
熵、聯和熵與條件熵、交叉熵與相對熵是什麼呢?詳細解讀這裡有!
熵是一個很常見的名詞,在物理上有重要的評估意義,自然語言處理的預備知識中,熵作為資訊理論的基本和重點知識,在這裡我來記錄一下學習的總結,並以此與大家分享。
資訊理論基本知識
1、熵
2、聯和熵與條件熵
3、互資訊
4、交叉熵與相對熵
5、困惑度
6、總結
1、熵
熵也被稱為自資訊,描述一個隨機變數的不確定性的數量。熵越大,表明不確定性越大,所包含的資訊量也越大,就說明很難去預測事件行為或者正確估值。
熵的公式定義:


解答:

這裡計算將相同概率的字符合並計算,結果表明什麼呢?
結果說明傳輸一個字元平均只需要2.5個位元:
| 字元 | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 編碼 | 100 | 00 | 101 | 01 | 110 | 111 |
2、聯和熵與條件熵
聯和熵描述一對隨機變數平均所需要的資訊量。公式定義: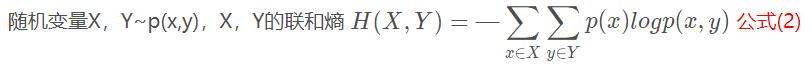
與之聯絡密切的條件熵指的是:給定X的情況下,Y的條件熵為:
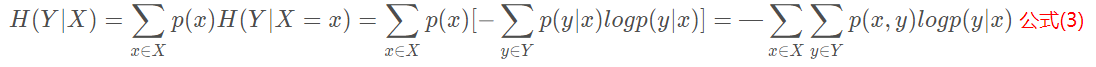
將以上公式(1)化簡可以得到 H(X,Y)=H(X)+H(Y∣X) 公式(4),被稱為熵的連鎖規則。
3、互資訊
熵的連鎖規則H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y), 所以H(X)−H(X∣Y)=H(Y)−H(Y∣X),這個差就成為互資訊,記作I(X;Y) 。
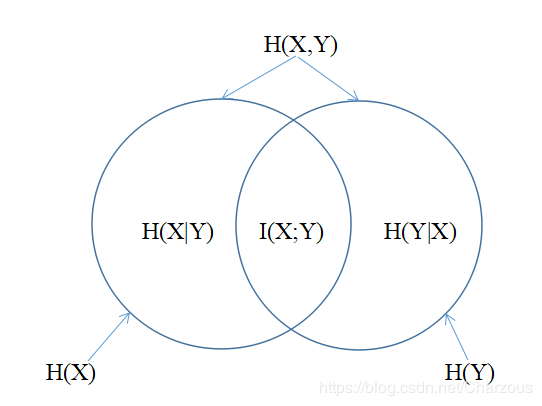
在圖中I(X;Y)反映的是已知Y的值後X的不確定性的減少量。在圖中I(X;Y)反映的是已知Y的值後X的不確定性的減少量。在圖中I(X;Y)反映的是已知Y的值後X的不確定性的減少量。簡而言之,Y的值透露了多少關於X的資訊量。
實際應用: 互資訊描述了兩個隨機變數之間的統計相關性,平均互資訊是非負的,在NLP中用來判斷兩個物件之間的關係,比如:根據主題類別和詞彙之間的互資訊進行特徵提取。另外在詞彙聚類、漢語自動分詞、詞義消岐、文字分類等問題有著重要用途。
4、交叉熵與相對熵
相對熵簡稱KL差異或KL距離,衡量相同時間空間裡兩個概率分佈相對差異的測度。

根據公式可知,當兩個隨機分佈完全相同時,即p=q,其相對熵為0。當兩個隨機分佈差別增加,相對熵的期望值也增大。
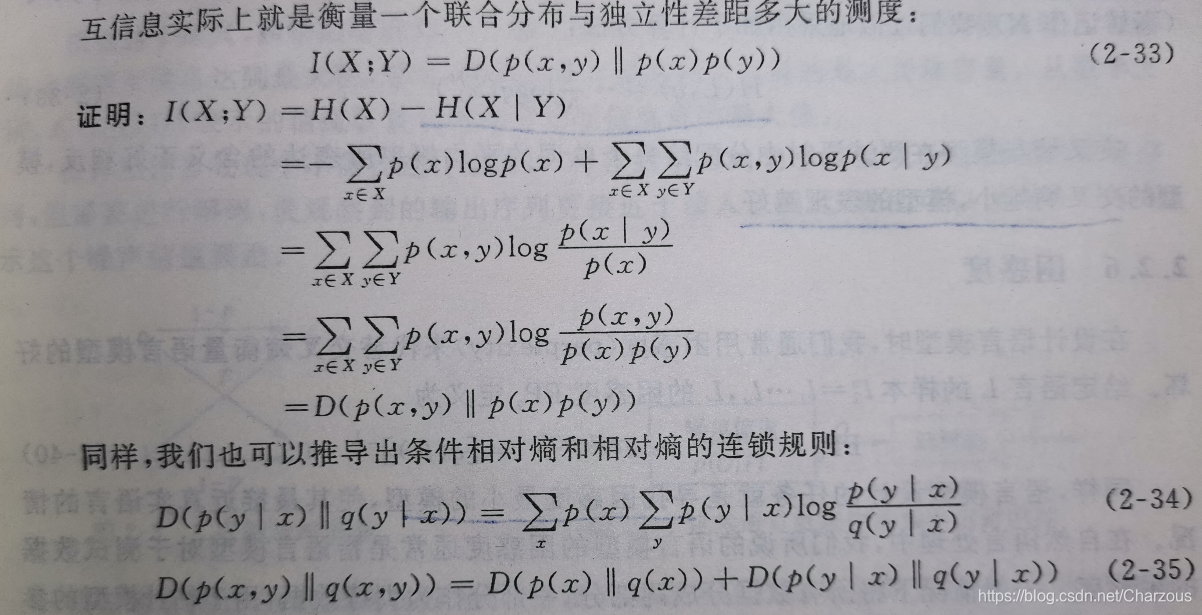
交叉熵就是機器學習中經常提到的一種熵的計算。它到底是什麼呢?
交叉熵是衡量估計模型與真實概率分佈之間之間差異情況。
如果一個隨機變數X~p(x),q(x)為用於近似p(x)的概率分佈,則實際p與模型q之間的交叉熵定義為:


在設計模型q時候,目的是使交叉熵最小,這樣模型的表現更好,從而使模型更接近最真實的概率分佈p(x),一般的,當樣本足夠大時候,上面計算近似為:
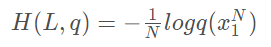
5、困惑度
在設計語言模型,通常用困惑度(perplexity)來代替交叉熵衡量語言模型的好壞。

所以,尋找困惑度最小的模型成為模型設計的任務,通常指的是模型對於測試資料的困惑度。
6、總結
在資訊理論的熵部分,我們學到了什麼呢?開始說到,這是NLP基礎,也是入門機器學習的重要理論部分。
- 熵(自資訊):描述一個隨機變數的不確定性的數量。熵越大,表明不確定性越大,所包含的資訊量也越大,就說明很難去預測事件行為或者正確估值。
- 聯和熵:描述一對隨機變數平均所需要的資訊量。
- 條件熵:給定X的情況下,通過聯和熵計算Y的條件熵,類似於條件概率思想。由此引出互資訊概念。
- 相對熵:簡稱KL差異或KL距離,衡量相同時間空間裡兩個概率分佈相對差異的測度,與互資訊密切相關。
- 交叉熵:衡量估計模型與真實概率分佈之間之間差異情況。
學習之後的一些記錄,發現這部分知識在其他方面經常提及到,卻不知其原理知識,因此做了一個簡單的總結備忘,與爾共享!
更好的閱讀體驗請轉至我的CSDN部落格哦!
我的CSDN部落格:熵、聯和熵與條件熵、交叉熵與相對熵是什麼呢?來這裡有詳細解讀!
我的部落格園:熵、聯和熵與條件熵、交叉熵與相對熵是什麼呢?詳細解讀這裡有!
————————————————
版權宣告:本文為CSDN博主「Charzous」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處連結及本宣告。
原文連結:https://blog.csdn.net/Charzous/article/details/107669211