
Redis服務之高可用元件sentinel
前文我們瞭解了redis的常用資料型別相關命令的使用和說明,回顧請參考https://www.cnblogs.com/qiuhom-1874/p/13419690.html;今天我們來聊一下redis的高可用元件sentinel;首先來回顧下redis的主從同步,主從同步最主要的作用是讓master的資料在其他伺服器上實時存在副本,起到了備份的效果;對於redis的讀寫來說,主從架構能夠讓讀的請求分散到多個從伺服器上,從而降低了單臺redis讀請求的io壓力,同時也提高了redis讀請求的併發能力;通常為了資料的一致性,從伺服器一旦成為某一臺redis的slave,那麼從伺服器上之前有的資料會被清空,然後把master傳送過來的資料應用到記憶體,從而實現和master資料一致;除此之外slave通常會是隻讀屬性,也就說slave端只能執行讀操作,寫操作會被拒絕,所以寫請求始終是由master來完成;那麼問題來了,對於這種主從複製架構的環境中,如果master宕機了,master宕機意味著整個系統將不能夠寫資料到redis,很顯然這種情況我們應該及時解決;怎麼解決呢?有沒有這樣的一元件幫我們對master做實時的監控,一旦發現master宕機就提升一個slave當選新的master,如果原master還有其他slave,將其他slave都從屬於新的master;除此之外它還應該讓系統在發生切換master時觸發報警通知,讓管理員儘快把壞掉的master修復上線;對,sentinel就有我們上述的這些功能,它能夠監控主從同步叢集中的master節點,在master發生宕機後能夠自動故障轉移,將提升一臺slave作為新的master,然後通知管理員;
Sentinel是一個分散式系統,我們可以在一個架構中執行多個sentinel,這些sentinel程序使用流言協議(gossipprotocols)來接收關於 Master是否下線的資訊,並使用投票協議(Agreement Protocols)來決定是否執行自動故障遷移,以及選擇哪個 Slave 作為新的 Master。每個sentinel程序會向其他sentinel程序、master、slave定時傳送訊息,以確保對方是否”活”著,如果發現對方在指定配置時間(可配置的)內未得到迴應,則暫時認為對方已掉線,也就是所謂的”主觀認為宕機” ,英文名稱:Subjective Down,簡稱 SDOWN。有主觀宕機,肯定就有客觀宕機。當多個sentinel程序中多數的sentinel程序在對 Master 做出 SDOWN 的判斷,並且通過 SENTINEL is-master-down-by-addr 命令互相交流之後,得出的 Master Server 下線判斷,這種方式就是“客觀宕機”,英文名稱是:Objectively Down, 簡稱 ODOWN。通過一定的 vote 演算法,從剩下的 slave 從伺服器節點中,選一臺提升為 Master 伺服器節點,然後自動修改相關配置,並開啟故障轉移(failover)。
配置使用sentinel
環境說明
| 角色 | ip地址 | 埠 |
| master | 192.168.0.41 | 6379 |
| slave01 | 192.168.0.42 | 6379 |
| slave02 | 192.168.0.43 | 6379 |
| sentinel01 | 192.168.0.41 | 26379 |
| sentinel02 | 192.168.0.42 | 26379 |
| sentinel03 | 192.168.0.43 | 26379 |
架構圖

提示:從上面的架構圖可以知道,首先我們必須要有一個主從架構的叢集,然後在部署sentinel 來對主從同步叢集做監控;
redis主從複製叢集搭建
1、在192.168.0.41/42/43上安裝redis,可以使用yum安裝,也可以使用編譯安裝,redis安裝請參考https://www.cnblogs.com/qiuhom-1874/p/13378138.html;
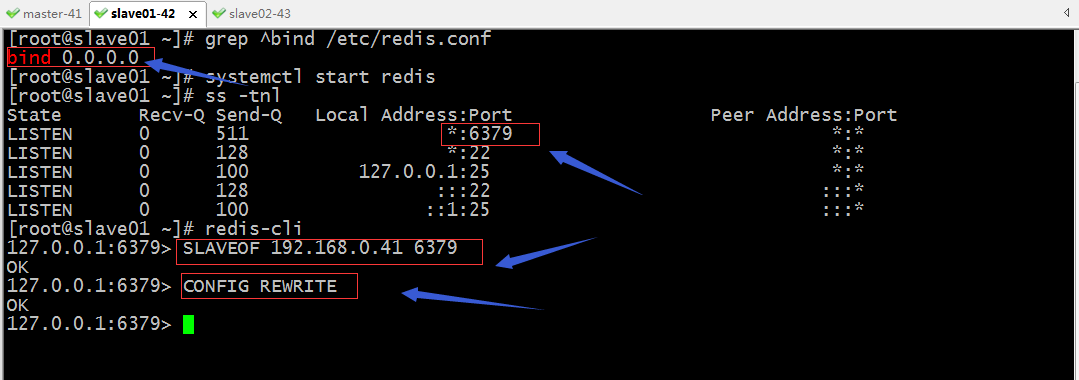
2、配置192.168.0.41/42/43上的redis監聽在非本機127.0.0.1上並配置42/43上的redis從屬於192.168.0.41
master

slave01
slave02

提示:redis支援線上修改配置,儲存配置到配置檔案;SLAVEOF 指令用於指定redismaster的ip地址和埠,表示把該redis配置成對應master的slave角色;CONFIG REWRITE是把我們的配置儲存到配置檔案;
在master上檢視是否有兩個從節點連線到master

驗證:在master上寫資料,看看是否能夠及時同步到兩個slave上?



提示:可以看到在主庫上寫資料,從庫上能夠及時的同步主庫上的資料;到此redis的主從叢集就搭建完畢了;
配置sentinel,讓其監控master

提示:三個sentinel的配置都是一樣的,這裡需要明確指定監控主從同步叢集的master的ip地址和埠,以及有效法定票數,有效法定票數指的是至少有多少個sentinel主觀認為master down了,然後才觸發選舉新master操作;通常在這種流言協議中,一般都是大於叢集半數,如果是3臺sentinel,至少要2臺主觀認為master宕機,才開始觸發選舉新master;如果是5臺,那至少要3臺;如果master配置的有認證密碼,我們還需要在sentinel中指定認證密碼;
sentinel配置檔案說明
bind:該指令和redis配置檔案中的bind是同樣的用法,用於指定sentinel的監聽地址;預設不指定,監聽本機所有可用地址;
protected-mode:指定是否開啟保護模式;
port:用於指定sentinel的監聽埠;預設是26379
daemonize:用於指定sentinel是否執行為守護程序,yes表示執行為後臺守護程序;no表示不執行為守護程序,直接在前臺執行;
pidfile:指定pid檔案路徑;
logfile:指定日誌檔案路徑;
dir:指定sentinel的工作路徑;
sentinel monitor <master-name> <ip> <redis-port> <quorum>:用於指定監控master節點的ip地址和埠以及有效法定票數;其中<master-name>是給監控的master一個名稱,可以隨便寫,起標識的作用;<quorum>表示sentinel叢集的quorum機制,即至少有quorum個sentinel節點同時判定主節點故障時,才認為其真的故障;
sentinel auth-pass <master-name> <password>:指定master認證密碼;通常都需要設定密碼,並且master的密碼和slave的密碼應該是一樣;
sentinel down-after-milliseconds <master-name> <milliseconds>:配置監控到指定的叢集的主節點異常狀態持續多久方才將標記為“故障”;
sentinel parallel-syncs <master-name> <numslaves>:指在failover過程中,能夠被sentinel並行配置的從節點的數量;
sentinel failover-timeout <master-name> <milliseconds>:sentinel必須在此指定的時長內完成故障轉移操作,否則,將視為故障轉移操作失敗;
sentinel notification-script <master-name> <script-path>:通知指令碼,此指令碼被自動傳遞多個引數;
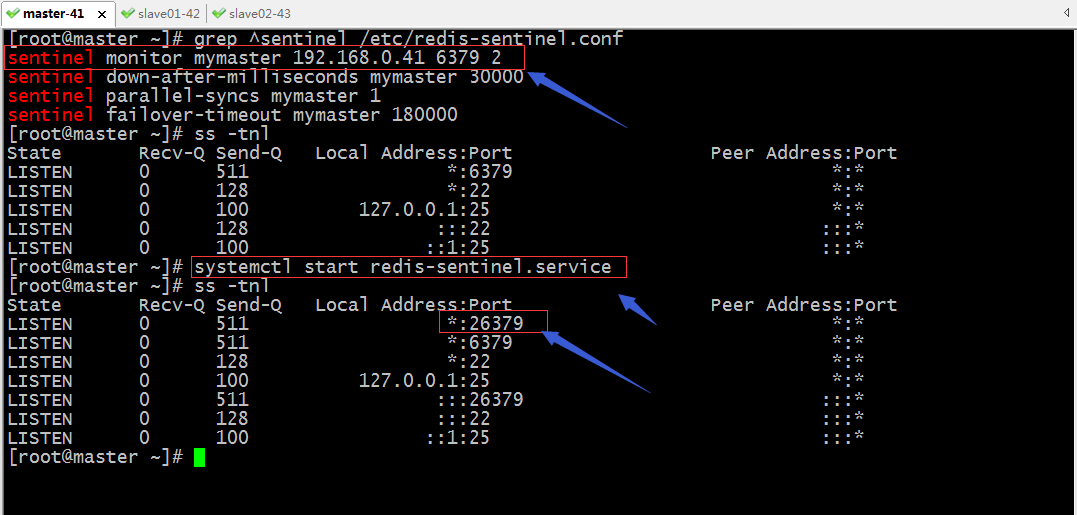
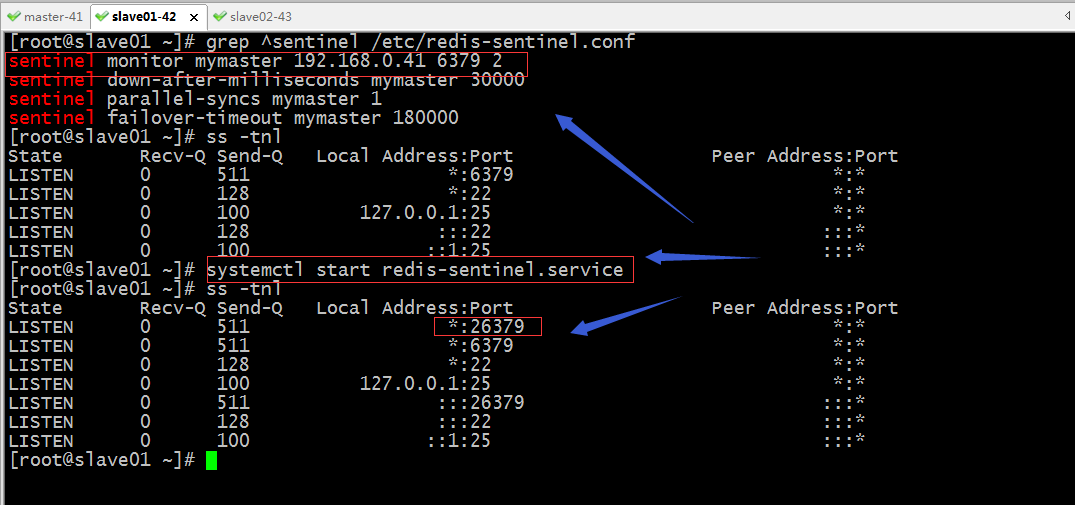
瞭解了sentinel的配置檔案,接下我們把3臺sentinel都啟動起來
master
slave01
slave02
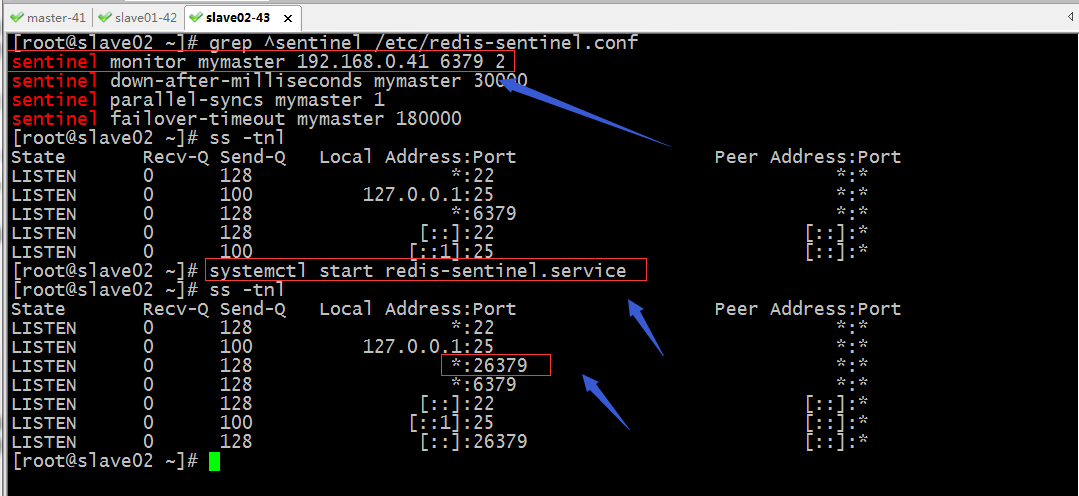
提示:從上面的資訊可以看到3個sentinel都監控master的ip地址和埠,其實他們3個的配置檔案都是一樣的;
檢視sentinel日誌
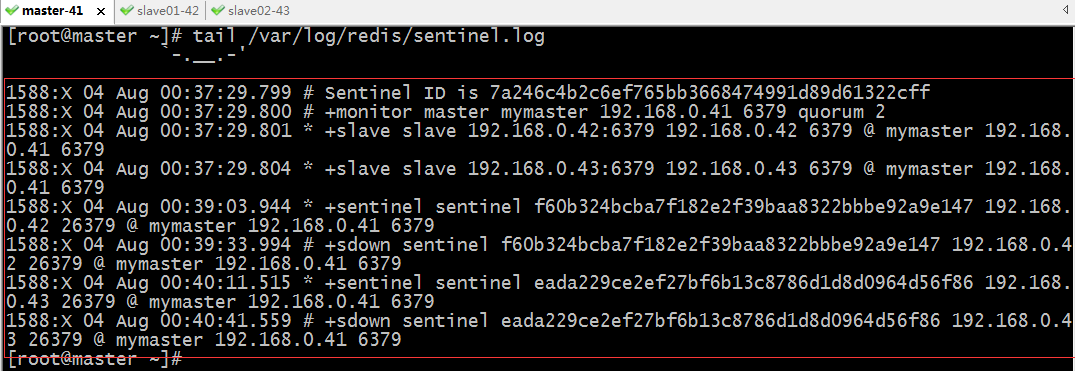
提示:從上面的日誌資訊可以瞭解到sentinel監控的master是192.168.0.41:6379;並且有兩個slave分別是192.168.0.42:6379和192.168.0.43:6379;
檢視sentinel狀態

提示:它提示我們開啟了保護模式;
關閉保護模式
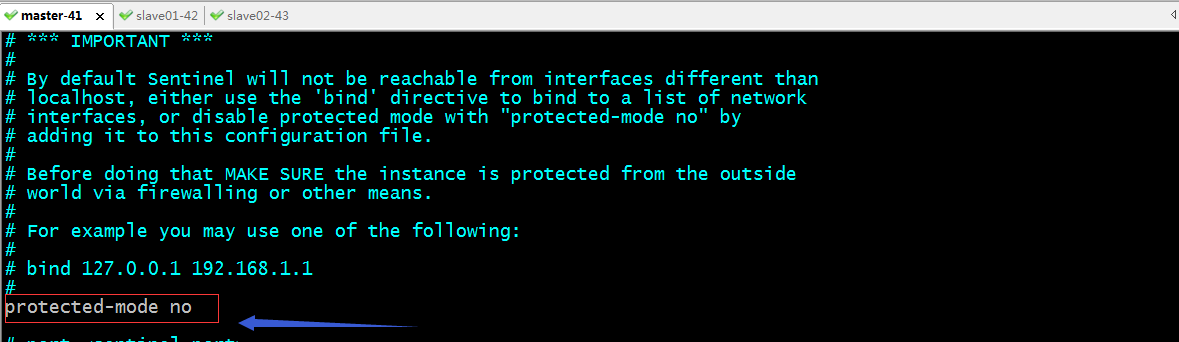
重啟sentinel,再次檢視sentinel狀態
[root@master ~]# systemctl restart redis-sentinel.service [root@master ~]# ss -tnl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 511 *:26379 *:* LISTEN 0 511 *:6379 *:* LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 511 :::26379 :::* LISTEN 0 128 :::22 :::* LISTEN 0 100 ::1:25 :::* [root@master ~]# redis-cli -h 192.168.0.41 -p 26379 192.168.0.41:26379> info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.0.41:6379,slaves=2,sentinels=3 192.168.0.41:26379> info clients # Clients connected_clients:3 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0 192.168.0.41:26379> CLIENT LIST id=2 addr=192.168.0.42:59048 fd=14 name=sentinel-f60b324b-cmd age=38 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=ping id=3 addr=192.168.0.43:37480 fd=15 name=sentinel-eada229c-cmd age=38 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=publish id=4 addr=192.168.0.41:36706 fd=16 name= age=32 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client 192.168.0.41:26379>
提示:從上面的狀態資訊可以看到當前sentinel監控的master是出於正常ok狀態,有兩個slave和3個sentinel;對於192.168.0.41:26379目前有3個客戶端連線,二個是sentinel,一個本機;到此3臺sentinel搭建啟動完成;
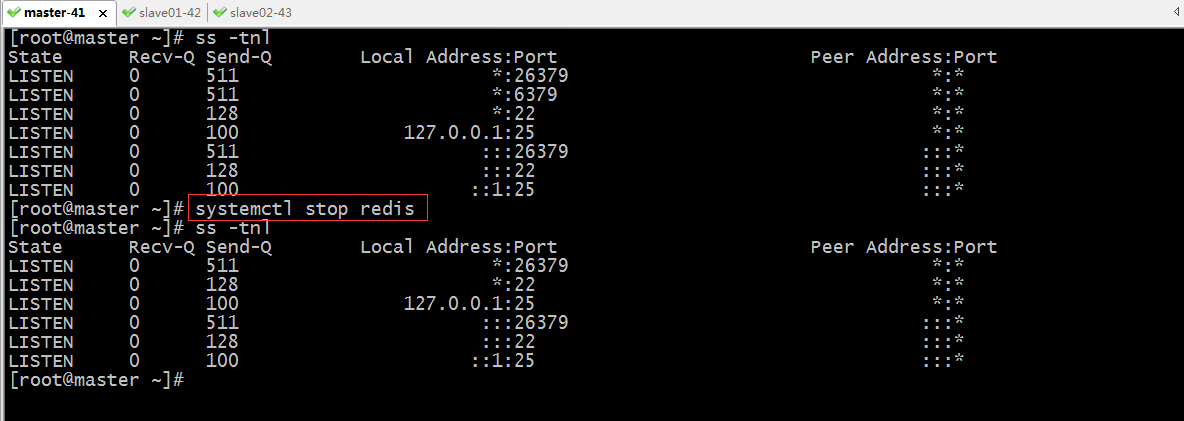
驗證:把master宕機,看看sentinel是否將在兩個從節點選舉一個為新master?是否將另外一個slave重新指向新master?
在slave01上檢視主從同步資訊
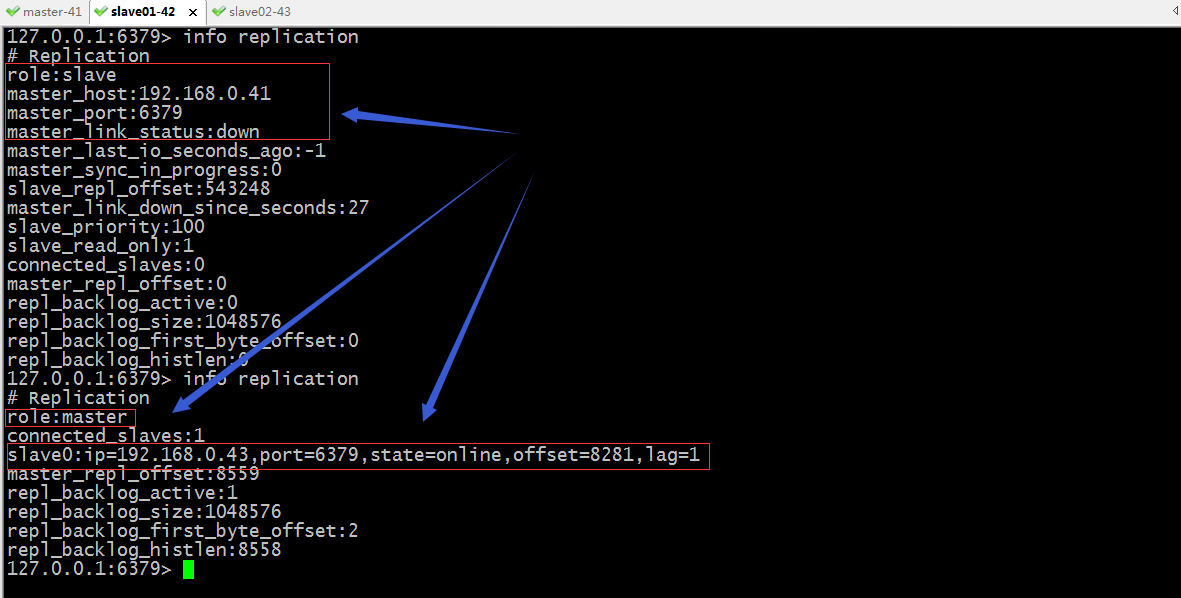
提示:第一次檢視只是告訴我們master宕機了,第二次檢視就告訴我們當前節點為master,並且擁有一個slave節點,這說明已經完成了故障轉移,slave01已經被提升為新的master了;
在192.168.0.43上檢視主從資訊,看看是否指向新的master?

提示:在slave02上看主從同步資訊,可以看到slave02已經從屬新master了;
檢視故障轉移時 sentinel日誌

提示:從上面的日誌資訊可以瞭解到,在從sdown到odown後,就會觸發vote演算法開始選舉leader;然後將原master降級為slave,然後將選舉出來的leader原salve屬性去除(slaveof no one);然後提升新master,然後將剩下的slave重新配置新master為主;最後是切換master,開始新的監控;
檢視故障 轉移後的 redis 配置檔案
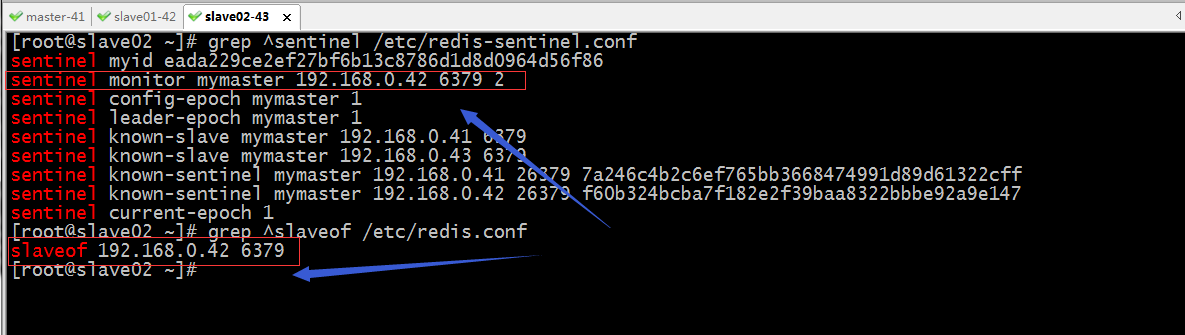
提示:故障轉移後 redis.conf 中的 slaveof 行的 master IP 會被修改,sentinel.conf 中的 sentinel monitor IP 會被修改。同時在sentinel配置檔案的末尾還會有新增known-slave和known-sentinel等資訊;
修復舊master 讓其重新上線
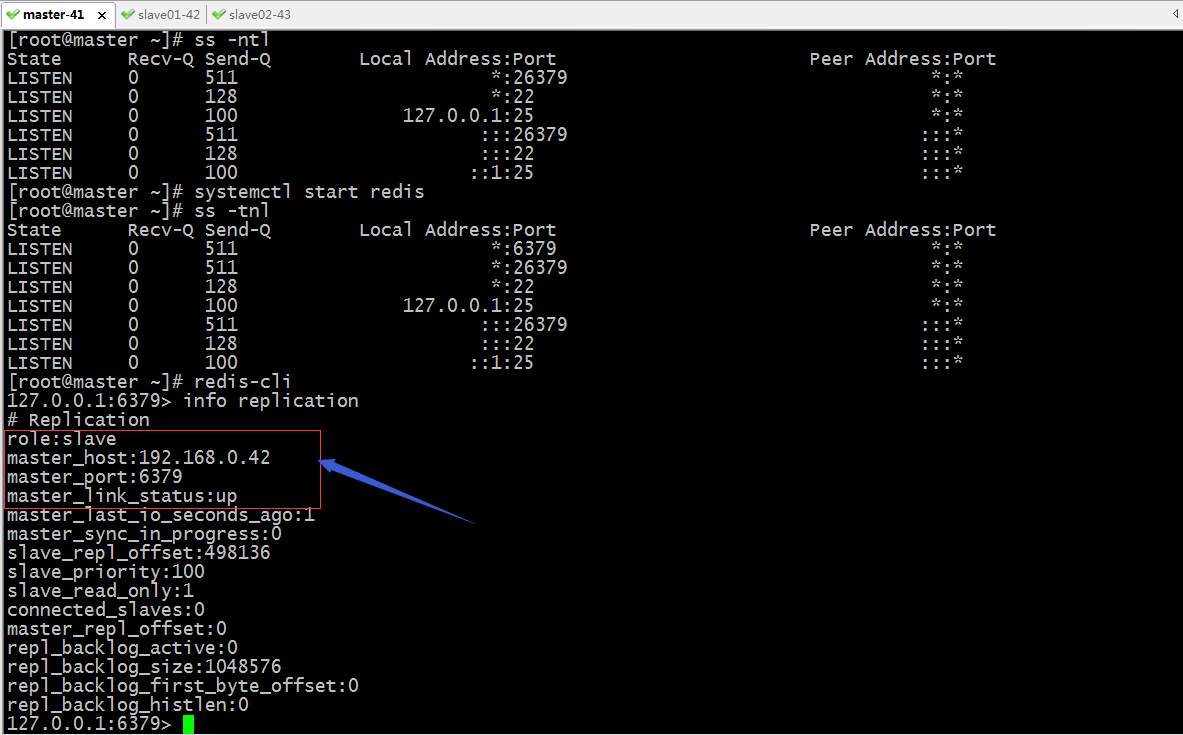
提示:把原master啟動後,它自動就成為了新主的slave;這主要是因為sentinel在故障轉移時把其配置檔案中的slaveof 修改成新的master地址了;
在新master上檢視主從同步資訊

提示:在沒有恢復原master時,在新master上檢視主從同步資訊,只能看到一個salve,啟動原master後,在看就有兩個slave是在