
強化學習 3—— 使用蒙特卡洛取樣法(MC)解決無模型預測與控制問題
阿新 • • 發佈:2020-08-10
## 一、問題引入
回顧上篇[強化學習 2 —— 用動態規劃求解 MDP](https://blog.csdn.net/november_chopin/article/details/107896549)我們使用策略迭代和價值迭代來求解MDP問題
#### 1、策略迭代過程:
- 1、評估價值 (Evaluate)
$$
v_{i}(s) = \sum_{a\in A} \pi(a|s) \left( {\color{red}R(s, a)} + \gamma \sum_{s' \in S} {\color{red}P(s'|s, a)} \cdot v_{i-1}(s') \right)
$$
- 2、改進策略(Improve)
$$
q_i(s,a) = {\color{red}R(s, a)} + \gamma \sum_{s' \in S} {\color{red}P_{(s'|s,a)}} \cdot v_i(s') \\
\pi_{i+1}(s) = argmax_a \; q^{\pi_i}(s,a)
$$
#### 2、價值迭代過程:
$$
v_{i+1}(s) \leftarrow max_{a \in A} \; \left({\color{red}R(s, a)} + \gamma \sum_{s' \in S} {\color{red}P_{(s'|s,a)}} \cdot V_i(s')\right)
$$
然後提取最優策略 $ \pi $
$$
\pi^*(s) \leftarrow argmax_a \; \left({\color{red}R(s, a)} + \gamma \sum_{s' \in S} {\color{red}P_{(s'|s,a)}} \cdot V_{end}(s')\right)
$$
可以發現,對於這兩個演算法,有一個前提條件是獎勵 R 和狀態轉移矩陣 P 我們是知道的,因此我們可以使用策略迭代和價值迭代演算法。對於這種情況我們叫做 `Model base`。同理可知,如果我們不知道環境中的獎勵和狀態轉移矩陣,我們叫做 `Model free`。
不過有很多強化學習問題,我們沒有辦法事先得到模型狀態轉化概率矩陣 P,這時如果仍然需要我們求解強化學習問題,那麼這就是不基於模型(Model Free)的強化學習問題了。
其實稍作思考,大部分的環境都是 屬於 Model Free 型別的,比如 熟悉的雅達利遊戲等等。另外動態規劃還有一個問題:需要在每一次回溯更新某一個狀態的價值時,回溯到該狀態的所有可能的後續狀態。導致對於複雜問題計算量很大。
------
所以,我們本次探討**在 Model Free 情況下的策略評估**方法,策略控制部分留到下篇討論。對於 Model Free 型別的強化學習模型如下如所示:
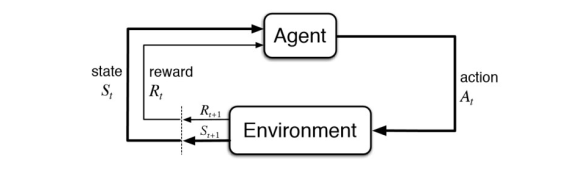
此時需要智慧體直接和環境進行互動,環境根據智慧體的動作返回下一個狀態和相應的獎勵給智慧體。這時候就需要智慧體蒐集和環境互動的軌跡(Trajectory / episode)。
對於 Model Free 情況下的 策略評估,我們介紹兩種取樣方法。蒙特卡洛取樣法(Monte Carlo)和時序差分法(Temporal Difference)
## 二、蒙特卡洛取樣法(MC)
對於Model Free 我們不知道 獎勵 R 和狀態轉移矩陣,那應該怎麼辦呢?很自然的,我們就想到,讓智慧體和環境多次互動,我們通過這種方法獲取大量的軌跡資訊,然後根據這些軌跡資訊來估計真實的 R 和 P。這就是蒙特卡洛取樣的思想。
蒙特卡羅法通過取樣若干經歷完整的狀態序列(Trajectory / episode)來估計狀態的真實價值。所謂的經歷完整,就是這個序列必須是達到終點的。比如下棋問題分出輸贏,駕車問題成功到達終點或者失敗。有了很多組這樣經歷完整的狀態序列,我們就可以來近似的估計狀態價值,進而求解預測和控制問題了。
### 1、MC 解決預測問題
一個給定策略 $\pi$ 的完整有 T 個狀態的狀態序列如下
$$
\{S_1, A_1, R_1, S_2, A_2, R_2, \cdots,S_T, A_T, R_T\}
$$
在馬爾科夫決策(MDP)過程中,我們對價值函式 $v_\pi(s)$ 的定義:
$$
v_\pi(s) = E_\pi[G_t|S_t = s] = E_\pi[R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} | S_t = s]
$$
可以看出每個狀態的價值函式等於所有該狀態收穫的期望,同時這個收穫是通過後續的獎勵與對應的衰減乘積求和得到。那麼對於蒙特卡羅法來說,如果要求某一個狀態的狀態價值,只需要求出所有的完整序列中該狀態出現時候的收穫再取平均值即可近似求解,也就是:
$$
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3}+\cdots \gamma^{T-t-1}R_T
$$
$$
v_\pi(s) \approx average(G_t) \quad s.t.\; S_t = s
$$
上面預測問題的求解公式裡,我們有一個average的公式,意味著要儲存所有該狀態的收穫值之和最後取平均。這樣浪費了太多的儲存空間。一個較好的方法是在迭代計算收穫均值,即每次儲存上一輪迭代得到的收穫均值與次數,當計算得到當前輪的收穫時,即可計算當前輪收穫均值和次數。可以通過下面的公式理解:
$$
\mu_t = \frac{1}{t}\sum_{j=1}^tx_j = \frac{1}{t}\left( x_t + \sum_{j=1}^{t-1}x_j \right) = \frac{1}{t}\left( x_t + (t-1)\mu_{t-1} \right) \\
\Downarrow \\
\mu_t = = \mu_{t-1} + \frac{1}{t}(x_t-\mu_{t-1})
$$
這樣上面的狀態價值公式就可以改寫成:
$$
N(S_t) \leftarrow N(S_t) + 1 \\
v(S_t) \leftarrow v(S_t) + \frac{1}{N(S_t)}(G_t-v(S_t))
$$
這樣我們無論資料量是多還是少,演算法需要的記憶體基本是固定的 。我們可以把上面式子中 $\frac{1}{N(S_t)}$ 看做一個超引數 $\alpha$ ,可以代表學習率。
$$
v(S_t) \leftarrow v(S_t) + \alpha(G_t-v(S_t))
$$
對於動作價值函式$Q(S_t, A_t)$, 類似的有:
$$
Q(S_t, A_t) = Q(S_t, A_t) + \alpha(G_t - Q(S_t, A_t))
$$
### 2、MC 解決控制問題
MC 求解控制問題的思路和動態規劃策略迭代思路類似。在動態規劃策略迭代演算法中,每輪迭代先做策略評估,計算出價值 $v_k(s)$ ,然後根據一定的方法(比如貪心法)更新當前 策略 $\pi$ 。最後得到最優價值函式 $v_*$ 和最優策略$\pi_*$ 。在文章開始處有公式,還請自行檢視。
對於蒙特卡洛演算法策略評估時一般時優化的動作價值函式 $q_*$,而不是狀態價值函式 $v_*$ 。所以評估方法是:
$$
Q(S_t, A_t) = Q(S_t, A_t) + \alpha(G_t - Q(S_t, A_t))
$$
蒙特卡洛還有一個不同是一般採用$\epsilon - 貪婪法$更新。$\epsilon -貪婪法$通過設定一個較小的 $\epsilon$ 值,使用 $1-\epsilon$ 的概率貪婪的選擇目前認為有最大行為價值的行為,而 $\epsilon$ 的概率隨機的從所有 m 個可選行為中選擇,具體公式如下:
$$
\pi(a|s) =
\begin{cases}
\epsilon/|A| + 1 - \epsilon, & \text{if $a^* = argmax_a \; q(s,a)$} \\
\epsilon/|A|, & \text{otherwise}
\end{cases}
$$
在實際求解控制問題時,為了使演算法可以收斂,一般 $\epsilon$ 會隨著演算法的迭代過程逐漸減小,並趨於0。這樣在迭代前期,我們鼓勵探索,而在後期,由於我們有了足夠的探索量,開始趨於保守,以貪婪為主,使演算法可以穩定收斂。
Monte Carlo with $\epsilon - Greedy$ Exploration 演算法如下:

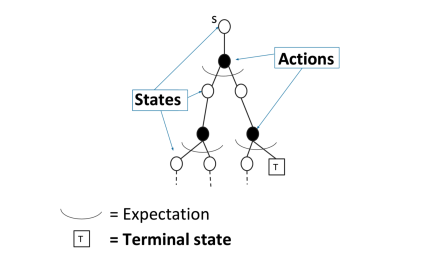
### 3、在 策略評估問題中 MC 和 DP 的不同
**對於動態規劃(DP)求解**
通過 `bootstrapping`上個時刻次評估的價值函式 $v_{i-1}$ 來求解當前時刻的 價值函式 $v_i$ 。通過貝爾曼等式來實現:
$$
V_{t+1}(s) = \sum_{a \in A}\pi(a|s) \left(R(s, a) + \gamma \sum_{s' \in S} P_{(s'|s, a)} \cdot V_t(s')\right)
$$
**對於蒙特卡洛(MC)取樣**
MC通過一個取樣軌跡來更新平均價值
$$
v(S_t) \leftarrow v(S_t) + \alpha(G_t-v(S_t))
$$
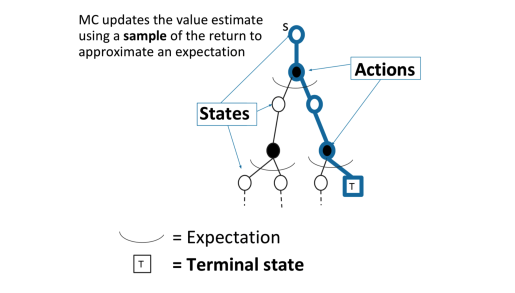
MC可以避免動態規劃求解過於複雜,同時還可以不事先知道獎勵和裝填轉移矩陣,因此可以用於海量資料和複雜模型。但是它也有自己的缺點,這就是它每次取樣都需要一個完整的狀態序列。如果我們沒有完整的狀態序列,或者很難拿到較多的完整的狀態序列,這時候蒙特卡羅法就不太好用了。如何解決這個問題呢,就是下節要講的時序差分法(TD)。
如果覺得文章寫的不錯,還請各位看官老爺點贊收藏加關注啊,小弟再此謝謝啦
**參考資料:**
B 站 [周老師的強化學習綱要第三節上](https://www.bilibili.com/video/BV1N74