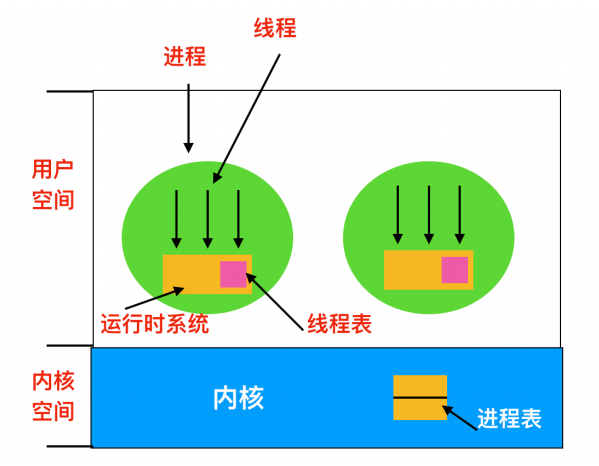
執行緒在執行時系統之上執行,執行時系統是管理執行緒過程的集合,包括前面提到的四個過程: pthread_create, pthread_exit, pthread_join 和 pthread_yield。
### 在核心中實現執行緒
當某個執行緒希望建立一個新執行緒或撤銷一個已有執行緒時,它會進行一個系統呼叫,這個系統呼叫通過對執行緒表的更新來完成執行緒建立或銷燬工作。
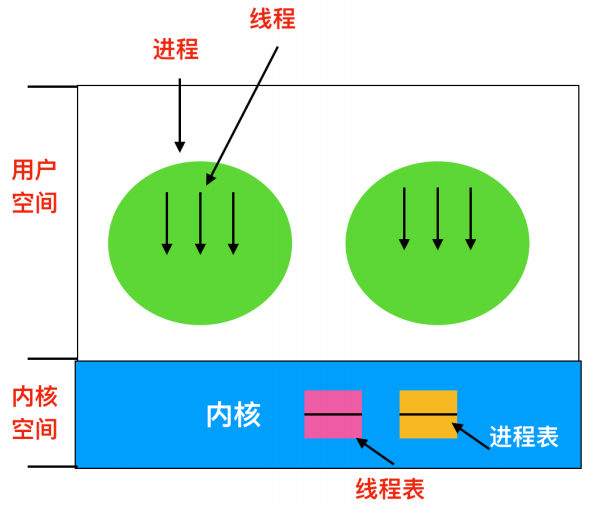
核心中的執行緒表持有每個執行緒的暫存器、狀態和其他資訊。這些資訊和使用者空間中的執行緒資訊相同,但是位置卻被放在了核心中而不是使用者空間中。另外,核心還維護了一張程序表用來跟蹤系統狀態。
所有能夠阻塞的呼叫都會通過系統呼叫的方式來實現,當一個執行緒阻塞時,核心可以進行選擇,是執行在同一個程序中的另一個執行緒(如果有就緒執行緒的話)還是執行一個另一個程序中的執行緒。但是在使用者實現中,執行時系統始終執行自己的執行緒,直到核心剝奪它的 CPU 時間片(或者沒有可執行的執行緒存在了)為止。
### 混合實現
結合使用者空間和核心空間的優點,設計人員採用了一種`核心級執行緒`的方式,然後將使用者級執行緒與某些或者全部核心執行緒多路複用起來
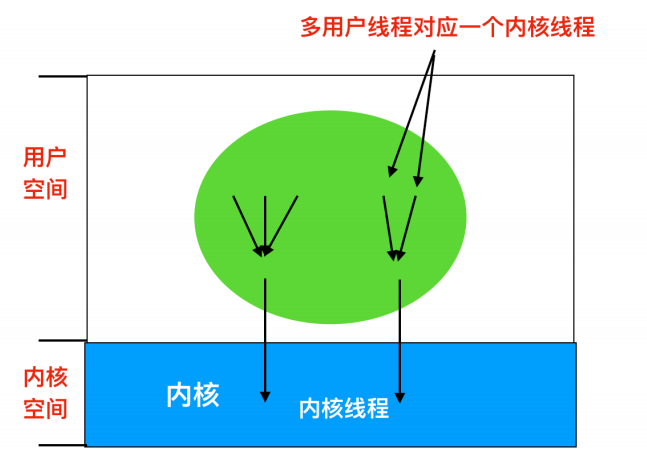
在這種模型中,程式設計人員可以自由控制使用者執行緒和核心執行緒的數量,具有很大的靈活度。採用這種方法,核心只識別核心級執行緒,並對其進行排程。其中一些核心級執行緒會被多個使用者級執行緒多路複用。
## 程序間通訊
程序是需要頻繁的和其他程序進行交流的。下面我們會一起討論有關 `程序間通訊(Inter Process Communication, IPC)` 的問題。大致來說,程序間的通訊機制可以分為 6 種
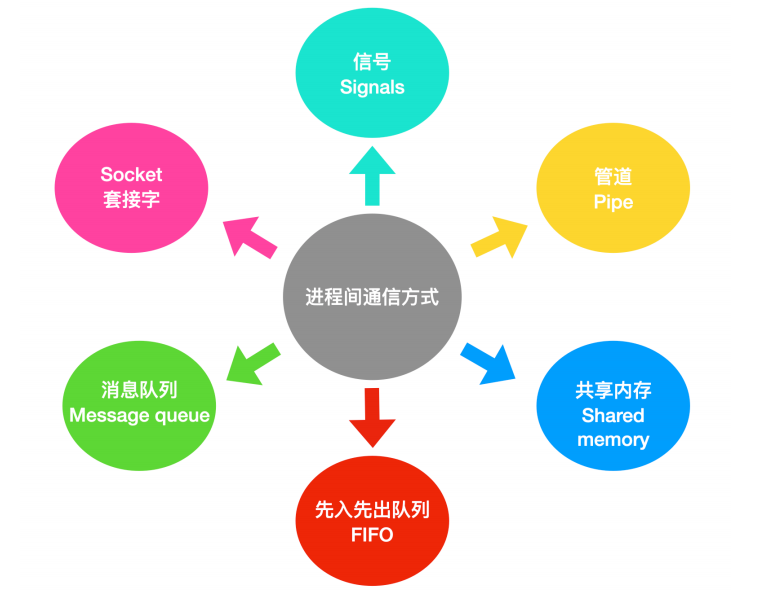
下面我們分別對其進行概述
### 訊號 signal
訊號是 UNIX 系統最先開始使用的程序間通訊機制,因為 Linux 是繼承於 UNIX 的,所以 Linux 也支援訊號機制,通過向一個或多個程序傳送`非同步事件訊號`來實現,訊號可以從鍵盤或者訪問不存在的位置等地方產生;訊號通過 shell 將任務傳送給子程序。
你可以在 Linux 系統上輸入 `kill -l` 來列出系統使用的訊號,下面是我提供的一些訊號

程序可以選擇忽略傳送過來的訊號,但是有兩個是不能忽略的:`SIGSTOP` 和 `SIGKILL` 訊號。SIGSTOP 訊號會通知當前正在執行的程序執行關閉操作,SIGKILL 訊號會通知當前程序應該被殺死。除此之外,程序可以選擇它想要處理的訊號,程序也可以選擇阻止訊號,如果不阻止,可以選擇自行處理,也可以選擇進行核心處理。如果選擇交給核心進行處理,那麼就執行預設處理。
作業系統會中斷目標程式的程序來向其傳送訊號、在任何非原子指令中,執行都可以中斷,如果程序已經註冊了新號處理程式,那麼就執行程序,如果沒有註冊,將採用預設處理的方式。
### 管道 pipe
Linux 系統中的程序可以通過建立管道 pipe 進行通訊
在兩個程序之間,可以建立一個通道,一個程序向這個通道里寫入位元組流,另一個程序從這個管道中讀取位元組流。管道是同步的,當程序嘗試從空管道讀取資料時,該程序會被阻塞,直到有可用資料為止。shell 中的`管線 pipelines` 就是用管道實現的,當 shell 發現輸出
```shell
sort