
Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems
本文(OSDI 18')主要介紹一種新的副本複製協議:SAUCR(場景可感知的更新與故障恢復)。它是一種混合的協議:
在一定場景(正常情況)下:副本複製的資料快取在記憶體中。
故障發生時(多個節點掛掉,處於系統無法正常執行的邊緣):副本複製的資料快取同步刷入磁碟。
該協議在保證高效能的同時,保證了很強的永續性和可用性。
Introduction
分散式儲存系統通常通過維護多個副本來進行容錯,這些協議都是基於Majority Based 複製協議進行的,例如raft,Paxos協議。這些Majority Based 複製協議也是leader-based 實現的。它們執行的時候有如下的特點:
- 這些節點組成的系統都每一時刻都會有一個leader去維護整個系統的執行。客戶端傳送更新請求到會發送到Leader進行響應處理。Leader收到更新請求,將這些請求打包成一個log,轉發給其他的follower。當leader收到多數節點日誌寫入完成的響應資訊後,就會執行更新操作(同時也指示副本節點執行相應的操作),回覆客戶端的請求。
- 每一個leader都會有一個epoch相關聯,且在每一個epoch期間只有一個leader。
- 每一條更新操作的日誌訊息中都會帶有一個log的索引號和epoch資訊。
- Leader通過心跳檢查follower是否正常。如果在一定的時間內follower長時間沒有收到心跳,就會懷疑leder掛掉了,就會重新發一起一次選舉,新的leader有epoll號。當選的leader必須滿足日誌完整性約束,即本節點種擁有系統所有已經commited的日誌資訊。
motivation
論文將傳統的複製協議分成了兩種型別:
Disk-durable :Leader將log同步到各個節點後,立即將日誌資料持久化到 disk 中,優點是,可用性好,可靠性好,但是由於每次要呼叫寫磁碟函式,資料持久化到磁碟中,資料複製的效能不好;因為一條log的確認需要半數以上的節點做出響應回覆,所以當宕機的節點個數超過一半時,整個分散式系統就無法運行了,當節點恢復後,執行的節點個數超過一半後,這個系統就會恢復過來。
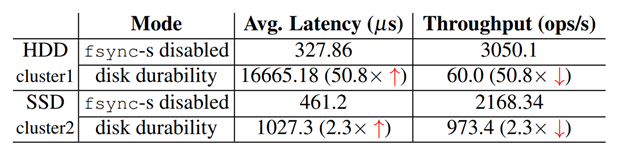
Memory-durable :將log儲存到記憶體中,啟動後臺程序非同步的將log持久到磁碟上,優點是,效能好。如下圖的對比:
但是該方法可靠性和可用性比較差,存在較大的丟失資料的風險。如下圖:五個節點,掛了三個節點的時候,資料都會丟失掉,後期三個節點恢復後,這三個節點會成為一個多數派,會從他們三個之中選出一個leader,這個leader會把正常的兩個節點的資料給覆蓋掉,造成資料的丟失。
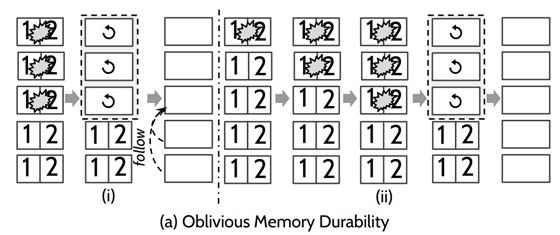
針對Memory-Durability在節點恢復時,丟失資料的節點可能會將正常節點資料給覆蓋掉的問題,有人提出了Loss-Aware Memory Durability協議。當節點從故障恢復時,把自己標記為recovering,表示自己不能參與Leader選舉(包括成為候選者和投票),向其他正在執行(不在recovering狀態)的節點發送一個訊息,拉取最新的資料(其它節點不能是recovering),並收到大多數節點的響應(必須包括Leader)。如下圖,該協議可以保證正常節點資料不被覆蓋。但是這個協議有一個問題就是如果多數節點都掛掉的話,系統會永遠無法執行。

這篇論文提出了一個分散式複製協SAUCR議在Disk-durable和Memory-durable之間切換,在保證系統性能的同時,也可以儘量保證資料不被丟失的風險。
SAUCR Overview
論文提出的方法基於一個假設:非同時性猜想,也就說多個副本節點同時宕機的可能性非常非常低。同時,極大部分情況下節點之間的宕機存在一定的時間差。作者從Google叢集中過去某一段時間的資料觀察到,每次隨機取5臺機器,觀察這些機器宕機間隔,99.9999%的故障事件,它們的時間差超過50ms。
這個協議不像raft協議一樣能保證很高的可用性,它也是有可能出現系統不可用的情況。如果多臺機器獨立的宕機或者相互之間有關聯,但多數節點不會同時掛機,以一定時間間隔的掛機的情況,這個協議是可以保證資料正確的,可以實現log的持久化。針對同時發生的宕機的問題,會分為兩種情況:
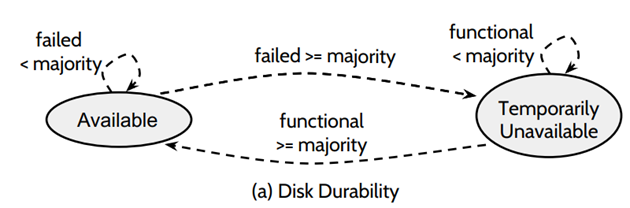
第一種是宕機節點的個數等於半數⌈n/2⌉,是可以保證資料不會丟失。
第二種是宕機的節點個數超過大多數(1/5, 4/6)同時掛掉,不能保證資料的永續性,整個系統都不可用。
SAUCR content
基於leader base的選舉協議 和raft協議類似,有選舉的過程。執行這個協議的系統有兩種模式:Fast mode和Slow mode
Fast Mode 和memorydurablity類似,所有的更新都會被快取到大部分節點的記憶體當中,就可以確認這筆交易,更新的log非同步的刷到磁碟上。並不會同步的等大多數節點都刷到磁碟之後才去確認。一個請求被commit的條件比原來的raft協議要嚴格一點,要求leader收到⌈n/2⌉ + 1個節點的確認回覆,這筆交易才算成功(4/ 5)。因此,系統要在Fast Mode 下執行,正常執行的節點個數必然要大於等於n/2+1個節點,這樣才可以處理使用者的請求。
Slow Mode 慢模式和raft協議很類似,節點收到更新請求後,會將log同步的刷到磁碟,leader提交一條資料更新的要求就是收到大多數節點的完成資料持久化操作的響應。(3/5)
SAUCR:Failure Reaction
Follower宕機
Leader會通過傳送心跳訊號檢測follower是否正常,如果丟失了心跳訊號,leader就會懷疑follower掛掉了。 如果Leader檢測到系統中執行的節點個數只有半數(3/5),整個系統就會馬上切換到slow-mode。從慢速模式切換到快速模式(檢測到系統中執行的節點個數多餘半數(4/5)),需要等待一定的時間,比如多個心跳,才會切換回快速模式。
Leader宕機
Follower通過心跳發現leader掛掉之後(有可能leader並沒有掛掉,只是心跳訊號來的晚),follower會立即將記憶體中的資料都落盤。資料落盤的時間和開始選舉的時間是沒有關聯的,follower在一段時間內如果沒有收到來自leader的心跳,從follower切換到候選者。而資料刷盤的時間是當Follower沒有收到Leader的一兩次心跳就會促發落盤機制。
SAUCR:Enabling Safe Mode-Aware Recovery
宕機恢復策略:SAUCR 在不同的 mode 下,恢復的策略和方法是不一樣的,那麼 crash 重啟開始恢復的節點,首先需要知道自己之前處在一個什麼 mode 下。
在 fast mode 下,節點在處理第一個操作的時候,會同時持久化一個 fast-switch-entry 到 disk 中,這個 entry 是當前的 (epoch,log-index)。
在Slow mode下,在切換到 slow mode 的時候,會刷 memory buffer 到盤中,同時也會刷 latest-on-disk-entry 到盤中,這個 entry 也是一個 (epoch,log-index)。
如果節點重啟,發現 fast-switch-entry 在前面,則說明 crash 的時候,節點處於 fast mode,相反,如果 latest-on-disk-entry 在前面,說明節點 crash 的時候,節點處在 slow mode。
LLE Map是一個儲存了目前系統正在執行時,所有節點所處在的epoch時期,以及節對應節點目前最新的log_entry index.(就是正在複製的 log entry index,而不是已經成功複製的 log entry index,這樣是為了保證 crash 起來的節點獲取到的 LLE 一定是包含已經 commit 的 log 的,這樣才不會出現數據丟失。)
節點在選舉的時候,會根據這個LLE Map中epoch和log-index來做判斷。每次leader向follow傳送心跳的時候都會帶上這個LLE map資訊,在 fast mode 的時候,LLE map 寫在記憶體中,所以節點宕機恢復得時候,就會丟失掉所有得LLE資訊,因此論文提出了一種Max-Among-Minority的演算法來恢復LLE,將在後文做介紹。而在 slow mode 的時候 LLE Map 寫在 disk,只需從磁碟恢復就可以了。
宕機恢復的主要步驟:
1. 從磁碟中恢復 (last logged entry )LLE,實際上就是知道自己到底擁有多少日誌
在慢模式下,這個LLE是持久化到磁碟上的,直接可以從磁碟讀取資料。
在快模式下,磁碟中讀不到最新得log entry,會執行一個Max-Among-Minority 演算法獲取自己的LLE
2. 等待並參加下一次選舉,通過選舉來判斷哪個節點的LLE是最新的(主節點)。
3. 從主節點去複製資料。
Max-Among-Minority
1. 首先待恢復節點將自己標記狀態為recovering,
2. 向其它節點獲取自己的LLE
3. 其它節點若是正常執行的節點或者已經恢復的節點,則返回響應,否則忽略請求 (2/5)
4. 待恢復節點要收到⌈n/2⌉−1個節點回復LLE,並選擇最大的最大得值作為自己要恢復的LLE。
為什麼⌈n/2⌉−1個訊息是安全的?
L`表示通過Max-Among-Minority 恢復的LLE值, L表示當掉的時候機器記憶體中存在的真實的LLE。
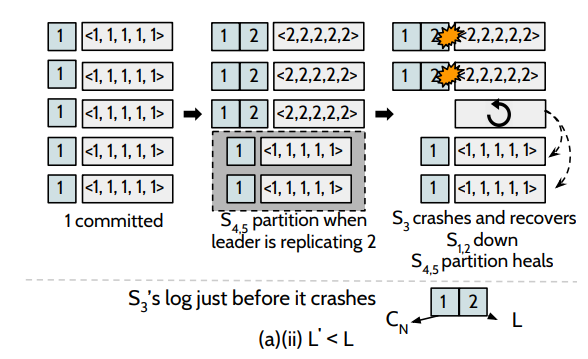
若L`大於L的情況下,如圖:初始時刻,系統已經成功提交了第1條日誌,此時,leader正打算複製第2條日誌到其他節點的時候,S3掛掉了(L = 1),但此時系統中仍然存在四個節點,這個更新操作是可以被提交,在S3恢復的過程中, S2和S4也掛掉了,這個時候,⌈n/2⌉-1 = 2,S3可以收到S1和S5的LLE,去恢復自己的資料,可以保證資料的安全性。
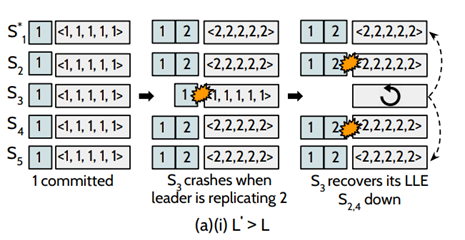
若L`小於L的情況下,假設這個恢復的節點為 N,其 log 是 D, Cn 為 D 最後一條被 committed 的 log entry。 L 為 actual last-logged entry (LLE),L' 為通過 max-among-minority algorithm 恢復的 LLE,如果能證明 L' ≥ Cn,那麼就不會出現丟失資料。反證法證明 L' <Cn是不可能產生的:
假設五個節點的情況下,在 fast mode 情況下,由於一個 entry 的提交是需要 bare majority + 1,也就是 4 個副本複製成功,那麼必定和 bare mniority,也就是 2 個副本有交集,4+2 > 5,那麼意味著要麼 Cn 不可能提交,從而與假設矛盾;如圖,假設某種情況下存在下圖的中間狀態,L = 2 D = {1, 2} Cn = {1, 2}? L' = 1。可知Cn必定是錯誤的。只能是Cn={1}。
SAUCR:Summary
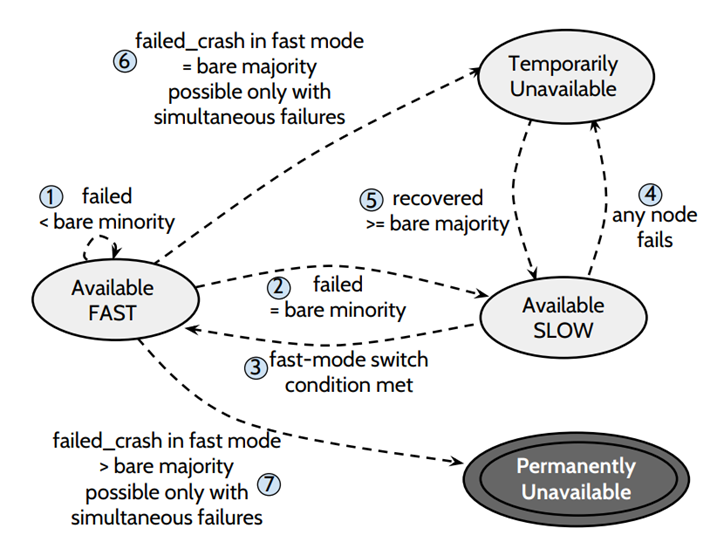
(1)離線節點的個數 < bare minotiry (5箇中當掉1個) ,叢集處於 fast mode,可用
(2)離線節點個數 = bare minority 節點離線 (5箇中宕掉2個),叢集處於 slow mode,可用
(3)有節點恢復,又回到 < bare minority 節點離線,叢集處於 fast mode,可用
(4)在 slow 狀態下,出現任意數量的節點離線,叢集都將處於不可用的狀態
(5)恢復到 >= bare majority 個節點線上,進去 slow mode,可用
(6)當有 =bare majority 個節點同時離線,將會造成 Temporarily unavailable,為什麼是臨時的不可用,因為,其他節點加入或者恢復,叢集還可以進入可用狀態
(7)如果在 fast mode 下,> bare majority 個節點同時離線,那麼叢集將處於 Permanently unavailable,因為 recovery 至少收到 bare minority 個節點的 response,所以即使通過配置變更加節點或者 crash 節點 recovery 也都不好使了。一般這種時候需要人工介入。
Evaluation
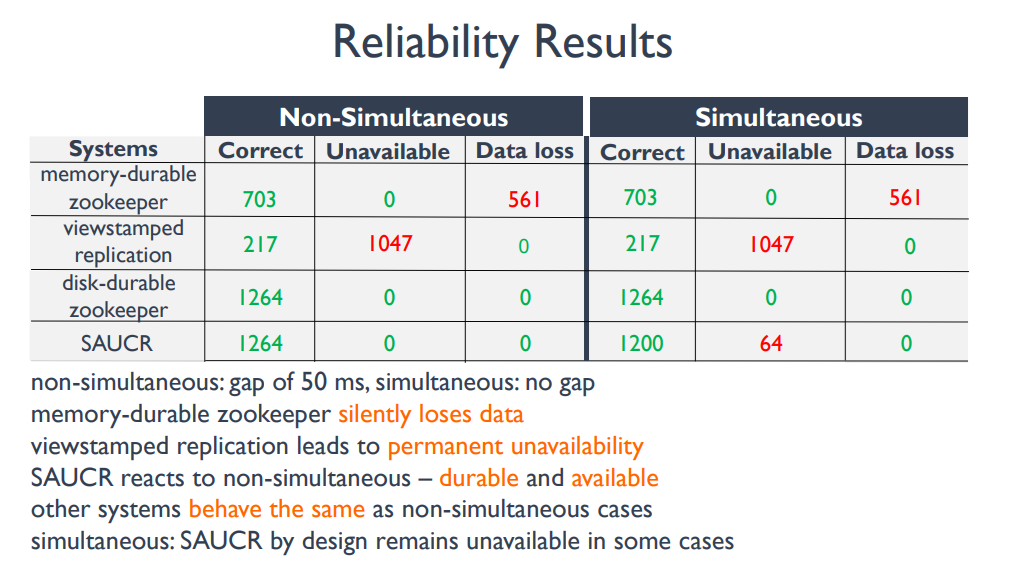
如下圖,SAUCR 在非 NSC 的猜想前提下,可用性和可靠性都沒有降低;而且即使考慮 SC 的情況,也只是可用性降低了一些,但是資料可靠性並沒有降低。
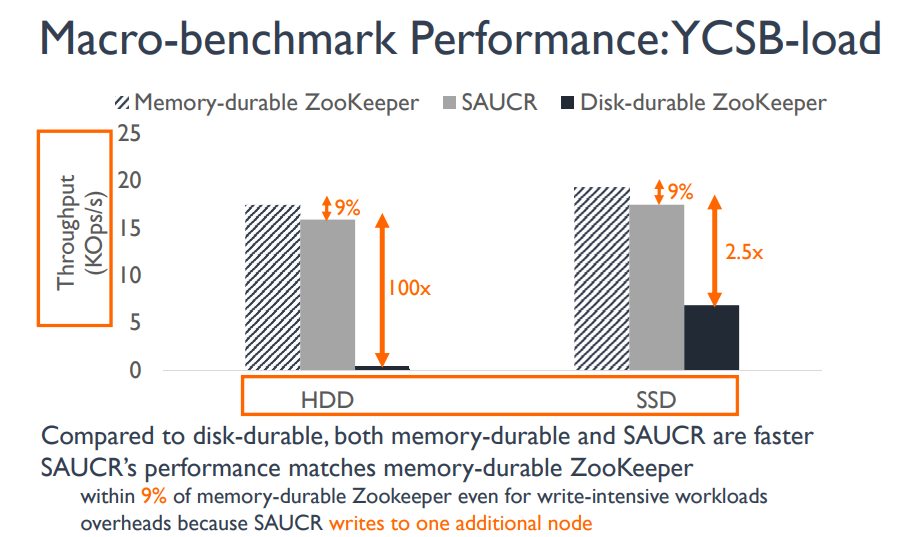
SAUCR還可以保持一個很好的效能(雖然是在快模式下測試的)
Summary

相關推薦
Fault-Tolerance, Fast and Slow: Exploiting Failure Asynchrony in Distributed Systems
本文(OSDI 18')主要介紹一種新的副本複製協議:SAUCR(場景可感知的更新與故障恢復)。它是一種混合的協議: 在一定場景(正常情況)下:副本複製的資料
軟體測試基礎——fault、error and failure
*************軟體測試基礎************* 首先解釋一下fault、error以及failure的各自定義: Fault: 可能導致系統或功能失效的異常條件(Abnormal condition that can cause
fault tolerance中的錯誤和故障檢測(Error and Fault Detection Mechanisms)
這裡的介紹來自論文Survey of Error and Fault Detection Mechanisms: 下面這張圖來自論文,反映了當今關於錯誤檢測機制(Error Detection Mec
Building Microservices with Spring Cloud - Fault tolerance Circuit breaker
tps blog logs single pri ros ces nts bre ref: https://cloud.spring.io/spring-cloud-netflix/single/spring-cloud-netflix.html#_circuit_bre
軟體測試的幾個術語(故障--Fault、錯誤--Error、失效--Failure)
1.解釋 Fault--故障 編碼過程中,存在於軟體中的靜態缺陷 (Defect) Error--錯誤 軟體執行過程中,執行fault後,觸發得到的結果(錯誤)。 Failure--失效 失效。error傳到軟體外部,使用者和測試人員能夠觀測的到的失效行為。
QEMU, a Fast and Portable Dynamic Translator-Fabrice Bellard-翻譯
Abstract We present the internals of QEMU, a fast machine emulator using an original portable dynamic translator. It emulates several CPUs (x86,
Optical Flow Guided Feature A Fast and Robust Motion Representation for Video Action Recognition論文解讀
Optical Flow Guided Feature A Fast and Robust Motion Representation for Video Action Recognition論文解讀 1. Abstract 2. 論文解讀 3
Fast and accurate object detection in high resolution 4K and 8K video using GPUs 論文筆記
文章目錄 一、基本資訊 二、研究背景 三、創新點 3.1 概述 3.2 詳解 3.2.1 問題分析 3.2.2 Attention pipeline 3.2.3 Implementation
LiveScan3D: A Fast and Inexpensive 3D Data Acquisition System for Multiple Kinect v2 Sensors
LiveScan3D:用於多個Kinect v2感測器的快速、低成本的3D資料採集系統 文章翻譯 引言:我們提出了一種利用多個Kinect v2感測器進行實時3D採集的方法。與使用單個感測器的方法不同,比如[1],我們可以同時記錄多個視點的動態場景。 我
閱讀筆記——《FFDNet Toward a Fast and Flexible Solution for CNN based Image Denoising》
本博文屬於閱讀筆記,僅供本人學習理解用 論文連結:https://ieeexplore.ieee.org/abstract/document/8365806 給出程式碼(https://github.com/cszn/FFDNet) Many methods mos
Building Fast and Compact Convolutional Neural Networks for Offline HCCR
--pattern recognition 2017 摘要: 像其他的計算機視覺技術一樣,離線的手寫文字識別使用CNN方法取得了很好的效果。但是需要非常複雜的網路才可以取得較好的效果。這樣的網路直觀地看起來計算成本過高,並且需要儲存大量引數,這使得它們在行動式裝置中部署
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition 翻譯
光流引導特徵:視訊動作識別的快速魯棒運動表示
Byzantine Fault Tolerance in a nutshell
Byzantine Fault Tolerance in a nutshellWhen you start to get more into blockchain, one term that you’re going to hear a lot is Byzantine Fault Tolerance.No
Move Fast and Break Things is Not Dead
Move Fast and Break Things is Not DeadMove Fast, Fix Shit, and Learn FasterThe first poster printed in the Facebook Analog Research Laboratory said “Done i
Exploiting GPS and the fixes we face in the future
For decades, we’ve taken GPS for granted. And sometimes we still need a second opinion to get to where we’re going. Navigation has always been a noble if o
拜占庭共識演算法PBFT:Practical Byzantine Fault Tolerance
論文地址:http://pmg.csail.mit.edu/papers/osdi99.pdf PBFT是Practical Byzantine Fault Tolerance的縮寫,意為實用拜占庭容錯演算法。該演算法是Miguel Castro (卡斯特羅)和Barbara Liskov(
拜占庭共識演算法RBFT:Redundant Byzantine Fault Tolerance
最近在研究拜占庭共識,做個記錄吧,有些可能也沒理解透。 RBFT : Redundant Byzantine Fault Tolerance 論文地址:http://lig-membres.imag.fr/aublin/rbft/report.pdf 摘要: 提出其他已有的BFT演算
【文章閱讀】【超解像】-Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Network
【文章閱讀】【超解像】–Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Network 論文連結:https://arxiv.org/abs/1710.01992 專案主頁:http://vll
【文章閱讀】【超解像】---Deep laplacian Pyramid Networks for Fast and Accurate Super-Resolution
【文章閱讀】【超解像】–Deep laplacian Pyramid Networks for Fast and Accurate Super-Resolution 期刊論文CVPR2017連結:http://vllab.ucmerced.edu/wlai24/LapSRN/papers
讀書筆記22:Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recogni
文章題目:Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition(CVPR2018) 摘要部分:開頭一句話指出motion rep