
面試中的老大難-mysql事務和鎖,一次性講清楚!
阿新 • • 發佈:2020-08-13
眾所周知,`事務和鎖`是mysql中非常重要功能,同時也是面試的重點和難點。本文會詳細介紹`事務和鎖`的相關概念及其實現原理,相信大家看完之後,一定會對`事務和鎖`有更加深入的理解。
> 本文主要內容是根據掘金小冊《從根兒上理解 MySQL》整理而來。如想詳細瞭解,建議購買掘金小冊閱讀。
## 什麼是事務
在維基百科中,對事務的定義是:**事務是資料庫管理系統(DBMS)執行過程中的一個邏輯單位,由一個有限的資料庫操作序列構成**。
### 事務的四大特性
事務包含四大特性,即**原子性(Atomicity)**、**一致性(Consistency)**、**隔離性(Isolation)**和**永續性(Durability)**(ACID)。
1. 原子性(Atomicity)
**原子性是指對資料庫的一系列操作,要麼全部成功,要麼全部失敗,不可能出現部分成功的情況**。以轉賬場景為例,一個賬戶的餘額減少,另一個賬戶的餘額增加,這兩個操作一定是同時成功或者同時失敗的。
2. 一致性(Consistency)
**一致性是指資料庫的完整性約束沒有被破壞,在事務執行前後都是合法的資料狀態**。這裡的一致可以表示資料庫自身的約束沒有被破壞,比如某些欄位的唯一性約束、欄位長度約束等等;還可以表示各種實際場景下的業務約束,比如上面轉賬操作,一個賬戶減少的金額和另一個賬戶增加的金額一定是一樣的。
3. 隔離性(Isolation)
**隔離性指的是多個事務彼此之間是完全隔離、互不干擾的**。隔離性的最終目的也是為了保證一致性。
4. 永續性(Durability)
**永續性是指只要事務提交成功,那麼對資料庫做的修改就被永久儲存下來了,不可能因為任何原因再回到原來的狀態**。
### 事務的狀態
根據事務所處的不同階段,事務大致可以分為以下5個狀態:
1. 活動的(active)
當事務對應的資料庫操作正在執行過程中,則該事務處於`活動`狀態。
2. 部分提交的(partially committed)
當事務中的最後一個操作執行完成,但還未將變更重新整理到磁碟時,則該事務處於`部分提交`狀態。
3. 失敗的(failed)
當事務處於`活動`或者`部分提交`狀態時,由於某些錯誤導致事務無法繼續執行,則事務處於`失敗`狀態。
4. 中止的(aborted)
當事務處於`失敗`狀態,且回滾操作執行完畢,資料恢復到事務執行之前的狀態時,則該事務處於`中止`狀態。
5. 提交的(committed)
當事務處於`部分提交`狀態,並且將修改過的資料都同步到磁碟之後,此時該事務處於`提交`狀態。

### 事務隔離級別
前面提到過,事務必須具有隔離性。實現隔離性最簡單的方式就是不允許事務併發,每個事務都排隊執行,但是這種方式效能實在太差了。為了兼顧事務的隔離性和效能,事務支援不同的隔離級別。
為了方便表述後續的內容,我們先建一張示例表`hero`。
```sql
CREATE TABLE hero (
number INT,
name VARCHAR(100),
country varchar(100),
PRIMARY KEY (number)
) Engine=InnoDB CHARSET=utf8;
```
#### 事務併發執行遇到的問題
在事務併發執行時,如果不進行任何控制,可能會出現以下4類問題:
- 髒寫(Dirty Write)
**髒寫是指一個事務修改了其它事務未提交的資料**。

如上圖,`Session A`和`Session B`各開啟了一個事務,`Session B`中的事務先將`number`列為1的記錄的`name`列更新為'關羽',然後`Session A`中的事務接著又把這條`number`列為1的記錄的`name`列更新為張飛。如果之後`Session B`中的事務進行了回滾,那麼`Session A`中的更新也將不復存在,這種現象就稱之為**髒寫**。
- 髒讀(Dirty Read)
**髒讀是指一個事務讀到了其它事務未提交的資料**。
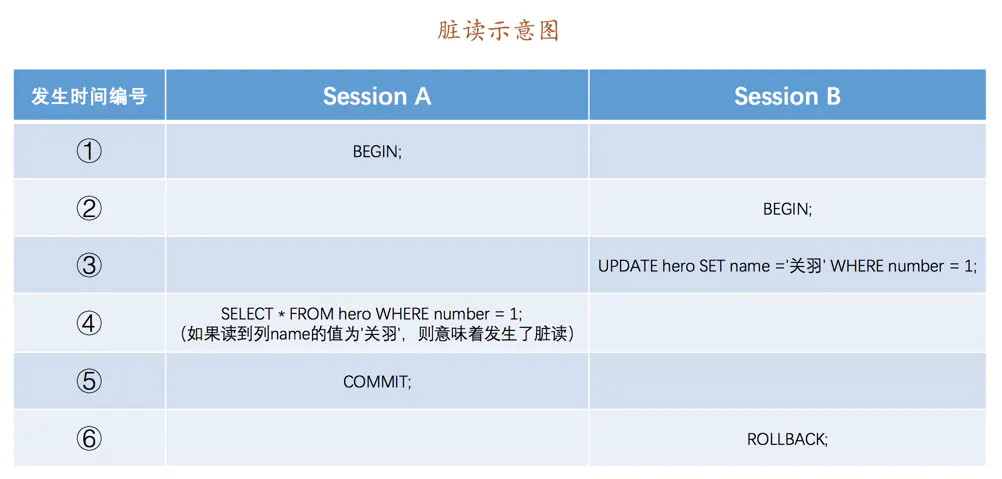
如上圖,`Session A`和`Session B`各開啟了一個事務,`Session B`中的事務先將`number`列為1的記錄的`name`列更新為`'關羽'`,然後`Session A`中的事務再去查詢這條`number`為1的記錄,如果讀到列`name`的值為`'關羽'`,而`Session B`中的事務稍後進行了回滾,那麼`Session A`中的事務相當於讀到了一個不存在的資料,這種現象就稱之為**髒讀**。
- 不可重複讀(Non-Repeatable Read)
**不可重複讀指的是在一個事務執行過程中,讀取到其它事務已提交的資料,導致兩次讀取的結果不一致**。

如上圖,我們在`Session B`中提交了幾個隱式事務(mysql會自動為增刪改語句加事務),這些事務都修改了`number`列為1的記錄的列`name`的值,每次事務提交之後,如果`Session A中`的事務都可以檢視到最新的值,這種現象也被稱之為**不可重複讀**。
- 幻讀(Phantom)
**幻讀是指的是在一個事務執行過程中,讀取到了其他事務新插入資料,導致兩次讀取的結果不一致**。

如上圖,`Session A`中的事務先根據條件`number > 0`這個條件查詢表`hero`,得到了`name`列值為`'劉備'`的記錄;之後`Session B`中提交了一個隱式事務,該事務向表`hero`中插入了一條新記錄;之後`Session A`中的事務再根據相同的條件`number > 0`查詢表`hero`,得到的結果集中包含`Session B`中的事務新插入的那條記錄,這種現象也被稱之為**幻讀**。
> 不可重複讀和幻讀的區別在於**不可重複讀是讀到的是其他事務修改或者刪除的資料,而幻讀讀到的是其它事務新插入的資料**。
髒寫的問題太嚴重了,任何隔離級別都必須避免。其它無論是髒讀,不可重複讀,還是幻讀,它們都屬於資料庫的讀一致性的問題,都是在一個事務裡面前後兩次讀取出現了不一致的情況。
#### 四種隔離級別
在`SQL`標準中設立了4種隔離級別,用來解決上面的讀一致性問題。不同的隔離級別可以解決不同的讀一致性問題。
- `READ UNCOMMITTED`:未提交讀。
- `READ COMMITTED`:已提交讀。
- `REPEATABLE READ`:可重複讀。
- `SERIALIZABLE`:序列化。
各個隔離級別下可能出現的讀一致性問題如下:
| 隔離級別 | 髒讀 | 不可重複讀 | 幻讀 |
| --- | --- | --- | --- |
| 未提交讀(READ UNCOMMITTED) | 可能 | 可能 | 可能 |
| 已提交讀(READ COMMITTED) | 不可能 | 可能 | 可能 |
| 可重複讀(REPEATABLE READ) | 不可能 | 不可能 | 可能(對InnoDB不可能) |
| 序列化(SERIALIZABLE) | 不可能 | 不可能 | 不可能 |
`InnoDB`支援四個隔離級別(和`SQL`標準定義的基本一致)。隔離級別越高,事務的併發度就越低。唯一的區別就在於,**`InnoDB` 在`可重複讀(REPEATABLE READ)`的級別就解決了幻讀的問題**。這也是`InnoDB`使用`可重複讀` 作為事務預設隔離級別的原因。
## MVCC
MVCC(Multi Version Concurrency Control),中文名是多版本併發控制,簡單來說就是通過維護資料歷史版本,從而解決併發訪問情況下的讀一致性問題。
### 版本鏈
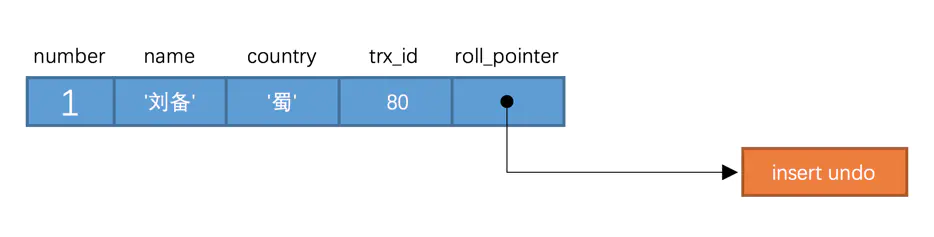
在`InnoDB`中,每行記錄實際上都包含了兩個隱藏欄位:事務id(`trx_id`)和回滾指標(`roll_pointer`)。
1. `trx_id`:事務id。每次修改某行記錄時,都會把該事務的事務id賦值給`trx_id`隱藏列。
2. `roll_pointer`:回滾指標。每次修改某行記錄時,都會把`undo`日誌地址賦值給`roll_pointer`隱藏列。
假設`hero`表中只有一行記錄,當時插入的事務id為80。此時,該條記錄的示例圖如下:
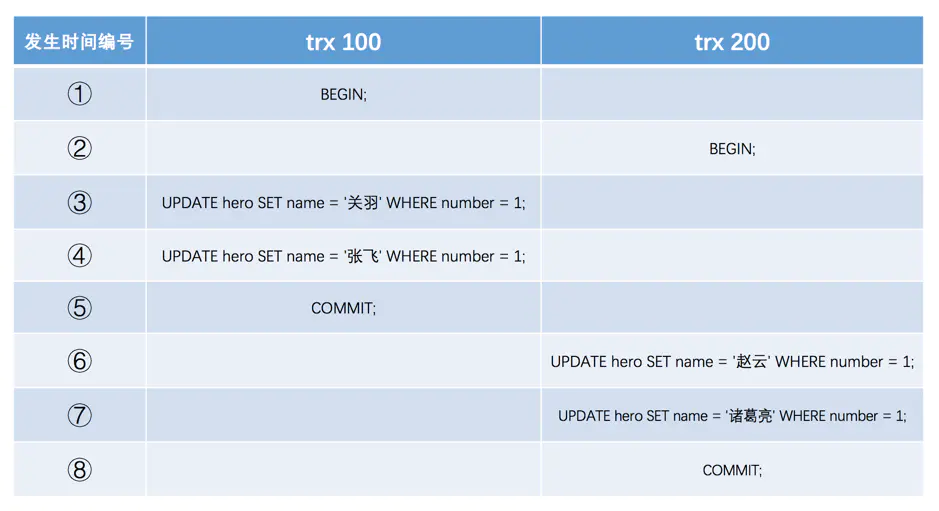
假設之後兩個事務`id`分別為`100`、`200`的事務對這條記錄進行`UPDATE`操作,操作流程如下:
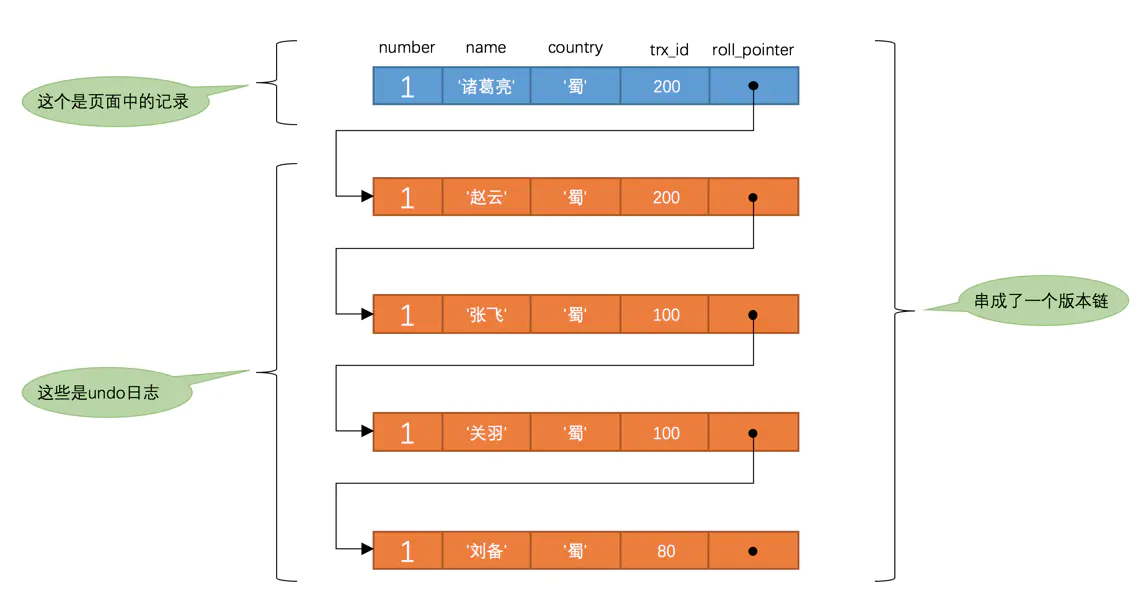
由於每次變動都會先把`undo`日誌記錄下來,並用`roll_pointer`指向`undo`日誌地址。因此可以認為,**對該條記錄的修改日誌串聯起來就形成了一個`版本鏈`,版本鏈的頭節點就是當前記錄最新的值**。如下:
### ReadView
如果資料庫隔離級別是`未提交讀(READ UNCOMMITTED)`,那麼讀取版本鏈中最新版本的記錄即可。如果是是`序列化(SERIALIZABLE)`,事務之間是加鎖執行的,不存在讀不一致的問題。**但是如果是`已提交讀(READ COMMITTED)`或者`可重複讀(REPEATABLE READ)`,就需要遍歷版本鏈中的每一條記錄,判斷該條記錄是否對當前事務可見,直到找到為止(遍歷完還沒找到就說明記錄不存在)**。`InnoDB`通過`ReadView`實現了這個功能。`ReadView`中主要包含以下4個內容:
- `m_ids`:表示在生成`ReadView`時當前系統中活躍的讀寫事務的事務id列表。
- `min_trx_id`:表示在生成`ReadView`時當前系統中活躍的讀寫事務中最小的事務id,也就是`m_ids`中的最小值。
- `max_trx_id`:表示生成`ReadView`時系統中應該分配給**下一個事務的id值**。
- `creator_trx_id`:表示生成該`ReadView`事務的事務id。
有了`ReadView`之後,我們可以基於以下步驟判斷某個版本的記錄是否對當前事務可見。
1. 如果被訪問版本的`trx_id`屬性值與`ReadView`中的`creator_trx_id`值相同,意味著當前事務在訪問它自己修改過的記錄,所以該版本可以被當前事務訪問。
2. 如果被訪問版本的`trx_id`屬性值小於`ReadView`中的`min_trx_id`值,表明生成該版本的事務在當前事務生成`ReadView`前已經提交,所以該版本可以被當前事務訪問。
3. 如果被訪問版本的`trx_id`屬性值大於或等於`ReadView`中的`max_trx_id`值,表明生成該版本的事務在當前事務生成`ReadView`後才開啟,所以該版本不可以被當前事務訪問。
4. 如果被訪問版本的`trx_id`屬性值在`ReadView`的`min_trx_id`和`max_trx_id`之間,那就需要判斷一下`trx_id`屬性值是不是在`m_ids`列表中,如果在,說明建立`ReadView`時生成該版本的事務還是活躍的,該版本不可以被訪問;如果不在,說明建立`ReadView`時生成該版本的事務已經被提交,該版本可以被訪問。
在`MySQL`中,`READ COMMITTED`和`REPEATABLE READ`隔離級別的的一個非常大的區別就是它們生成`ReadView`的時機不同。**`READ COMMITTED`在每次讀取資料前都會生成一個`ReadView`**,這樣就能保證每次都能讀到其它事務已提交的資料。**`REPEATABLE READ` 只在第一次讀取資料時生成一個`ReadView`**,這樣就能保證後續讀取的結果完全一致。
## 鎖
事務併發訪問同一資料資源的情況主要就分為`讀-讀`、`寫-寫`和`讀-寫`三種。
1. `讀-讀`
即併發事務同時訪問同一行資料記錄。由於兩個事務都進行只讀操作,不會對記錄造成任何影響,因此併發讀完全允許。
2. `寫-寫`
即併發事務同時修改同一行資料記錄。這種情況下可能導致`髒寫`問題,這是任何情況下都不允許發生的,因此只能通過`加鎖`實現,也就是當一個事務需要對某行記錄進行修改時,首先會先給這條記錄加鎖,如果加鎖成功則繼續執行,否則就排隊等待,事務執行完成或回滾會自動釋放鎖。
3. `讀-寫`
即一個事務進行讀取操作,另一個進行寫入操作。這種情況下可能會產生`髒讀`、`不可重複讀`、`幻讀`。最好的方案是**讀操作利用多版本併發控制(`MVCC`),寫操作進行加鎖**。
### 鎖的粒度
按鎖作用的資料範圍進行分類的話,鎖可以分為`行級鎖`和`表級鎖`。
1. `行級鎖`:作用在資料行上,鎖的粒度比較小。
2. `表級鎖`:作用在整張資料表上,鎖的粒度比較大。
### 鎖的分類
為了實現`讀-讀`之間不受影響,並且`寫-寫`、`讀-寫`之間能夠相互阻塞,`Mysql`使用了`讀寫鎖`的思路進行實現,具體來說就是分為了`共享鎖`和`排它鎖`:
1. `共享鎖(Shared Locks)`:簡稱`S鎖`,在事務要讀取一條記錄時,需要先獲取該記錄的`S鎖`。`S鎖`可以在同一時刻被多個事務同時持有。我們可以用`select ...... lock in share mode;`的方式手工加上一把`S鎖`。
2. `排他鎖(Exclusive Locks)`:簡稱`X鎖`,在事務要改動一條記錄時,需要先獲取該記錄的`X鎖`。`X鎖`在同一時刻最多隻能被一個事務持有。`X鎖`的加鎖方式有兩種,第一種是自動加鎖,在對資料進行增刪改的時候,都會預設加上一個`X鎖`。還有一種是手工加鎖,我們用一個`FOR UPDATE`給一行資料加上一個`X鎖`。
還需要注意的一點是,如果一個事務已經持有了某行記錄的`S鎖`,另一個事務是無法為這行記錄加上`X鎖`的,反之亦然。
除了`共享鎖(Shared Locks)`和`排他鎖(Exclusive Locks)`,`Mysql`還有`意向鎖(Intention Locks)`。意向鎖是由資料庫自己維護的,一般來說,當我們給一行資料加上共享鎖之前,資料庫會自動在這張表上面加一個`意向共享鎖(IS鎖)`;當我們給一行資料加上排他鎖之前,資料庫會自動在這張表上面加一個`意向排他鎖(IX鎖)`。**`意向鎖`可以認為是`S鎖`和`X鎖`在資料表上的標識,通過意向鎖可以快速判斷表中是否有記錄被上鎖,從而避免通過遍歷的方式來查看錶中有沒有記錄被上鎖,提升加鎖效率**。例如,我們要加表級別的`X鎖`,這時候資料表裡面如果存在行級別的`X鎖`或者`S鎖`的,加鎖就會失敗,此時直接根據`意向鎖`就能知道這張表是否有行級別的`X鎖`或者`S鎖`。
### InnoDB中的表級鎖
`InnoDB`中的表級鎖主要包括表級別的`意向共享鎖(IS鎖)`和`意向排他鎖(IX鎖)`以及`自增鎖(AUTO-INC鎖)`。其中`IS鎖`和`IX鎖`在前面已經介紹過了,這裡不再贅述,我們接下來重點了解一下`AUTO-INC鎖`。
大家都知道,如果我們給某列欄位加了`AUTO_INCREMENT`自增屬性,插入的時候不需要為該欄位指定值,系統會自動保證遞增。系統實現這種自動給`AUTO_INCREMENT`修飾的列遞增賦值的原理主要是兩個:
1. `AUTO-INC鎖`:在執行插入語句的時先加上表級別的`AUTO-INC鎖`,插入執行完成後立即釋放鎖。**如果我們的插入語句在執行前無法確定具體要插入多少條記錄,比如`INSERT ... SELECT`這種插入語句,一般採用`AUTO-INC鎖`的方式**。
2. `輕量級鎖`:在插入語句生成`AUTO_INCREMENT`值時先才獲取這個`輕量級鎖`,然後在`AUTO_INCREMENT`值生成之後就釋放`輕量級鎖`。**如果我們的插入語句在執行前就可以確定具體要插入多少條記錄,那麼一般採用輕量級鎖的方式對AUTO_INCREMENT修飾的列進行賦值**。這種方式可以避免鎖定表,可以提升插入效能。
> mysql預設根據實際場景自動選擇加鎖方式,當然也可以通過`innodb_autoinc_lock_mode`強制指定只使用其中一種。
### InnoDB中的行級鎖
前面說過,通過`MVCC`可以解決`髒讀`、`不可重複讀`、`幻讀`這些讀一致性問題,但實際上這只是解決了普通`select`語句的資料讀取問題。事務利用`MVCC`進行的讀取操作稱之為`快照讀`,所有普通的`SELECT`語句在`READ COMMITTED`、`REPEATABLE READ`隔離級別下都算是`快照讀`。除了`快照讀`之外,還有一種是`鎖定讀`,即在讀取的時候給記錄加鎖,在`鎖定讀`的情況下依然要解決`髒讀`、`不可重複讀`、`幻讀`的問題。由於都是在記錄上加鎖,這些鎖都屬於`行級鎖`。
**`InnoDB`的行鎖,是通過鎖住索引來實現的,如果加鎖查詢的時候沒有使用過索引,會將整個聚簇索引都鎖住,相當於鎖表了**。根據鎖定範圍的不同,行鎖可以使用`記錄鎖(Record Locks)`、`間隙鎖(Gap Locks)`和`臨鍵鎖(Next-Key Locks)`的方式實現。假設現在有一張表`t`,主鍵是`id`。我們插入了4行資料,主鍵值分別是 1、4、7、10。接下來我們就以聚簇索引為例,具體介紹三種形式的行鎖。
- 記錄鎖(Record Locks)
所謂記錄,就是指聚簇索引中真實存放的資料,比如上面的1、4、7、10都是記錄。

顯然,記錄鎖就是直接鎖定某行記錄。當我們使用唯一性的索引(包括唯一索引和聚簇索引)進行等值查詢且精準匹配到一條記錄時,此時就會直接將這條記錄鎖定。例如`select * from t where id =4 for update;`就會將`id=4`的記錄鎖定。
- 間隙鎖(Gap Locks)
間隙指的是兩個記錄之間邏輯上尚未填入資料的部分,比如上述的(1,4)、(4,7)等。

同理,間隙鎖就是鎖定某些間隙區間的。當我們使用用等值查詢或者範圍查詢,並且沒有命中任何一個`record`,此時就會將對應的間隙區間鎖定。例如`select * from t where id =3 for update;`或者`select * from t where id > 1 and id < 4 for update;`就會將(1,4)區間鎖定。
- 臨鍵鎖(Next-Key Locks)
臨鍵指的是間隙加上它右邊的記錄組成的左開右閉區間。比如上述的(1,4]、(4,7]等。

臨鍵鎖就是記錄鎖(Record Locks)和間隙鎖(Gap Locks)的結合,即除了鎖住記錄本身,還要再鎖住索引之間的間隙。當我們使用範圍查詢,並且命中了部分`record`記錄,此時鎖住的就是臨鍵區間。注意,臨鍵鎖鎖住的區間會包含最後一個record的右邊的臨鍵區間。例如`select * from t where id > 5 and id <= 7 for update;`會鎖住(4,7]、(7,+∞)。mysql預設行鎖型別就是`臨鍵鎖(Next-Key Locks)`。當使用唯一性索引,等值查詢匹配到一條記錄的時候,臨鍵鎖(Next-Key Locks)會退化成記錄鎖;沒有匹配到任何記錄的時候,退化成間隙鎖。
`間隙鎖(Gap Locks)`和`臨鍵鎖(Next-Key Locks)`都是用來解決幻讀問題的,在`已提交讀(READ COMMITTED)`隔離級別下,`間隙鎖(Gap Locks)`和`臨鍵鎖(Next-Key Locks)`都會失效!
> 原創不易,覺得文章寫得不錯的小夥伴,點個贊