
最佳實踐:Pulsar 為批流處理提供融合儲存
阿新 • • 發佈:2020-09-03
非常榮幸有機會和大家分享一下 Apache Pulsar 怎樣為批流處理提供融合的儲存。希望今天的分享對做大資料處理的同學能有幫助和啟發。
這次分享,主要分為四個部分:
* 介紹與其他訊息系統相比, Apache Pulsar 的獨特優勢
* 分析批流處理中的儲存需求
* 講述 Apache Pulsar 如何完美匹配批流處理中的儲存需求
* 介紹怎樣使用 Apache Pulsar 提供批流融合的儲存
# Apache Pulsar 簡介
Apache Pulsar 是新近開源的一個大規模分散式訊息系統,是 Apache 的頂級專案,在 Yahoo 全球數十個機房大規模部署併線上穩定使用了 4 年多。Apache Pulsar 設計中學習和借鑑了其他優秀的分散式系統,在保證一致性和高吞吐的同時,也提供了其他優秀特性,比如支援上百萬的 Topic、無縫的多中心互備、靈活的擴充套件性等。
這裡我們簡單介紹一下,與其他訊息系統相比, Apache Pulsar 擁有的獨特優勢,大致有以下3點:
* 獨特的軟體架構(儲存和計算分離,分層分片的儲存)
* 靈活的消費模型( Exclusive、Failover、Shared 和 KeyShared)
* 豐富的企業特性(多租戶)
在介紹 Apache Pulsar 時,通常會用這樣一句話,“Flexible Pub-Sub Messaging backed by durable log Storage”。這句話表明了 Pulsar 和其他訊息系統的根本不同,它採用了儲存和計算分離的架構。
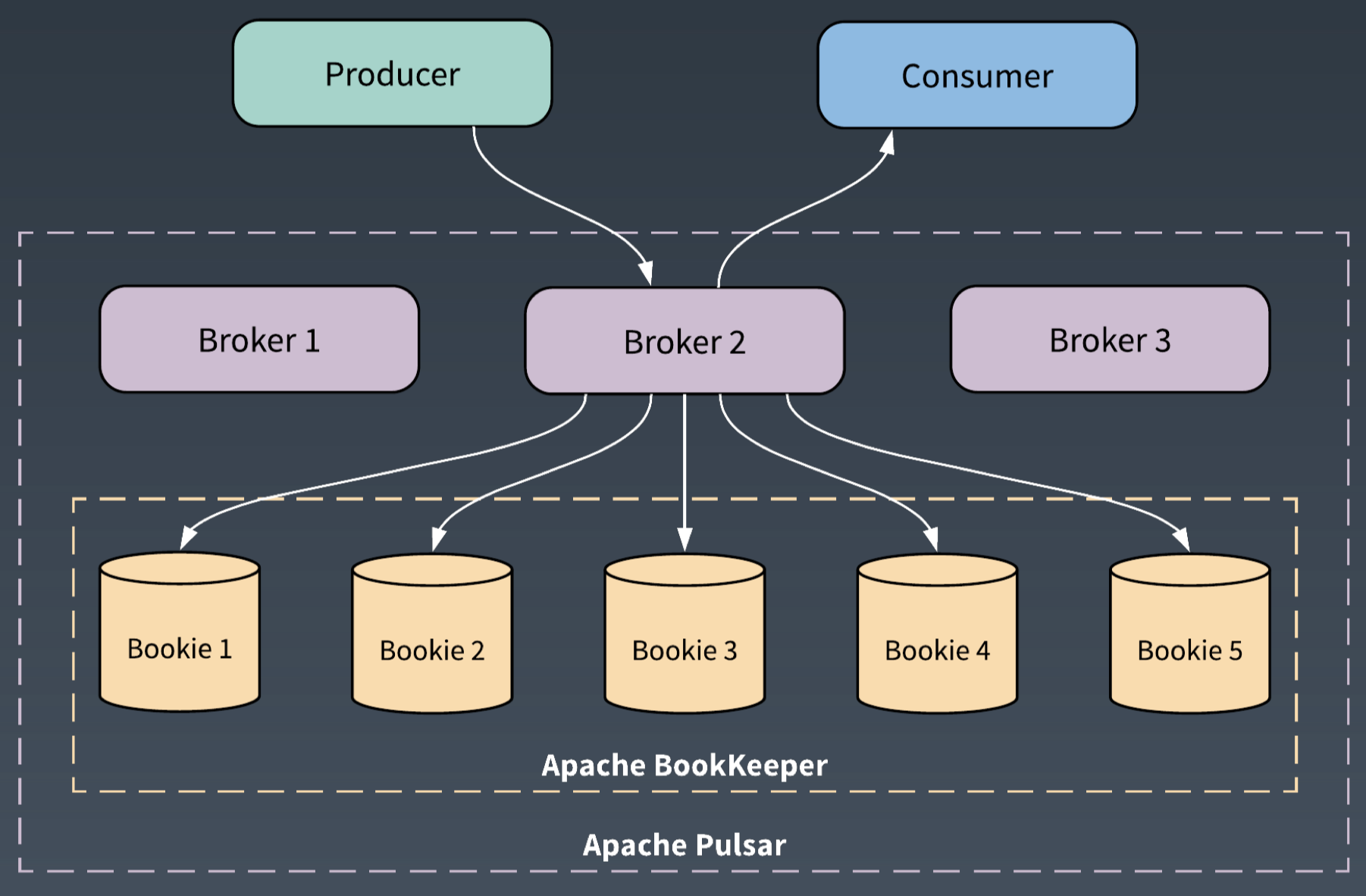
Pulsar 的服務層使用 Broker,儲存層使用 BookKeeper,來提供高效和一致的儲存。
從架構上來說,Apache Pulsar 採用了分層和分片的架構。這是 Pulsar 滿足批流處理中儲存需求的基礎。
在 Apache Pulsar 的分層架構中,服務層 Broker 和儲存層 BookKeeper 的每個節點都是對等的。Broker 僅僅負責訊息的服務支援,不儲存資料。這為服務層和儲存層提供了瞬時的節點擴充套件和無縫的失效恢復。
儲存層 BookKeeper 為 WAL(Write Ahead Log)提供了儲存,是一個分散式的 Log 儲存系統。
WAL 和資料處理中的流有很多相似性,都是資料來源源不斷地追加,都對順序和一致性有嚴格要求。
BookKeeper 通過 Quorum Vote 的方式來實現資料的一致性,跟 Master/Slave 模式不同,BookKeeper 中每個節點也是對等的,對一份資料會併發地同時寫入指定數目的儲存節點。對等的儲存節點,保證了多個備份可以被併發訪問;也保證了儲存中即使只有一份資料可用,也可以對外提供服務。
Apache Pulsar 通過分層分片的架構,將邏輯的分割槽轉化為分片來作為儲存單元。這為資料的併發訪問提供了基礎。
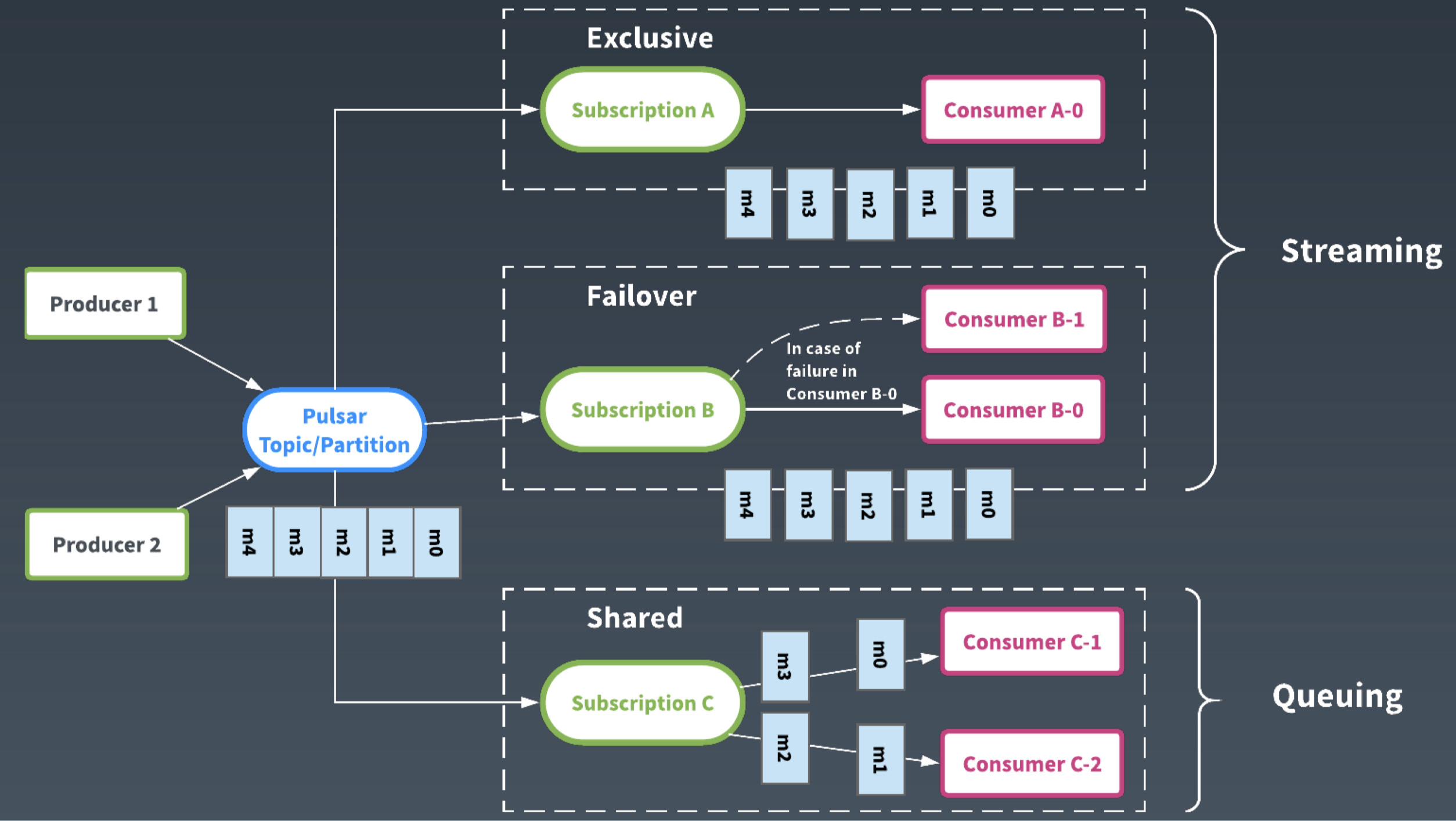
除了架構的不同,從使用者介面來說,Apache Pulsar 通過訂閱的抽象,提供了靈活的消費模型。每一個訂閱類似一個 Consumer Group,接收一個 topic 的所有的訊息。使用者可以使用不同的訂閱型別、以不同的模式來共同消費同一個 Topic 中的訊息。
如果對順序性有要求,可以使用 Exclusive 和 Failover 的訂閱模式,這樣同一個 Topic 只有一個 Consumer 在消費,可以保證順序性。
如果使用 Shared 訂閱模式,多個 Consumer 可以併發消費同一個 Topic。通過動態增加 Consumer 的數量,可以加速 Topic 的消費,減少訊息在服務端的堆積。
Pulsar 即將釋出的 2.4.0 版本添加了一種新的訂閱模式: KeyShared。KeyShared 模式保證在 Shared 模式下同一個 Key 的訊息也會發送到同一個 Consumer,在併發的同時也保證了順序性。
Apache Pulsar 靈活的消費模型,避免了因為不同的消費場景需要部署多套訊息系統的場景,消除了資料生產端的資料分離。
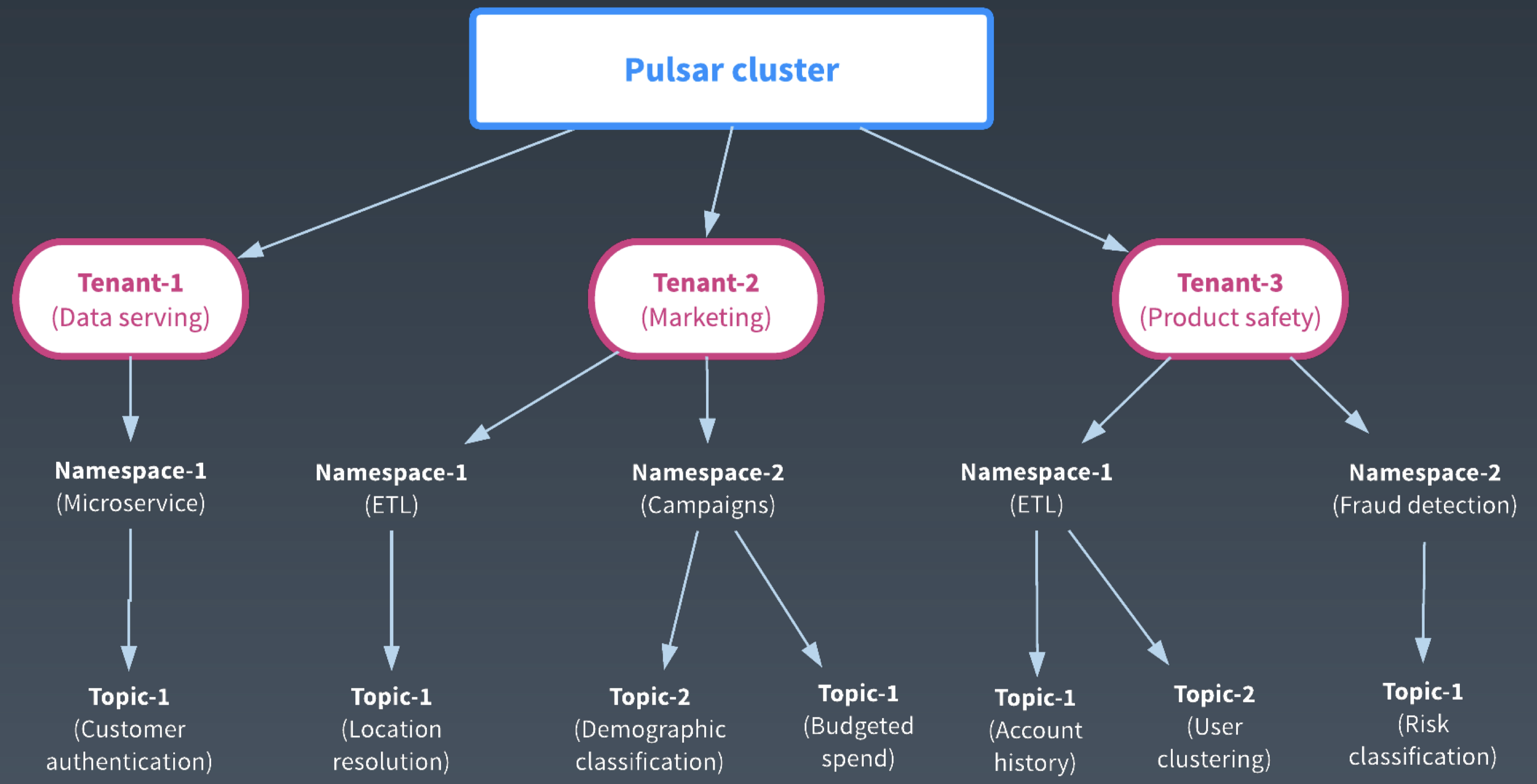
此外,Apache Pulsar 是以多租戶為基礎的豐富的企業級特性。企業內部可以搭建一套 Pulsar 叢集,在叢集中給各個部門分配不同的租戶,並設定租戶的管理許可權。租戶的管理員再根據部門的不同業務和場景需求,建立不同的 Namespace。在 Namespace 中可以設定管理策略,比如流控,Quota,互備的叢集,資料副本數等。這樣為 Topic 的管理提供了一個層級的可控的檢視。
Apache Pulsar 的企業級特性,為企業搭建統一大叢集提供了基礎,方便了叢集的管理和資料的共享。
以上是關於 Apache Pulsar 的簡單介紹,歡迎參閱 Apache Pulsar 的官網和微信公眾號瞭解更多內容。
# 批流處理中的儲存現狀

在大資料處理剛剛興起的時候,一般使用者會採用 λ 架構,維護批流兩套系統:批系統主要處理歷史資料; 流系統處理實時的資料,對批系統的結果進行補充來提高時效。兩套系統造成資料冗餘,增加維護成本。
在儲存層,批處理常使用 HDFS 和網路物件儲存等;流處理常使用 Kafka 或其他的訊息系統。
為了解決 λ 架構的問題,逐漸演化出 κ 架構,使用一套系統來滿足實時資料處理和歷史資料處理的需求。
在 κ 架構中,資料的“可重複處理”是關鍵。一方面要求實時資料能及時獲取最新資料,處理完立即匯出給其他系統使用;另一方面要滿足處理歷史資料的需求,需要具備讀大量歷史資料的能力。實時資料的處理決定了必須使用訊息系統,但是訊息系統並不能完全滿足批處理的併發需求。
在前面的分享中,百度和阿里的專家分享了計算層的批流融合。我們認為批流融合儲存層的需求是一個融合的儲存表徵: 訊息系統 + 併發的儲存訪問。
# 為什麼 Apache Pulsar 能滿足批流處理中的儲存需求
下面我們從 “Apache Pulsar 提供的儲存抽象”、“批流處理中的 IO 模式”和 “Apache Pulsar 提供的無限流儲存” 這三個方面來解釋為什麼 Apache Pulsar 能滿足批流融合的儲存需求。
## Segmented Stream 儲存表徵
前面我們介紹了 Apache Pulsar 首先是一個訊息系統,它和其他訊息系統類似,提供了簡潔的以 Topic,Producer,Consumer 為基礎的 Pub/Sub 模型。
Pulsar 靈活的訂閱模式和高頻寬、低延遲特性,能夠很好的滿足流處理的需求。
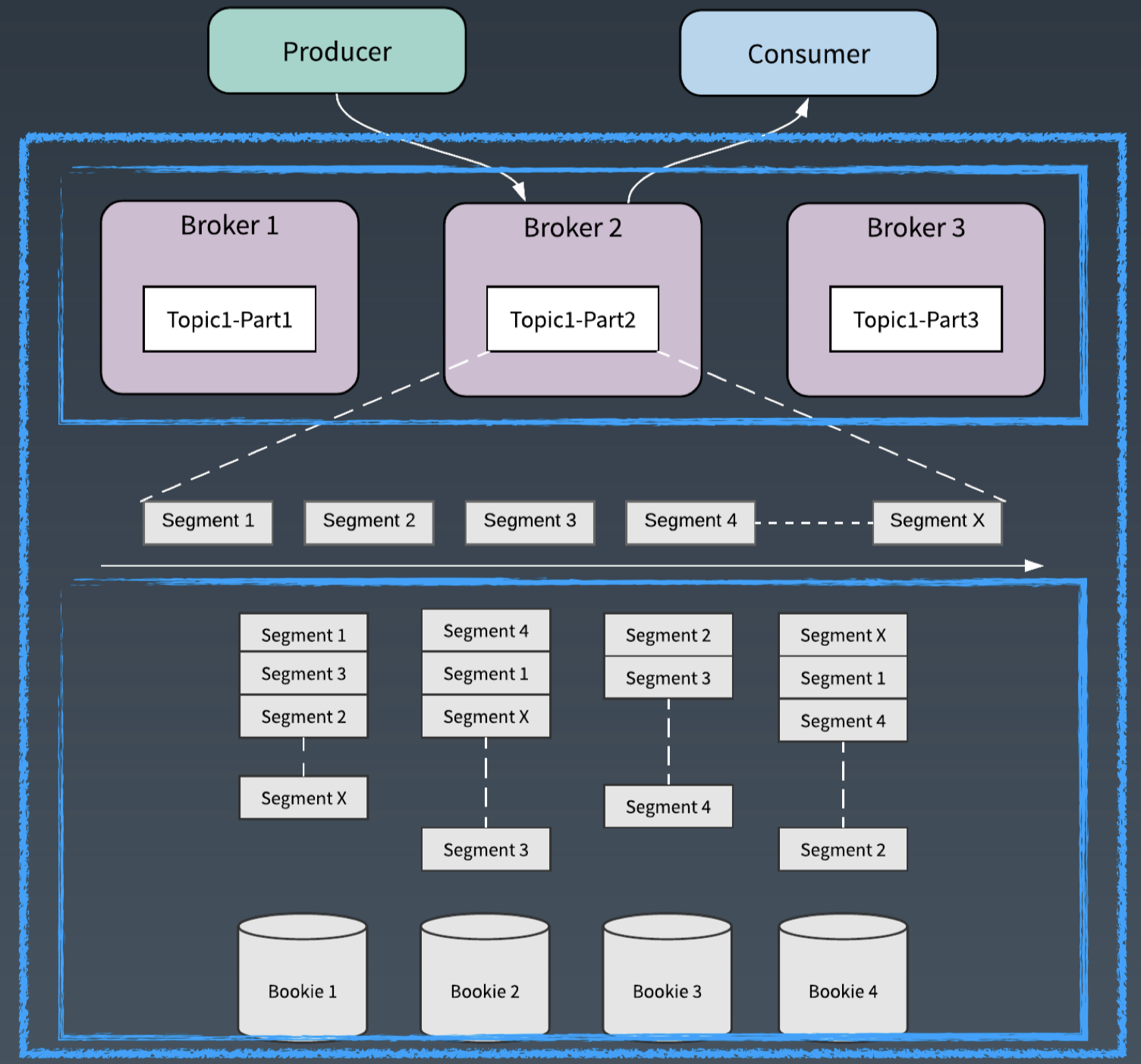
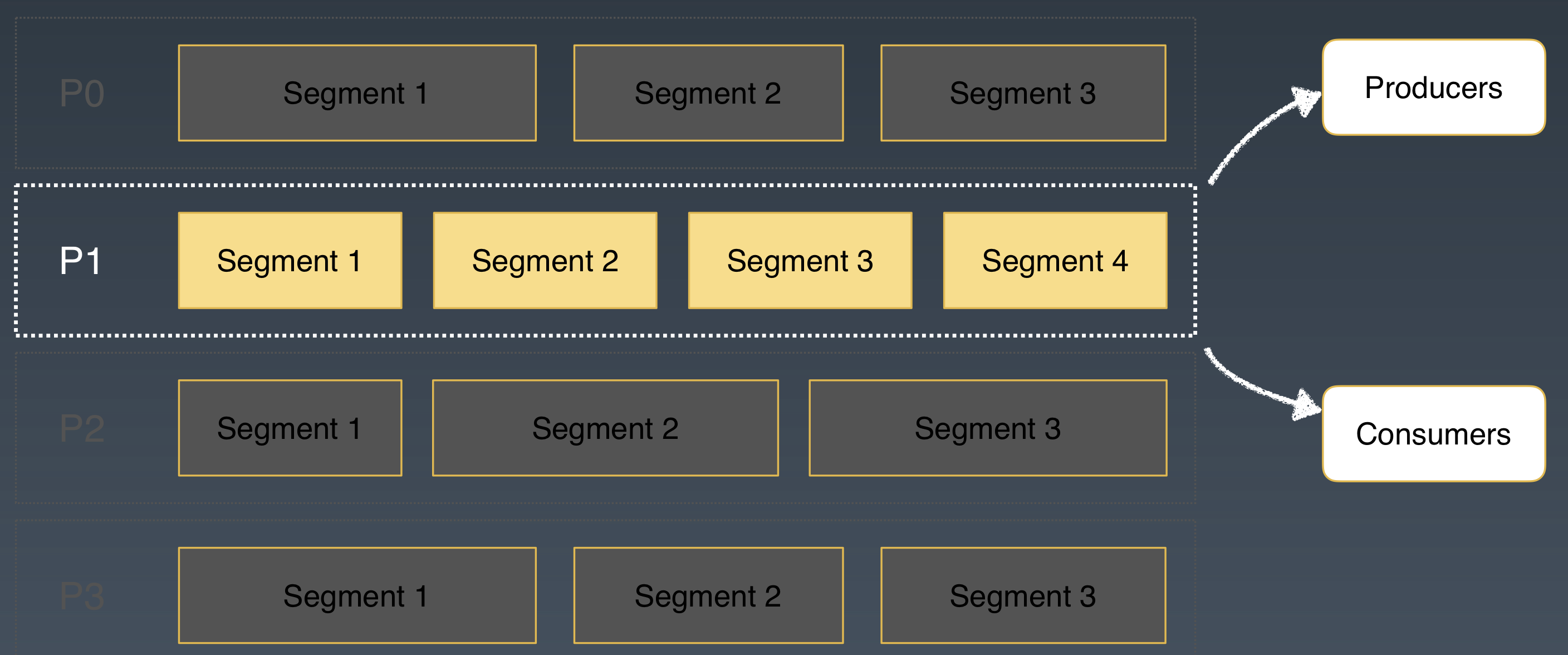
Apache Pulsar 的 Topic 可以分為不同的分割槽。和其他訊息系統不同的是 Apache Pulsar 利用分片的架構,每個邏輯分割槽又進行了分片。
在分層分片的架構中,分片是儲存的單元,可以類比 HDFS 中的一個檔案塊,分片被均勻地分佈在儲存層的 BookKeeper 節點中。
我們再從批流處理的角度來看 Apache Pulsar 的這種分片(Segment)的架構:
* 對於流處理來說,Apache Pulsar 的每個 Partition 就是流處理的一個流,它通過 Pub/Sub 的介面來給流處理提供資料互動。
* 對於批處理來說,Apache Pulsar 以分片為粒度,可以為批處理提供資料的併發訪問。
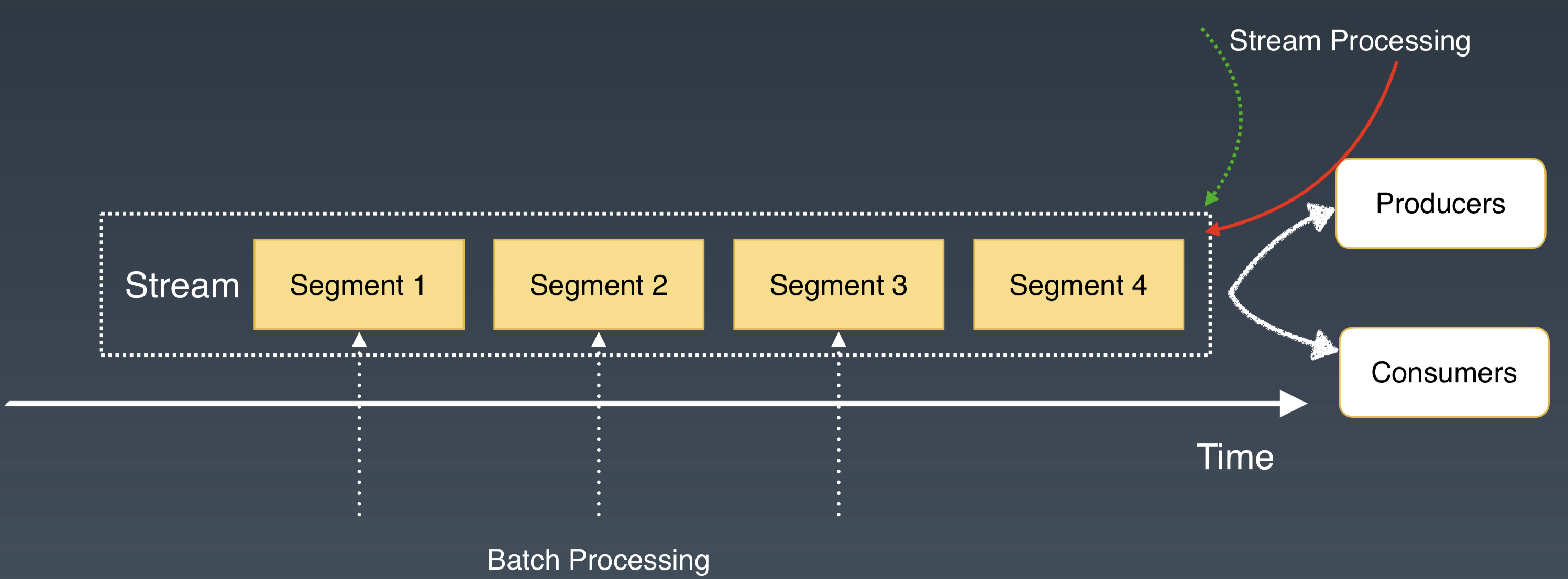
一方面,Apache Pulsar 中每個 Partition 都可以看做是源源不斷流入資料的載體,藉助於分片和二級儲存,Apache Pulsar 有能力將 Partition 所有流入的資料都儲存下來。這樣每個 Partition 都可以看作是 Stream 的儲存抽象。
另一方面, Apache Pulsar 的 Partition 是邏輯分割槽的概念,分割槽內部又被分成分片,作為儲存和 IO 訪問的單元。
結合這兩個概念,我們把 Apache Pulsar 對每個 Partiton 的儲存表徵稱為 Segmented Stream。
通過 Pulsar 的 Segmented Stream 抽象,為批流處理提供了一個統一的儲存表徵。
## 匹配批流處理中的 IO 模式
介紹了 Apache Pulsar 的 Segmented Stream 的儲存表徵後,下面我們結合批流處理中資料的三種常用的訪問模式: Write,Tailing Read 和 Catchup Read,來看看 Apache Pulsar 這種架構的合理性。這裡主要會討論延遲、IO 的併發和隔離,並用大家比較熟悉的 Kafka 系統來對比說明。
* Write:往 Stream 中新增新的資料。
* Tailing Read:讀最新的資料。
* Catchup Read:讀歷史老資料。
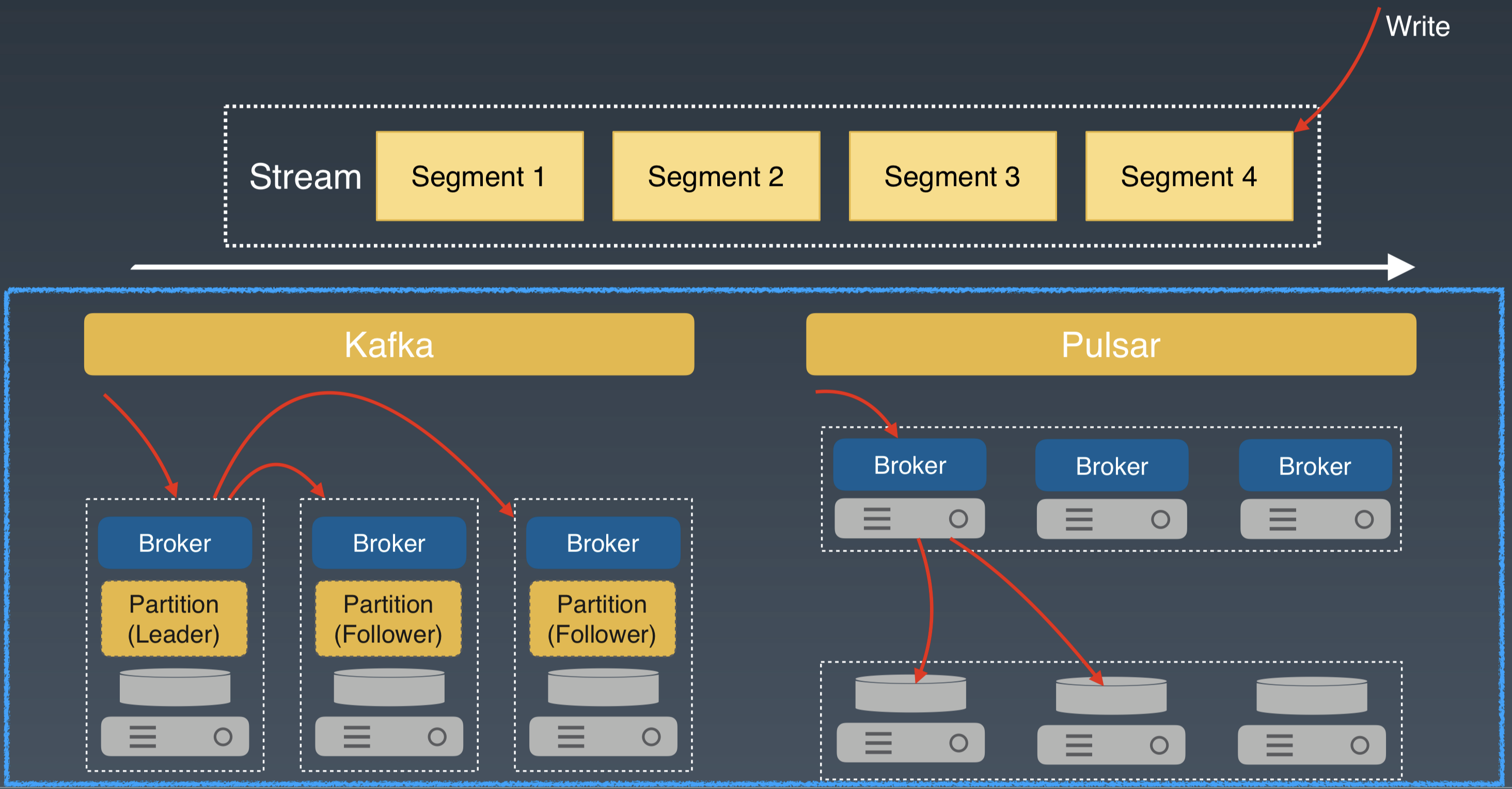
對於 Write 這種模式,所有的寫都直接追加在 Stream 的尾部。對於和 Kafka 類似的 Master/Slave 架構系統來說,資料會先寫入 Leader Broker,再發送給其他 Follower Broker。
Apache Pulsar 的寫先發送到 broker,然後 broker 作為儲存代理,併發將資料傳送給儲存層的多個 Bookie 節點。兩種架構都會有兩次網路跳躍。
對於 Write 模式,延遲差別不大。
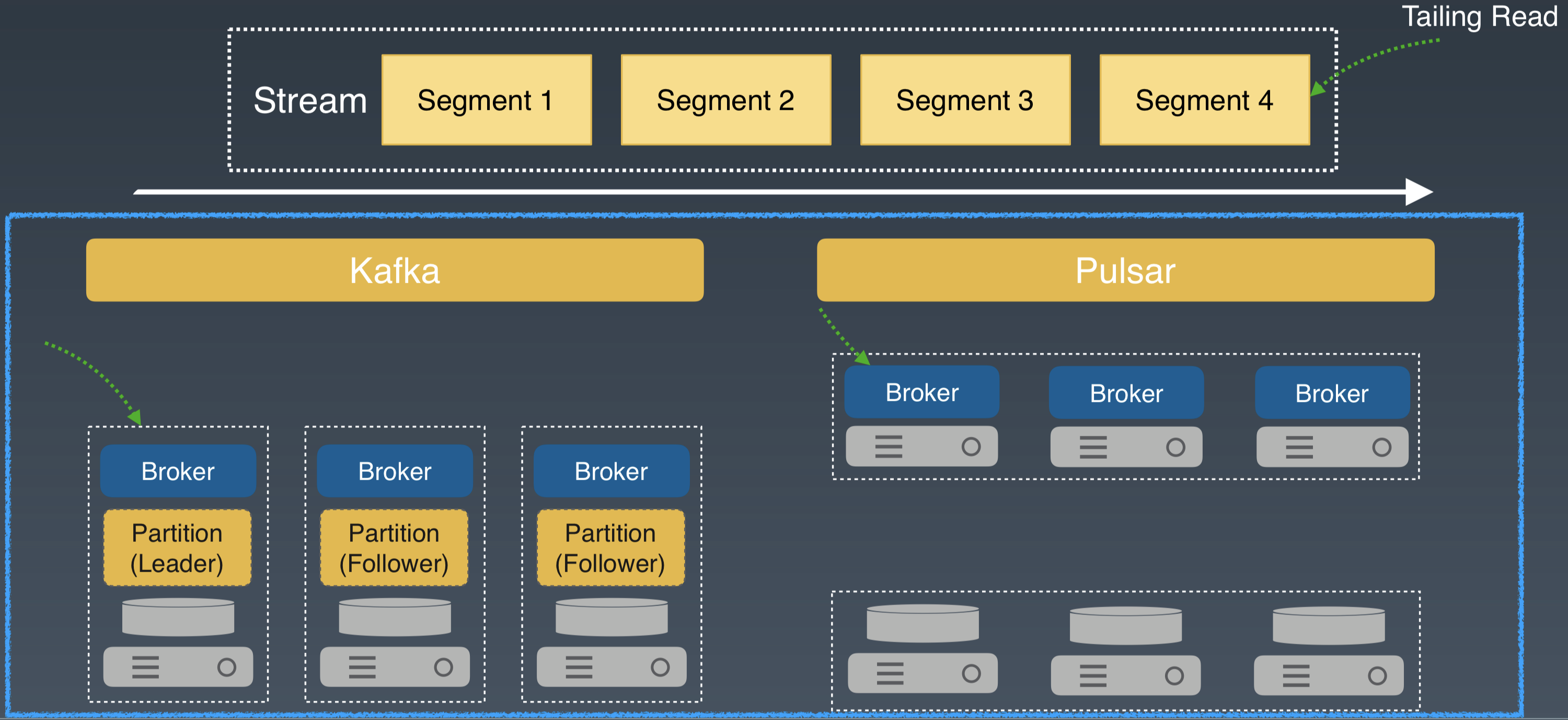
Tailing Read 是流處理中的常用模式。它從 Stream 的尾部讀取最新寫入的資料。
對於和 Kafka 類似的系統,Tailing Read 會從 Leader Broker 直接讀取。對於 Apache Pulsar,在 Broker 中有一段自維護的 Cache 來快取剛剛寫入的最新資料,Tailing Read 直接從 Broker 獲取資料並返回。
兩種架構都只有 1 次網路跳躍。對 Tailing Read 模式,延遲差別不大。
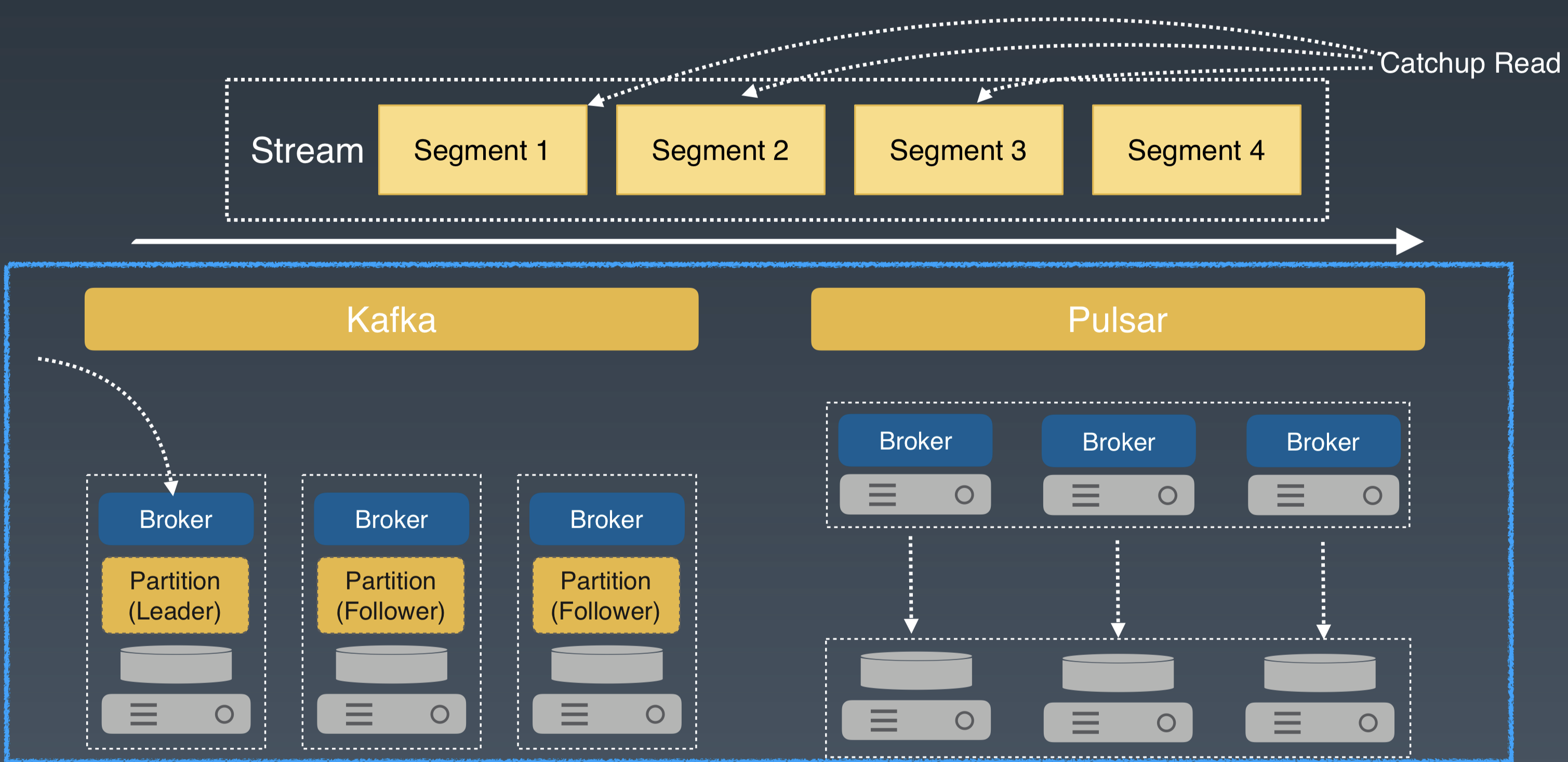
Catchup Read 是批處理中常用的讀取模式。它從 Stream 的指定位置,讀取一定量的歷史資料。這種場景一般對資料的讀取量比較大,注重讀取的頻寬。
對於 Kafka 類似的系統,Catchup Read 一般還是會使用 Pub/Sub 的介面,從 Leader Broker 直接讀取。對於 Apache Pulsar,我們可以從 Broker 中讀取元資料,獲取 partition 中分片的起始位置和分片在 BookKeeper 中的儲存資訊,繞過 Pub/Sub 介面,利用 BookKeeper 的 Read 介面,直接從儲存層併發訪問多個分片。BookKeeper 提供了多副本的高可用,提升了讀取歷史資料的併發能力。
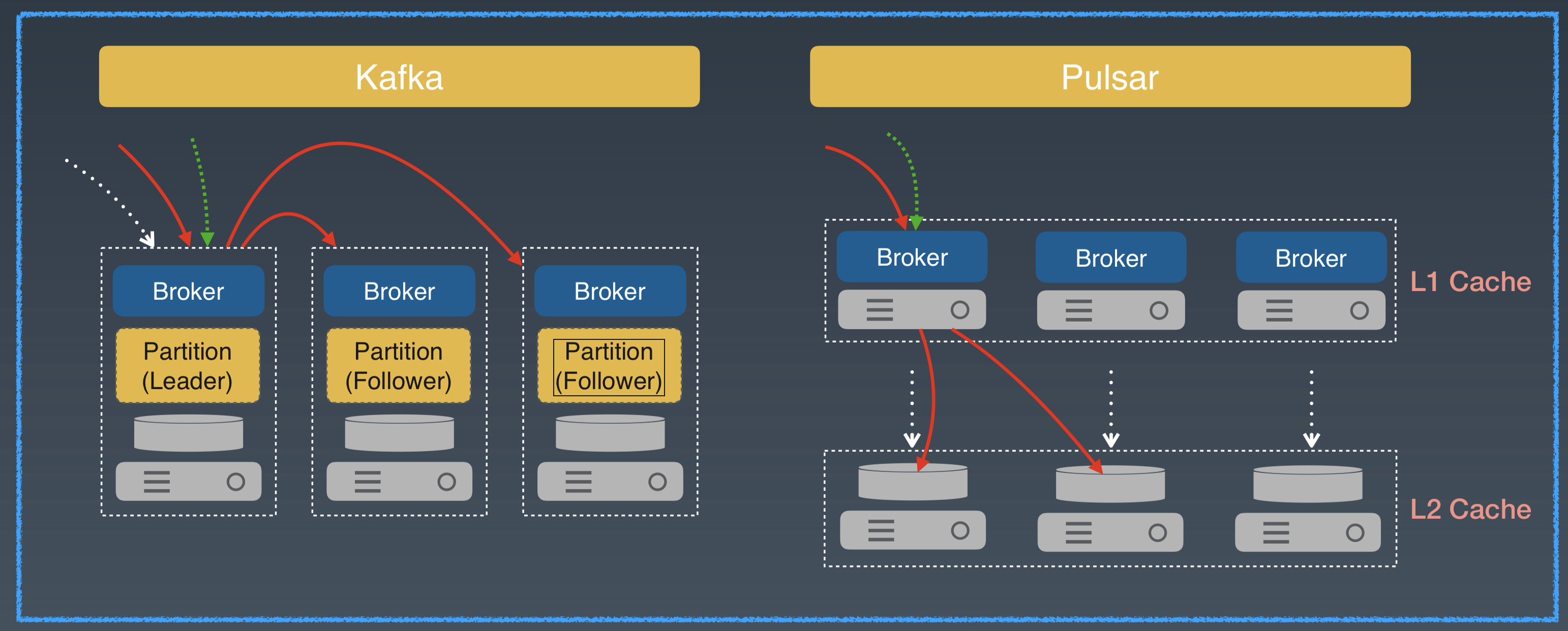
如果我們把這三種 IO 模式放在一起看就更有意思了。 這可以類比使用者在某時間段,對 Stream 既有最新資料讀寫,也有歷史資料讀寫的情形。這是在批流融合中經常遇到的場景。
對和 Kafka 類似的系統,這三種 IO 模式都會發生在 Leader Broker。在 Leader Broker 中,系統的資料都需要通過檔案系統的 Pagecache,歷史資料和最新的資料會爭用 Pagecache 資源,造成讀寫響應不及時。
如果這時再遇到 Broker 磁碟空間寫滿,需要擴容的情況,那就需要等待資料的搬移和 rebalance 的操作。這時,IO 的延遲和服務質量很難得到保障。
Apache Pulsar Segmented Stream 的儲存表徵,結合分層分片的架構,為新資料和歷史資料做了天然的隔離。最新的資料 IO 發生在 Broker 層。
對歷史資料的併發讀寫,直接發生在儲存節點。冷熱資料被天然隔離,使用者完全不用擔心 IO 的衝突和爭用。Apache Pulsar 在節點擴容和錯誤恢復的過程中,也不會有資料大量拷貝和 rebalance,因此提升了系統的高可用性。
通過這三種 IO 模式的說明和對比,我們發現 Pulsar Segmented Stream 的儲存表徵,再結合分層分片的架構,可以很好地滿足批流處理中對儲存系統的需求。
## 無限的流儲存支援
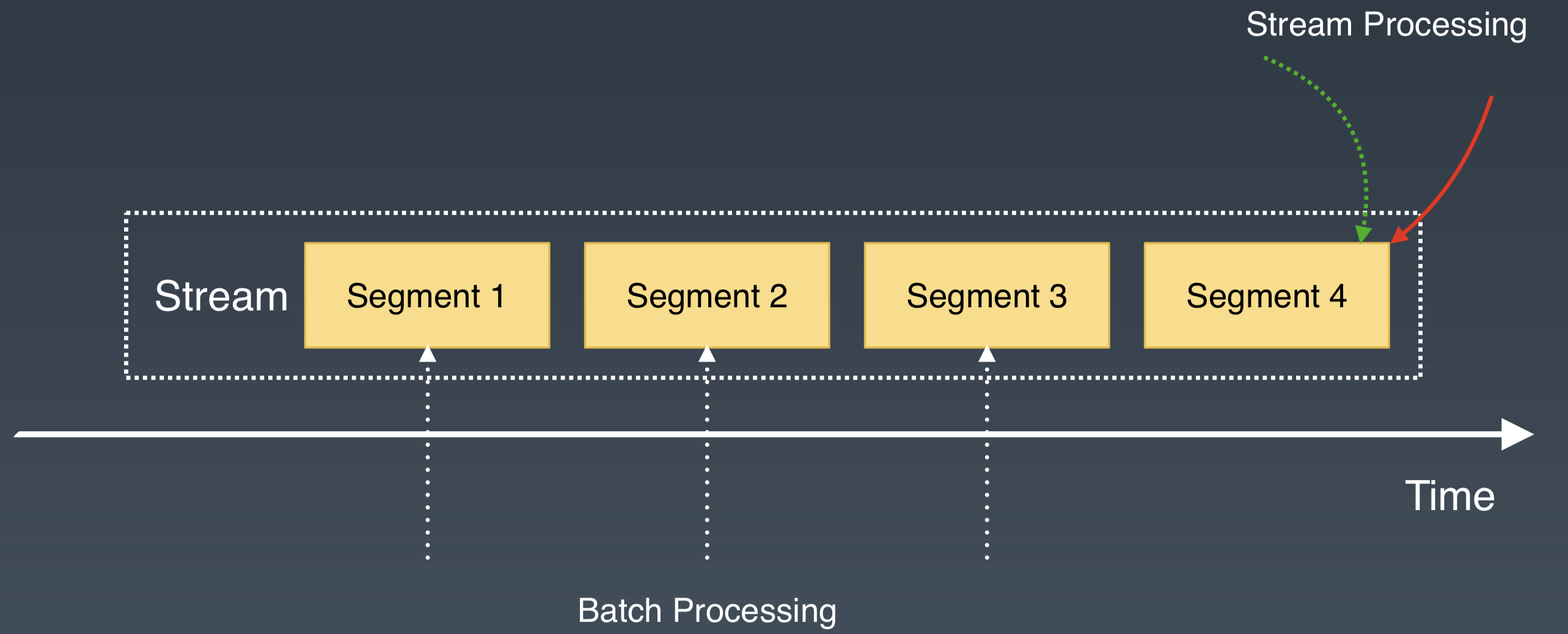
Pulsar Segmented Stream 的儲存表徵,很好地模擬了現實中 Stream 資料。對於流儲存的另一個需求是理論上無限的儲存空間。這樣可以滿足對歷史資料的儲存和訪問需求。Apache Pulsar 從兩個方面解決了這個問題。
一方面 Pulsar 的儲存層中,分片會均衡地分佈到所有的儲存節點中,這避免了其他系統中單一broker 儲存容量的限制,進而可以利用整個叢集的儲存空間。
另一方面,Pulsar 的分片架構,為資料的二級儲存擴充套件提供了很好的基礎。對於Segmented Stream,使用者可以設定 Segment 在 BookKeeper 中保留的時間或大小。如果超過設定的值,將舊的 Segment 遷移到廉價的二級儲存,比如 Aws S3,Google Cloud Storage,或者HDFS 中。二級儲存的頻寬一般有保障,可以滿足歷史資料的批處理模式。 通過二級儲存可以減輕無限儲存的成本。
## 小結
Pulsar 利用自身的分層分片的架構,提供了 Segmented Stream 的儲存表徵,滿足了批流融合的儲存需求。
* 通過 Pulsar Pub/Sub 介面訪問 Segmented Stream,可以滿足流處理的儲存需求;
* 通過 Pulsar 儲存層對 segment 的訪問介面(Segment Reader),可以滿足批處理的併發訪問需求。
從批流處理的 IO 模式分析中可以發現,Pulsar 的架構可以很好地處理批流處理中的 IO 併發和隔離。並且 Pulsar 提供了理論上無限流儲存的能力,能夠滿足批處理中,對海量歷史資料的儲存需求。
# 怎樣使用 Pulsar 提供批流融合的儲存
前面我們介紹了為什麼 Pulsar 的架構能滿足批流融合的儲存需求。接著我們會介紹 Pulsar是如何在工程上實現的。
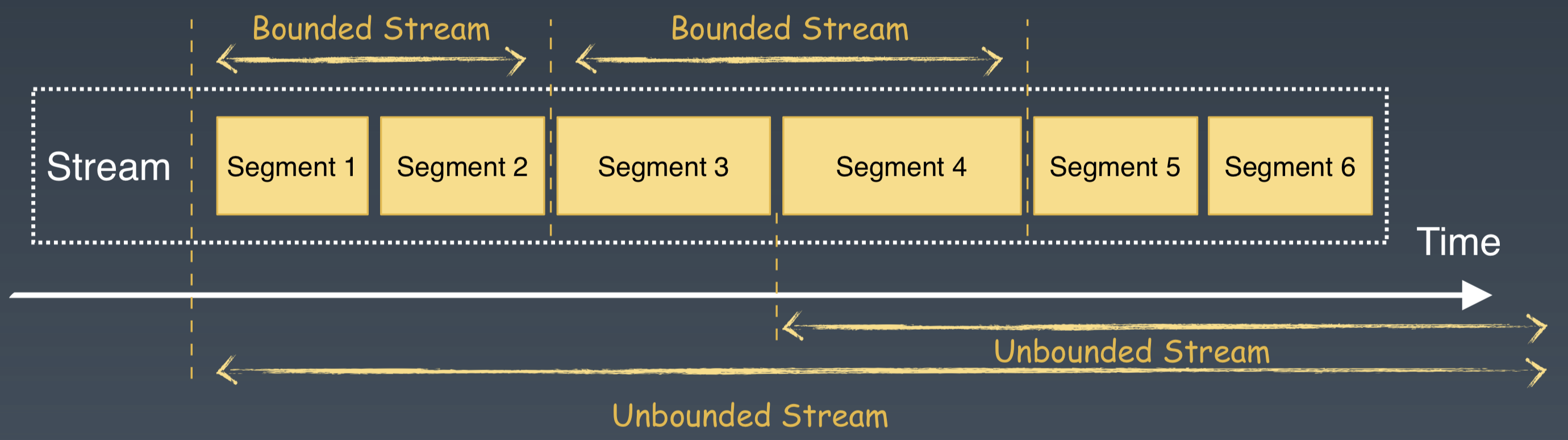
基於 Segmented Stream 儲存的表徵,我們很容易區分和支援批處理和流處理。批處理所請求的資料可以看做是一個有邊界的流(Bounded Stream)。流處理所請求的資料可以看做是一個沒有邊界的流(UnBounded Stream)。
下面我們看在 Pulsar 內部,批處理和流處理會怎樣訪問 Segmented Stream。
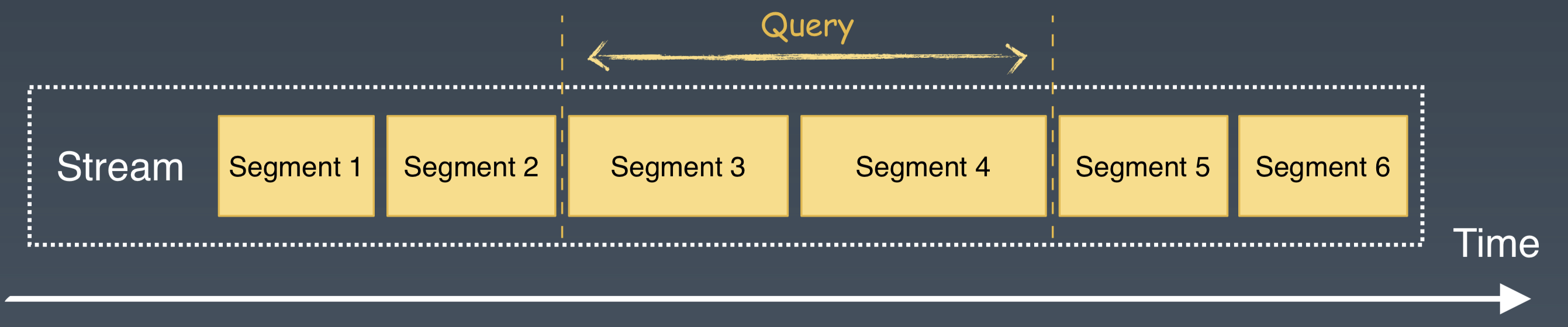
這裡的程式碼是一個計算廣告點選率的 SQL 語句。如果使用者想要查詢某個時間段內的點選率,會提供點選事件的起止時間。起止時間可以確定一個流的起止邊界,進而確定一個 Bounded Stream。這是一個典型的批處理場景。
對 Pulsar 的處理來說,首先根據起止時間來確定和獲取所需要的 Segments 列表;然後選擇這些Segments,繞過 pub/sub 介面,直接通過 Pulsar 的 Segment Reader 介面,來訪問 Pulsar 的儲存層。
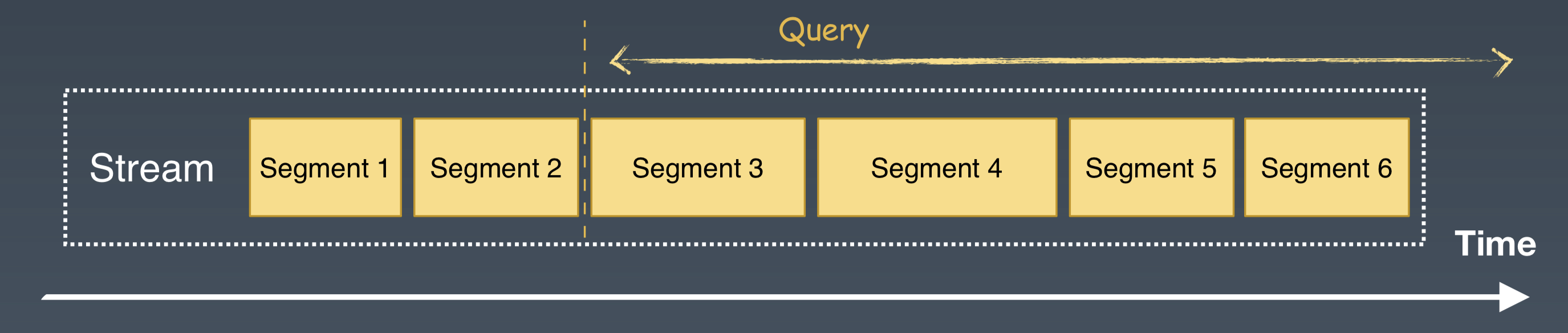
流處理是一系列不會停止的 Windows 訪問和查詢。與批處理相比,流處理它沒有截止的時間點,即使查詢到當前時刻,它仍然繼續對當前的 window 不斷地查詢,一個 window 處理結束,接著處理下一個 window。它的 SQL 查詢語句不會變化,但是查詢 window 中的資料會不斷實時更新,它是一個源源不斷的、不停處理最新資料的方式。
對於這種訪問模式,直接使用 Pulsar 的 pub/sub 介面就可以直接獲取最新的訊息,滿足流處理的需求。
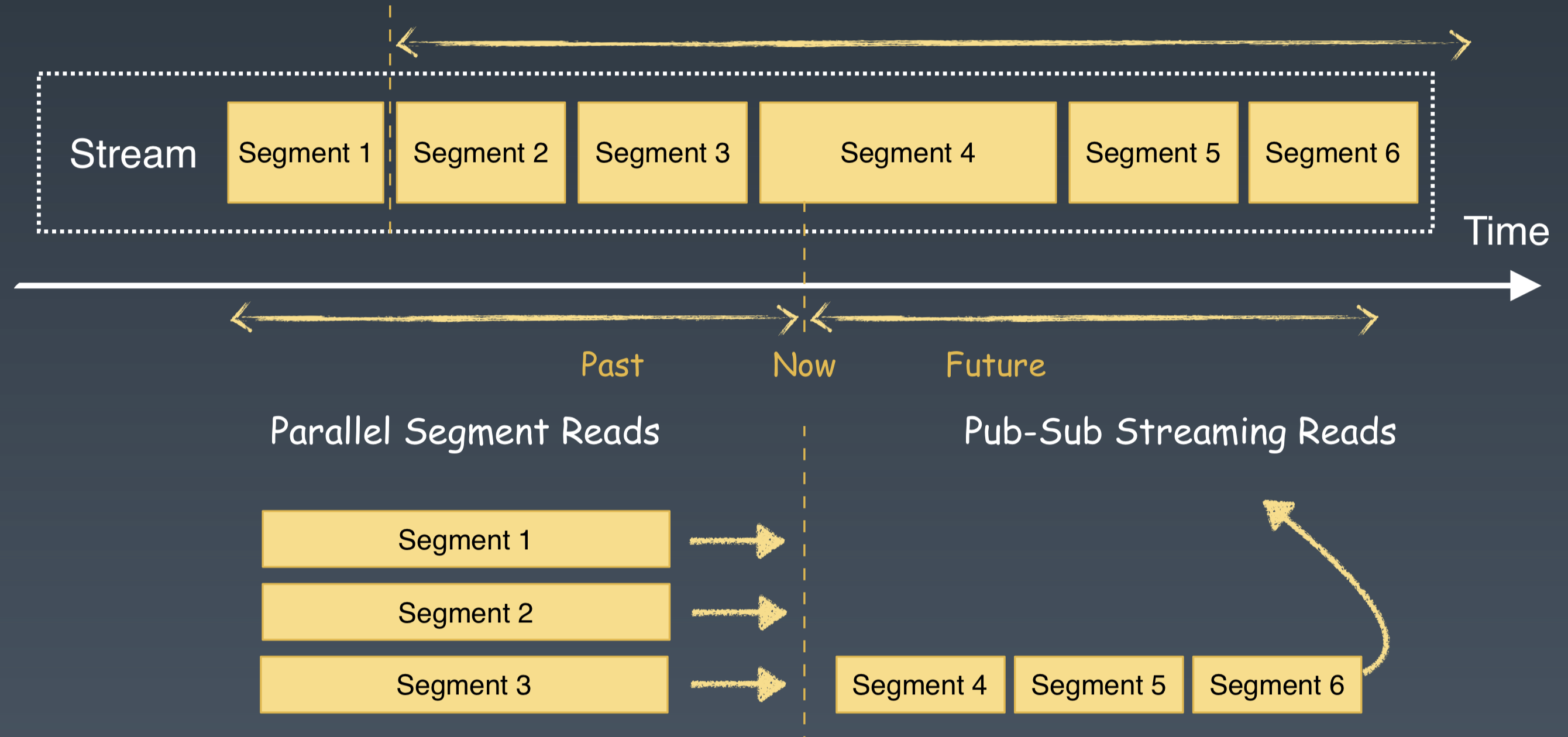
對批流融合,在計算層,更多關注的是批流融合的計算模型、API 和執行時的統一。在儲存層,通過 Segmented Stream 的儲存表徵,為批流資料提供了統一的資料儲存和組織方式。
針對批流處理的不同訪問模式,Pulsar 提供了兩套 API 介面。流處理使用 Pub/Sub 的介面;批處理使用 Parallel Segment Read(PSegment)的介面。
對於批處理的介面,我們在 Pulsar SQL 裡面做了一個嘗試,Pulsar SQL 藉助 Presto,對寫入Pulsar 中的資料進行互動式的查詢。
如果你想體驗 Pulsar SQL,可以檢視 Pulsar 的 [SQL手冊](https://pulsar.apache.org/docs/en/sql-getting-started)。
Pub/Sub 的介面已經比較完善,我們最近在豐富和完善 PSegment 介面。

在 PSegment 中,我們的主要工作是整合Pulsar 和 Flink、Spark、Hive 及 Presto 。這些工作主要集中在 API 的實現和 Schema 的整合。這些工作完成之後,我們會開源這部分的程式碼。
# 總結
Pulsar 是下一代雲原生的訊息和流儲存的平臺。我們認為訊息和流是一份資料的兩種不同表徵方式。Pulsar 採用了儲存計算分離的分層架構和分割槽內再分片的儲存架構,這種架構能夠提供基於Segmented Stream 的儲存表徵,能為批和流處理提供融合的儲存基礎。
作者翟佳,StreamNative 聯合創始人兼 CTO,本文為其 InfoQ 技術大會演講的內容