
Kubernetes實戰指南(三十一):零宕機無縫遷移Spring Cloud至k8s
阿新 • • 發佈:2020-07-14
[toc]
# 1. 專案遷移背景
## 1.1 為什麼要在“太歲”上動土?
目前公司的測試環境、UAT環境、生產環境均已經使用k8s進行維護管理,大部分專案均已完成容器化,並且已經在線上平穩執行許久。在我們將大大小小的專案完成容器化以後,測試、UAT、生產環境的發版工具以及CICD流程慢慢的實現統一化管理,並且基於k8s開發了內部的發版稽核平臺,同時接入了Jira等專案管理工具。
在自研平臺進行發版時,能夠自動關聯專案的開發進度以及Release版本,最重要的是其可以控制發版許可權、統一發版工具及發版模式,並且支援一鍵式發版多個專案的多個模組,同時也包括了發版失敗應用的統一回滾及單個應用的回滾。
因為該專案從始至今一直在使用GitRunner進行發版,並且基於虛機部署,所以一直沒有整合到發版稽核平臺,但是由於專案比較重要,並且涉及的服務和機器較多,所以必須要把這個專案進行容器化並且統一發版工具才能更好的適應公司的環境,以及更好的應對下一代雲端計算的發展。
## 1.2 為什麼要棄用Git Runner?
首先我們看一下Git Runner發版的頁面,雖然看起來很簡潔清爽,但是也難免不了會遇到一些問題。
### 1.2.1 多分支並行開發問題
當多分支並行開發或者能夠發版到生產環境的分支較多時,很容易在手動部署的階段點錯,或者看序列,當然這種概率很小。
但是我們可以看到另外一個問題,每次提交或者合併,都會觸發構建,當我們使用Git Flow分支流時,可能同時有很多分支都在並行開發、並行測試、並行構建,如果Git Runner是基於虛機建立的,很有可能會出現構建排隊的情況,當然這個排隊的問題,也是能解決的。
### 1.2.2 多微服務配置維護問題
其次,如果一個專案稍微大一些,維護起來也不是很方便。比如這個準備要遷移的專案,一個前端和二十多個業務應用,在加上Zuul、ConfigServer、Eureka將近三十個服務,每個服務對應一個Git倉庫,然後每個服務同時在開發的分支又有很多,如果想要升級GitLab CI指令碼或者微服務的機器想要新增節點,這將是一個枯燥乏味的工作。
### 1.2.3 安全問題
最後,還有一個安全的問題,GitLab的CI指令碼一般都是內建在程式碼倉庫裡面的,這就意味著任何有Push或者Merge許可權的人都可以隨意的修改CI指令碼,這會導致意想不到的結果,同時也會威脅到伺服器和業務安全,
針對發版而言,可能任何的開發者都可以點擊發版按鈕,這些可能一直都是一個安全隱患。
但是這些並不意味著Git Runner是一個不被推薦的工具,新版的GitLab內建的Auto DevOps和整合Kubernetes依舊很香。但是可能對於我們而言,使用Git Runner進行發版的專案並不多,所以我們想要統一發版工具、統一管理CI指令碼,所以可能其它的CI工具更為合適。
## 1.3 為什麼要容器化?
### 1.3.1 埠衝突問題
容器化之前這個專案採用虛機部署的,每個虛擬機器交叉的啟動了兩個或者三個微服務,這會遇到一個問題,就是埠衝突的問題,在專案加入新應用時,需要考慮伺服器之間埠衝突問題的,還要考慮每個微服務的埠不能一樣,因為使用虛擬機器部署應用時,可能會有機器節點故障需要手動遷移應用的情況,如果部分微服務埠一樣,遷移的過程可能會受阻。
另外,當一個專案只有幾個應用時,埠維護起來可能沒有什麼問題,像本專案,涉及三十多個微服務,這就會成為一件很痛苦的事情。而使用容器部署時,每個容器相互隔離,所有應用可以採用同樣的埠,就無需再去關心埠的問題。
### 1.3.2 程式健康問題
使用過Java程式的人大部分都遇到過程式假死的情況,比如埠明明是通的,但是請求就是不處理,這就是一種程式假死的現象。而我們在使用虛機部署時,往往不能把健康檢查做的很好,或許在虛機上面並沒有做介面級的健康檢查,這就會造成程式假死無法自動處理的問題,並且在虛機上面做一些介面級的健康檢查及處理操作並不是一件簡單的事情,同樣也是一件枯燥乏味的事情,尤其是當一個專案微服務過多,健康檢查介面不一致時更為痛苦。
但在k8s上面,自帶的Read和Live探針用以處理上面的問題就極其簡單,如圖所示,我們可以看到目前支援三種方式的健康檢查:

- **tcpSocket**: 埠健康檢查
- **exec**: 根據指定命令的返回值
- **httpGet**: 介面級健康檢查
同時這些健康檢查的靈活性也很高,可以自定義檢查間隔、錯誤次數、成功次數、檢查Host等引數,而且上面提到的介面級健康檢查httpGet也支援自定義主機名、請求頭、檢查路徑以及HTTP或者HTTPS等配置,可以看到用k8s自帶的健康檢查可以省去我們很大一部分工作,不用再去維護非常多令人討厭的指令碼。
### 1.3.3 故障恢復問題
在使用虛機部署應用時,有時可能會碰到宿主機故障,單節點的應用無法使用,或者多節點部署的應用由於其他副本不可用,導致自身壓力大出現服務延遲的情況。而恰恰宿主機無法很快恢復,這時可能就需要手動新增節點或者需要新加伺服器才能解決這類問題,這個過程可能會很漫長,或許也很痛苦。因為需要去準備依賴環境,然後才能去部署自己的應用,並且有時候你可能還需要更改CI指令碼。。。
而使用k8s編排時,我們無需關心這類問題,一切的故障恢復、容災機制都由強大的k8s負責,你可以去喝杯咖啡,或者你剛開啟電腦去處理這個問題時,一切都已經恢復如初。
### 1.3.4 其他小問題
當然k8s給我們帶來的便利性和解決的問題遠不止上面所說的,容器映象幫我們解決了依賴環境的問題,服務編排幫我們解決了故障容災的問題,我們可以使用k8s的包管理工具一鍵建立一套新的環境,我們可以使用k8s的服務發現讓開發人員無需再關注網路部分的開發,我們可以使用k8s的許可權控制讓運維人員無需再去管理每臺伺服器的許可權,我們可以使用k8s強大的應用程式釋出策略讓我們無需過多的考慮如何實現零宕機發布應用及應用回滾,等等,這一切的便利性正在悄悄的改變著我們的行為。
## 2. 遷移計劃
### 2.1 藍綠遷移
首先來看一下遷移之前的架構
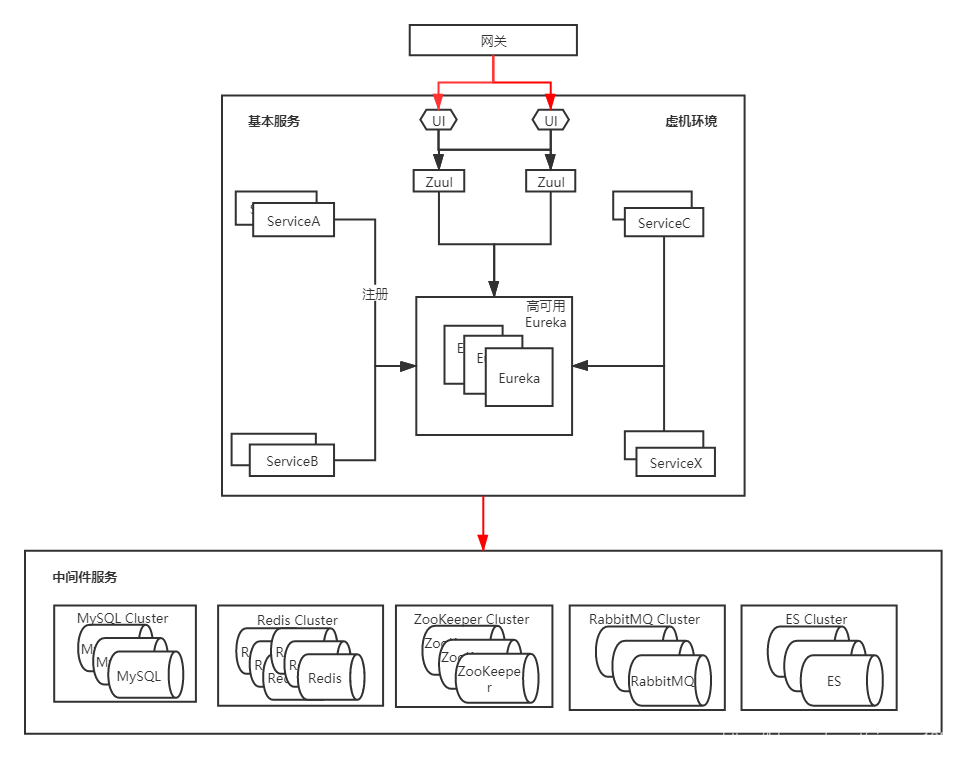
和大多數SpringCloud架構一樣,使用NodeJS作為前端,Eureka用作服務發現,Zuul進行路由分發,ConfigServer作為配置中心。這種架構也是SpringCloud在企業中最普遍的架構,沒有使用更多額外的元件,所以我們在第一次遷移時,也沒有考慮太多,還是按照遷移其他專案時用的方案,即在k8s上新建一套環境(本次遷移沒有涉及到中介軟體),也就是容器化環境,配置一個同樣的域名,然後新增hosts解析進行測試,沒有問題的話直接進行域名切換即可完成遷移。這種方式是最簡單也是最常用的方式,類似於程式發版的藍綠部署,此時在k8s新建一套環境對應的架構圖如下:
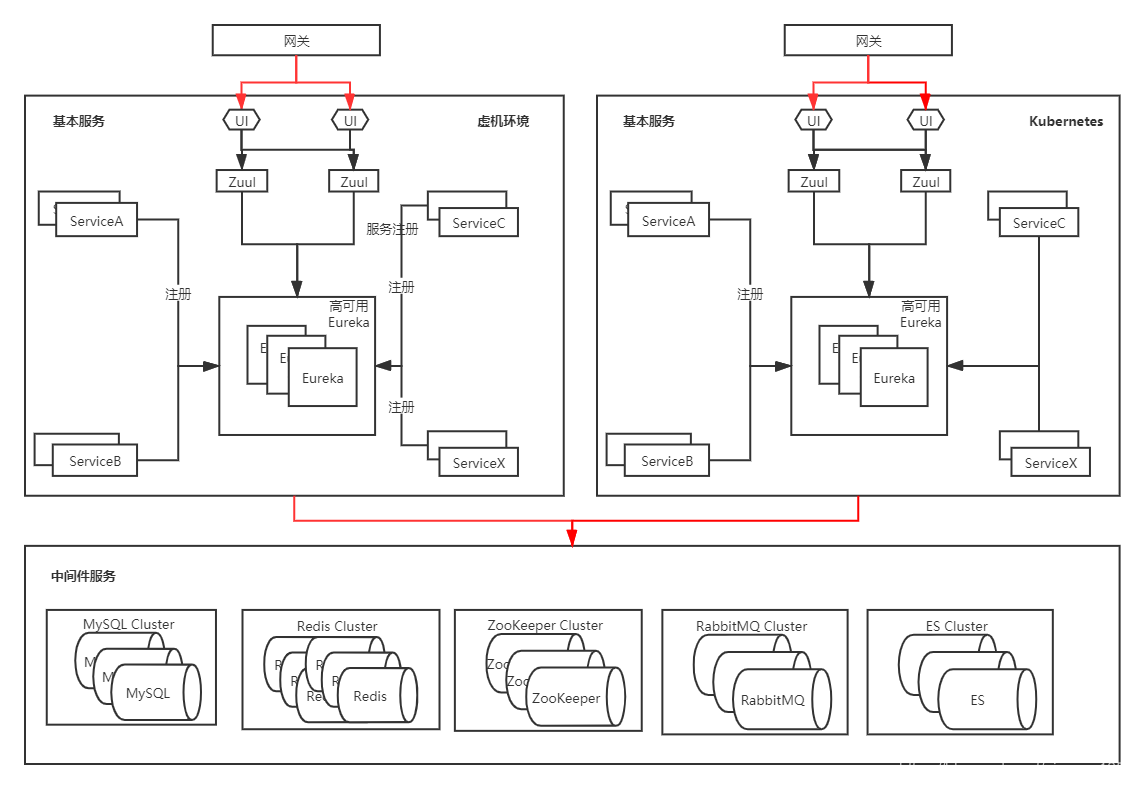
在進行測試時,此專案同時並行了兩套環境,一套虛機環境,一套容器環境,容器環境只接收測試人員的流量,兩套環境連線的是同一套中介軟體服務,因為其他專案大部分也是按照這種方式遷移的,並且該專案在測試環境也進行過同樣的流程,沒有出現什麼問題,所以也同樣認為這種方式在本專案也不會出現什麼問題。但往往現實總會與預期有所差異,在測試過程中由於兩套環境並存,導致了部分生產資料出現問題,由於容器環境沒有經過完整性測試,也沒有強制切換域名,後來緊急關停了所有的容器問題才得以恢復。由於時間比較緊迫,我們並沒有仔細排查問題所在,只是修復了部分資料,後來我們認為可能是遷移過程中部分微服務master分支和生產程式碼不一致造成的,當然也可能並不是這麼簡單。為了規避這類問題再次發生只能去修改遷移方案。
### 2.2 灰度遷移
由於上面的遷移方案出了點問題,就重新定了一個方案,較上次略微麻煩,採用逐個微服務遷移至k8s,類似於應用程式發版的灰度釋出。
單個應用遷移時,需要確保容器環境和虛機環境的程式碼一致,在遷移時微服務採用域名註冊的方式。也就是每個微服務都配置一個內部域名,通過域名去註冊到Eureka,而不是採用容器的IP和埠去註冊(因為k8s內部的IP和虛擬機器未打通),此時的環境如下圖所示:
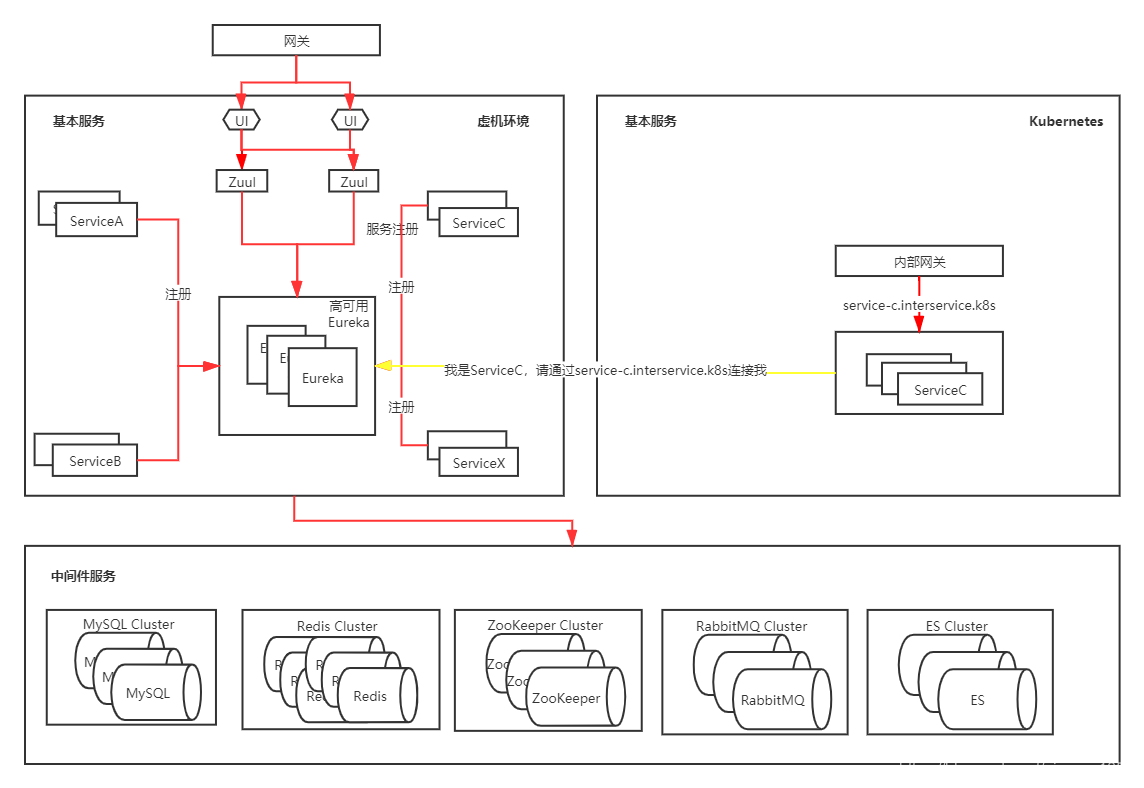
此時有一個域名service-c.interservice.k8s指向ServiceC,然後ServiceC註冊到Eureka時修改自己的地址為該域名(預設是宿主機IP+埠),之後別的應用通過該地址呼叫ServiceC,當ServiceC測試無問題後,下線虛擬機器裡面的ServiceC,最後的架構如圖所示:
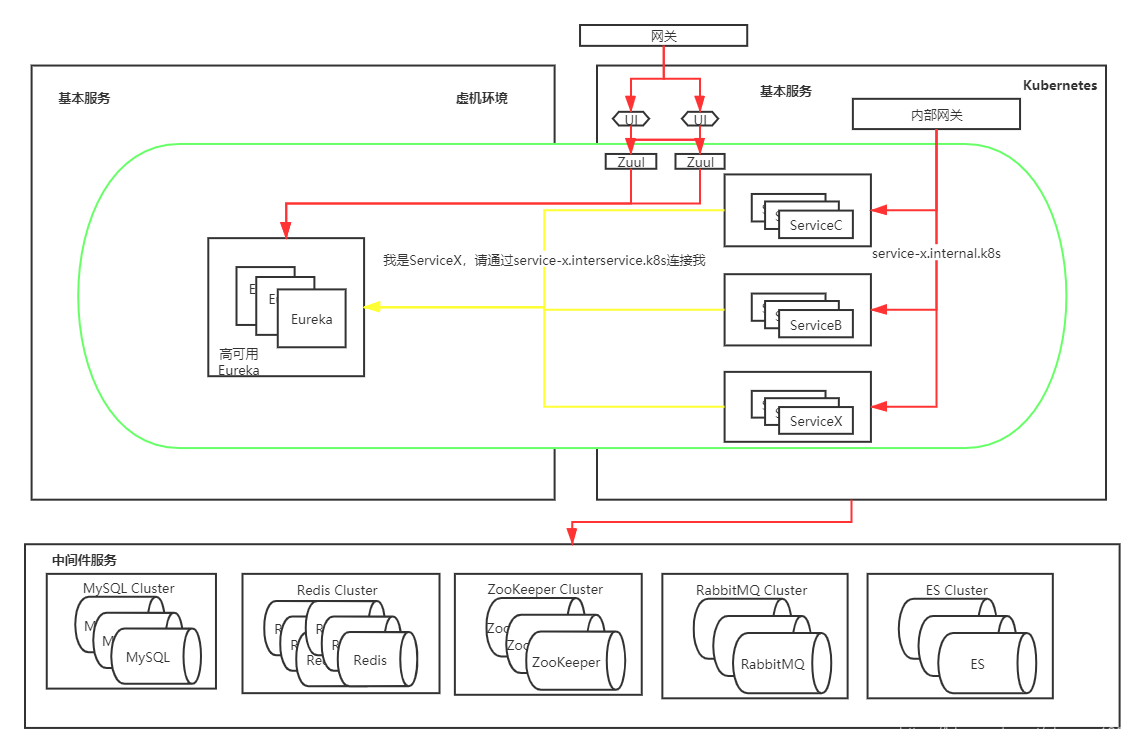
除了Zuul、前端UI和Eureka,其他服務都使用灰度的方式遷移到k8s,比藍綠的形式更為複雜,需要為每個微服務單獨建立Service、域名,在遷移完成之後還需要刪除。到這一步後,除了Eureka其他服務都已經部署在k8s上,而對於Eureka的遷移,涉及的細節更多。
### 2.3 Eureka遷移
到這一步後,服務訪問沒有出現其他問題,除了Eureka之外的服務,都已經部署在k8s,而Eureka的過度型遷移設計的問題可能會更多。因為我們不能直接在k8s上部署一套高可用的Eureka叢集,然後直接把ConfigServer裡面的微服務註冊地址改成k8s中的Eureka地址,因為此時兩個Eureka叢集都是獨立的Zone,註冊資訊並不會共享,這種會在更改配置的過程中丟失註冊資訊,此時架構圖可能會出現如下情況:
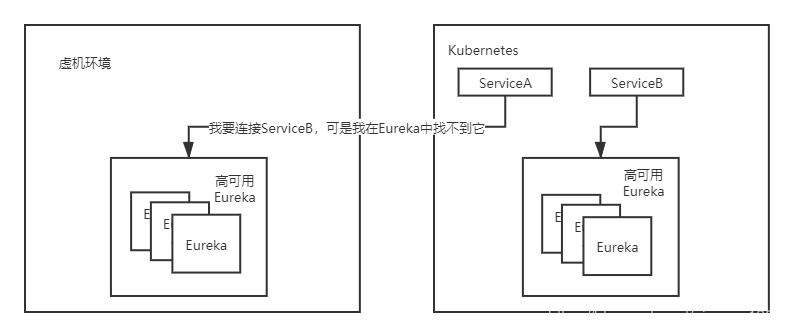
也就是在替換配置的過程中,可能會有ServiceA註冊到了之前的Eureka上,ServiceB註冊到了k8s中的Eureka,就會導致ServiceA找不到ServiceB,反過來也是同樣的問題。
所以在k8s搭建Eureka的集群后,需要給每個Eureka例項配置一個臨時域名,然後更改之前的Eureka叢集和k8s裡面的Eureka叢集的zone配置,讓k8s裡面的Eureka和虛機裡面的Eureka組成一個新的叢集,這樣註冊資訊就會被同步,無論註冊到Eureka都不會造成服務找不到,此時的架構圖如下(此時所有的服務還是註冊到原來的Eureka叢集中):
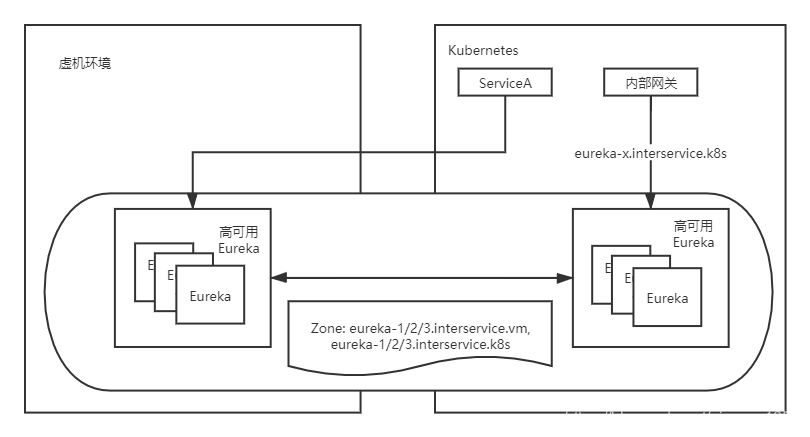
接下來需要做的事情,就是更改微服務的配置,此時需要更改地方有三處:
1. 微服務註冊到Eureka的地址更為容器IP和埠,不再使用域名註冊,因為此時微服務都已經在k8s中,直接通過內部Pod IP即可連線;
2. 更改服務註冊的Eureka地址為k8s Eureka的service地址,Eureka使用StatefulSet部署,直接通過eureka-0/1/2.eureka-headless-svc就可以連線;
3. 待所有的微服務都已經遷移完畢後,更改k8s的Eureka叢集的zone為:eureka-0/1/2.eureka-headless-svc,並刪除其他微服務的Service和域名。
最終的架構圖如圖:
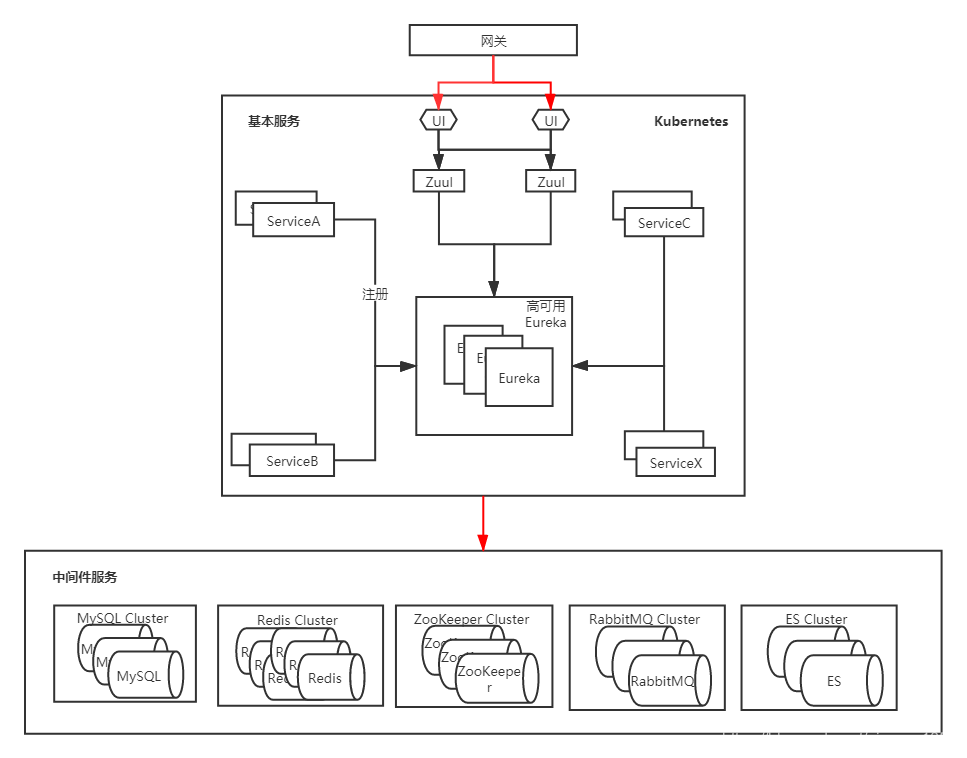
# 3. 總結
為了保證服務的可用性,我們無奈的採用灰度的方式進行遷移,比藍綠的方式麻煩了很多,而且需要考慮的問題也有很多。在程式沒有任何問題的前提下,還是建議採用藍綠的方式進行遷移,不僅遇到的問題少,遷移也比較方便快捷。當然採用灰度的方式對於大型的專案或者不能中斷服務的專案可能更為穩妥,因為一次性全部切換可能會有遺漏的需要測試的地方。當然無論哪種方式,對應用的容器化、遷移至Kubernetes才是比較重要的事情,畢竟雲端計算才是未來,而Kubernetes是雲端計算的