
深入理解mysql-進階知識點,啟動項、系統變數、字符集介紹!
阿新 • • 發佈:2020-08-02
mysql資料庫是當前應用最為的廣泛的資料庫,在實際工作中也經常接觸到。真正用好mysql也不僅僅是會寫sql就行,更重要的是真正理解其內部的工作原理。本文先從巨集觀角度介紹一些mysql相關的知識點,目的是為了讓大家對mysql能有一個大體上的認知,後續再逐一對每個知識點的進行深入解讀。
> 本文主要內容是根據掘金小冊《從根兒上理解 MySQL》整理而來。如想詳細瞭解,建議購買掘金小冊閱讀。
## 通訊方式
mysql採用了典型的**客戶端/伺服器架構(C/S架構)**模式。對於計算機而言,資料庫客戶端程式和伺服器程式分別運在不同的程序中。所以客戶端程序向伺服器程序傳送sql請求並得到返回結果的過程本質上就是**程序間通訊**。mysql支援的程序間通訊方式包括`TCP/IP`、`命名管道`、`共享記憶體`、`unix域套接字檔案`。
1. `TCP/IP`: **如果服務端程序和客戶端程序執行在不同的主機中,只能通過`TCP/IP`網路通訊協議進行通訊**。mysql伺服器啟動時監聽某個埠(預設3306),等待客戶端程序來連線。當然,服務端程序和客戶端程序在同一主機中,通過本機迴環地址(127.0.0.1)也是可以使用`TCP/IP`進行通訊的。
2. `命名管道或共享記憶體`: **如果服務端程序和客戶端程序都執行在一臺windows主機上,可以通過命名管道或共享記憶體方式進行通訊**。
1. 使用`命名管道`來進行程序間通訊: 需要在啟動伺服器程式的命令中加上`--enable-named-pipe`引數,然後在啟動客戶端程式的命令中加入`--pipe`或者`--protocol=pipe`引數。
2. 使用`共享記憶體`來進行程序間通訊: 需要在啟動伺服器程式的命令中加上`--shared-memory`引數,在成功啟動伺服器後,共享記憶體便成為本地客戶端程式的預設連線方式,不過我們也可以在啟動客戶端程式的命令中加入`--protocol=memory`引數來顯式的指定使用共享記憶體進行通訊。
3. `Unix域套接字檔案`: 如果我們的伺服器程序和客戶端程序都執行在同一臺作業系統為類Unix的機器上的話,我們可以使用Unix域套接字檔案來進行程序間通訊。
真實環境中,伺服器和客戶端基本都是執行在不同主機中的,它們之間採用的通訊方式就是`TCP/IP`。
## 一條查詢sql的基本處理過程
不論客戶端程序和伺服器程序是採用哪種方式進行通訊,最後實現的效果都是:**客戶端向伺服器傳送一段文字(sql語句),伺服器程序處理後再向客戶端程序傳送一段文字(處理結果)**。下面以查詢sql為例,簡單說明一下伺服器處理客戶端請求的大致處理過程。
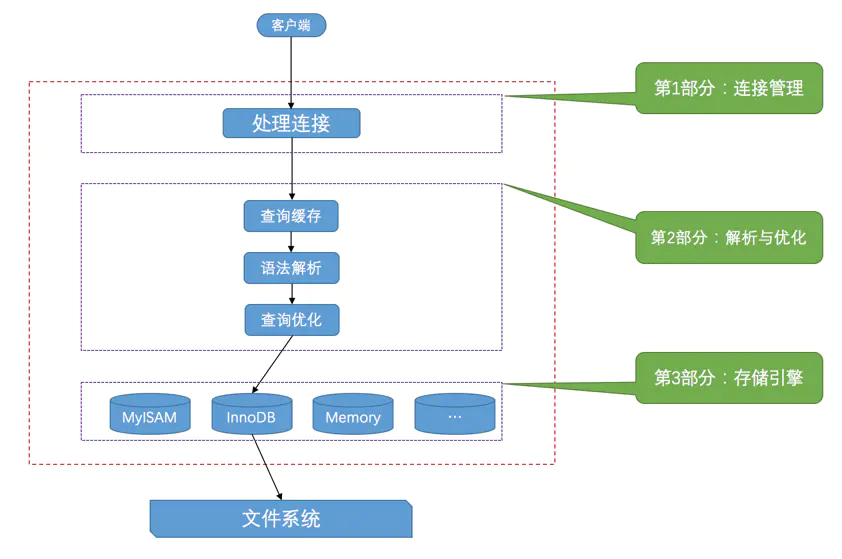
從圖中我們可以看出,伺服器程式處理來自客戶端的查詢請求大致需要經過三個部分,分別是`連線管理`、`解析與優化`、`儲存引擎`。
### 連線管理
每當有一個客戶端連線到伺服器時,伺服器都會建立一個執行緒來專門處理與這個客戶端的互動。在客戶端程式發起連線的時候,需要攜帶主機資訊、使用者名稱、密碼,伺服器程式會對客戶端程式提供的這些資訊進行認證,如果認證失敗,伺服器程式會拒絕連線。
當連線建立後,與該客戶端關聯的伺服器執行緒會一直等待客戶端傳送請求,MySQL伺服器接收到的請求只是一個文字訊息,該文字訊息還要經過各種處理才能將最後的處理結果返回客戶端。
### 解析與優化
到現在為止,MySQL伺服器已經獲得了文字形式的請求,接著還需要經過`查詢快取`、`語法解析`、`查詢優化`等進行處理。
#### 查詢快取
如果伺服器開啟了查詢快取,在執行查詢的時候會先從查詢快取中獲取查詢結果。如果命中快取則直接返回結果,否則接著執行。mysql不推薦使用查詢快取,並且在8.0版本已經移除此功能。真實環境中也不會使用,因此不用詳細瞭解。
#### 語法解析
這一步主要做的事情是對語句基於`SQL語法`進行詞法和語法分析和語義的解析,將要查詢的表、各種查詢條件都提取出來放到MySQL伺服器內部使用的一些資料結構上來。
#### 查詢優化
因為我們寫的MySQL語句執行起來效率可能並不是很高,MySQL的優化程式會對我們的語句做一些優化,如外連線轉換為內連線、表示式簡化、子查詢轉為連線等等。優化的結果就是生成一個執行計劃,這個執行計劃表明了應該使用哪些索引進行查詢,表之間的連線順序等。我們可以使用`EXPLAIN`語句來檢視某個語句的執行計劃。
### 儲存引擎
mysql資料是儲存在`資料表`裡面,但表只是邏輯上的概念,資料真正是儲存在物理磁碟上的。儲存引擎負責的就是物理上資料的儲存和提取。為了實現不同的功能,MySQL提供了各式各樣的儲存引擎,不同儲存引擎在物理上的儲存結構存在一些差異。但是不同的儲存引擎提供了統一的呼叫介面(也就是儲存引擎API)。
mysql支援多種儲存引擎,可以通過如下命令檢視:
```sql
show engines ;
```
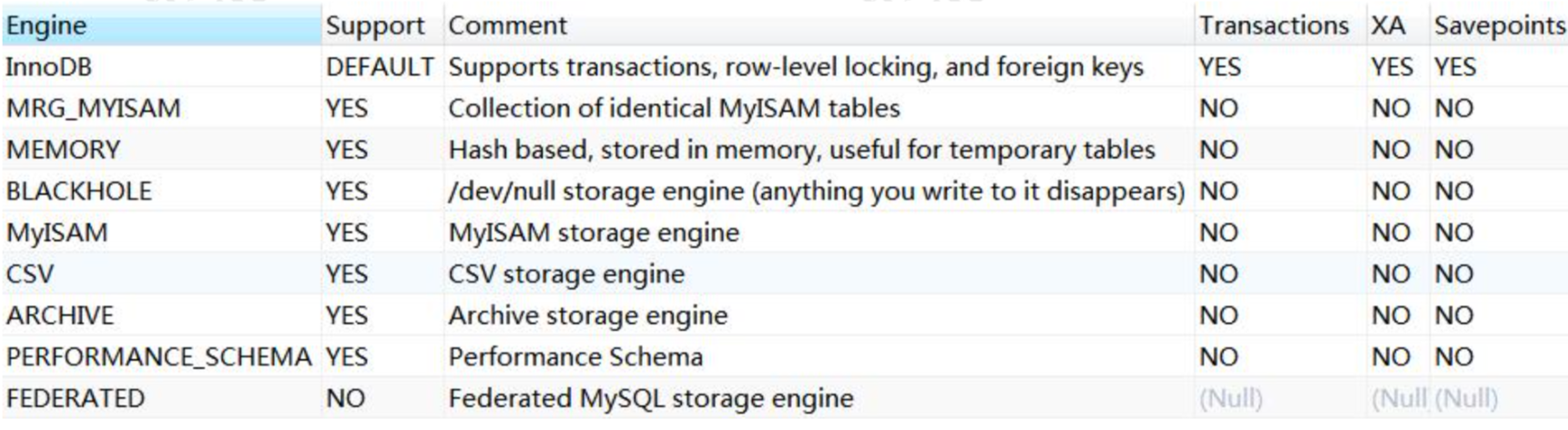
**雖然支援的儲存引擎很多,但是我們需要重點關注InnoDB以及適當瞭解MyISAM儲存引擎即可!**
為了管理方便,人們把`連線管理`、`查詢快取`、`語法解析`、`查詢優化`這些並不涉及真實資料儲存的功能劃分為`MySQL server`的功能,把真實存取資料的功能劃分為`儲存引擎`的功能。
## 啟動選項和系統變數
mysql程式(包括伺服器相關程式和客戶端相關程式)在啟動的時候可以指定啟動引數,來控制程式啟動後的行為。這些啟動引數可以放在命令列中指定,也可以把它們放在配置檔案中指定。
### 在命令列上使用啟動選項
啟動mysql程式的命令列後邊指定啟動選項的通用格式如下:
```shell
--啟動選項1[=值1] --啟動選項2[=值2] ... --啟動選項n[=值n]
```
各個啟動選項之間使用空白字元隔開,在每一個啟動選項名稱前邊新增`--`。對於不需要值的啟動選項,比方說`skip-networking`,它們就不需要指定對應的值。對於需要指定值的啟動選項,比如`default-storage-engine`我們在指定這個設定項的時候需要顯式的指定它的值,比方說`InnoDB`、`MyISAM`。
```shell
mysqld --default-storage-engine=MyISAM --skip-networking
```
比如上面的啟動項就表示預設儲存引擎為`MyISAM`,並且禁止使用`TCP/IP`方式通訊。
為了使用的方便,對於一些常用的選項提供了短形式,比如:
| 長形式|短形式 | 含義 |
|------------|-----------|--------|
| --host | -h| 主機名 |
| --user | -u| 使用者名稱 |
| --password | -p| 密碼 |
| --port | -P| 主機名 |
| --host | -h| 埠 |
### 配置檔案中使用選項
相比於使用命令列的方式設定啟動選項,mysql更推薦使用配置檔案來設定啟動選項。我們把需要設定的啟動選項都寫在這個配置檔案中,每次啟動伺服器的時候都從這個檔案里加載相應的啟動選項。
MySQL程式在啟動時會尋找多個路徑下的配置檔案,這些路徑有的是固定的,有的是可以在命令列指定的。根據作業系統的不同,配置檔案的路徑也有所不同,並且越後面路徑下的配置優先順序越好。總之就是多個路徑下都可以存在配置檔案,並且有個優先順序的關係。這裡就不展開了。
#### 配置檔案的內容
與在命令列中指定啟動選項不同的是,配置檔案中的啟動選項被劃分為若干個組,每個組有一個組名,用中括號`[]`擴起來,像這樣:
```properties
[server]
(具體的啟動選項...)
[mysqld]
(具體的啟動選項...)
[mysqld_safe]
(具體的啟動選項...)
[client]
(具體的啟動選項...)
[mysql]
(具體的啟動選項...)
[mysqladmin]
(具體的啟動選項...)
```
啟動mysql程式時,會使用對應的一個或多個組下的啟動選項。每個組下邊可以定義若干個啟動選項,我們以`[server]`組為例來看一下填寫啟動選項的形式(其他組中啟動選項的形式是一樣的):
```properties
[server]
option1 #這是option1,該選項不需要選項值
option2 = value2 #這是option2,該選項需要選項值
```
### 系統變數
**mysql系統變數是指能夠影響伺服器程式執行行為的變數**。比如允許同時連入的客戶端數量由系統變數`max_connections`控制,表的預設儲存引擎由系統變數`default_storage_engine`控制。每個系統變數都有一個預設值,我們可以使用命令列或者配置檔案中的選項在啟動伺服器時改變一些系統變數的值,或者在執行時動態修改(大多數系統變數支援動態修改)。
#### 作用範圍
多個客戶端程式可以同時連線到一個伺服器程式。對於同一個系統變數,我們有時想讓不同的客戶端有不同的值,mysql通過**系統變數的作用範圍**來解決上述問題。具體來說作用範圍分為下面兩種:
1. `GLOBAL`:全域性變數,影響伺服器的整體操作。
2. `SESSION`:會話變數,影響某個客戶端連線的操作。(注:`SESSION`有個別名叫`LOCAL`)
很顯然,通過啟動選項設定的系統變數的作用範圍都是`GLOBAL`的,也就是對所有客戶端都有效的。通過客戶端動態修改系統變數語法如下:
```sql
SET [GLOBAL|SESSION] 系統變數名 = 值;
```
**如果在設定系統變數的語句中省略了作用範圍,預設的作用範圍就是SESSION。**同理,我們可以使用下列命令檢視MySQL伺服器程式支援的系統變數以及它們的當前值:
```sql
SHOW [GLOBAL|SESSION] VARIABLES [LIKE 匹配的模式];
```
### 狀態變數
**mysql狀態變數是指描述伺服器執行狀態的變數,**比方說`Threads_connected`表示當前有多少客戶端與伺服器建立了連線。
由於狀態變數是用來顯示伺服器程式執行狀況的,所以**它們的值只能由伺服器程式自己來設定(對客戶端而言是隻讀的)**。與系統變數類似,狀態變數也有`GLOBAL`和`SESSION`兩個作用範圍的,所以檢視狀態變數的語句可以這麼寫:
```sql
SHOW [GLOBAL|SESSION] STATUS [LIKE 匹配的模式];
```
## mysql支援的字符集和比較規則
在計算機中,資料最終都是以二進位制的形式儲存的。因此,如果我們要儲存字串,首先就先得確定字串中的每個字元對應的二進位制資料是什麼,然後再將這些二進位制資料儲存到計算機中。將一個字元對映成一個二進位制資料的過程也叫做`編碼`,將一個二進位制資料對映到一個字元的過程叫做`解碼`。
使用字符集可以解決資料儲存的問題,但是無法完全解決字元之間相互比較的問題。簡單場景下,我們可以直接通過比較字元的二進位制資料來判斷大小,這種方式其實就是`二進位制比較規則`。而有些場景下,`二進位制比較規則`並不適用,比如忽略大小寫的時候。因此**為了應對不同的場景,同一種字符集可以有多種比較規則**。
### 字符集
mysql中支援很多種字符集,可以通過以下語句檢視:
```sql
SHOW CHARSET [LIKE 匹配的模式];
```
```shell
mysql> SHOW CHARSET;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
...
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
...
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.01 sec)
```
1. `Charset`: 字符集名稱
2. `Description`: 字符集描述
3. `Default collation`: 預設的比較規則
4. `Maxlen`: 一個字元最大佔用的位元組數。對於採用`變長編碼方式`的字符集而言,一個字元佔用的位元組數不是固定的。比如在`GB2312字符集`中,一個字母只佔用1個位元組,而一個漢字佔用了2個位元組。
在mysql中,`utf8`和`utf8mb4`的區別就在於1個字元佔用的最大位元組數不同。`utf8`一個字元佔用1-3個位元組,而`utf8mb4`一個字元佔用1-4個位元組。實際上,mysql的`utf8`是`utf8mb3`的別名。如果需要儲存一些佔用4個位元組的特殊字元(比如emoji表情),建議使用`utf8mb4`字符集。
### 比較規則
可以通過以下語句檢視mysql中支援的比較規則:
```sql
SHOW COLLATION [LIKE 匹配的模式];
```
```shell
mysql> SHOW COLLATION LIKE 'utf8\_%';
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | | Yes | 1 |
...
+--------------------------+---------+-----+---------+----------+---------+
27 rows in set (0.00 sec)
```
1. `Collation`: 比較規則名稱,基本符合`字符集名稱_語言_字尾`模式。第一部分`字符集名稱`就是與其關聯的字符集的名稱開頭,第二部分表示該比較規則作用的語言,比如`utf8_spanish_ci`是以西班牙語的規則比較,`utf8_general_ci`是一種通用的比較規則。第三部分字尾主要用來表示要不要區分大小寫和重音之類的。
2. `Charset`: 關聯的字符集的名稱。
3. `Default`: yes表示是字符集預設的比較規則。
| 字尾 | 英文釋義| 描述 |
| ------ | ------ | ------ |
| _ai | accent insensitive | 不區分重音 |
| _as | accent | sensitive | 區分重音 |
|_ci | case insensitive |不區分大小寫 |
| _cs | case sensitive | 區分大小寫 |
|_bin | binary | 以二進位制方式比較 |
### 字符集和比較規則作用域級別
mysql中字符集和比較規則有4種作用域級別:
1. 伺服器級別
2. 資料庫級別
3. 表級別
4. 列級別
實際上,**字符集和比較較規則最後肯定是作用在`列級別`欄位上的**。可以簡單的認為,如果`列級別`沒有指定字符集和比較較規則,就使用`表級別`的;如果`表級別`沒有指定字符集和比較較規則,就使用`資料庫級別`的;以此類推。
#### 伺服器級別
MySQL提供了兩個系統變數來表示伺服器級別的字符集和比較規則:
- `character_set_server`: 伺服器級別的字符集
- `collation_server`: 伺服器級別的比較規則
伺服器級別預設的字符集是`utf8`,預設的比較規則是`utf8_general_ci`。
#### 資料庫級別
我們在建立和修改資料庫的時候可以指定該資料庫的字符集和比較規則,具體語法如下:
```sql
CREATE DATABASE 資料庫名
CHARACTER SET 字符集名稱
COLLATE 比較規則名稱;
ALTER DATABASE 資料庫名
CHARACTER SET 字符集名稱
COLLATE 比較規則名稱;
```
比如:
```sql
mysql> CREATE DATABASE charset_demo_db
-> CHARACTER SET gb2312
-> COLLATE gb2312_chinese_ci;
Query OK, 1 row affected (0.01 sec)
```
如果想檢視當前資料庫使用的字符集和比較規則,可以檢視下面兩個系統變數的值:
- `character_set_database`: 當前資料庫的字符集
- `collation_database`: 當前資料庫的比較規則
#### 表級別
我們可以在建立和修改表的時候指定表的字符集和比較規則,語法如下:
```sql
CREATE TABLE 表名
(列的資訊)
CHARACTER SET 字符集名稱
COLLATE 比較規則名稱
ALTER TABLE 表名
CHARACTER SET 字符集名稱
COLLATE 比較規則名稱
```
比如:
```sql
mysql> CREATE TABLE t(
-> col VARCHAR(10)
-> ) CHARACTER SET utf8 COLLATE utf8_general_ci;
Query OK, 0 rows affected (0.03 sec)
```
#### 列級別
需要注意的是,對於儲存字串的列,**同一個表中的不同的列也可以有不同的字符集和比較規則**。我們在建立和修改列定義的時候可以指定該列的字符集和比較規則,語法如下:
```sql
CREATE TABLE 表名(
列名 字串型別 CHARACTER SET 字符集名稱 COLLATE 比較規則名稱,
其他列...
);
ALTER TABLE 表名 MODIFY 列名 字串型別 CHARACTER SET 字符集名稱 COLLATE 比較規則名稱;
```
比如我們修改一下表t中列col的字符集和比較規則可以這麼寫:
```sql
mysql> ALTER TABLE t MODIFY col VARCHAR(10) CHARACTER SET gbk COLLATE gbk_chinese_ci;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
```
還需要注意的一點是:**由於字符集和比較規則是相互聯絡的,如果我們只修改了字符集和比較規則,都可能引起關聯的字符集和比較規則發生變