
《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》論文總結
阿新 • • 發佈:2020-07-17
# Aurora總結
**說明**:本文為論文 **《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》** 的個人理解,難免有理解不到位之處,歡迎交流與指正 。
**論文地址**:[Aurora Paper](https://github.com/XutongLi/Learning-Notes/blob/master/Distributed_System/Paper_Reading/Aurora/aurora.pdf)
> 本文首先基於 **MIT6.824** 課程內容介紹 **AWS** 雲資料庫的演進過程,接著基於論文內容介紹 **Aurora**。
***
## 0. 簡介
**Aurora** 是一種由 *AWS* 於 *2017* 年提出的關係型資料庫架構,它為 **OLTP** 業務提供關係型資料庫服務。它將計算與儲存分離、基於 `Quorum` 模型保證底層儲存的一致性、將 *redo* 日誌相關的功能下推到儲存層、並通過讀寫分離降低資料庫層的負載。
***
## 1. 資料庫執行過程
首先來描述一下單機通用事務型資料庫的寫操作執行過程,資料儲存在硬碟的 *B-Tree* 中,資料庫中有快取的資料頁。
以事務 `x=x+10` `y=y-10` 為例:
- 首先鎖定 `x` 和 `y`
- 在 **WAL (Write-Ahead Log)** 中新增更新條目
- 此時 *log entry* 可以表示為:
| LSID | TID | Key | old | new | 註釋 |
| ---- | ---- | ------ | ---- | ---- | -------------------- |
| 101 | 7 | x | 500 | 510 | x=x+10 |
| 102 | 7 | y | 750 | 740 | y=y-10 |
| 103 | 7 | commit | | | transaction finished |
- 在 *WAL* 寫入到硬碟後釋放 `x` 和`y` 的鎖定,回覆 *client*
- *Log Applicator* 在快取資料頁的前映象上作用 *log entry* 上的修改,會產生後鏡像
- 之後將修改後的快取資料頁寫入到硬碟中(延遲寫入可以優化效能,因為資料頁很大)
故障恢復時:
- 對於 *log* 中所有已提交的事務重放( **redo** )
- 對於 *log* 中所有未提交的事務回滾( **undo** )
***
## 2. AWS 資料庫演進過程
### 2.1 Amazon EC2
每臺伺服器上開啟多個虛擬機器,每個虛擬機器為一個 **EC2例項** ,可以作為 *web* 伺服器或者資料庫伺服器,資料儲存在直接連線的物理磁碟上。
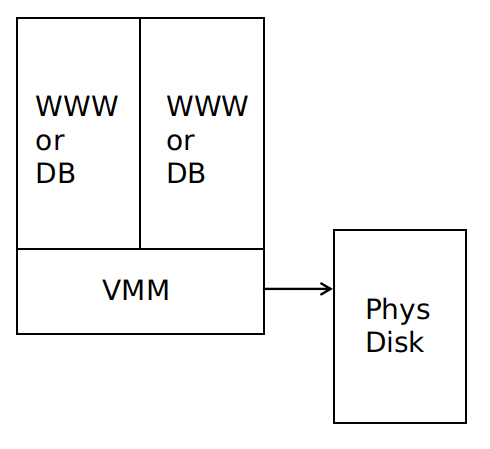
可通過 **EC2** 構建服務,如下圖所示:
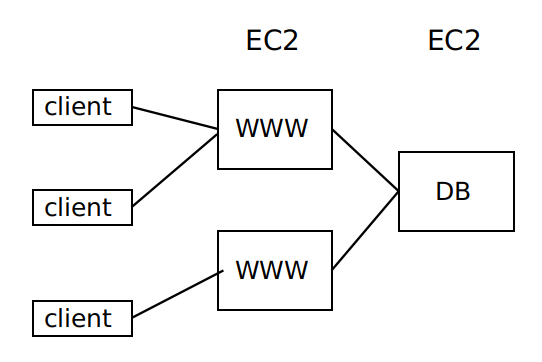
**EC2** 適用於 *web* 伺服器,因為伺服器負載增加時可以通過租借更多的 *EC2* 來承擔更大的負載,並且一旦發生伺服器崩潰,由於 *web* 伺服器是無狀態的,不會有什麼負面影響。但是 **EC2** 不適用於資料庫伺服器,因為它只能提供只讀的副本,沒有很好的伸縮性,且一旦發生伺服器崩潰,資料庫中的資料可能會永久丟失。
### 2.2 Amazon EBS
**EBS** 是彈性塊儲存,相當於是 *EC2* 的儲存硬碟,實際實現為帶有硬碟驅動的一組伺服器,以鏈式複製的形式組織,使用基於 *Paxos* 的配置管理。
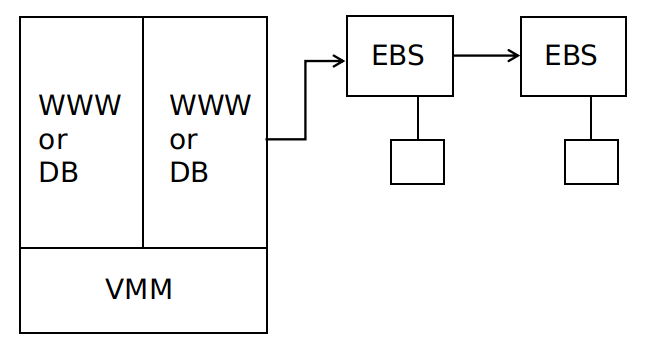
每個副本都儲存在一個可用區當中,對於每次寫操作,必須等到所有副本寫入,才可以響應客戶端。
**EBS** 的容錯性高於本地硬碟儲存,一旦一個 **EC2** 例項故障,重啟另一個例項、並連線到同一個 **EBS** 即可。
**EBS** 的缺點:
- 儲存共享,在一個時間點上,一個給定的 **EBS** 只能被一個 **EC2** 例項使用
- 很多資料需要通過網路傳輸,即使僅有很少一部分資料被修改,整個資料塊都要被傳輸
- 兩個副本容錯性還是不夠,但是更多的副本會影響效能
- 所有的副本都在一個可用區中,一旦可用區發生火災、網路故障、電力故障等,所有的副本將不能被訪問
### 2.3 Amazon Multi-AZ RDS

**Amazon Multi-AZ RDS** 採用 **mirrored MySQL**,將資料庫作為服務,而不是讓使用者在 **EC2** 上建立自己的資料庫。
每次寫操作都寫到本地 *EBS* 和映象 *EBS* ,並傳送給備份例項的 *EBS* 和其映象 *EBS* ,傳送內容包括 *log* 和 *data page* 以及一些別的資料,寫操作要等到四個 *EBS* 副本都寫入後才返回響應。
**Amazon Multi-AZ RDS** 實現了跨可用區的容災,缺點是傳送資料量太大,且步驟1、3、5是順序且同步的,延時會因為同步而累積(寫放大問題)。
***
## 3. Aurora
### 3.1 一些術語
**可用區 (Availability Zone, AZ)**:一個可用區是一個地域的子集,與其他可用區通過低時延的鏈路連線。可用區之間對很多故障是隔離的,將資料副本存放在不同可用區中,可以保證通常的故障模式只會影響到一個副本。
**資料段 (data segment)**:將資料庫的總容量劃分為固定大小的資料段,每個資料段大小為 *10G* 。資料段是系統中最小的故障和恢復單元。
> 為何採用資料段?
>
> 必須保證在修復一個故障所需的時間內,不相關故障成對出現的概率足夠低。因為不相關故障成對出現的情況難以控制,因此通過降低平均修復時間來降低成對故障的影響,於是將資料分段。
**保護群 (Protect Group, PG)**:每個資料段有6個副本,組成一個 *PG* ,分佈在3個 *AZ* 中,每個 *AZ* 2個。
**儲存卷 (storage volume)**:儲存卷是一組串聯的 *PG*,物理上使用大量的儲存節點實現,這些節點通過 *EC2* 配置為帶有附加 *ssd* 的虛擬主機。通過分配更多的 *PG* ,可以線性的擴充套件資料卷的容量。
### 3.2 quorum機制
**Aurora** 使用基於 **quorum** 的投票機制來為儲存伺服器容錯。
如果 *V* 個副本每個都有一個投票權,那麼一個讀操作必須獲得 *R* 票,一個寫操作必須獲得 *W* 票。為讀到最新的資料,必須滿足 $W+R>V$ (使讀多數派和寫多數派至少包含一個相同節點);為讓每次寫操作都知到最近寫入的資料,必須滿足 $W>V/2$ 。
**Aurora** 被設計為能容忍:*a)* 掛掉一整個 *AZ* 以及一個額外的節點而不影響讀取資料(AZ+1);*b)* 掛掉一整個 *AZ* 而不影響寫入資料。具體設計為:
- 將資料複製為6個副本,存放在3個 *AZ* 中,每個 *AZ* 2個
- $V=6$ 、$W=4$ 、$R=3$
**如何確定哪個讀取副本擁有最新的資料?**
寫操作每次給資料一個單調遞增的版本號,儲存伺服器記錄資料的版本號,讀操作會取所有副本中版本號最大的。
**基於quorum機制的儲存伺服器的優點**:
- 對於伺服器故障、執行慢或網路分割槽的問題處理更平滑,因為每次操作不需要得到所有副本伺服器的迴應(如如相對於鏈式複製,鏈式複製需要等待寫操作在所有副本上完成)
- 在滿足 $W+R>V$ 的前提下,可以調整 *W* 和 *R* 在針對不同的讀寫負載情況,若讀負載比較大,可以減小 *R*,反之亦然
> **Raft** 也使用了 *quorum* 機制:*leader* 在多數副本寫入 *log entry* 後才會將該 *log entry* 提交
>
> 但是 **Raft** 更加強大:可以處理更復雜的操作(由於它的順序操作);出現 *split-brain* 問題時可以自動重新選舉出 *leader*
### 3.3 REDO日誌處理下推到儲存層
**Aurora** 中,**Log Applicator** 被下推到了儲存層,用來在後臺或按需產生資料頁,通過網路傳輸的寫資料只有 **REDO** 日誌,因此減少了網路負載、並提供了可觀的效能和永續性。
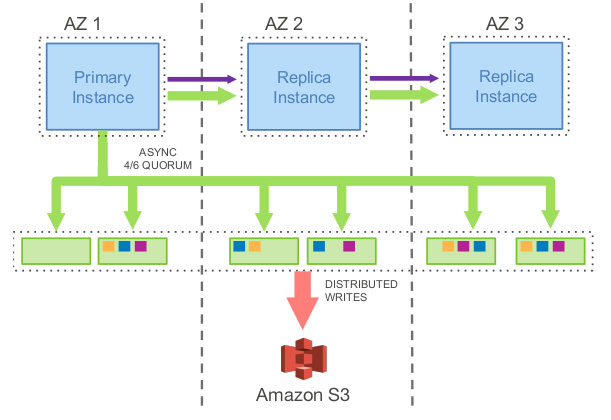
上圖展示了一個 **Aurora** 叢集,包括一個主例項和多個副本例項,部署在不同的可用區中,該模型工作流程為:
- 主例項將 **REDO** 日誌寫入儲存層。*I/O* 流根據目的地來將日誌順序打成 *batch* ,並將每個 *batch* 傳給資料的6個副本並持久化到資料盤上
- 主例項將日誌以及元資料的更新一起傳送給副本例項
- 資料庫引擎只要收到6箇中的4個回覆就形成了一個寫多數派,此時可認為這些日誌檔案被持久化了
- 每個資料副本使用這些 **REDO** 日誌將資料頁的變更應用在他們的 *buffer cache* 中
- 對磁碟上資料庫資料的寫入(B-Trees等)可以在以後完成,通常是希望能夠將多個事務對資料庫同一部分的寫入合併為一個磁碟寫入。
基於此模型,實驗表明,**Aurora** 可以負載比 *MySQL* 映象多35倍的事務。
對於 **故障恢復** ,在傳統的資料庫中,系統必須從最近的一個檢查點開始恢復,重放日誌確保所有的 *REDO* 日誌都被應用。在 **Aurora** 中,可持久化 *REDO* 日誌不斷地、非同步地應用在儲存層,分佈在各個資料節點上。如果資料頁還沒生成,一個讀請求可能會應用一些 *REDO* 日誌來生成資料頁。這樣,故障恢復被分散在所有的正常的前臺操作中,在資料庫啟動的時候不需要做任何事情。
下圖為儲存節點的處理流程:
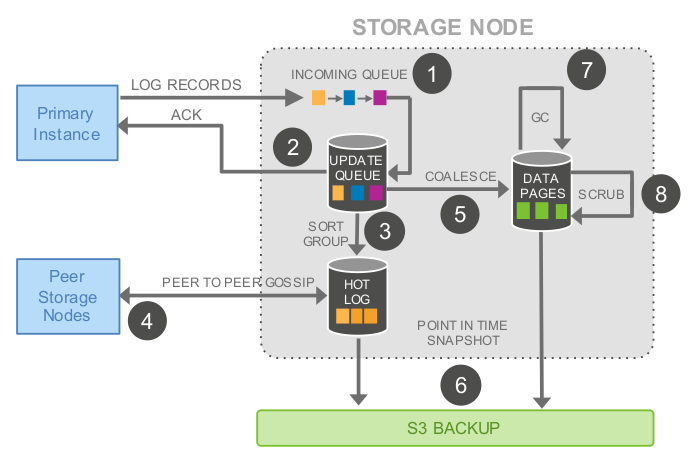
儲存節點的處理流程為:
1. 收到日誌記錄並將其加入記憶體的佇列
2. 持久化記錄並確認寫入
3. 整理日誌記錄並確認日誌中有哪些缺失,因為有些包可能丟了
4. 與其他資料節點互動填補空缺
5. 用日誌記錄生成新的資料頁
6. 不斷將資料頁和 *REDO* 日誌持久化到 *S3*
7. 週期性地回收舊的版本
8. 最後週期性的對資料頁進行 *CRC* 校驗
以上操作都為非同步的,只有步驟1和2是在前臺操作的路徑中,可能會影響延時。
### 3.4 故障恢復時一致性保證
**Aurora** 使用 **非同步** 的思路來維護狀態的一致性協議(從上層來看,維護一致性和可永續性的狀態點,並隨著收到請求的確認訊息,不斷地推進這些點),而不是使用 *2PC* 這種溝通複雜且對錯誤容忍度低的協議:
- 每一條日誌記錄都有一個由資料庫產生的單調遞增的日誌編號 **LSN**
- 儲存服務首先確定 **VCL (Volume Complete LSN)** ,它是能確保各副本之前的日誌記錄都可用的最大 *LSN*。在儲存恢復過程中,大於 *VCL* 的日誌必須被截斷
- 資料庫可以有多個 **CPL (Consistency Point LSN)** ,*CPL* 標記了 *log* 中可以被安全讀取的點,*CPL* 必須小於等於 *VCL*
- 可以定義 **VDL (Volume Durable LSN)** 為副本中最大的 *CPL* ,所有大於 *VDL* 的日誌記錄都可以被截斷丟棄
例如:即使有到 *LSN* 為1007的完整資料,資料庫發現只有900、1000和1100是 *CPL* 點,那麼必須在1000處截斷。因為有到1007的完整資料,但是隻有到1000是持久化的。
實現中,資料庫和儲存必須如下互動:
1. 每個資料庫層的事務會被劃分為多個 *mini* 事務,這些事務是有序的,並且被原子地執行
2. 每個 *mini* 事務由多個連續的日誌記錄組成
3. *mini* 事務的最後一個日誌記錄就是一個 *CPL*
在故障恢復的時候,資料庫告訴儲存服務建立每個 *PG* 的可持久化點,並使用這些來確認 *VDL* ,然後傳送命令截斷所有大於 *VDL* 的日誌記錄。
### 3.5 常規操作
#### 3.5.1 寫
**Aurora** 中,資料庫不斷與儲存服務互動,維護狀態來保持大多數派,持久化日誌記錄,並將事務標記為已提交。
寫操作是將 *log* 寫入到儲存伺服器中,不會修改已有的資料項。一次寫操作包含一個過程中的事務或是事務結束標記。
資料庫傳送每一條 *log* 到6個儲存副本中,收到4個寫確認後,會將此 *log* 提交,即將 *VDL* 向前推進一個。
當資料庫提交一個事務,處理這個提交請求的執行緒將事務放在一邊,並將 *COMMIT LSN* 記錄在一個單獨的事務佇列中等待被確認提交,然後就去做其他事情了。當 *VDL* 不斷的增加,資料庫找到哪些事務等待被確認,用一個單獨的執行緒給等待的客戶端返回事務完成的確認。
#### 3.5.2 讀
**Aurora** 中,與傳統資料庫一樣,資料頁是從 *buffer cache* 中讀取,只有在被請求的頁不在 *cache* 中時,才會發起一次儲存 *I/O* 請求。
如果 *buffer cache* 滿了,系統會找到一個頁並將其踢出快取。傳統資料庫中,若踢出的頁是髒頁,為保證讀取的資料永遠是最新的,該髒頁在被替換之前會被重新整理到資料盤中。但是 **Aurora** 在踢出頁時不會寫磁碟,它通過保證踢出 *應用的最新日誌記錄的 LSN* 大於等於 *VDL* 的資料頁,來保證 *buffer cache* 中的資料永遠是最新的。這個協議確保:(a)所有對資料頁的變更都已經持久化在日誌中了,(b)如果快取失效,可以通過獲取最新頁來構造當前*VDL* 所對應的頁面。
資料庫在通常情況下都不需要通過多數派讀來獲得一致性。當從盤裡面讀一個頁的時候,資料庫建一個讀取點,代表請求發生時的 *VDL* 。資料庫可以選擇一個對這個讀取點是完整的儲存節點,這樣讀取的資料肯定是最新的版本。
**Aurora** 在故障恢復的時候需要進行多數派讀( *read quorum* )。
### 3.6 讀寫分離
副本例項為只讀的副本,*client* 可以傳送只讀請求給它們,這樣可以減少主例項的負載。
在 **Aurora** 中,一個寫副本和多至15個讀副本可以掛載同一個共享的儲存空間。因而,讀副本不會增加任何的儲存和寫開銷。
只讀副本從儲存伺服器讀取資料頁並將它們快取,主例項會發送 *log* 給副本例項,副本例項使用這些 *log* 去更新快取中的資料頁。
### 3.7 Aurora 雲上體系

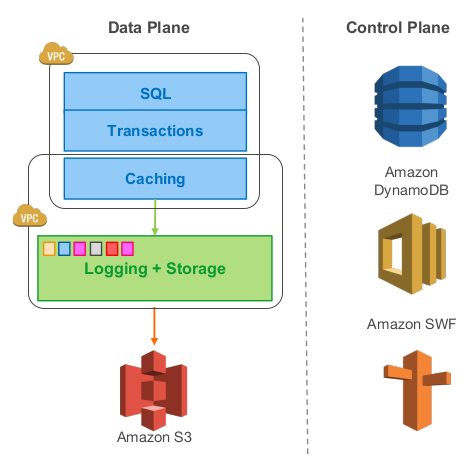
- 每個資料庫叢集包含一個寫副本、0個或多個讀副本
- 叢集中所有例項分佈於不同的可用區中,連線到相同區域的儲存服務
- **Aurora** 使用 *Amazon RDS* 作為控制面板,*RDS* 監控叢集健康狀況,判斷是否要做故障切換
- 每個資料庫例項可以與三個 *Amazon* 虛擬網路 *VPC* 通訊:使用者應用與資料庫引擎互動的 *Customer VPC* 、資料庫引擎與 *RDS* 控制面板互動的 *RDS VPC* 、資料庫與儲存服務互動的 *Storage VPC*
- 儲存服務部署在一個 *EC2* 虛擬機器叢集上,叢集最少跨同一個區域的三個可用區
- 儲存節點操作本地的 *SSD* 盤,與資料庫例項、其他儲存節點、備份/恢復服務互動,持續地將資料備份到 *S3* 或者從 *S3* 恢復資料
- 儲存服務的控制面板用 *Amazon DynamoDB* 作為持久儲存,存放資料庫容量配置、元資料以及備份到 *S3*上的資料的詳細資訊
- 為了支援長時間的操作,比如由故障導致的資料庫恢復或者複製操作,儲存服務的控制面板使用 *Amazon Simple Workflow Service, SWF*
### 3.8 優點和缺點
**優點**:
- 計算與儲存分離,一份儲存對接多個計算節點,多租戶儲存服務,成本低
- 讀寫分離,降低資料庫負載
- 只通過網路傳輸日誌,解決寫放大問題
- *quorum* 機制降低最差效能點的懲罰
- 例項快速故障恢復
- 跨可用區容錯
- 架構簡單,通過多副本能快速擴充套件讀能力,單個寫副本則避免了分散式事務等複雜實現
**缺點**:
- 適合於讀多寫少的應用
- 複雜查詢(*OLAP*)能力較弱
- 單個寫副本,無分割槽多點寫能