
第二次作業:卷積神經網路 part 1
阿新 • • 發佈:2020-08-01
# 第二次作業:卷積神經網路 part 1
## 視訊學習
### 數學基礎
受結構限制嚴重,生成式模型效果往往不如判別式模型。
RBM:數學上很漂亮,且有統計物理學支撐,但主流深度學習平臺不支援RBM和預訓練。
自編碼器:正則自編碼器、稀疏自編碼器、去噪自編碼器和變分自編碼器。
- 概率/函式形式統一:
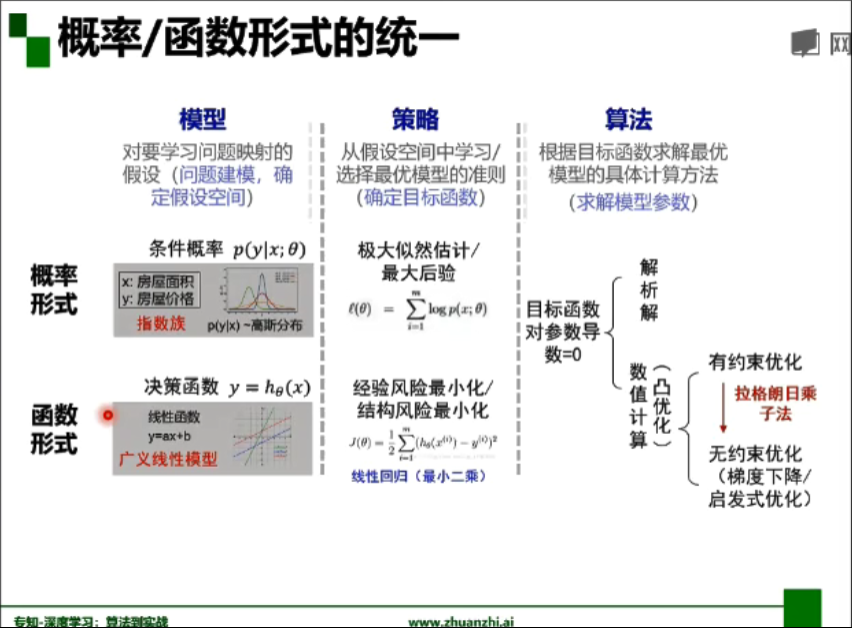
- 欠擬合、過擬合解決方案:
- 欠擬合:提高模型複雜度
- 決策樹:拓展分支
- 神經網路:增加訓練輪數
- 過擬合1:降低模型複雜度
- 優化目標加正則項
- 決策樹:剪枝
- 神經網路:early stop、dropout
- 過擬合2:資料增廣(訓練集越大,越不容易過擬合)
- 計算機視覺:影象旋轉、縮放、剪下
- 自然語言處理:同義詞替換
- 語音識別:新增隨機噪聲
- 交叉熵與對數損失函式關係:如果把所有樣本取均值就把交叉熵轉化成了對數損失函式。
平方損失函式假設高斯分佈,而分類問題是二項/多項分佈,對數損失與二項/多項分佈下的最大似然等價。
- 頻率學派:引數估計只依賴觀測資料
- 貝葉斯學派:引數估計同時依賴觀測資料和先驗知識
### 卷積神經網路CNN
- 基本應用:分類、檢索、檢測、分割、人臉識別、影象生成、風格轉化、自動駕駛
- 深度學習三部曲:搭建神經網路、損失函式、優化函式
- 全連線網路處理影象問題:引數太多:權重矩陣的引數太多 -> 過擬合
- 卷積神經網路的解決方法:區域性關聯,引數共享
- CNN組成:CONV layer卷積層、RELU layer啟用層、POOL layer池化層、FC layer全連線層
- **卷積**操作:
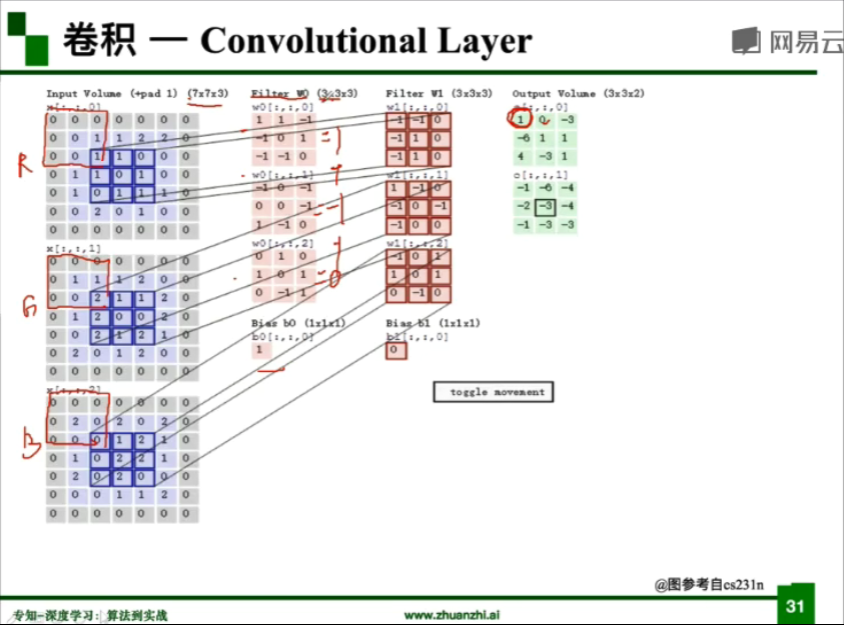
> kernel/filter:卷積核/濾波器
>
> stride:步長
>
> weights:權重
>
> receptive field:感受野
>
> activation map 或 feature map:特徵圖
>
> padding :填充
>
> depth/channel:深度/通道
- 特徵圖大小計算公式:(N-F+padding*2)/stride+1,輸入為N×N,卷積核為F×F
- 引數量:(卷積核大小5×5+偏置1)×個數
- 池化(pooling):保留了主要特徵的同時減少了引數和計算量,防止過擬合,提高模型泛化能力
- Max pooling:最大值池化
- Average pooling:平均值池化
> ps:池化層無引數,且不改變通道個數
> 縮小影象(或稱為下采樣(subsampled)或降取樣(downsampled))
>
> 原理:對於一幅影象I尺寸為M*N,對其進行s倍下采樣,即得到(M/s)*(N/s)尺寸的得解析度影象,當然s應該是M和N的公約數才行,如果考慮的是矩陣形式的影象,就是把原始影象s*s視窗內的影象變成一個畫素,這個畫素點的值就是視窗內所有畫素的均值。
>
> 目的:1.使得影象符合顯示區域的大小。2.生成對應影象的縮圖。
>
> 放大影象(或稱為上取樣(upsampling)或影象插值(interpolating))
>
> 原理:影象放大幾乎都是採用內插值方法,即在原有影象畫素的基礎上在畫素點之間採用合適的插值演算法插入新的元素。
>
> 目的:放大原影象,從而可以顯示在更高解析度的顯示裝置上。
- 全連線(Fully Connected):
- 兩層之間的所有神經元都有權重連結
- 通常全連線層在卷積神經網路尾部
- 全連線層引數量通常最大
- 卷積神經網路典型結構:
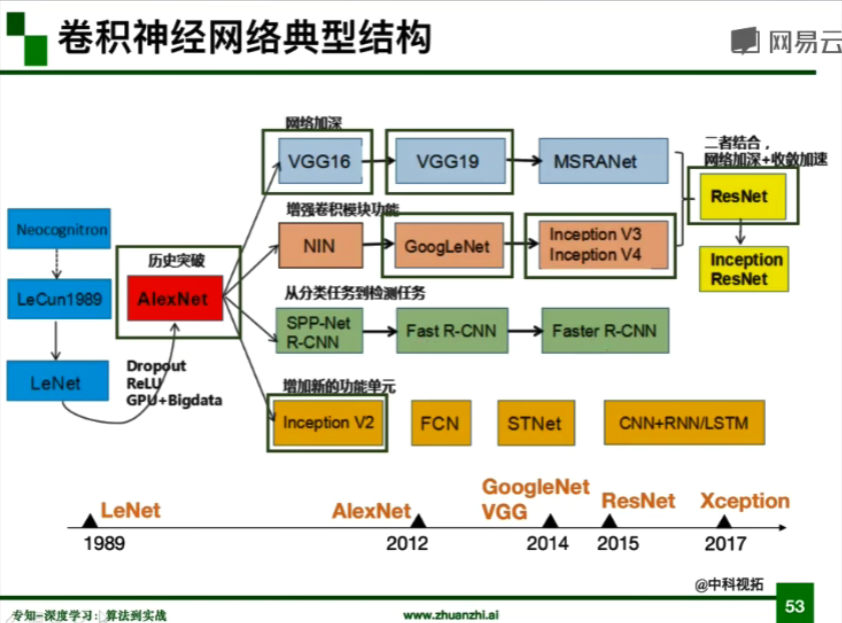
- **AlexNet**
- ILSVRC2012冠軍,錯誤率下降十個百分點,深度學習轉折點
- 大資料訓練:百萬級ImageNet影象資料
- 非線性啟用函式:ReLU
- 解決了梯度消失問題(在正區間)
- 計算速度特別快,只需要判斷輸入是否大於0
- 收斂速度遠快於Sigmoid
- 防止過擬合1:Dropout(隨機失活)
- 訓練時隨機關閉部分神經元,測試時整合所有神經元
- 防止過擬合2:Data augmentation(資料增強)
- 平移、翻轉、對稱
- 隨機crop。訓練的時候,對於256×256的圖片進行隨機crop到224×224
- 水平翻轉,相當於將樣本倍增
- 改變RGB通道強度
- 對RGB空間做一個高斯擾動
- 其他:雙GPU實現
> ps:Dropout訓練時為0.5,測試時設定0
- **ZFNet**
- ILSVRC2013冠軍,14.8%
- 網路結構與AlexNet相同
- 提取更詳細資訊:將卷積層1中的感受野大小由11×11改為7×7,步長由4改為2
- 卷積層3、4、5中的濾波器個數由384,384,256改為512,512,1024
- **VGG**
- ILSVRC2014亞軍,7.3%
- 是一個更深的網路:8 layers(AlexNet) -> 16 - 19(VGG)
- 廣泛用於遷移學習
> 因為當時沒有Batch Normalization,較深網路訓練的方法是先訓練前面層,然後凍結前面層引數,再訓練後面層。
- **GoogLeNet**
- ILSVRC2014冠軍,6.7%
- 組成
- 卷積層池化層:卷積—池化—卷積—卷積—池化
- Inception模組:多個Inception結構堆疊
- 輔助分類器:解決過深導致梯度消失問題,作用不大,v3拿掉
- 除分類外沒有額外FC層:網路很深,但引數量僅為AlexNet的1/12
- Naive Inception
- 多種卷積核增加特徵多樣性(conv1×1,conv3×3,conv5×5,pool3×3)
- 在深度上進行串聯:padding使結果大小保持一致
- 通道非常大:計算複雜度過高
- Inception v2
- 插入1×1卷積核進行降維:減小通道數,降低引數量
- Inception v3
- 用兩個3×3卷積核代替5×5卷積核:對應感受野大小一樣
- 進一步對v2引數量進行降低
- 增加非線性啟用函式(啟用兩次):使網路產生更多獨立特徵(disentangled feature),表徵能力更強,訓練更快
> Inception結構最初由GoogLeNet引入,GoogLeNet叫做Inception-v1;之後引入了BatchNormalization,叫做Inception-v2;隨後引入分解,叫做Inception-v3。
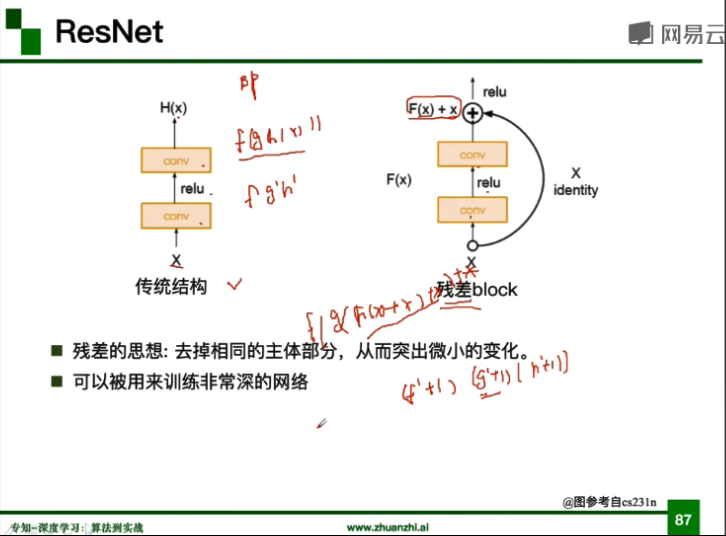
### ResNet
- 殘差學習網路(deep residual learning network)
- ILSVRC2015冠軍,3.57%
- 深度有152層
- 除了輸出層外沒有其他全連線層
- 殘差的思想:去掉相同的主體部分,從而突出微小的變化
- 可以被用來訓練非常深的網路,不會出現梯度消失
## 程式碼練習
### MNIST資料集分類
- 建立全連線網路和卷積神經網路
```python
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子類的函式必須在建構函式中執行父類的建構函式
# 下式等價於nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 這裡直接用 Sequential 就定義了網路,注意要和下面 CNN 的程式碼區分開
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出現在model類的forward函式中,用於改變輸入或輸出的形狀
# x.view(-1, self.input_size) 的意思是多維的資料展成二維
# 程式碼指定二維資料的列數為 input_size=784,行數 -1 表示我們不想算,電腦會自己計算對應的數字
# 在 DataLoader 部分,我們可以看到 batch_size 是64,所以得到 x 的行數是64
# 大家可以加一行程式碼:print(x.cpu().numpy().shape)
# 訓練過程中,就會看到 (64, 784) 的輸出,和我們的預期是一致的
# forward 函式的作用是,指定網路的執行過程,這個全連線網路可能看不啥意義,
# 下面的CNN網路可以看出 forward 的作用。
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 執行父類的建構函式,所有的網路都要這麼寫
super(CNN, self).__init__()
# 下面是網路裡典型結構的一些定義,一般就是卷積和全連線
# 池化、ReLU一類的不用在這裡定義
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函式,定義了網路的結構,按照一定順序,把上面構建的一些結構組織起來
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
```
- 定義訓練與測試函式
> 控制變數:全連線網路與CNN擁有相同數量的模型引數。
>
> 這裡分兩次進行:第一次不打亂畫素順序,第二次打亂畫素順序。

```python
# 對每個 batch 裡的資料,打亂畫素順序的函式
def perm_pixel(data, perm):
# 轉化為二維矩陣
data_new = data.view(-1, 28*28)
# 打亂畫素順序
data_new = data_new[:, perm]
# 恢復為原來4維的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
# 訓練函式
def train_perm(model, perm):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 畫素打亂順序
# data = perm_pixel(data, perm)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 測試函式
def test_perm(model, perm):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 畫素打亂順序
# data = perm_pixel(data, perm)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
```
> 不打亂畫素順序的情況下全連線與CNN準確率分別為88%、96%
>
> 打亂畫素順序的情況下全連線與CNN準確率分別為87%、84%
從結果來看,全連線網路的效能基本上沒有發生變化,但是CNN的效能明顯下降,卷積和池化就難以發揮作用。
這是因為CNN會利用畫素的區域性關係,但是打亂順序以後,這些畫素間的關係將無法得到利用。
### CIFAR10資料集分類
PyTorch 建立了一個叫做 totchvision 的包,該包含有支援載入類似Imagenet,CIFAR10,MNIST 等公共資料集的資料載入模組 torchvision.datasets 和支援載入影象資料轉換模組 torch.utils.data.DataLoader。
CIFAR-10資料集,它包含十個類別:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。影象尺寸為3x32x32,也就是RGB的3層顏色通道,每層通道內的尺寸為32*32。

- 訓練網路
```python
for epoch in range(10): # 重複多輪訓練
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 優化器梯度歸零
optimizer.zero_grad()
# 正向傳播 + 反向傳播 + 優化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 輸出統計資訊
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
```
> 使用CNN訓練10個epoch後在整個資料集上的表現準確率為64%
對於複雜多分類問題可以改進CNN使得效能進一步提升,具體可採用Dropout、Data Augmentation等方法,或者採用下面更強大的網路結構。
### 使用VGG16對CIFAR10分類
- VGG16模型
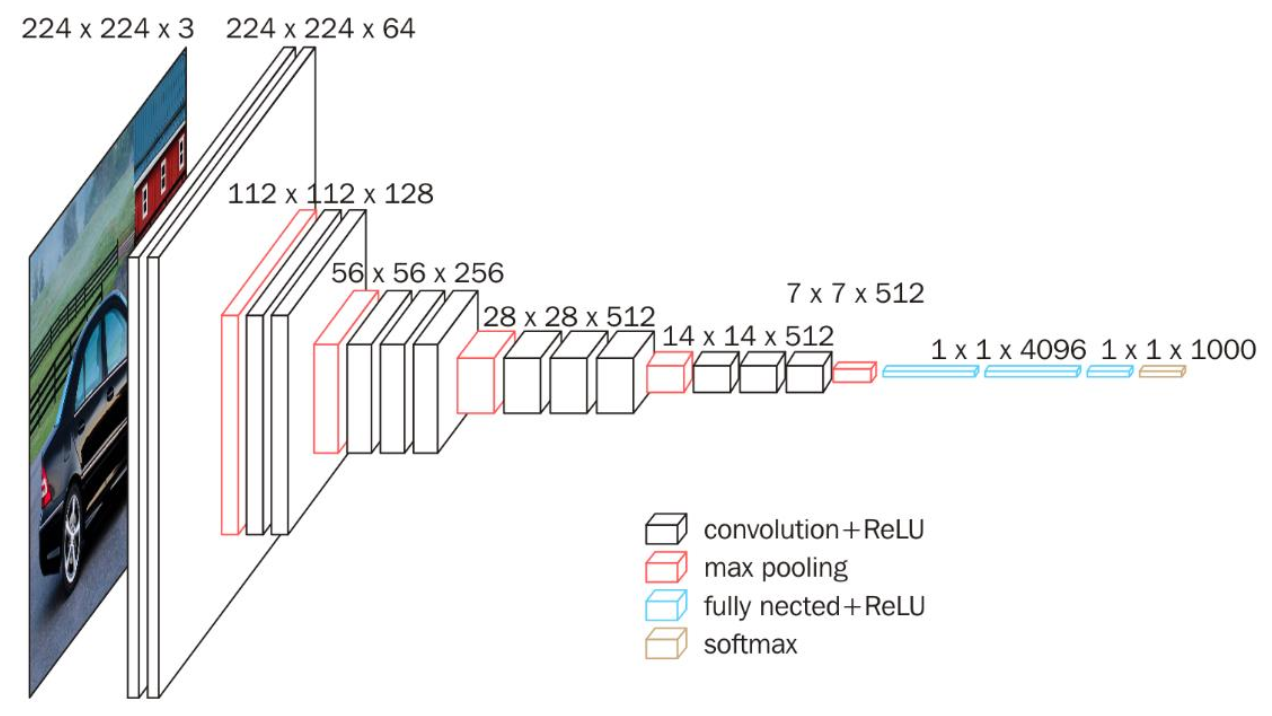
訓練測試步驟同上。
> 使用VGG訓練10個epoch後在整個資料集上的表現準確率為83%
我們發現將網路引數改小後,一個簡化版的VGG仍然能夠顯著地將準確率從64%提升到83%。
VGG名稱來源於牛津大學視覺幾何組(Visual Geometry Group)的縮寫。
該模型參加2014年的ImageNet影象分類與定位挑戰賽,取得了優異成績:在分類任務上排名第二,在定位任務上排名第一。
### 貓狗大戰(VGG模型遷移學習)

在原始碼基礎上做了以下改進,進一步提高準確率:
1. 資料增強:在資料處理的地方加入旋轉
2. 使用VGG19:相比VGG16網路更深,表現更優
3. 採用Adam優化器,並將學習率調整為3e-4:相比SGD優化能力更強,學習率比較玄學
4. 增大訓練樣本:使得訓練結果更精確
```python
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判斷是否存在GPU裝置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
```
- **下載資料:**
因為資料集檔案儲存結構與規範格式不一樣,需要加入一些對資料的操作,這裡感謝之前同學分享的方法。
```python
! wget https://static.leiphone.com/cat_dog.rar
# 解壓rar壓縮包,需要安裝rarfile庫(pip install rarfile)
! pip install rarfile
import rarfile
path = "cat_dog.rar"
path2 = "/content/"
rf = rarfile.RarFile(path) #待解壓檔案
rf.extractall(path2) #解壓指定檔案路徑
! mkdir cat_dog/val/Dog
! mkdir cat_dog/val/Cat
! mkdir cat_dog/train/Cat
! mkdir cat_dog/train/Dog
! mkdir cat_dog/test/test
! mv cat_dog/val/dog* cat_dog/val/Dog/
! mv cat_dog/val/cat* cat_dog/val/Cat/
! mv cat_dog/train/cat* cat_dog/train/Cat/
! mv cat_dog/train/dog* cat_dog/train/Dog/
! mv cat_dog/test/*.jpg cat_dog/test/test
```
- **資料處理:**
torchvision支援對輸入資料進行一些預處理/變換,圖片將被整理成 224×224×3 的大小,同時還將進行歸一化處理。
```python
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
# transforms.RandomHorizontalFlip(p=0.5), # 水平翻轉
# transforms.RandomVerticalFlip(p=0.5), # 垂直翻轉
# transforms.RandomRotation(30), # 隨機旋轉
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './cat_dog'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'val']}
tsets = {y: datasets.ImageFolder(os.path.join(data_dir, y), vgg_format)
for y in ['test']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'val']}
dset_classes = dsets['train'].classes
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(tsets['test'],batch_size=5,shuffle=False,num_workers=6)
```
- **建立VGG Model:**
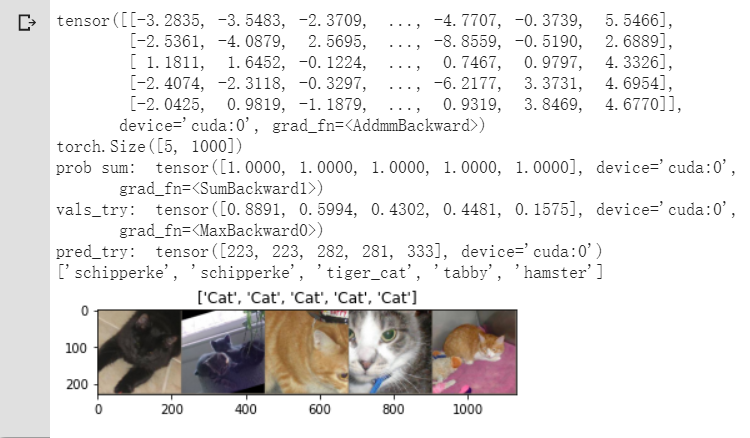
使用預訓練好的CNN模型,遷移學習。
我們可以看到VGG對於1000分類的表現也非常出色,可以細分到貓的具體種類。
```python
# ImageNet 1000類的JSON檔案展示VGG預測結果
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
# 使用了VGG19
model_vgg = models.vgg19(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
print(outputs_try)
print(outputs_try.shape)
'''
可以看到結果為5行,1000列的資料,每一列代表對每一種目標識別的結果。
但是我也可以觀察到,結果非常奇葩,有負數,有正數,
為了將VGG網路輸出的結果轉化為對每一類的預測概率,我們把結果輸入到 Softmax 函式
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print( 'prob sum: ', torch.sum(probs,1))
print( 'vals_try: ', vals_try)
print( 'pred_try: ', pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])
```
- **修改最後一層,凍結前面層的引數:**
VGG 模型由三種元素組成:
1. 卷積層(CONV)是發現影象中區域性的 pattern
2. 全連線層(FC)是在全域性上建立特徵的關聯
3. 池化(Pool)是給影象降維以提高特徵的 invariance
```python
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False # 凍結前面層的引數
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) # 1000類替換為2類(4096為全連線層維度)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
```
- **訓練並測試全連線層:**
- 建立損失函式和優化器
- 訓練模型
- 測試模型
```python
'''
第一步:建立損失函式和優化器
損失函式 NLLLoss() 的 輸入 是一個對數概率向量和一個目標標籤.
它不會為我們計算對數概率,適合最後一層是log_softmax()的網路.
'''
criterion = nn.NLLLoss()
# 二分類:NLLLoss(負對數似然損失函式)
# criterion = nn.CrossEntropyLoss()
# 多分類:CrossEntropyLoss(交叉熵損失函式)
# 學習率 Adam最優3e-4
lr = 0.0003
# 隨機梯度下降
# optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
# Adam
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:訓練模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs) # 可調整訓練影象序號,增大訓練樣本
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型訓練
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
```
```python
# 第三步:測試模型
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
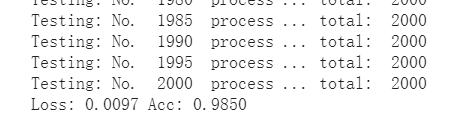
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
```
- **輸出CSV型別檔案:**
```python
import re
# 得到測試圖片編號
string = tsets['test'].imgs[0][0]
num = re.sub("\D", "", string)
result = []
# 將測試資料集(test)輸入到網路中,得到識別結果
for item,lable in loader_test:
item = item.to(device)
ll = model_vgg_new(item)
_,pre = torch.max(ll.data,1)
result += pre
# 結果排序
result_end =list()
cc = 0
for item in result:
string = tsets['test'].imgs[cc][0]
num = re.sub("\D", "", string)
result_end.append((num,item.tolist()))
cc += 1
result_sort = sorted(result_end,key=lambda x:int(x[0]))
# 寫入檔案
import csv
f = open('out_file.csv','w')
writer = csv.writer(f)
for i in result_sort:
writer.writerow(i)
f.clos