
細說websocket快速重連機制
阿新 • • 發佈:2020-07-23
## 引言
在一個完善的即時通訊應用中,websocket是極其關鍵的一環,它為web應用的客戶端和服務端提供了一種全雙工的通訊機制,但由於它本身以及其底層依賴的TCP連線的不穩定性,開發者不得不為其設計一套完整的保活、驗活、重連方案,才能在實際應用中保證應用的即時性和高可用性。就重連而言,其速度嚴重影響了上層應用的“即時性”和使用者體驗,試想開啟網路一分鐘後,微信還不能收發訊息的話,是不是要抓狂?
因此,如何在網路變更時快速恢復websocket的可用,就變得尤為重要。
## 快速瞭解websocet
Websocket誕生於2008年,在2011年成為國際標準,現在所有的瀏覽器都已支援。它是一種全新的應用層協議,是專門為web客戶端和服務端設計的真正的全雙工通訊協議,
可以類比HTTP協議來了解websocket協議。它們的不同點:
- HTTP的協議識別符號是`http`,websocket的是`ws`
- HTTP請求只能由客戶端發起,伺服器無法主動向客戶端推送訊息,而websocket可以
- HTTP請求有同源限制,不同源之間通訊需要跨域,而websocket沒有同源限制
相同點:
- 都是應用層的通訊協議
- 預設埠一樣,都是80或443
- 都可以用於瀏覽器和伺服器間的通訊
- 都基於TCP協議
兩者和TCP的關係圖:

[圖片來源](https://www.ruanyifeng.com/blog/2017/05/websocket.html)
## 重連過程拆解
首先考慮一個問題,何時需要重連?
最容易想到的是websocket連線斷了,為了接下來能收發訊息,我們需要再發起一次連線。但在很多場景下,即便websocket連線沒有斷開,實際上也不可用了,比如裝置切換網路、鏈路中間路由崩潰、伺服器負載持續過高無法響應等,這些場景下的websocket都沒有斷開,但對上層來說,都沒辦法正常的收發資料了。因此在重連前,我們需要一種機制來感知連線是否可用、服務是否可用,而且要能快速感知,以便能夠快速從不可用狀態中恢復。
一旦感知到了連線不可用,那便可以棄舊圖新了,棄用並斷開舊連線,然後發起一次新連線。這兩個步驟看似簡單,但若想達到快,且不是那麼容易的。
首先是斷開舊連線,對客戶端來說,如何快速快速斷開?協議規定客戶端必須要和伺服器協商後才能斷開websocket連線,但是當客戶端已經聯絡不上伺服器、無法協商時,如何斷開並快速恢復?
其次是快速發起新連線。此快非彼快,這裡的快並非是立即發起連線,立即發起連線會對伺服器帶來不可預估的影響。重連時通常會採用一些退避演算法,延遲一段時間後再發起重連。但如何在重連間隔和效能消耗間做出權衡?如何在“恰當的時間點”快速發起連線?
帶著這些疑問,我們來細看下這三個過程。
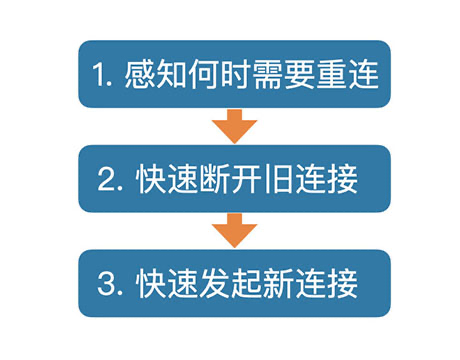
## 快速感知何時需要重連
需要重連的場景可以細分為三種,一是連線斷開了,二是連線沒斷但是不可用,三是連線對端的服務不可用了。
第一種場景很簡單,連線直接斷開了,肯定需要重連了。
而對於後兩者,無論是連線不可用,還是服務不可用,對上層應用的影響都是不能再收發即時訊息了,所以從這個角度出發,感知何時需要重連的一種簡單粗暴的方法就是通過心跳包超時:傳送一個心跳包,如果超過特定的時間後還沒有收到伺服器回包,則認為服務不可用,如下圖中左側的方案;這種方法最直接。那如果想要**快速感知**呢,就只能多發心跳包,加快心跳頻率。但是心跳太快對移動端流量、電量的消耗又會太多,所以使用這種方法沒辦法做到快速感知,可以作為檢測連線和服務可用的兜底機制。
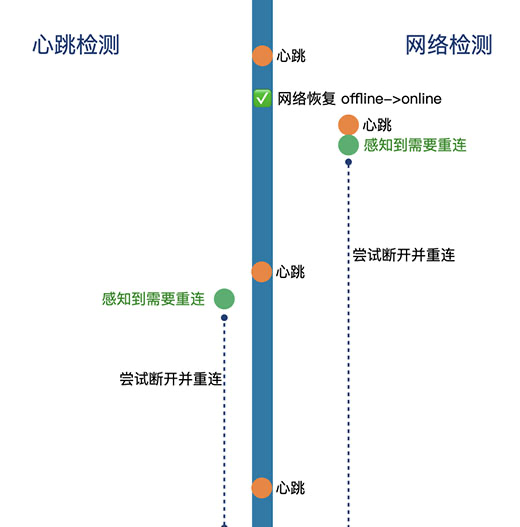
如果要檢測連線不可用,除了用心跳檢測,還可以通過判斷網路狀態來實現,因為斷網、切換wifi、切換網路是導致連線不可用的最直接原因,所以在網路狀態由`offline`變為`online`時,大多數情況下需要重連下,但也不一定,因為webscoket底層是基於TCP的,TCP連線不能敏銳的感知到應用層的網路變化,所以有時候即便網路斷開了一小會,對websocket連線是不會有影響的,網路恢復後,仍然能夠正常地進行通訊。因此在網路由斷開到連線上時,立即判斷下連線是否可用,可以通過發一個心跳包判斷,如果能夠正常收到伺服器的心跳回包,則說明連線仍是可用的,如果等待超時後仍沒有收到心跳回包,則需要重連,如上圖中的右側。這種方法的優點是速度快,在網路恢復後能夠第一時間感知連線是否可用,不可用的話可以快速執行恢復,但它只能覆蓋應用層網路變化導致websocket不可用的情況。
綜上,定時傳送心跳包檢測的方案貴在穩定,能夠覆蓋所有場景,但速度不太可;而判斷網路狀態的方案速度快,無需等待心跳間隔,較為靈敏,但覆蓋場景較為侷限。因此,我們可以結合兩種方案:定時以不太快的頻率傳送心跳包,比如40s/次、60s/次等,具體可以根據應用場景來定,然後在網路狀態由`offline`變為`online`時立即傳送一次心跳,檢測當前連線是否可用,不可用的話立即進行恢復處理。這樣在大多數情況下,上層的應用通訊都能較快從不可用狀態中恢復,對於少部分場景,有定時心跳作為兜底,在一個心跳週期內也能夠恢復。
## 快速斷開舊連線
通常情況下,在發起下一次連線前,如果舊連線還存在的話,應該先把舊連線斷開,這樣一來可以釋放客戶端和伺服器的資源,二來可以避免之後誤從舊連線收發資料。
我們知道websocket底層是基於TCP協議傳輸資料的,連線兩端分別是伺服器和客戶端,而TCP的`TIME_WAIT`狀態是由伺服器端維持的,因此在大多數正常情況下,應該由伺服器發起斷開底層TCP連線,而不是客戶端。也就是說,要斷開websocket連線時,如果是伺服器收到指示要斷開websocket,那它應該立即發起斷開TCP連線;如果是客戶端收到指示要斷開websocket,那它應該發訊號給伺服器,然後等待底層TCP連線被伺服器斷開或直至超時。
那如果客戶端想要斷開舊的websocket,可以分websocket連線可用和不可用兩種情況來討論。當舊連線可用時,客戶端可以直接給伺服器傳送斷開訊號,然後伺服器發起斷開連線即可;當舊連線不可用時,比如客戶端切換了wifi,客戶端傳送了斷開訊號,但是伺服器收不到,客戶端只能遲遲等待,直至超時才能被允許斷開。超時斷開的過程相對來說是比較久的,那有沒有辦法可以快點斷開?
上層應用無法改變只能由伺服器發起斷開連線這種協議層面的規則,所以只能從應用邏輯入手,比如在上層通過業務邏輯保證舊連線完全失效,模擬連線斷開,然後在發起新連線,恢復通訊。這種方法相當於嘗試斷開舊連線不行時,直接棄之,然後就能快速進入下一流程,所以在使用時一定要確保在業務邏輯上舊連線已完全失效,比如:保證丟掉從舊連線收到所有資料、舊連線不能阻礙新連線的建立,舊連線超時斷開後不能影響新連線和上層業務邏輯等等。
## 快速發起新連線
有IM開發經驗的同學應該有所瞭解,遇到因網路原因導致的重連時,是萬萬不能立即發起一次新連線的,否則當出現網路抖動時,所有的裝置都會立即同時向伺服器發起連線,這無異於黑客通過發起大量請求消耗網路頻寬引起的拒絕服務攻擊,這對伺服器來說簡直是災難。所以在重連時通常採用一些退避演算法,延遲一段時間再發起重連,如下圖中左側的流程。
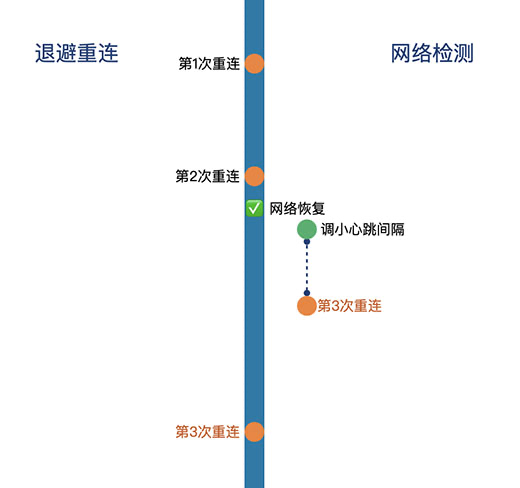
如果要快速連上呢?最直接的做法就是縮短重試間隔,重試間隔越短,在網路恢復後就能越快的恢復通訊。但是太頻繁的重試對效能、頻寬、電量的消耗就比較嚴重。如何在這之間做一個較好的權衡呢?
一種比較合理的方式是隨著重試次數增多,逐漸增大重試間隔;另一方面監聽網路變化,在網路狀態由`offline`變為`online`這種比較可能重連上的時刻,可以適當地減小重連間隔,如上圖中的右側(隨重試次數的增多,重連間隔也會變大),兩種方式配合使用。
除此之外,還可以結合業務邏輯,根據成功重連上的可能性適當的調整間隔,如網路未連線時或應用在後臺時重連間隔可以調大一些,網路正常的狀態下可以適當調小一些等等,加快重連上的速度。
## 結尾
最後總結一下,本文在開頭將websocket斷網重連細分為三個步驟:確定何時需要重連、斷開舊連線和發起新連線。然後分別分析了在websocket的不同狀態下、不同的網路狀態下,如何快速完成這個三個步驟:首先通過定時傳送心跳包的方式檢測當前連線是否可用,同時監測網路恢復事件,在恢復後立即傳送一次心跳,快速感知當前狀態,判斷是否需要重連;其次正常情況下由伺服器斷開舊連線,與伺服器失去聯絡時直接棄用舊連線,上層模擬斷開,來實現快速斷開;最後發起新連線時使用退避演算法延遲一段時間再發起連線,同時考慮到資源浪費和重連速度,可以在網路離線時調大重連間隔,在網路正常或網路由`offline`變為`online`時縮小重連間隔,使之儘可能快地重連上。
參考:
- https://tools.ietf.org/html/rfc6455
- https://www.ruanyifeng.com/blog/2017/05/websock